안녕하세요 Cathy입니다! 이번 글에서는 NESS의 아키텍쳐에 대해서 설명드리려고 합니다.
아키텍쳐 구상도
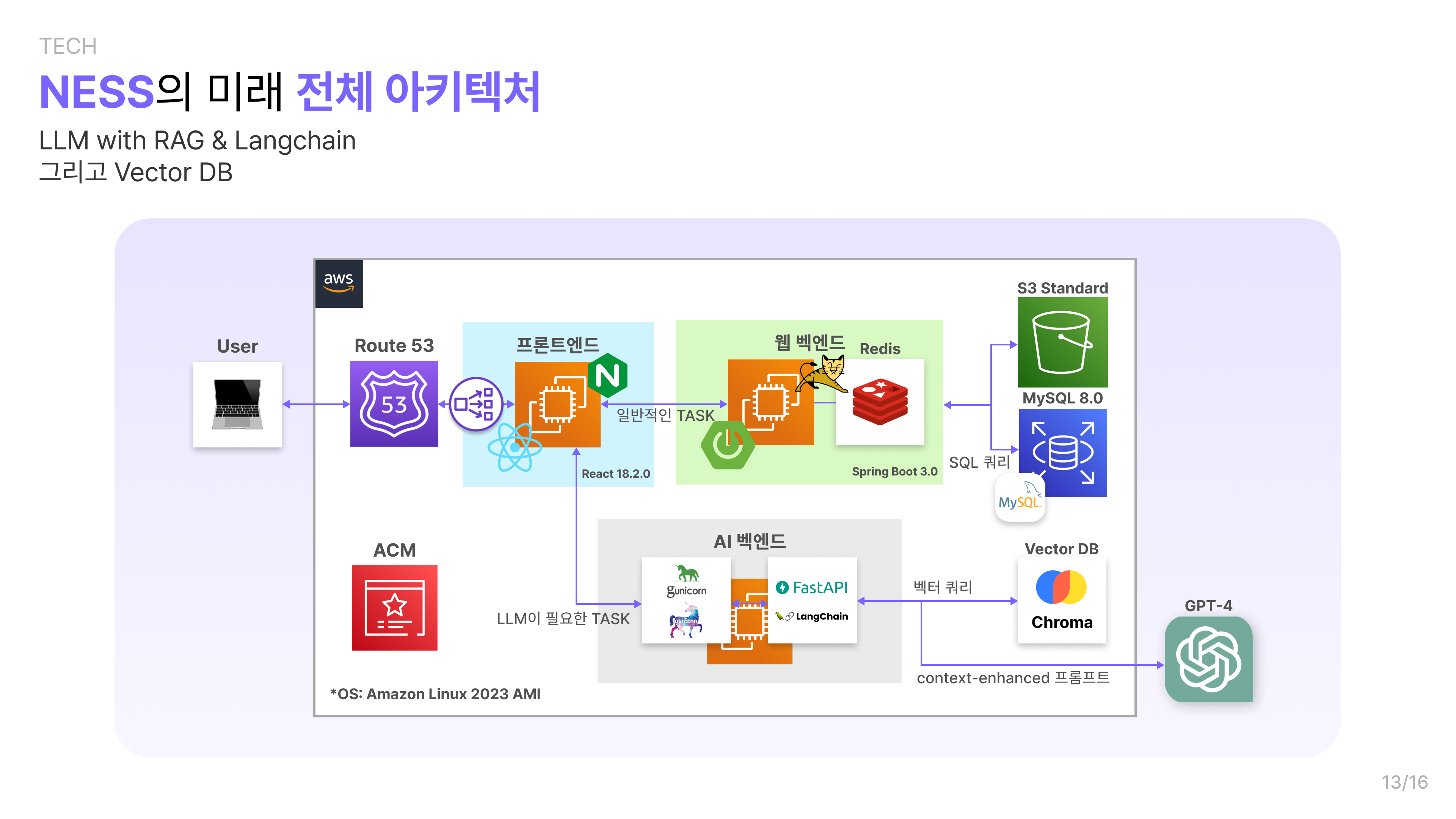
어느 정도 기획이 마무리가 됨에 따라서 서비스의 아키텍쳐도 일차적으로 완성되었습니다. 완성된 아키텍쳐는 아래와 같습니다.
