
내용 출처
KOCW 반효경 교수님 <운영체제> 강의
책 <운영체제와 정보기술의 원리>
반효경 교수님의 <운영체제> 강의 내용을 기반으로 정리했으며,
교수님의 저서 <운영체제와 정보기술의 원리>에서 추가할 만한 내용을 이와 같은 인용문 형식으로 추가함.
CPU Burst & I/O Burst
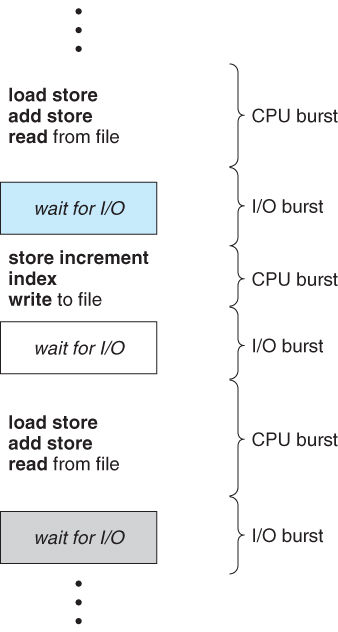
- CPU burst : CPU가 일을 수행하는 상태
- I/O burst : I/O 작업을 기다리는 상태
Add 명령 : CPU 내의 레지스터에 있는 두 값을 더해 레지스터에 저장
Load 명령 : 메모리에 있는 데이터를 CPU로 읽어들임
Store 명령 : CPU에서 계산된 결과값을 메모리에 저장
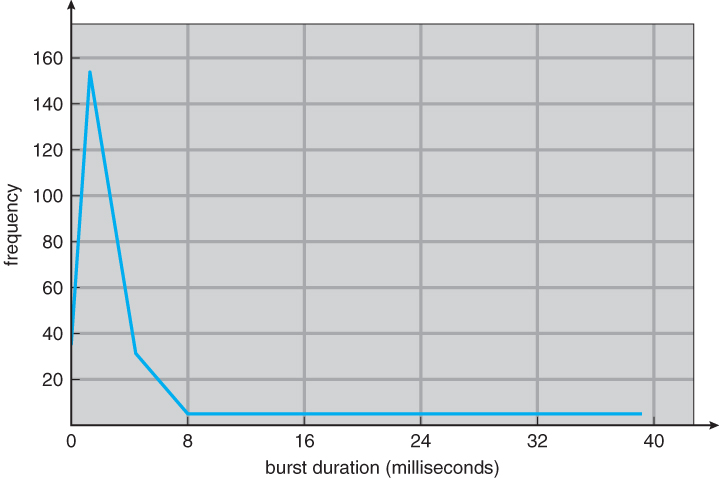
CPU Burst 그래프 | 그림 출처
여러 종류의 작업이 섞여 있기 때문에 CPU 스케줄링이 필요하다.
-
interactive job에게 적절한 response를 제공해야 한다.
-
CPU와 I/O 장치 등 시스템 자원을 골고루 효율적으로 사용해야 한다.
-
I/O bound process
I/O 요청이 빈번해 CPU burst가 짧게 나타나는 프로세스 -
CPU bound process
I/O 작업을 거의 수행하지 않아 CPU burst가 길게 나타나는 프로세스
CPU 스케줄러 & 디스패처
CPU 스케줄러가 ready queue에서 CPU를 줄 프로세스를 고르고, 디스패처가 선택된 프로세스에게 실제로 CPU 제어권을 넘긴다.
-
CPU Scheduler
- ready 상태의 프로세스 중에서 이번에 CPU를 줄 프로세스를 고른다.
-
Dispatcher
- 문맥 교환 : CPU의 제어권을 CPU 스케줄러에 의해 선택된 프로세스에게 넘긴다.
디스패치 지연시간 (dispatch latency)
디스패처가 하나의 프로세스를 정지시키고 다른 프로세스에게 CPU를 전달하기까지 걸리는 시간
주의) CPU 스케줄러라는 독립된 하드웨어 혹은 소프트웨어가 있는 것이 아니라, 운영체제 내에 CPU 스케줄링을 하는 코드가 있고, 이를 CPU 스케줄러라고 부르는 것이다. 디스패처도 마찬가지다.
[CPU 스케줄링이 필요한 경우]
- Running -> Blocked (ex. I/O 요청하는 시스템 콜)
- Running -> Ready (ex. 할당 시간 만료로 timer interrupt)
- Blocked -> Ready (ex. I/O 완료 후 인터럽트)
- Terminate
-
nonpreemptive(비선점형)
CPU를 획득한 프로세스가 스스로 CPU를 반납하기 전까지는 CPU를 빼앗기지 않는 방법 -
preemptive(선점형)
프로세스가 CPU를 계속 사용하기를 원하더라도 강제로 빼앗을 수 있는 스케줄링 방법
(nonpreemptive/preemptive 용어는 꼭 알아둘 것!)
