데이터 조작어(Data Manipulation Language, DML)의 종류
데이터 조작어는 모두 동사로 시작한다.
시작하는 동사에 따라 다음과 같이 4가지 조작어가 있다.
- SELECT-검색
- INSERT-등록
- UPDATE-수정
- DELETE-삭제
SELECT 구문의 기본 문형
 SELECT 옆에 괄호 안에 있는 DISTINCT는 필수가 아니다. 이와 마찬가지로 ALIAS도 필수가 아니다.
SELECT 옆에 괄호 안에 있는 DISTINCT는 필수가 아니다. 이와 마찬가지로 ALIAS도 필수가 아니다.
SELECT 전체 데이터 검색
*은 모든 컬럼을 보여준다.
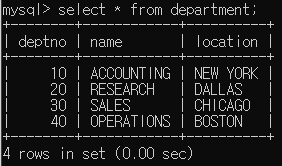 department의 테이블을 볼 수 있다.
department의 테이블을 볼 수 있다.
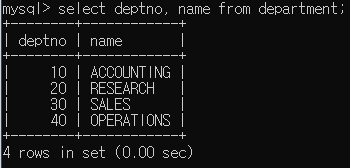
SELECT 특정 컬럼 검색
SELECT 컬럼에 Alias 부여하기
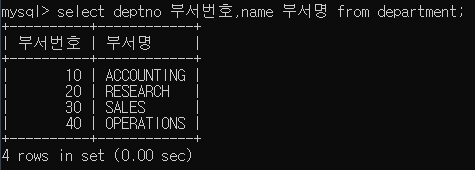
위 사진에서는 Alias를 부여할 때 공백 다음에 별칭을 써주었는데
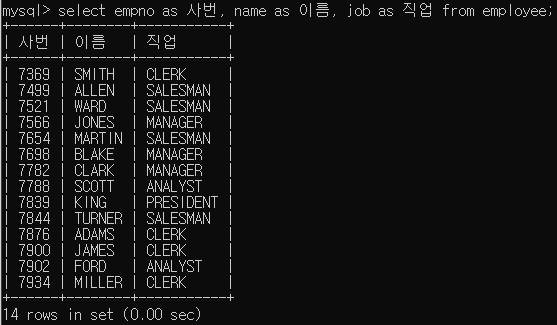 다음과 같이 명시적으로 사용할 수도 있다.
다음과 같이 명시적으로 사용할 수도 있다.
이는 콤마가 아닐 경우에는 from이거나 ALIAS로 생각하게 되므로 명시적으로 쓰지 않고 공백 다음에 사용할 수 있다.
SELECT 컬럼의 합성(Concatenation)
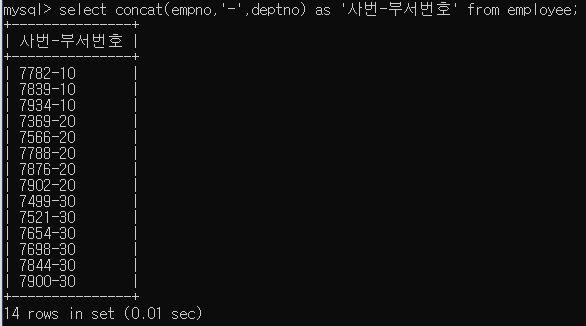
SELECT 중복행의 제거
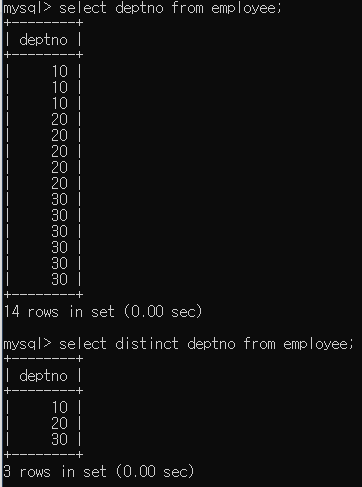
SELECT 정렬하기
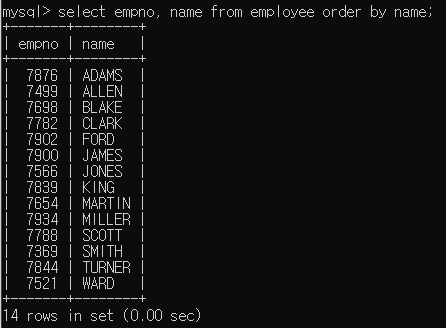 이름을 기준으로 정렬했으며
이름을 기준으로 정렬했으며 order by를 사용할 경우 기본적으로 ascending으로 정렬된다.