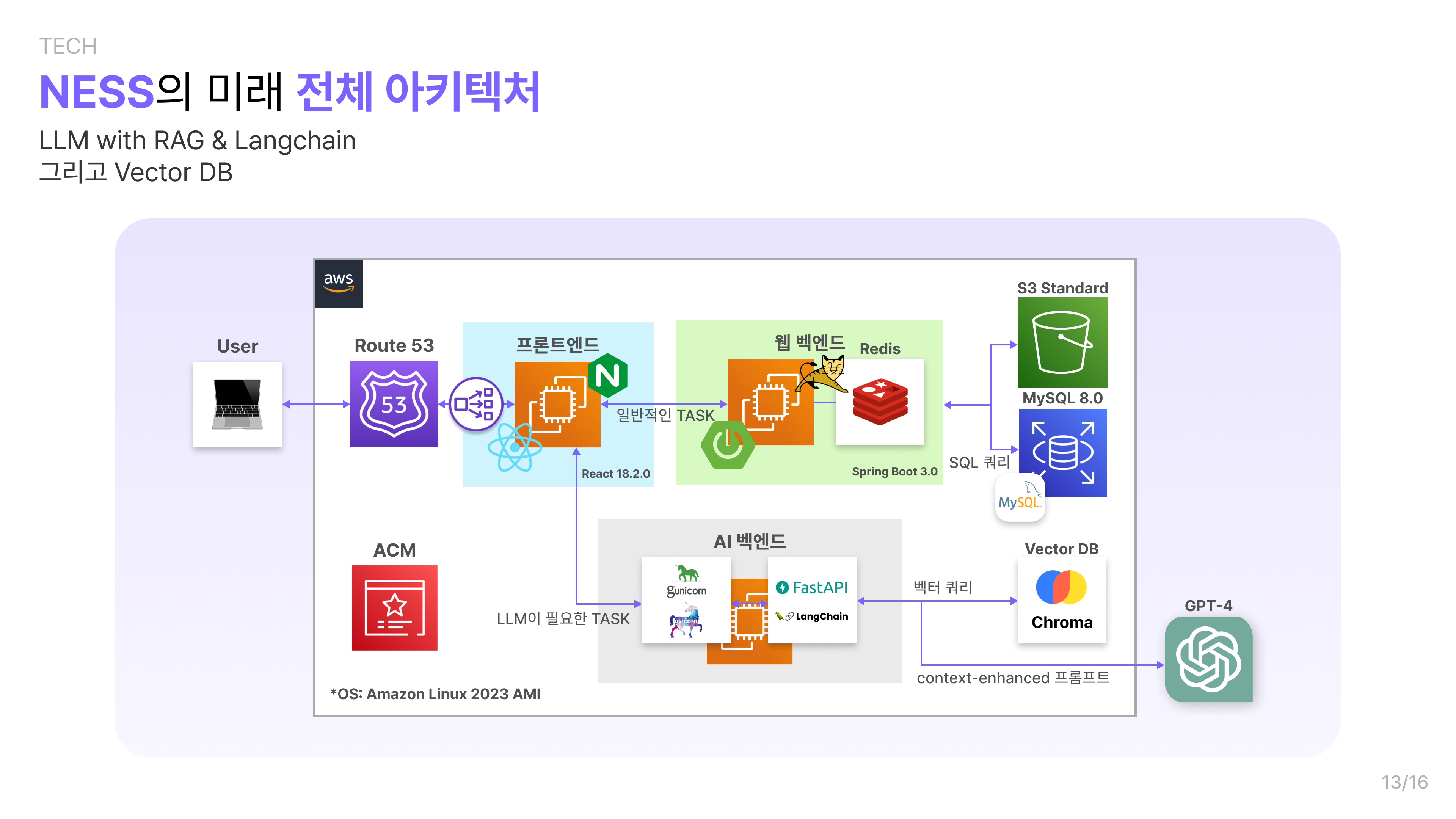
그럼 지금부터 각 요소를 살펴보겠습니다.
