User-based CF (UBCF)
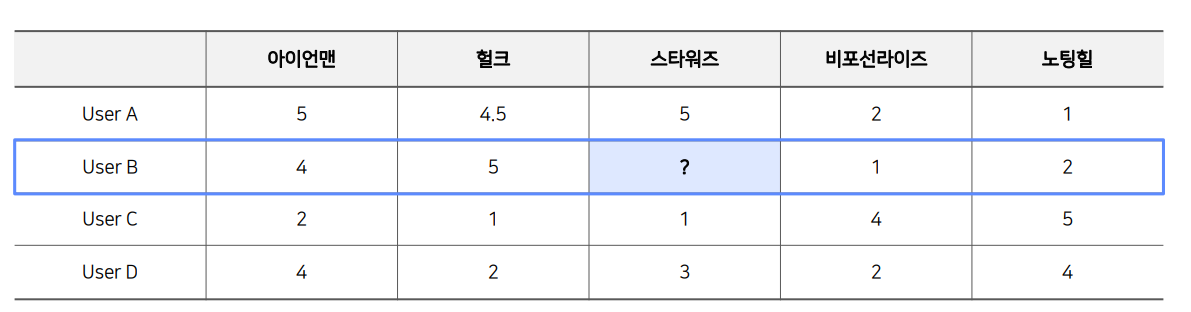
UBCF는 유저 간 유사도를 구한 후, 해당 유저와 유사도가 높은 유저들이 선호하는 아이템을 추천해준다.
유저-아이템 행렬은 아래와 같이 구성하고, 우리가 알고자하는 평점을 예측하는 것이다.
Item-based CF (IBCF)
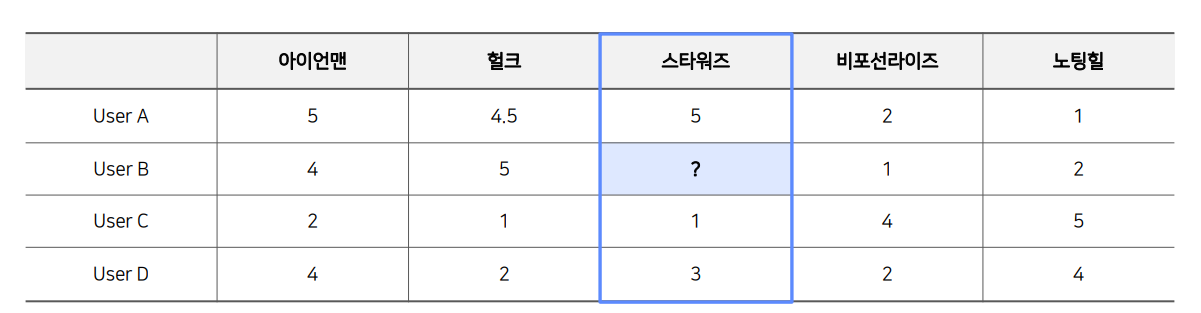
UBCF와 반대로 IBCF는 아이템 간 유사도를 구한 후, 해당 아이템과 유사도가 높은 아이템이 유저들로부터 받은 평점을 토대로 예측한다.
Neighborhood-based CF (NBCF)
NBCF의 목적은 해당 유저가 특정 아이템에 부여할 평점을 예측하는 것이다.
NBCF는 구현, 이해하기 쉽다.
하지만, 아이템과 유저가 계속 늘어날수록 확장성이 떨어지고 (Scalability), 데이터가 적을 경우 성능이 떨어진다 (Sparsity).
(NBCF를 사용하기 위해선 sparsity ratio가 99.5% 이하일때 추천 (sparsity ratio : 행렬 전체 원소 중 빈 원소 비율))
K-Nearest Neighbors CF (KNN CF)
앞서 소개한 NBCF는 모든 유저와 유사도를 구해야 한다.
따라서 유저가 많아질수록 연산량이 기하급수적으로 증가하고, 오히려 성능이 떨어지기도 한다.
따라서 KNN CF는 특정 유저와 가장 유사한 유저 K명을 선별해서 (KNN) 평점을 예측한다.
