Langchain 공부 #4
챗봇 만들기 프로젝트
- 데이터 주입
- LLM 을 데이터에 넣어주기
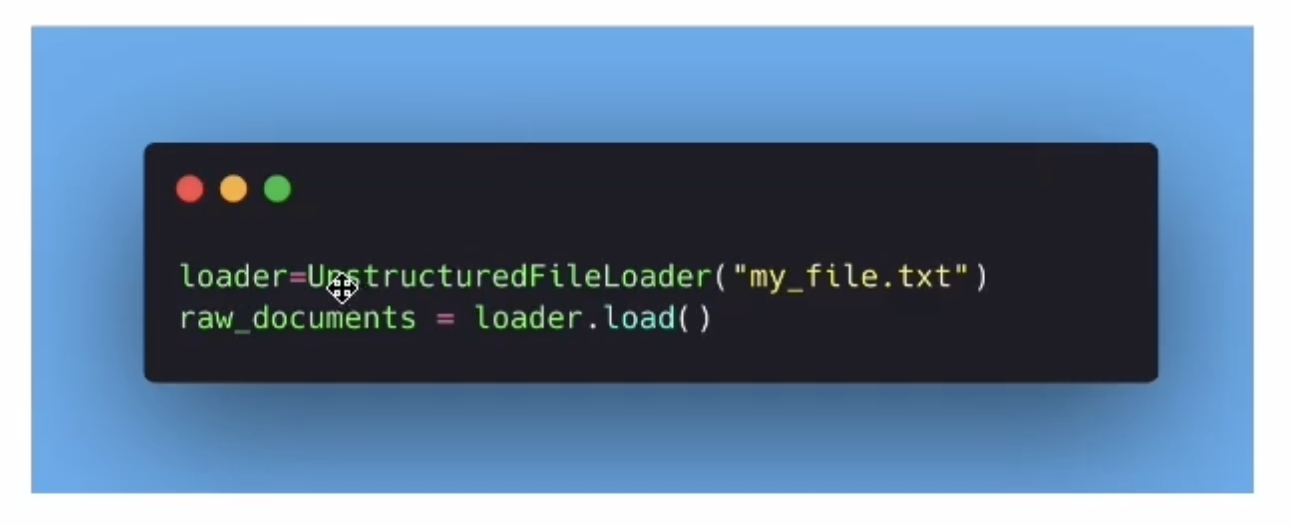
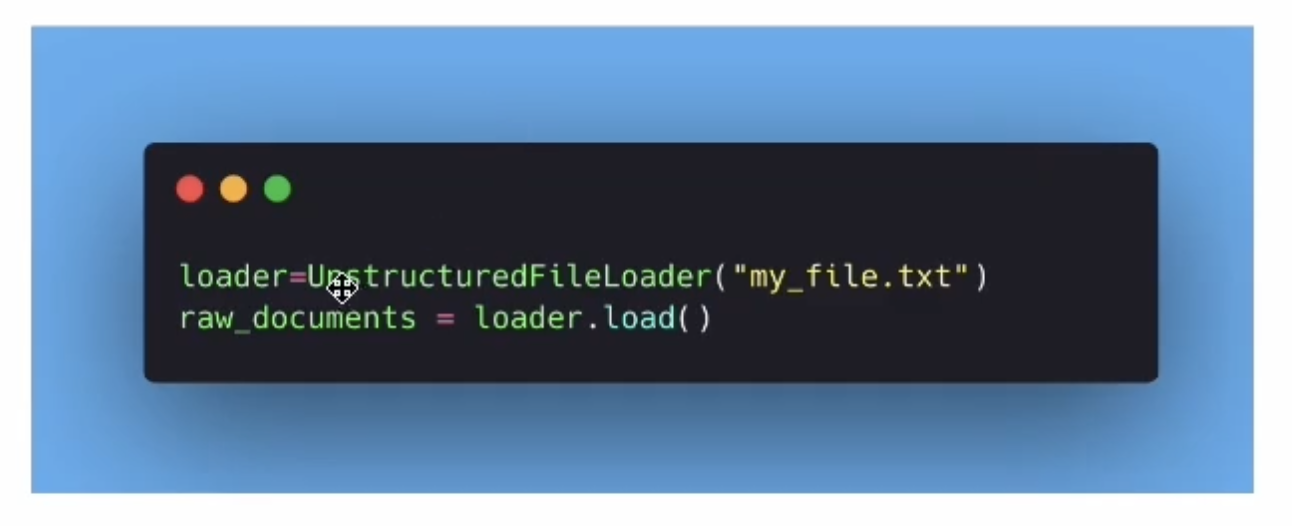
Data Ingestion
- 데이터 불러오기
- LangChain Document object의 형식으로 보내야 함
- 이 object는 text와 metadata를 포함함 (어디서 왔는지 등등)
-
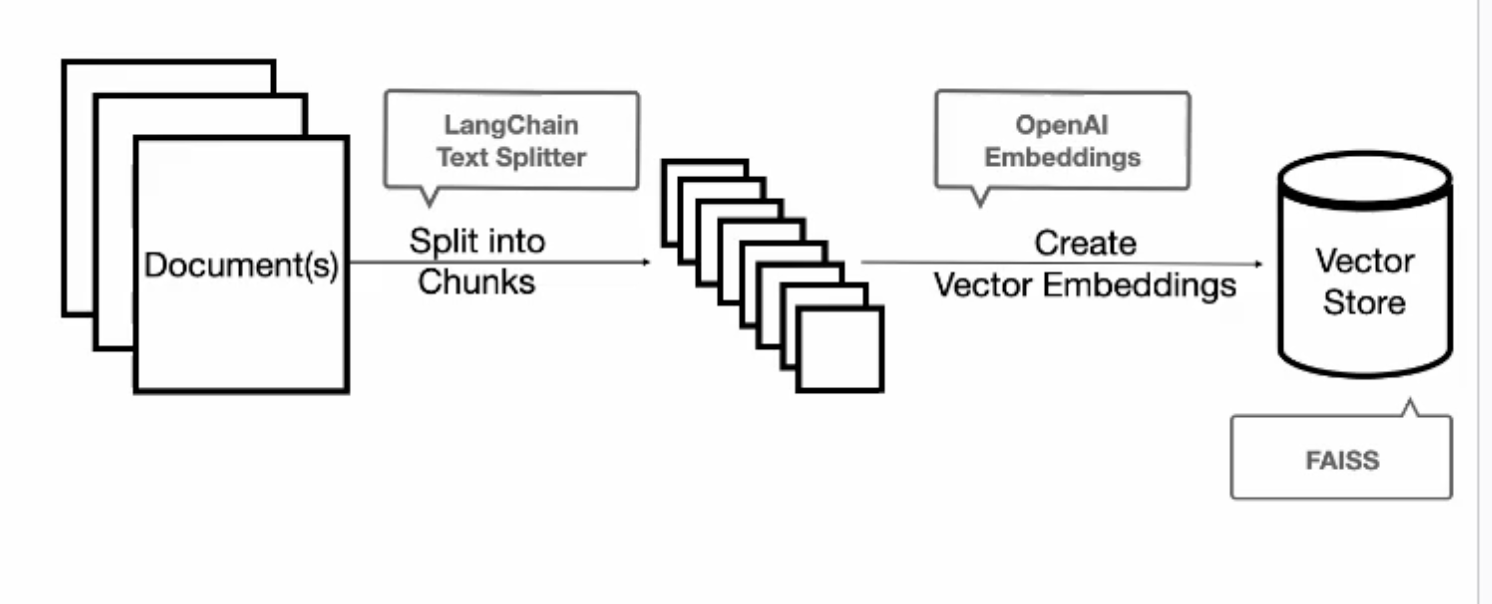
Text 자르기 (연관된 정보들을 가져오기 위해 자르는 것이 필요)