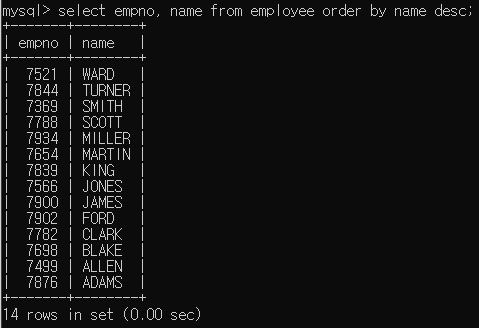
order by [컬럼명, n번째 컬럼] 뒤에 desc`를 붙여 desending으로 정렬할 수 있다.
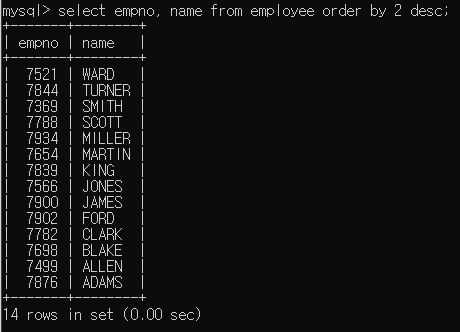 2번째 컬럼을
2번째 컬럼을 desc로 정렬하였다.
SELECT 특정 행 검색 - WHERE절
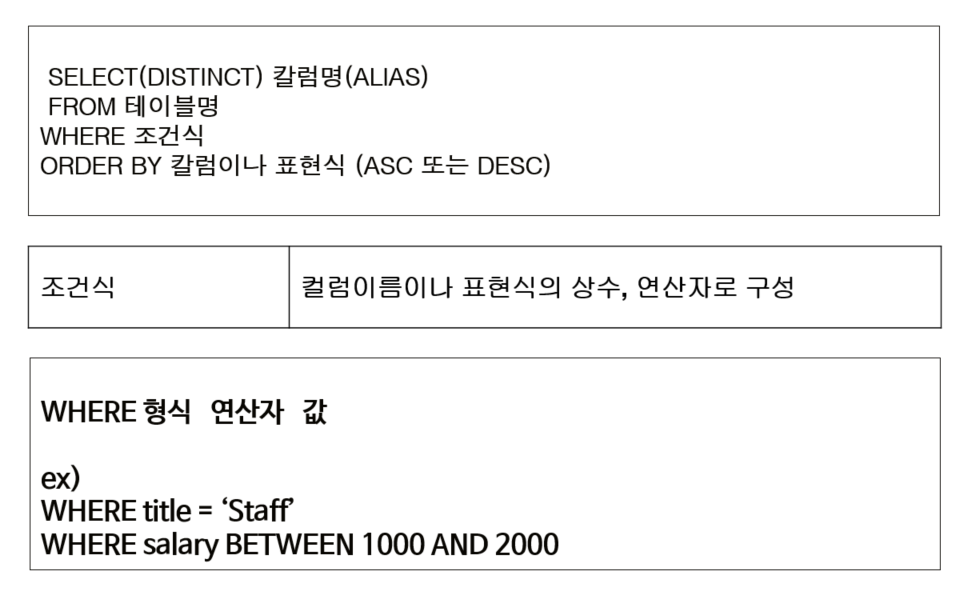
-
산술비교 연산자
employee테이블에서 고용일(hiredate)이 1981년 이전의 사원이름과 고용일을 출력
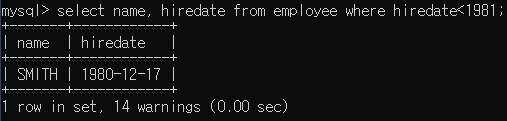
-
논리비교 연산자
employee테이블에서 부서번호가 30인 사원이름과 부서번호 출력
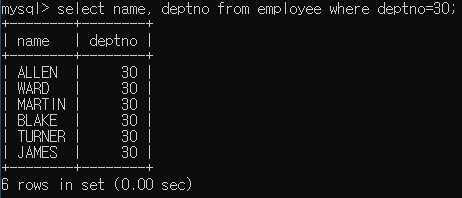
-
IN키워드
employee테이블에서 부서번호가 10또는 30인 사원이름과 부서번호를 출력
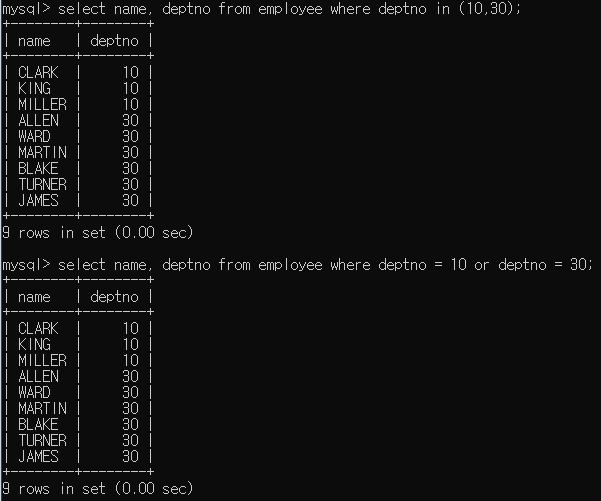 두번째 쿼리는 논리연산자를 통해 같은 결과를 가졌다.