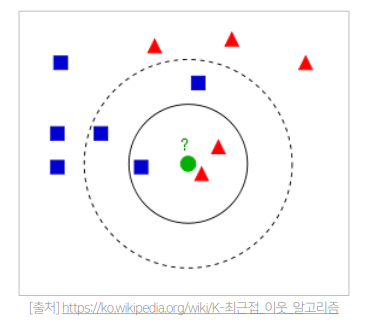
KNN을 사용하기 위해선 유사도 측정법을 정의해야한다. (Similarity Measure)
보통은 거리의 역수 개념을 사용한다.
따라서, 거리를 어떻게 측정할지에따라 유사도 측정 방법이 달라진다.
Similariy Measure
Mean Squared Difference Similarity
각 기준에 대한 점수 차이 계산, 유사도는 유클리드 거리에 반비례한다.
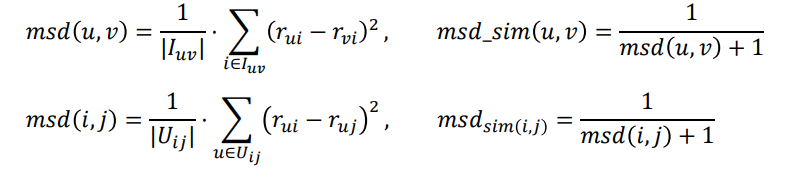
Cosine Similarity
두 벡터의 방향이 얼마나 유사한지 의미한다.
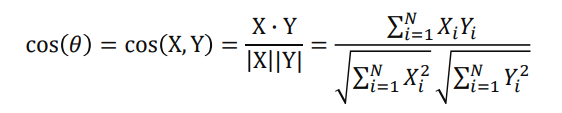
Pearson Similarity (Pearson Correlation)
각 벡터를 표본 평균으로 정규화한 후 코사인 유사도를 구한 값이다.
(1에 가까우면 양의 상관관계, 0 == 독립, -1에 가까우면 음의 상관관계)
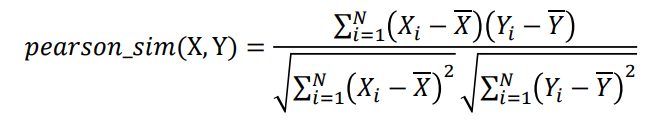
Jaccard Similarity
집합 개념을 사용한 유사도로, 같은 아이템을 얼마나 공유하고 있는지를 나타낸다. (1 == 모두 같음, 0 == 모두 다름)
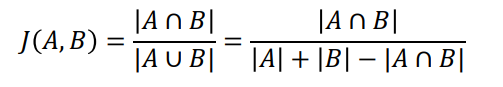
평점을 예측해보자
Absolute Rating
그냥 평균내자 (Average)
동일한 Weight를 적용해서 평균를 낸다.
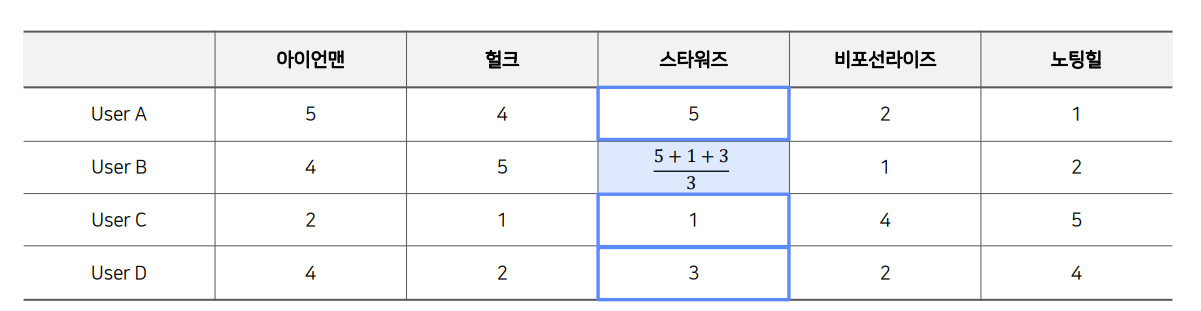
평균은 좀 그러니까 Weight를 주자 (Weighted Average)
유저 or 아이템간 유사도 값을 weight로 줘서 평균을 낸다.
