
1. 자바의 배열이 가졌던 한계
자바에서 제공하고 있는 배열은 자바스크립트의 배열과 다르게 그 한계점을 명확히 드러내고 있는데요.
고정적인 길이, 동일한 데이터 타입만 저장, 요소의 검색 및 삭제, 추가 기능의 제한 등의 생각보다 비효율적인 모습도 가지고 있습니다.
그래서 자바에서는 이러한 자료 구조의 전체적인 흐름을 보다 원활히 하기 위해 사용자에게 컬렉션 을 제공하는데요.
이러한 컬렉션은 기본 배열과는 다르게 출력 부터 간단히 할 수 있다는 이점을 가지고 있기 때문에 자바에서는 배열을 사용할 때 거의 특수한 경우가 아니라면 컬렉션을 사용한 배열 관리를 해주고 있습니다.
- 배열 출력 예시
public static void main(String[] args) { // ArrayList 컬렉션을 이용한 배열 생성 List<Integer> list1 = new ArrayList<Integer>(); // 일반적인 배열 생성 int[] list2 = new int[3]; // 값 할당 list1.add(1); list1.add(2); list1.add(3); list2[0] = 1; list2[1] = 2; list2[2] = 3; // 출력 : [I@7d6f77cc (변수명만 써주면 배열의 주소값을 출력하기 때문에 toString을 사용해야함) System.out.println(list2.toString()); // 출력 : [1, 2, 3] (toString을 사용하지 않아도 자동으로 호출되어 배열 안의 요소가 출력되므로 그냥 변수명을 적어줘도됨) System.out.println(list1); }
- 인덱스 범위 예시
public static void main(String[] args) { List<Integer> list1 = new ArrayList<Integer>(); // 정적 배열의 길이는 3 int[] list2 = new int[3]; list1.add(1); list1.add(2); list1.add(3); list1.add(4); list1.add(5); // 넣고자 하는 데이터는 배열의 길이를 넘어선 다섯개. list2[0] = 1; list2[1] = 2; list2[2] = 3; list2[3] = 4; list2[4] = 5; // 기본적인 배열은 정해진 배열의 길이 이상으로 데이터를 넣는 것이 불가능 하므로 ArrayIndexOutOfBoundException 에러가 발생 System.out.println(list2); // ArrayList는 배열의 가용 범위에 제한이 없으므로 값을 언제든 넣을 수 있음 System.out.println(list1); }
대표적으로 List, Set, Map 컬렉션이 존재하며, 순서 여부 및 중복 여부 등에 따른 차이를 보이긴 하지만 기존의 배열과는 다르게 가변적인 길이와 서로 다른 데이터 타입 저장 가능, 요소의 검색, 삭제, 추가의 용이, 쉬운 배열 출력 및 제네릭 기능 제공
등 기존 배열과의 차이점에 대해서는 공통적인 요소로 가지고 있습니다.
자바의 기존 배열과 컬렉션 클래스에 대해서 그 차이를 비교해보며 클랙션의 주요 특징들을 살펴보겠습니다.
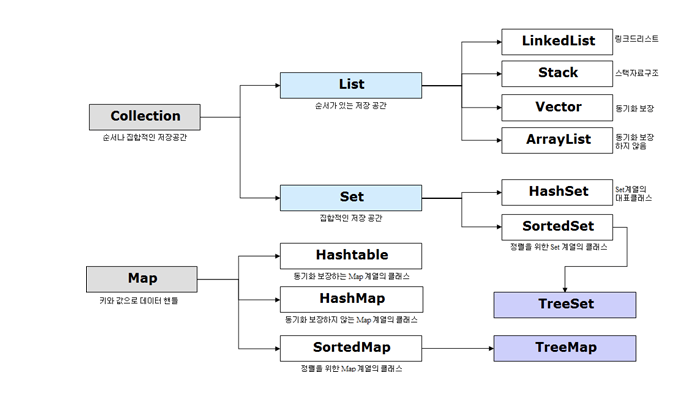
다양한 컬렉션 가계도, 참고로 동기화 보장이란 멀티 스레드 환경에서 데이터의 일관성을 유지하기 위한 메커니즘을 제공 받는 것을 의미한다고 합니다.
(자료 출처 : https://velog.io/@jaeyunn_15/DataStructure-Java-Collections-List-Set-Map)
2. List 컬렉션
컬렉션에서 제공하고 있는 List 컬렉션은 인덱스에 의한 순서가 있는 객체 요소로 구성된 데이터 집합
입니다. 인덱스를 이용하여 접근하는 것이 가능하며 요소의 중복 저장이 가능
하다는 특징을 가지고 있습니다.
대표적으로 사용되는 클래스는 ArrayList가 있으며, 사용법은 아래와 같습니다.