두번째 쿼리는 논리연산자를 통해 같은 결과를 가졌다. -
AND키워드

-
LIKE키워드
와일드 카드를 사용하여 특정 문자를 포함한 값에 대한 조건을 처리
%는 0에서부터 여러 개의 문자열을 나타낸다.
_는 단 하나의 문자를 나타내는 와일드 카드
A로 시작하는 이름을 가진 사원들 출력
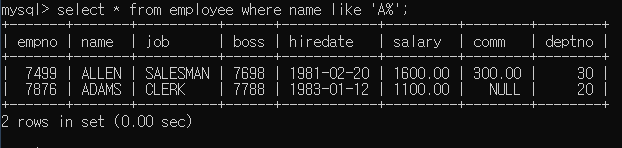
A로 이름이 끝나는 사원들 출력
 없네요.
없네요.
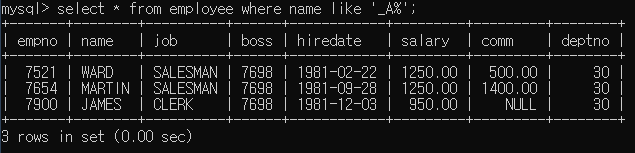
이름 안에 A가 들어가는 사원들 출력
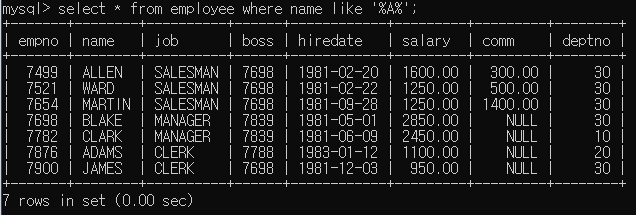
이름의 두번째 스펠링이 'A'인 사원들 출력
SELECT 함수의 사용
UPPER,UCASE,LOWER,LCASE: 문자열을 대문자 혹은 소문자로 나타낸다.
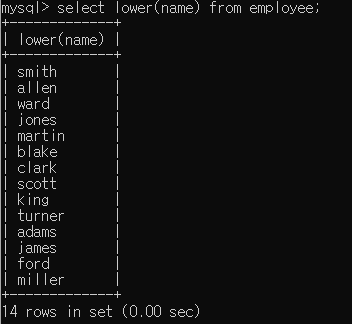
LOWER함수를 이용해서 이름을 소문자로 출력
*SUBSTRING : 문자열을 조건에 맞게 잘라낸다.
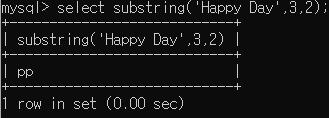
Happy Day 문자열에서 3번째 문자를 시작으로 2개의 문자를 자름
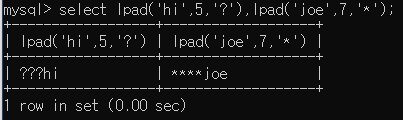
*LPAD, RPAD : 출력 시 공백이 존재할 경우 해당 부분 오른쪽 혹은 왼쪽에 지정한 문자를 채워준다.
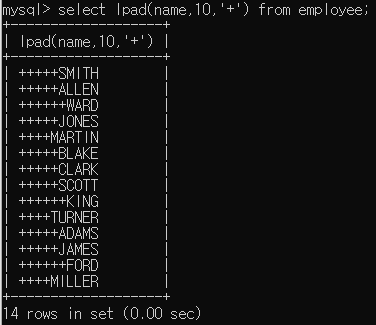
-
TRIME,LTRIM,RTRIM: 공백을 지워준다.