기술 요소
⛓️Langchain
Langchain은 LLM 기반 어플리케이션을 구축하게 쉽게 해주는 파이썬 라이브러리입니다. 여러 LLM 모델을 Chain으로 연결하는 것도 가능하고, LLM이 적절한 툴을 쓰게 하는 것도 가능합니다.
혹시 LLM이 수학 계산을 정확하게 하진 못한다는 점을 아시나요? LLM의 기반인 트랜스포머 모델은 가장 정확도 또는 유사도가 높은 문장을 출력해주는 것일 뿐, 정확한 정보를 출력해주진 않습니다. 이를 할루시네이션(Hallucination, AI가 잘못된 정보나 허위 정보를 생성하는 것)이라고 하죠. 유명한 사례로는 '세종대왕 맥북프로 던짐 사건'이 있겠습니다.

그러나 Langchain을 쓴다면 LLM이 수학 도구인 'llm-math'를 사용하게 만들 수 있습니다. 이를 통해서 LLM의 할루시네이션을 줄일 수 있습니다.
from langchain.agents import load_tools
from langchain.llms import OpenAI
llm = OpenAI(temperature=0)
# LLM에게 툴 제공
tools = load_tools(["llm-math"], llm=llm)물론, Langchain은 수학 도구 뿐만 아니라 다른 많은 기능들을 제공합니다. 이렇게 AI 모델을 사용하기 편리하게 만들기 위해서 Langchain을 도입하려고 합니다.
⚡FastAPI
Langchain을 도입함에 따라서 AI 백엔드로는 파이썬 기반 프레임워크가 필요했습니다(물론, Langchain을 쓰지 않더라도 AI를 다루려면 파이썬을 써야 하는 것은 당연합니다). FastAPI는 flask보다는 더 발전된 기능을 가지고 있고, Django보다는 간단한 최신 파이썬 웹 프레임워크라고 할 수 있습니다.