-
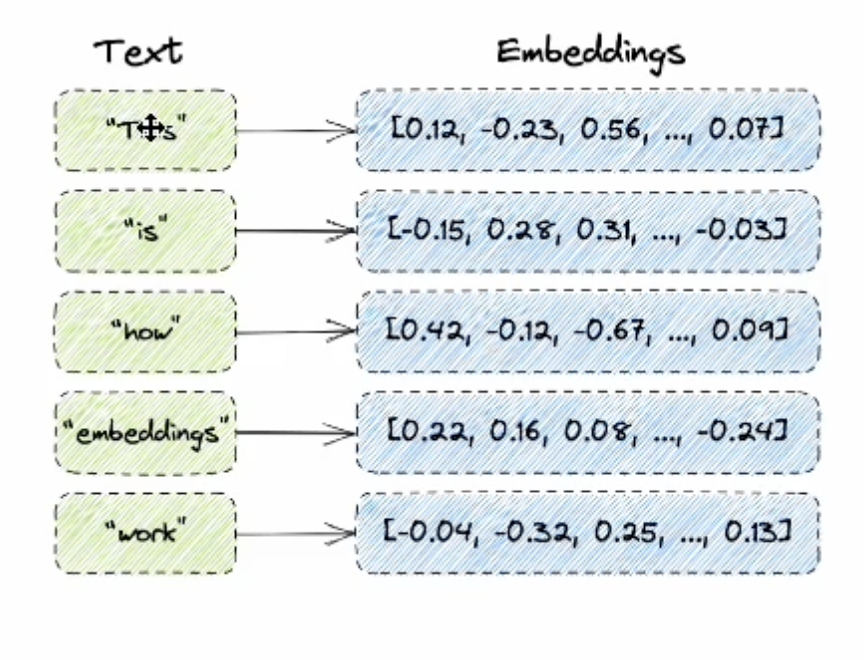
Embed text
- 텍스트를 num array로 전환한 것이 embeded text 인듯
- 연관 관계를 빠르게 찾기 위해 숫자로 전환하는 것
- embeddings를 Vector 데이터베이스에 주입하기
"Sementic Search"
- sementic: relating to meaning in language or logic
Generating Respones
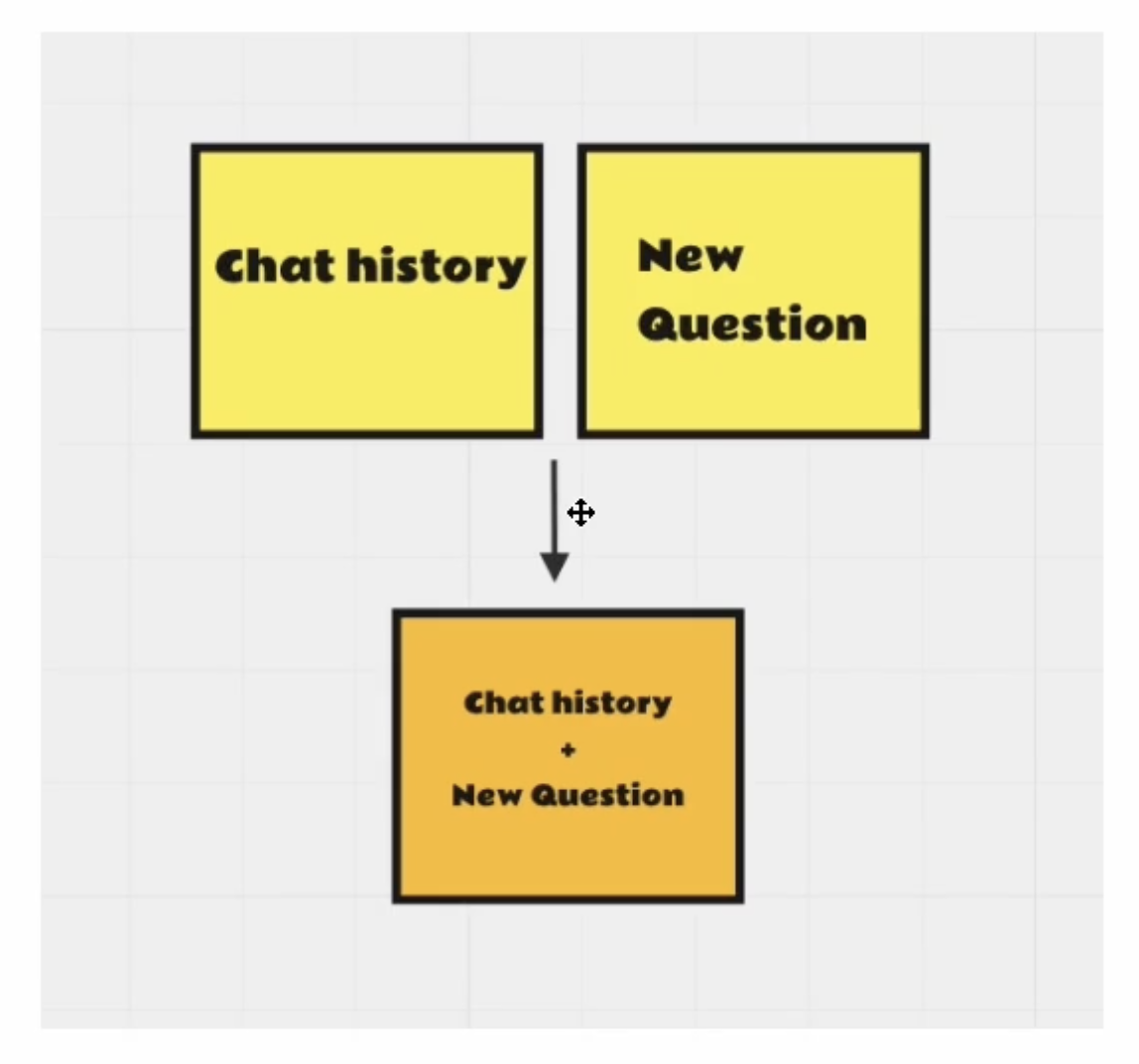
- 챗 히스토리와 새로운 질문을 결합