성능 척도
- 시스템 입장에서의 성능 척도
-
CPU Utilization (이용률)
전체 시간에서 CPU가 놀지 않고 일한 시간의 비율 -
Throughput (처리량)
주어진 시간 동안 몇 개의 작업을 완료했는가이용률과 처리량이 높을수록 시스템 입장에서 좋은 스케줄링 알고리즘이다.
-
프로세스 입장에서의 성능 척도
기준 : 특정 프로세스의 시작 ~ 종료까지의 시간이 아니라
이 프로세스가 CPU를 쓰러 들어왔다가 I/O를 하러 나갈 때까지의 시간
(한 번의 CPU burst 동안)
-
Turnaround Time (소요 시간)
CPU를 쓰러 들어와서 다 쓰고 나갈 때까지 걸리는 시간 (기다린 시간 포함) -
Waiting Time (대기 시간)
ready 큐에서 CPU를 쓰기 위해 기다린 시간 (순수하게 기다린 시간) -
Response Time (응답 시간)
처음으로 CPU를 얻기까지 걸린 시간
[대기 시간 vs 응답 시간]
선점형 스케줄링에서는 CPU를 얻었다 뺏기고를 반복할 수 있다. 그렇다면 여러 차례 기다리게 될 것이다. 여러 번 기다린 시간을 모두 합친 것이 Waiting Time이고, 처음 CPU를 얻기까지 기다린 시간이 Response Time이다.
FCFS 알고리즘
First-Come First-Served : 먼저 온 순서대로 처리한다. (nonpreemptive)
문제점 : Convoy Effect
긴 프로세스가 먼저 와서 짧은 프로세스의 대기 시간이 길어지는 현상
SJF 알고리즘
Shortest-Job-First : CPU burst time이 가장 짧은 프로세스를 가장 먼저 스케줄링한다.
2가지 방식
-
Nonpreemptive
일단 CPU를 잡으면 이번 CPU burst가 완료될 때까지 CPU를 선점당하지 않는다. -
Preemptive->Shortest Remaining Time First(SRTF)
현재 수행중인 프로세스의 남은 burst time보다 더 짧은 CPU burst time을 가지는 새로운 프로세스가 도착하면 CPU를 빼앗는다.
평균 Waiting Time을 최소화하는 최적 알고리즘이다.
문제점 1 - starvation
CPU 사용시간이 긴 프로세스는 영원히 CPU를 사용하지 못하게 될 수 있다.
문제점 2 - CPU 사용 시간을 미리 알 수 없다.
단, 과거의 CPU burst time을 통해 CPU 사용 시간을 추정할 수는 있다. 주로 exponential averaging을 사용한다. 과거의 CPU burst time을 t1, t2, t3...이라고 할 때, 가장 최근의 것일수록 더 많은 가중치를 두는 방식으로 평균을 낸다.
[exponential averaging 관련 글]
Exponential averaging for SJF CPU scheduling
우선순위 스케줄링
highest priority를 가진 프로세스에게 우선적으로 CPU를 할당한다.
보통 우선순위가 가장 높은 프로세스를 가장 작은 정수로 표현한다.
Nonpreemptive한 방식과 Preemptive한 방식이 있다.
SJF 스케줄링도 우선순위 스케줄링의 일종이다.
(우선순위의 기준 : 예측된 CPU 사용 시간)
문제점 : starvation
해결 방법 : Aging 기법
오래 기다린 프로세스의 우선순위를 증가시키는 기법
라운드 로빈 (RR) 알고리즘
- preemptive한 알고리즘이다.
- 각 프로세스는 동일한 크기의 할당 시간(time quantum)을 가진다.
- 할당 시간이 지나면 프로세스는 선점당하고 준비 큐의 제일 뒤에 가서 다시 줄을 선다.
- n개의 프로세스가 준비 큐에 있고 할당 시간이
q time unit인 경우, 각 프로세스는 최대q time unit단위로 CPU 시간의 1/n을 얻는다.- 어떤 프로세스도
(n-1)q time unit이상 기다리지 않는다.
- 어떤 프로세스도
할당 시간을 너무 크게 하면 FCFS와 같아진다.
할당 시간을 너무 짧게 하면 문맥 교환의 오버헤드가 지나치게 커진다.
따라서 적당한 할당 시간을 부여해야 한다. (일반적으로 10 ~ 100 밀리초)
응답 시간(Response Time)이 빨라진다. 일반적으로 SJF보다 평균 Turnaround time은 더 길지만, Response time은 더 짧다.
기다리는 시간이 CPU 사용시간에 비례한다는 점에서 공정한 스케줄링을 수행한다.