API 문서를 자동 생성해준다는 점, 파라미터 기반 API 입력 설계로 간단하다는 점에서 저희 팀은 FastAPI를 선택했습니다. 물론, 무엇보다 중요한 점은 저희 팀에 Django 개발자가 없고, 그렇다고 Flask를 선택하기에는 AI 백엔드로써는 다소 부족한 점이 많다는 것이 선택의 가장 큰 이유였습니다.
🔵chroma
Chroma는 Vector 기반 데이터베이스입니다. 그렇다면 Vector는 무엇일까요? 이는 백터 임베딩이라고도 하며, 데이터 객체의 수치 표현입니다.
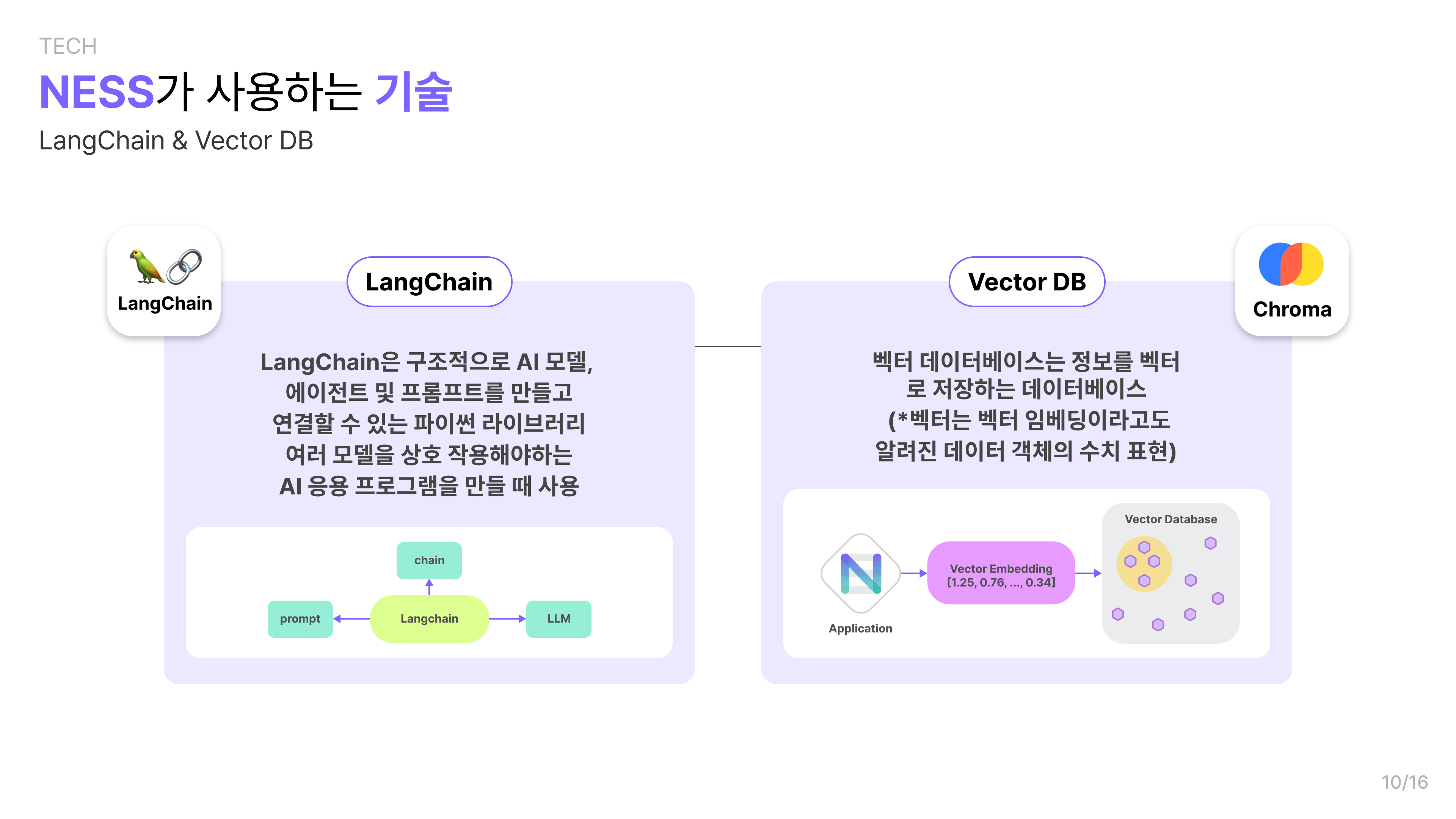
예를 들어, 현재 입력한 채팅 내용과 비슷한 과거의 채팅 내역을 찾아주고 싶다고 가정해보겠습니다. RDB에 String 값으로 채팅 내역을 저장한다면, 어떻게 비슷한 과거 채팅 내역을 찾을 수 있을까요? 유사도 알고리즘을 따로 구현해주어야 할까요? ML/AI 모델로 유사도를 검사해야 할까요?
Vector DB는 자산(채팅 내역)의 의미와 컨텍스트를 백터로 저장하기 때문에 이러한 문제를 쉽게 해결할 수 있습니다. Vector DB를 통해 인접 데이터 포인트(즉, 유사한 과거 채팅 내역)을 쉽게 찾아내고 그 결과를 반환할 수 있기 때문입니다.
저희 팀에서는 사용자 맞춤형 인공지능 비서를 만들고자 하는 만큼, 사용자의 과거 채팅 내역 등의 정보를 LLM에 프롬프트와 같이 전달해야 합니다. 따라서 Vector DB를 도입하기로 결정했습니다.
🤖RAG Based LLM
위에서 언급한 LangChain, Vector DB와 함께 다음과 같은 패턴을 구현할 수 있습니다.