// 리스트 선언 List list = new ArrayList(); // 요소 추가 list.add("apple"); list.add(2); list.add("orange"); list.add(false); // 리스트 길이 확인 int listLength = list.size(); // 특정 위치의 요소 대체 list.set(1, 20); // 특정 위치의 요소 획득 String fruit = list.get(0) // 특정 위치의 요소 여부 확인 (대소문자 구분) boolean containsBanana = list.contains("Apple"); // false 반환 // 특정 위치의 요소 삭제 (대소문자 구분 / 요소를 직접 넣거나 인덱스를 삽입할 수 있음, 특히 해당 객체의 요소가 숫자인지, 인덱스인지에 대한 확인 코드는 사용자가 직접 로직을 구현해야함.) list.remove("banana"); // 리스트의 모든 요소 제거 list.clear();
이러한 ArrayList 단점이라고 한다면, 기존 객체의 삽입 및 새로운 객체의 삽입시 작업 되는 객체를 기준으로 앞에 있는 기존의 객체들의 인덱스는 앞당겨지거나, 밀려나 변경된다는 점이 있는데,
이러한 점을 배제하고 싶다면 삽입 및 삭제 작업시 앞 뒤의 객체 연결 링크만 변경되어 ArrayList보다 효율적인 LinkedList의 사용을 고려할 수 있습니다.
3. Set 컬렉션
Set 컬렉션은 List 컬렉션과 다르게 인덱스를 사용하지 않습니다.
그래서 객체 간의 순서 또한 유지되지 않는데요.
더욱이 객체의 내용을 중복해서 저장할 수 없으며, 하나의 null 만을 저장
할 수 있습니다. 그래서 이를 두고 사람들은 수학의 집합 특성을 가지고 있다고 말하기도 하는데요.
정리하자면 Set은 'ㄹ랜덤한, 중복되지 않은 내용물을 담은 박스'
라고 보시면 되며, 이들을 구별하는 대에는 해시 코드를 사용하여 중복 여부를 구별하는거죠.
그리고 이러한 Set 컬렉션 에서 가장 많이 사용되는 클래스는 HashSet 클래스가 되겠습니다.
이 클래스는 ArrayList의 메서드와 사용법이 거의 동일하며, 중복 여부를 허용하지는 않으나 대소문자를 구분하기 때문에 사용시 주의를 해야합니다.
import java.util.HashSet; import java.util.Set; public class HashSetExample { public static void main(String[] args) { // HashSet 생성 Set<String> hashSet = new HashSet<>(); // 요소 추가 hashSet.add("apple"); hashSet.add("banana"); hashSet.add("orange"); // 요소 중복 추가 시도 hashSet.add("banana"); // 중복된 요소이므로 추가되지 않음 hashSet.add("Banana"); // 대소문자를 구분하지 않으므로 추가 가능 hashSet.add("BANANA".toLowerCase()); // 대소문자를 구분하지 않으므로 할당 할 때 소문자로 변환하여 할당함으로 대소문자 구분 이슈를 해결 // 요소 출력 System.out.println("HashSet: " + hashSet); // 출력: [orange, apple, banana] // 요소 개수 확인 System.out.println("Size of HashSet: " + hashSet.size()); // 출력: 3 // 요소 포함 여부 확인 System.out.println("Contains 'banana': " + hashSet.contains("banana")); // 출력: true System.out.println("Contains 'grape': " + hashSet.contains("grape")); // 출력: false // 요소 제거 hashSet.remove("banana"); // 요소 제거 후 출력 System.out.println("HashSet after removal: " + hashSet); // 출력: [orange, apple] } }
그리고 이러한 HashSet을 이용해 중복 여부를 체크하는 간단한 코드는 다음과 같습니다.
import java.util.HashSet; import java.util.Set; public class HashSetExample { public static void main(String[] args) { // 중복된 요소를 포함하는 배열 String[] fruits = {"apple", "banana", "orange", "apple", "banana"}; // 중복된 요소 제거를 위한 HashSet 생성 Set<String> uniqueFruits = new HashSet<>(); // add 메서드로 단일 개체들을 저장 hashSet.add("cherry"); hashSet.add("cherry"); // 매개변수를 두 개 전달하면 첫번째는 인덱스 자리가, 두번째는 기존의 값을 대체할 매개변수가 들어갑니다. hashSet.add(3,"Pineapple"); // enhanced-for문을 이용해 배열의 모든 요소를 HashSet에 추가 for (String fruit : fruits) { uniqueFruits.add(fruit); } // 중복이 제거된 요소를 출력 System.out.println("Unique fruits: " + uniqueFruits); } }
Iterator (반복자)
HashSet에는 인덱스가 없으므로 객체에 직접적인 접근을 지원하는 get 메서드 또한 없는데요. 그래서 특정 객체의 존재 여부 확인은 주로 contains를 사용하고, 데이터 구조의 순회하며 특정 객체를 추출하는 방법으로는 iterator (요소 순회 메서드)와 enhanced for문을 사용하는데요.
