프로젝트를 진행하면서 채팅 서버를 만들어야 할 일이 있었다. 구조적으로 처음 설계를 해봤고 어떤 부분이 문제일까를 계속 생각을 해봤을 때 내 나름대로의 결론을 냈고, 그 내용을 한번 공유해보고자 한다.
채팅서버의 특성
아래의 내용은 내가 채팅서버의 처리를 어떻게 할 지를 고민하면서 고려했던 사항들이다. 채팅 서버는 아래와 같은 특징을 가지고 있는 도메인이다.
- 채팅 서버는 읽기와 쓰기가 1 대 1 비율로 이뤄진다는 특성을 가지고 있다.
- 사용자들은 채팅 목록을 조회할 때에 최신 정보만을 조회할 가능성이 매우 높다.
- 인메모리 DB를 사용한다면 예상 사용자, 예상되는 채팅의 크기를 고려해서 인스턴스의 메모리 크기를 설정해야 한다.
- 채팅 기록은 손실돼서는 안된다.
채팅 서버에서 필요한 선택
따라서, 각각의 특성을 고려해봤을 때 선택하고, 선택할 가능성이 있거나 반드시 설정하면 안될 부분을 고민해보았다.
-
데이터베이스는 쓰기 비율이 높다는 특성과 최신 정보만을 조회한다는 특성을 고려했을 때 레디스를 사용하는 것이 좋다.
-
채팅 서버에서 사용자가 늘어난다는 점을 고려했을 때, scale out을 고려한다면 websocket의 커넥션이 특정 서버에 대해서만 붙어있어 다른 사용자에게 메시지가 안 갈 수 있다. 만약에 서버를 scale out할 예정이라면 이를 중계하기 위해서 중간에 메시징을 둬야 한다.(레디스의 pub/sub은 손실이 일어나기 때문에 절대로 하면 안된다.)
-
캐시의 역할도 하는 채팅 서버의 데이터 손실이 일어날 것을 대비했을 때 레디스 AOF나 RDB 같은 백업 및 장애 대응 설정이 필요하다.
→ fork 방식으로 멀티 프로세스 방식으로 동작하니 실제 가용 메모리에 비해서 COW 정책에 의한 메모리 증가로 레디스 서버 다운되는 것과 한번에 큰 데이터를 이동하다가 timeout 나는 부분을 조심해야 한다. -
DB와 레디스 서버의 동기화 과정에서 캐시 miss의 발생 영향을 최소화 해야 한다.
→ 레디스 서버는 캐싱의 역할도 한다. 이 때 레디스 서버의 데이터를 모두 DB에 동기화 시 Look aside 방식에서는 순간적으로 cache miss가 크게 발생하면서 데이터베이스로 부하가 크게 몰린다. 따라서 데이터 동기화는 작게 쪼개야 한다. -
레디스 서버에는 절대로 O(n), O(n * m) 명령어를 한번에 동작 시켜서는 안된다.
→ 레디스 서버는 멀티쓰레드로 동작하지 않는다. 멀티 쓰레드, 프로세스로 동작하는 부분은 백업이나 백그라운드에서 처리하는 무언가지 실제 우리가 하는 작업은 단일 쓰레드에 의해서 처리한다. 따라서 긴 작업에 의해서 서비스가 멈추는 현상을 고려해서 부분적으로 동기화 시켜야 한다.
읽기, 쓰기, 동기화
사실 위의 과정에 대해서 모두 고려한 설계가 필요하다고 생각한다. 각각의 측면에 대해서 나의 입장에 관해서 이야기해보면 다음과 같다.
읽기: 최대한 동기화를 하더라도 최신 데이터를 최대한 남겨두는 편이 데이터베이스로 가는 부하를 준다. 모든 데이터가 동기화돼서 버퍼 역할을 하는 레디스 서버가 모두 비워지면 캐시 미스가 크게 일어나 순간적으로 DB에 부하가 몰리는데 이 경우를 조심해야 한다. 따라서 한번에 모든 데이터가 동기화되기보다는 부분적으로 동기화될 수 있게 동기화 과정을 조심해야 한다.
쓰기: 쓰기 과정에서는 얼마만큼 데이터를 쓸 것인가에 대해서 처리를 고민해봐야 한다고 생각한다. 버퍼로 사용할 레디스 서버의 메모리 크기를 어느만큼 설정할 지를 결정하기 위해서는 어떤 데이터를 쓰기에 각각의 메시지의 크기의 평균은 어느만큼인지, 사용자 수는 얼마정도인 지, 사용자는 하루에 얼마만큼의 데이터를 보낼지를 예측해야 한다. 또한, 이 결과에 대해서 가상 시나리오를 통해서 얼마나 자주 데이터를 동기화할까, 얼마나 많은 사용자 데이터를 캐시 서버에 들고 있을 지를 고민해야 한다고 생각한다.
이 과정에서 대략적으로 내가 생각한 가정은 다음과 같았다.