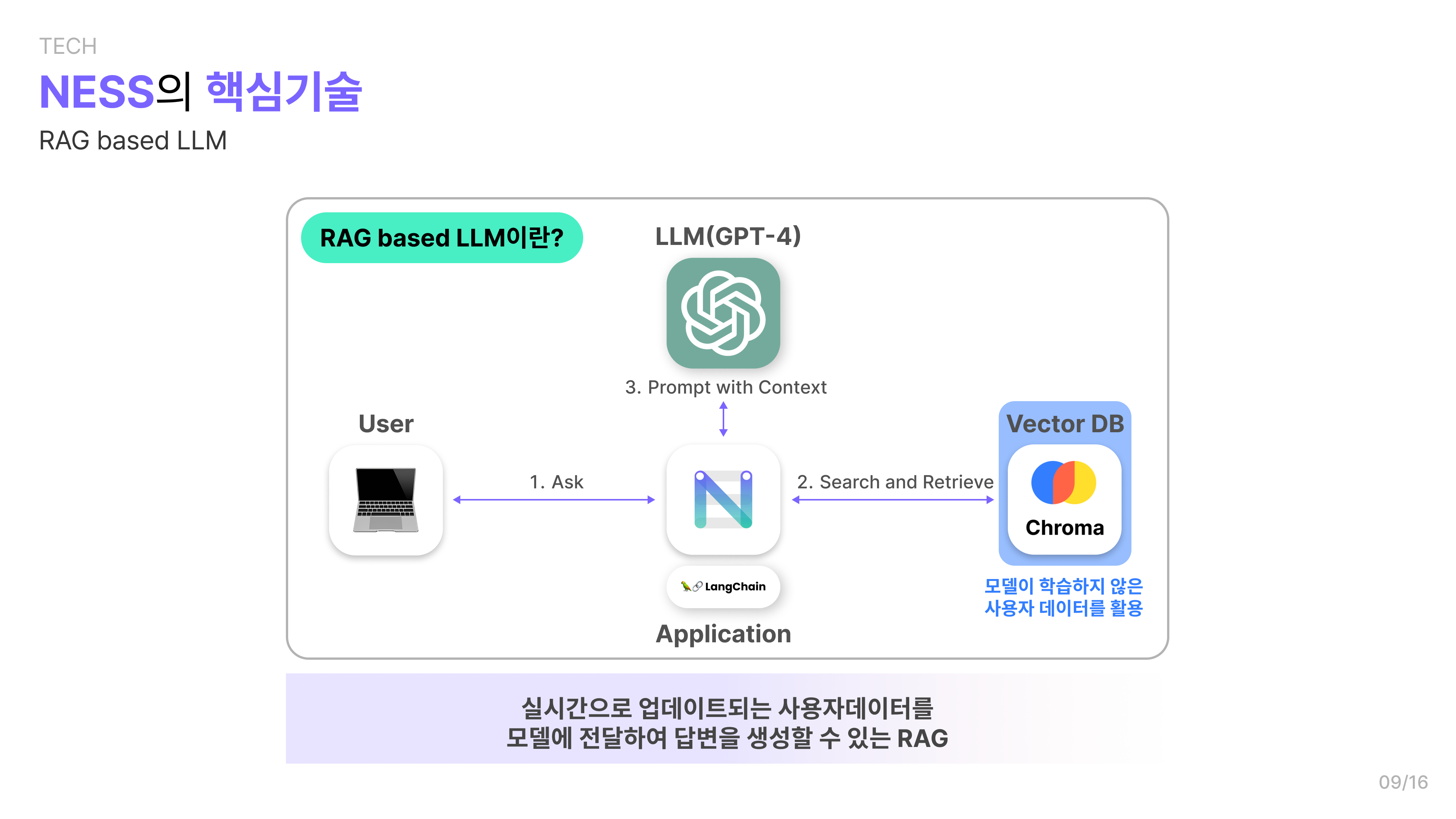
LLM에 프롬프트를 보내기 전에, 먼저 1) 관련 데이터를 Vector DB에 검색하고, 2) 관련 데이터를 프롬프트와 함께 LLM에 요청하는 것입니다. 이러한 패턴을 RAG(Retrieval-Augmented Generation)라고 합니다.
