MLflow란?
MLflow는 Machine Learning Lifecycle을 관리하는 오픈소스 플랫폼입니다. 머신러닝 워크플로우를 보다 쉽게 관리하고, 추적(tracking), 배포(deployment), 그리고 모델 재사용(reproducibility)을 지원합니다. MLflow는 다음과 같은 주요 컴포넌트로 구성되어 있습니다:
1. MLflow Tracking
- 기능:
- 머신러닝 실험의 매개변수, 메트릭, 아티팩트를 기록하고 추적.
- 모델 실험의 결과를 정리하고 비교 가능.
- 사용 방법:
log_param()을 통해 하이퍼파라미터 기록.log_metric()을 통해 성능 지표 기록.log_artifact()을 통해 데이터셋, 모델 파일, 결과 파일 등 아티팩트 저장.
- 저장소:
- 데이터는 로컬 파일 시스템, 클라우드 스토리지(AWS S3, GCS 등), 또는 데이터베이스에 저장 가능.
2. MLflow Projects
- 기능:
- 재현 가능한 머신러닝 코드 실행 환경 제공.
- 프로젝트 구조를 표준화하여 다른 사용자도 쉽게 실행 가능.
- 구성:
MLproject파일: 프로젝트의 메타데이터 정의.- Conda 환경을 활용하여 종속성 관리.
- 실행 방법:
- 명령어:
mlflow run <프로젝트 경로>
- 명령어:
3. MLflow Models
- 기능:
- 모델을 다양한 포맷으로 저장 및 배포.
- 공통 포맷을 사용하여 다양한 머신러닝 프레임워크(TensorFlow, PyTorch, Scikit-learn 등)와 호환 가능.
- 모델 저장:
mlflow.<framework>.log_model()또는save_model().- 저장된 모델은 로컬 파일, S3, Azure Blob 등 다양한 스토리지에 보관.
- 모델 배포:
- REST API로 제공 가능.
- Docker 컨테이너나 클라우드 서비스(AWS SageMaker, Azure ML)로 배포 가능.
4. MLflow Registry
- 기능:
- 모델의 버전 관리, 단계 추적(개발/검증/프로덕션), 모델의 메타데이터 관리를 지원.
- 모델 승인 워크플로우 관리 가능.
- 용어:
- Registered Model: 추적된 모델의 이름.
- Model Version: 특정 모델의 버전.
- Stage:
Staging,Production,Archived상태 관리.
MLflow의 주요 장점
- 프레임워크 독립적:
- TensorFlow, PyTorch, Scikit-learn 등 다양한 프레임워크와 통합 가능.
- 확장성:
- 플러그인 아키텍처를 통해 사용자 정의 기능 추가 가능.
- 재현성:
- 모든 실험 기록과 프로젝트를 통해 실험 재현 가능.
- 배포 편의성:
- 다양한 배포 옵션과 호환.
지난 포스트에서는 minio를 활용한 yolo 학습 코드가 나왔었다. 여기에서 mlflow는 학습 실험에 대한 기록 관리를 한다고 했는데 이어서 자세히 알아보자
MinIO를 활용한 yolo 학습 코드에서 MLflow 파트
import os
import subprocess
import boto3
import mlflow
# ========== 설정 부분 ==========
MINIO_ENDPOINT = "http://127.0.0.1:9000"
ACCESS_KEY = "your-access-key"
SECRET_KEY = "your-secret-key"
BUCKET_NAME = "mybucket"
DATA_PREFIX = "my-yolo-dataset/"
LOCAL_DATA_DIR = "./data" # YOLO 학습용 데이터 저장 디렉토리
DARKNET_PATH = "./darknet"
CONFIG_FILE = "cfg/yolov4.cfg"
DATA_FILE = "data/obj.data"
PRETRAINED_WEIGHTS = "yolov4.conv.137"
EXPERIMENT_NAME = "YOLOv4_Experiment"
USE_MLFLOW = True # 필요시 True/False로 MLflow 로깅 on/off
# ============================
...