- LLM에 요청을 보내기 전에, 이전 메세지와 질문을 결합함
- chatbot이 이전 메세지에 대한 답을 하기 위해서 필요한 과정
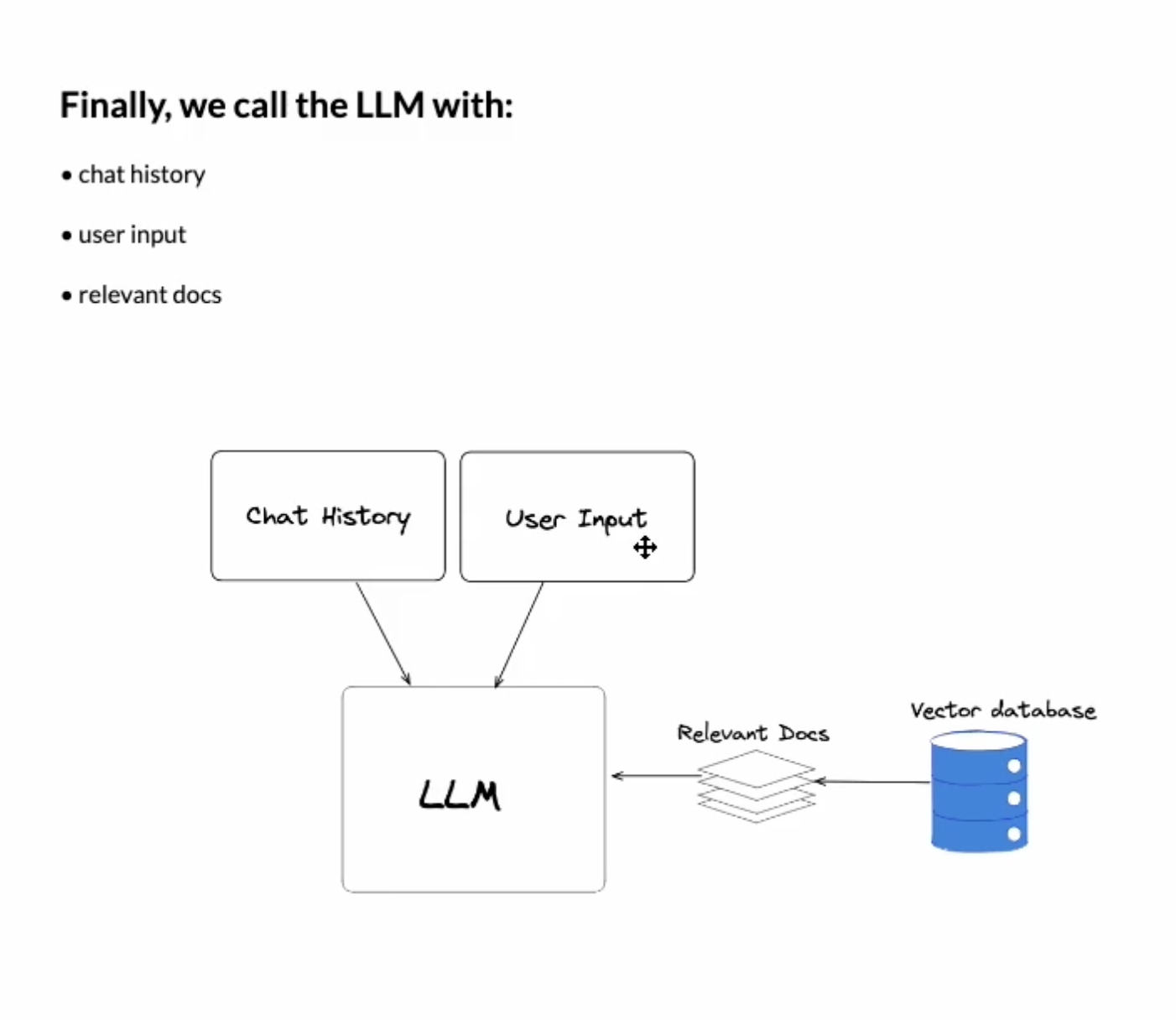
- 연관된 문서를 벡터 DB에서 조회
- 응답을 생성하기 위해 LLM 사용
Context Windows
- LLM은 오직 general한 정보만 갖고 있음 (개인 정보는 없음)
- 최신 정보가 아니고, 부정확한 정보일 수 있어 문제
- 이 정보들을 llmd에 주입시킬 필요성
그럼 이게 뭐냐?
- 모델 메모리.
- 100 tokens = 75 words.
Bottle nect
- 우리는 모든 information을 하나의 컨텍스트 윈도우에 넣을 수가 없음. 그게 문제임.
limit?
GPT-4 - Regular 8k, 32k
Calude - 100k (75,000 words!)
Solution?
- VectorDB!
- Relational DB는 왜 안될까?
- contextual하게 검색하려면 벡터 디비를 써야 함.
- Relational DB에서는 Monkey를 검색하면 Monkey 밖에 안나옴.
어떻게 돈을 줄이나.
- Sanitize the data (데이터 최신화..?)
- 데이터 요약하기 (chain, memory 개념 적용하기)
- 불필요한 정보 지워버리기