저희 팀에서는 사용자가 프롬프트를 보내면, 1) 먼저 Vector DB에서 관련 사용자 데이터를 검색하고, 2) 그 결과와 프롬프트를 함께 LLM에 전송하여, 3) 사용자 맞춤형 인공지능 비서를 만들기 위해서 위와 같은 패턴을 선택하게 되었습니다.
RAG와 관련된 더욱 자세한 설명으로는 저희 팀의 AI 엔지니어이신 chaen님(별명: 루비언니)이 작성하신 티스토리 글을 첨부합니다.
📝 RAG이란?: https://chaerryos.tistory.com/3
🪣S3 Standard
S3는 AWS의 데이터 가용성, 보안 및 성능을 제공하는 객체 기반 스토리지 서비스입니다. 저희 서비스에서는 이미지 파일 등을 저장할 때 사용할 예정입니다.
그렇다면 왜 S3일까요? 알다시피, AWS에는 EBS라는 블록 기반 스토리지도 있습니다. EBS는 EC2를 생성할 때 자동으로 부착되는 SSD입니다. 왜 블록 스토리지를 쓰지 않을까요?
가장 큰 이유는 S3 버킷의 경우 무한 확장이 가능하다는 점입니다. 컴퓨터를 사용할 때 가끔 저장공간이 부족해 문제가 생기셨던 경험이 있다면 이해가 쉬울 것 같습니다. 그러나 S3 버킷은 무한확장이 가능하기 때문에 위와 같은 문제를 고민할 필요가 없습니다. 또한, AWS S3에서는 각 객체(즉, 이미지)에 대한 URL을 생성해줍니다. 이 URL만 DB에 저장해준다면 사용자들은 하나의 엔트포인트로 이미지에 접근하는 것이 가능해집니다.
저희는 이 중에서 자주 액세스하는 데이터를 위한 클래스인, Standard Class를 사용하려고 합니다.
🛣️Route 53
Route 53은 AWS에서 제공하는 DNS입니다. DNS란 도메인 이름에 대한 적절한 IP 주소를 알려주는 서버입니다.
저희가 일반적으로 알고 있는 'google.com'과 같은 이름은 도메인 이름이라고 합니다. 그러나 구글의 서버 IP 주소는 따로 있습니다. 원래대로라면 IP 주소를 입력해야 서버에 접근 가능한 것이지만, DNS를 통해 기억하기 쉬운 도메인 이름만 주소창에 입력해주면 적절한 IP 주소를 알 수 있습니다.
이러한 기능을 하는 것이 바로 AWS의 Route 53입니다. 간단하게 말해서, 저희 서비스에서는 저희 도메인 이름과 EC2의 IP 주소를 변환하기 위해서 Route 53을 사용합니다.
🤐ACM
저희 서비스에서는 AI 모델을 쓰는 만큼 보안이 중요합니다. 보안을 위해 HTTPS 프로토콜을 쓰기 위해서 AWS의 ACM을 사용하려고 합니다. ACM은 쉽게 말해서 보안 인증서로, 이 인증서를 통해서 secure한 HTTP 프로토콜, 즉 HTTPS를 사용할 수 있습니다.
마무리
여기까지 해서 NESS의 1차 아키텍처가 구상되었습니다. 물론, 아직 전체를 테스트한 것은 아니기 때문에 얼마든지 변경될 수는 있습니다. 그러나 코어 기능인 RAG 패턴은 반드시 구현하는 것이 이번 프로젝트의 목표입니다.
그럼, 아키텍쳐가 새롭게 변경되면 다시 포스팅으로 돌아오겠습니다!
👩🏻💻 자기 소개
안녕하세요! 팀 re:cording에서 팀장을 맡고 있는 cathy라고 합니다. 팀 re:cording은 “사람들이 정말 쓸만한 서비스를 만들고 싶다”라는 열정 아래에서 만들어졌습니다. 좋은 서비스를 만들기 위해서 저희 팀은 끊임없이 다시 코딩하고, 새롭게 코딩하고, 또 새로운 것을 코딩하려 합니다.