이때 사용되는 Iterator는 인덱스가 없는 HashSet에 인덱스 접근이 가능하도록 도와주는 클래스라고 생각하셔도 되는데, 이때 Iterator는 생성 후 사용을 마친 뒤에는 일회용이라 추가 접근이 어려우므로, 재생성이 필요하다는 점을 가지고 있습니다.
물론 HashSet에서만 사용할 수 있는건 아니고 다른 컬렉션에도 사용할 수 있으나, 기본적으로 반복자는 순회가 불가능한 개체를 순회가 가능하도록 해주는 목적을 가지고 있기 때문에 HashSet에 대표적으로 사용됩니다.
// 1. iterator를 이용한 데이터 구조 순회 방법 import java.util.HashSet; import java.util.Iterator; import java.util.Set; public class HashSetExample { public static void main(String[] args) { List<String> list = new ArrayList<>(); Iterator itr = list.iterator(); Set<String> hashSet = new HashSet<>(); hashSet.add("apple"); hashSet.add("banana"); hashSet.add("orange"); // Iterator를 사용하여 HashSet의 모든 요소를 반복 Iterator<String> iterator = hashSet.iterator(); while (iterator.hasNext()) { String element = iterator.next(); System.out.println(element); } // 이 이후에는 iterator를 사용 못하므로 추가적인 작업이 필요할 때 새로운 iterator를 생성해야 합니다. } }
4. Map 컬렉션
Map 컬렉션은 자바스크립트의 객체와 가장 유사한 구조이며, 키(key)와 값(value)을 한 쌍
으로 가지고 있기에 키는 중복을 허용할 수 없지만, 값은 중복 허용이 가능한 구조입니다.
이러한 Map 컬렉션의 대표 클레스는 HashMap가 존재하며, JSON 형식으로 이루어진 자바스크립트의 객체의 간단한 출력 및 접근법과는 다르게 꽤나 복잡한 사용법을 가지고 있습니다. (심지어 객체의 내용 전부를 간단하게 출력할 수 있는 자바스크립트에 반해, 자바에서 객체의 내용을 전부 출력하려면 배열을 순회부터 해야합니다.)
특히 Map은 키와 값을 쌍으로 다룬 배열이다보니, List나 Set의 메서드 add(키와 쌍을 저장), remove(키를 제거하고 값을 반환), size(키와 값, 쌍으로 존재하는 요소의 개수 반환)의 메서드 동작 방식이 살짝 다르고, 또 위의 두 클래스에는 없는 Map 클래스만의 메서드 또한 존재합니다. (아래의 예시 코드에서 다루었습니다.)
import java.util.HashMap; import java.util.Map; public class Main { public static void main(String[] args) { // Map 객체 생성 (제네릭 타입은 키의 타입과 값의 타입을 각각 작성해 줍니다.) Map<String, Integer> map = new HashMap<>(); // 요소 추가 (키와 값을 차례대로 입력) map.put("apple", 10); map.put("banana", 20); map.put("orange", 30); // 값 조회 (키 입력) int appleCount = map.get("apple"); System.out.println("Number of apples: " + appleCount); // 요소 수정 (키와 값 입력) map.put("apple", 15); // 값 삭제 (키 입력) map.remove("banana"); // 모든 키-값 쌍 출력 for (Map.Entry<String, Integer> entry : map.entrySet()) { String key = entry.getKey(); int value = entry.getValue(); System.out.println("Key: " + key + ", Value: " + value); } // 특정 키가 존재하는지 확인 String keyToCheck = "apple"; if (map.containsKey(keyToCheck)) { System.out.println(keyToCheck + " exists in the map."); } else { System.out.println(keyToCheck + " does not exist in the map."); } // 특정 값이 존재하는지 확인 int valueToCheck = 30; if (map.containsValue(valueToCheck)) { System.out.println(valueToCheck + " exists in the map."); } else { System.out.println(valueToCheck + " does not exist in the map."); } } // 모든 값 출력 Collection<Integer> values = map.values(); System.out.println("All values: " + values); // 모든 키 출력 Set<String> keySet = map.keySet(); System.out.println("All keys: " + keySet); // entrySet을 이용하여 각 키-값 쌍을 순회하며 출력 (직접적으로 키와 값 전체를 출력하는 메서드는 없음.) Set<Entry<String, Integer>> entrySet = map.entrySet(); for (Entry<String, Integer> entry : entrySet) { String key = entry.getKey(); int value = entry.getValue(); System.out.println("Key: " + key + ", Value: " + value); } }