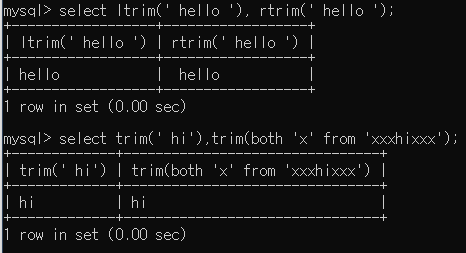
-
ABS(x): x의 절대값을 구해준다. -
MOD(n,m)/%: n을 m으로 나눈 나머지 값을 출력한다. -
FLOOR(x): x보다 크지 않은 가장 큰 정수를 반환한다. BiGINT로 자동 변환한다. -
CEILING(x): x보다 작지 않은 가장 작은 정수를 반환한다. -
POW(x,y),POWER(x,y): x의 y제곱을 반환한다. -
GREATEST(x,y,...): 가장 큰 값을 반환한다. -
LEAST(x,y,...): 가장 작은 값을 반환한다. -
CURDATE(),CURRENT_TIME: 오늘 날짜를 YYYY-MM-DD나 YYYYMMDD 형식으로 반환한다. -
CURTIME(),CURRENT_TIME: 현재 시각을 HH:MM:SS나 HHMMSS 형식으로 반환한다. -
NOW(),SYSDATE(),CURRENT_TIMESTAMP: 오늘 현시각을 YYYY-MM-DD HH:MM:SS나 YYYYMMDDHHMMSS 형식으로 반환한다. -
DATE_FORMAT(date, format): 입력된 date를 format 형식으로 반환한다. -
PERIOD_DIFF(p1, p2): YYMM이나 YYYYMM으로 표기되는 p1과 p2의 차이 개월을 반환한다.
SELECT CAST 형변환

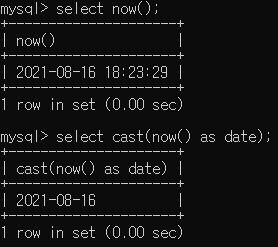
SELECT 그룹함수
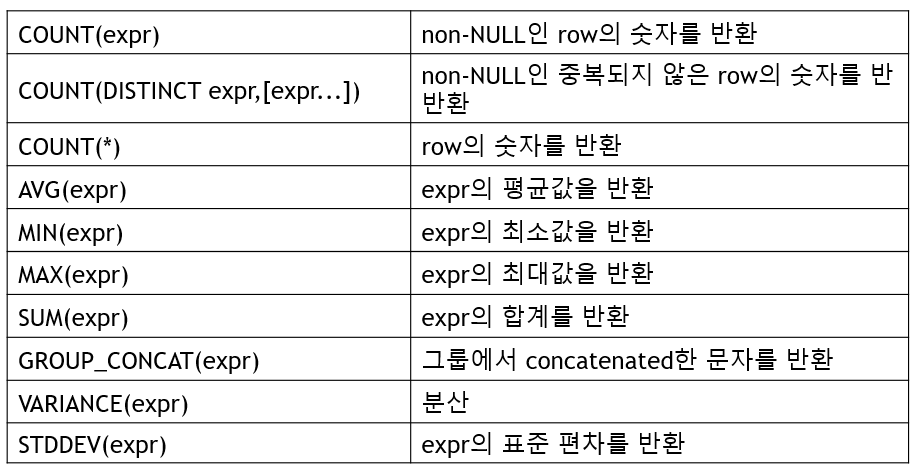
지금까지 본 함수들은 컬럼 하나에 결과가 하나 나오는 단일 함수였고 그룹함수는 여러 개의 컬럼을 가지고 하나의 결과가 나오게 한다.
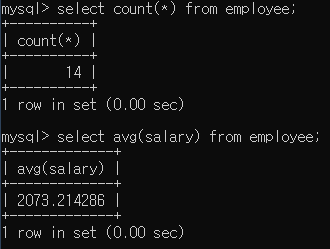 다음과 같이 여러 컬럼을 통해 결과를 보여주는 것을 알 수 있다.
다음과 같이 여러 컬럼을 통해 결과를 보여주는 것을 알 수 있다.
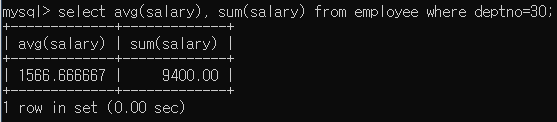
AVG, SUM
employee테이블에서 부서번호가 30인 직원의 급여 평균과 총합계를 출력
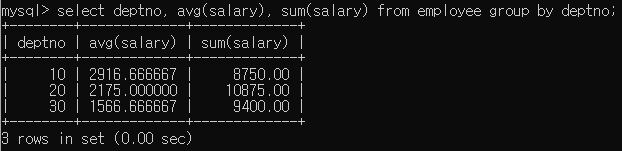
GROUP BY [컬럼명]:컬럼명에 해당하는 컬럼들을 보여준다.
employee테이블에서 부서별 직원의 부서번호, 급여 평균과 총합계를 출력
참고
부스트 코스