멀티레벨 큐
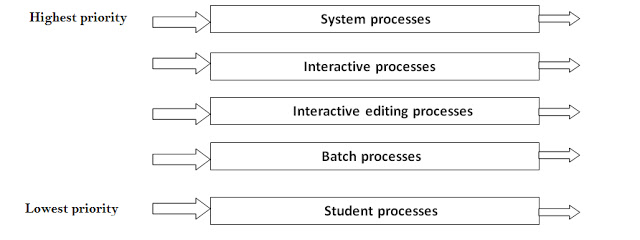
일반적으로 멀티레벨 큐에서 준비 큐는 대화형 작업을 담기 위한 전위 큐(foreground queue)와 계산 위주의 작업을 담기 위한 후위 큐(background queue)로 분할하여 운영된다. 그리고 각 큐는 독립적인 스케줄링 알고리즘을 가진다.
-
foreground (interactive) - RR
-
background (batch - no human interactive) - FCFS
-
큐에 대한 스케줄링 또한 필요하다.
-
Fixed Priority Scheduling
- 우선순위가 높은 줄이 비어있을 때만 낮은 줄에 CPU를 줄 수 있다.
(serve all from foreground then from background) - starvation의 가능성
- 우선순위가 높은 줄이 비어있을 때만 낮은 줄에 CPU를 줄 수 있다.
-
Time Slice
- 각 큐에 CPU 시간을 적절한 비율로 할당한다.
- ex) 80% to Foreground in RR / 20% to Background in FCFS
-
멀티레벨 피드백 큐
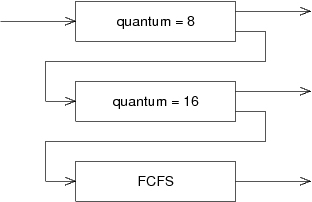
프로세스가 다른 큐로 이동 가능하다.
에이징(Aging)을 이와 같은 방식으로 구현할 수 있다.
멀티레벨 피드백 큐 스케줄러를 정의하는 파라미터들
- 큐의 수
- 각 큐의 스케줄링 알고리즘
- 프로세스를 상위 큐로 보내는 기준
- 프로세스를 하위 큐로 내쫓는 기준
- 프로세스가 CPU 서비스를 받으려 할 때 들어갈 큐를 결정하는 기준
보통은 multilevel feedback queue에서 처음 들어오는 프로세스를 우선순위가 가장 높은 큐에 넣고, 그 큐는 라운드 로빈의 할당 시간을 짧게 준다. 아래로 내려갈수록 라운드 로빈의 할당 시간을 길게 주며, 마지막 큐의 경우 FCFS 알고리즘을 사용한다.
멀티 프로세서 스케줄링
CPU가 여러 개인 경우 스케줄링은 더욱 복잡해진다.
-
Homogeneous processor인 경우
- 큐에 한 줄로 세워서 각 프로세서가 알아서 꺼내가게 할 수 있다.
- 반드시 특정 프로세서에서 수행되어야 하는 프로세스가 있는 경우에는 문제가 더 복잡해진다.
-
Load Sharing
- 일부 프로세서에 작업이 몰리지 않도록 부하를 적절히 공유하는 매커니즘이 필요하다.
- 별개의 큐를 두는 방법 vs 공동 큐를 사용하는 방법
-
Symmetric Multiprocessing (SMP)
- 모든 CPU가 대등하다.
- 각 프로세서가 각자 알아서 스케줄링을 결정한다.
-
Asymmentic Multiprocessing
- 하나의 프로세서가 다른 모든 CPU의 스케줄링 및 데이터 접근을 책임지고 나머지 CPU는 거기에 따라 움직인다.
스레드 스케줄링
-
Local Scheduling
- User level thread의 경우 사용자 수준의 thread library에 의해 어떤 스레드를 스케줄할지 결정한다.
(사용자 프로세스가 직접 어떤 스레드에게 CPU를 줄지 결정한다.)
- User level thread의 경우 사용자 수준의 thread library에 의해 어떤 스레드를 스케줄할지 결정한다.
-
Global Scheduling
- Kernel level thread의 경우 일반 프로세스와 마찬가지로 커널의
단기 스케줄러가 어떤 스레드를 스케줄할지 결정한다.
(운영체제가 어떤 스레드에게 CPU를 줄지 결정한다.)
- Kernel level thread의 경우 일반 프로세스와 마찬가지로 커널의
알고리즘 평가
-
Queueing Models
- 확률 분포로 주어지는 arrival rate(도착률)와 service rate(처리율) 등을 통해 각종 성능 척도의 값을 계산한다.
- 이론적인 방식으로, 현재는 실제 시스템에 구현하는 방식을 더 많이 사용한다.
-
Implementation & Measurement (구현 및 성능 측정)
- 실제 시스템에 알고리즘을 구현하여 실제 작업(workload)에 대해 성능을 측정 비교한다. (실측을 통한 성능 비교)
-
Simulation(모의 실험)
- 알고리즘을 모의 프로그램으로 작성 후 trace를 입력으로 하여 결과를 비교한다.
- trace는 시뮬레이션 프로그램에 입력값으로 들어간 데이터다. 실제 프로그램에서 추출한 trace일 경우 실제 상황을 더 잘 반영할 수 잇다.