def main():
# 1. 데이터 다운로드
download_data_from_minio()
# 2. MLflow 설정
if USE_MLFLOW:
mlflow.set_tracking_uri("http://127.0.0.1:5000") # MLflow tracking server URI (변경 가능)
mlflow.set_experiment(EXPERIMENT_NAME)
# 학습 파라미터 예시
learning_rate = 0.001
batch_size = 64
with mlflow.start_run() if USE_MLFLOW else nullcontext(): # mlflow 사용 안할 경우 dummy context
# 파라미터 로깅
if USE_MLFLOW:
mlflow.log_param("learning_rate", learning_rate)
mlflow.log_param("batch_size", batch_size)
mlflow.log_param("config_file", CONFIG_FILE)
mlflow.log_param("data_file", DATA_FILE)
# 3. Darknet 학습 실행
run_darknet_training()
# 4. 학습 결과 파싱 (mAP 등)
map_value = parse_darknet_log()
if map_value is not None and USE_MLFLOW:
mlflow.log_metric("mAP", map_value)
# 5. 최종 모델 가중치 파일 로깅
final_weights = find_final_weights()
if final_weights and USE_MLFLOW:
mlflow.log_artifact(final_weights, artifact_path="model")
# 필요하다면 기타 결과물(예: confusion matrix 이미지, log 파일)도 로깅 가능
if USE_MLFLOW:
mlflow.log_artifact("training.log", artifact_path="logs")
# mlflow 미사용 시 with 구문에서 예외 처리용 context
from contextlib import contextmanager
@contextmanager
def nullcontext():
yield
if __name__ == "__main__":
main()
상기 코드를 실행시키면 다음과 같이 YOLOv4_Experiment 파트가 생성되고 내부에 실행되고 있는 실험이 보인다.
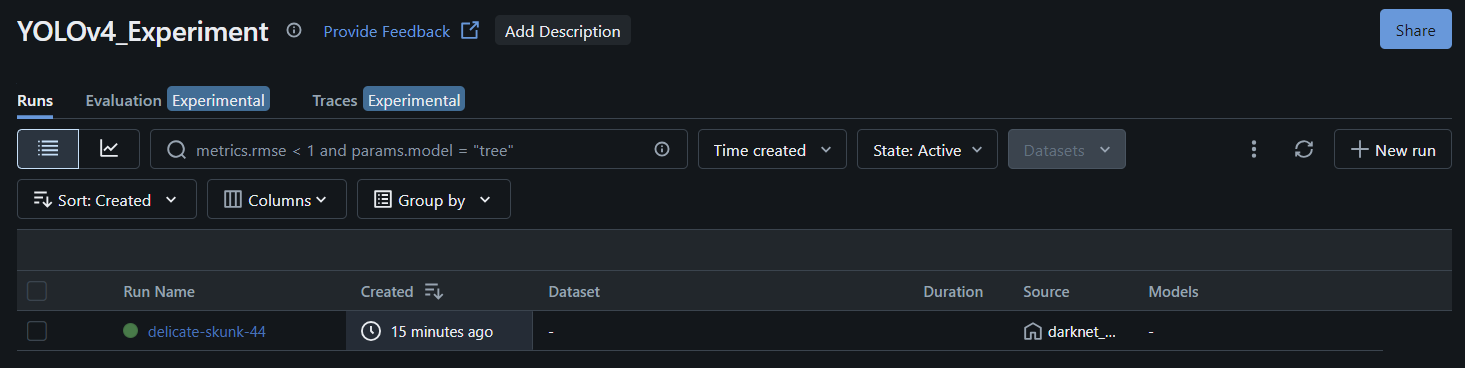
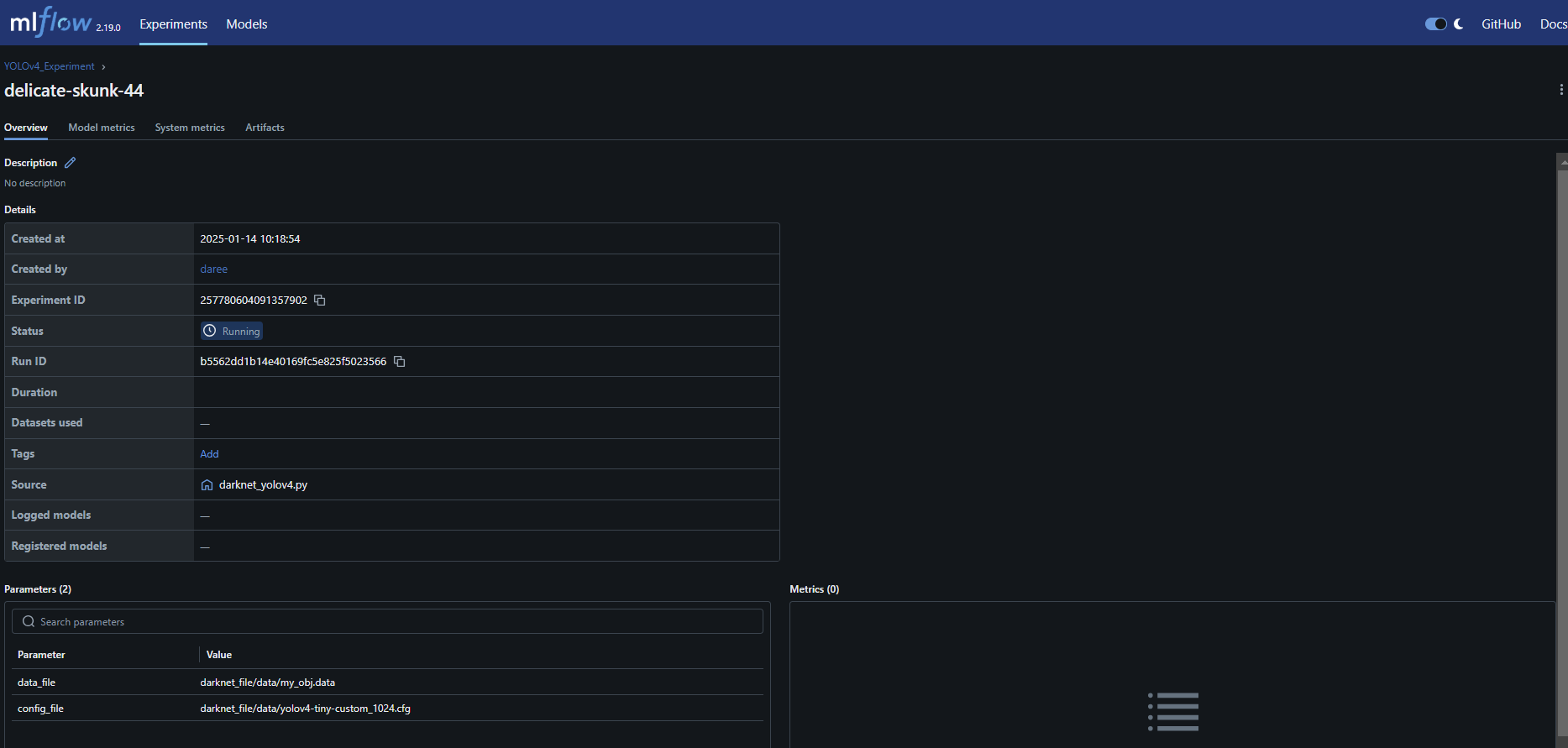
실행되고 있는 실험에 들어가보면 아래와 같이 상세한 정보가 나오고 설정한 실험 파라메터와 metric을 볼 수 있다

따라가기도 벅찬 AI Engineer 겸 부앙단