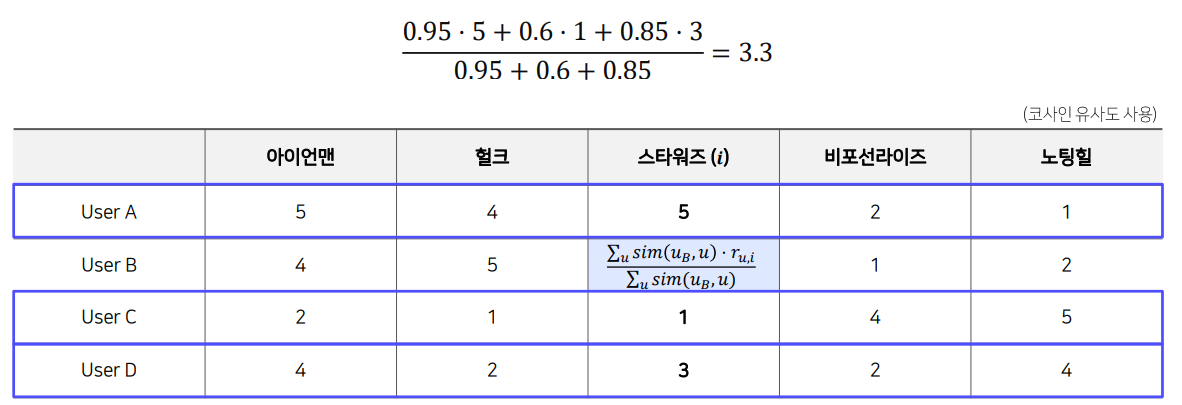
Relative Rating
Absolute Rating은 유저간 평점을 주는 기준이 다른데 동일하게 적용하는게 맞는가에 대한 한계를 가지고 있다.
(좋으면 5점을 술술 뿌리는 사람이 있는 반면, 좋아도 3점만 주는 사람이 있어 사람마다 평점 주는 기준이 다 다르다)
따라서, Relative Rating은 유저의 평균 평점에서 얼만큼 차이나는지, 편차 (Deviation)을 사용한다.
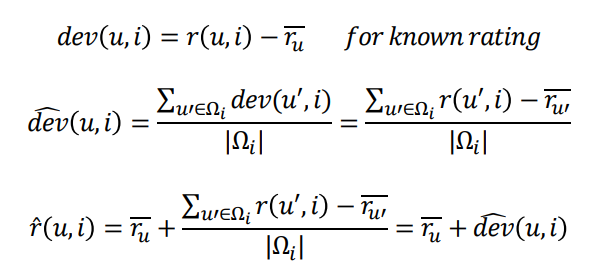
유저 평균 rating + predicted deviation으로 평점을 예측한다.
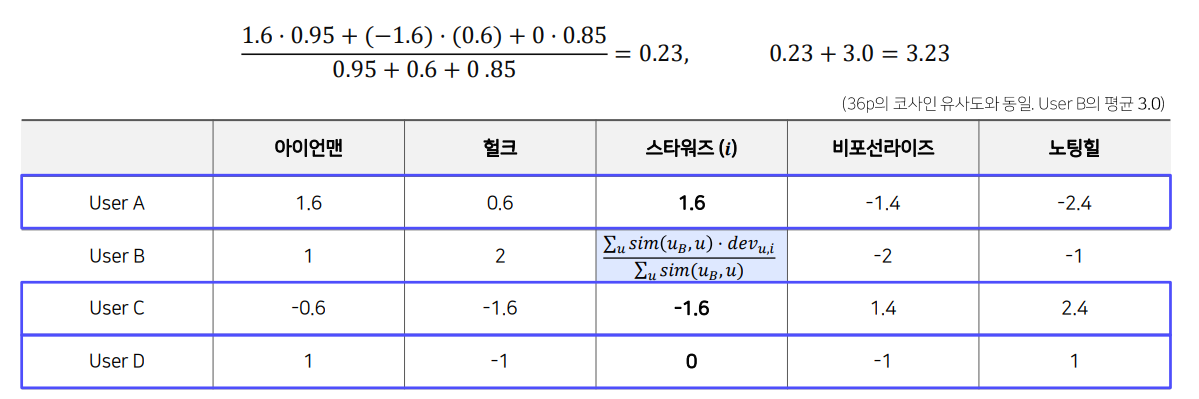
이제 유저에게 추천해보자
이렇게 모든 평점을 예측하고난 후, 타겟유저에게 평점 높은 순으로 정렬 후 추천해주면 된다.