- 사용자수 400명
- 메시지 유형: 텍스트
- 평균 메시지 크기: 100 byte 이내
- 하루 평균 사용자의 채팅 예상 개수: 100개
위와 같이 설정을 했다면 대략 하루에 쌓이는 데이터는 키 값까지 러프하게 5MB 정도 될 걸로 예상된다.
100 x 100 x 400 = 4,000,000 byte
따라서, 아직 사용자가 많지 않은 서비스의 특성상 사실 메모리의 양에 대해서는 크게 고민하지 않아도 될 것 같다. 대신 서버에서 한번에 DB로 동기화를 시키는 양에 대해서도 고민을 해봐야 될 것 같다.
만약에 캐싱의 목적으로만 최신 데이터 200개를 채팅방 별로 놔둔다고 해보자. 그러면 채팅방의 개수가 200개가 넘는 순간 한꺼번에 동기화하지 않고 한개씩 가장 오래된 데이터를 빼고 현재 메시지를 넣으면 캐시로 버퍼를 두었더라도 write through 방식처럼 동작할 것이다. 이렇게 처리가 되면 캐시를 통해서 DB로의 쓰기 부하를 줄이기 위한 목적을 달성할 수 없다. 따라서, 쓰기 과정에서 버퍼에 꽉 차는 경우에는 1개의 데이터가 아닌 오래된 데이터 100개나 50개를 조회해서 가져와서 처리하는 방법이 있을 것 같다. 시간 단위로 잘라도 될 것 같기도 하다. Lists 자료구조는 Double-Ended Queue이기 때문에 최신 데이터를 조회하지 않더라도 가장 오래된 데이터만을 순차적으로 가져올 수 있다는 특징이 있으므로 불필요하게 최신 데이터를 조회하게 명령어를 넣지만 않으면 될 것 같다.
동기화: 사실 동기화 과정도 쓰기 과정이랑 어느정도는 비슷하다. 별도의 동기화 과정이 필요하지 않을 수도 있다고는 생각한다. 하지만, 정말 사람이 많아져서 채팅방이 많아지면 더이상 쓰기는 안 일어나고 읽기만 일어날 가능성이 있는 오래된 채팅방 등은 메모리에서 데이터를 빼는 게 좋지 않을까?라는 생각이 들었다. 그래서 카카오톡도 3일 간만 데이터를 보관하고 넘으면 컴퓨터에서 가져올 수 없게 만든 게 아닐까 싶기도 했다.(이건 군 입대하고 훈련소 때 3일 밖에 데이터를 못 저장해서 다른 사람 카톡을 못보면서 알았다.)
아무튼 그래서 동기화 과정에 대해서는 이 부분은 어느정도 동기화 시기에 대한 튜닝과 예상이 계속적으로 필요하다고 생각한다. 일단은 7일 동안 보관해야 한다고 놔둬보자. 이 때 동기화 과정에서 조심할 건 스케줄러로 모든 팀에 대해서 둘러보긴 하되. 해당 명령어를 나눠야 된다. 레디스는 AOF나 RDB 등의 I/O 관련 작업을 제외하고는 실제 동작에 대해서 싱글쓰레드로 동작한다. 그래서 최악의 경우에는 모든 데이터가 7일이 넘은 경우 채팅방의 개수가 N개이고 채팅방의 버퍼 크기를 M으로 두었다고 하면 O(N * M) 명령어가 레디스 서버에서 실행될 수 있다.
위의 부분을 조심하기 위해서는 나라면 아마도 인덱스를 최대한 활용할 것 같다. 우선 채팅방의 PK를 Auto Increment로 가져갔다고 했을 때 100개나 1000개 등의 단위로 쪼갤 것이다. 그러면 이제 채팅방에서 1번부터 100번까지 읽은 뒤 해당 100번까지 레디스 서버에서 처리를 하고 이후에 100번 이후를 탐색하여 101번부터 200번까지를 뒤지면서 처리를 해줄 것 같다. PK가 인덱스로 설정되어있기 때문에 이렇게 하면 중간에 동기화 과정으로 인한 읽기나 쓰기 명령어의 장시간 blocking을 막을 수 있다. Auto Increment라면 별도의 인덱스를 놓을 필요도 없다. 스케줄러 처리 저 부분만 조심하면 된다.

이제 아래에는 각각의 동작흐름 플로우에 대해서 적어보았다. 아마도 해당 부분을 구현한다면 문제가 적지 않을까 싶으며, 다시 한 번 말하지만 보관일이랑 동기화 시간은 상황에 따라 조정해야 한다.
채팅 서버 읽기 과정

1. 클라이언트가 서버에게 채팅 기록 조회를 요청한다.
2. Redis 서버에서 데이터가 있는지 조회한다.
3. 데이터를 조회해서 가져온다.
3-1. 없는 경우
4. MySQL 서버에서 데이터가 있는지 조회한다.
5. 결과 값을 가져온다.
6. 클라이언트로 전달한다.
3-2. 있는 경우
4. 클라이언트로 전달한다.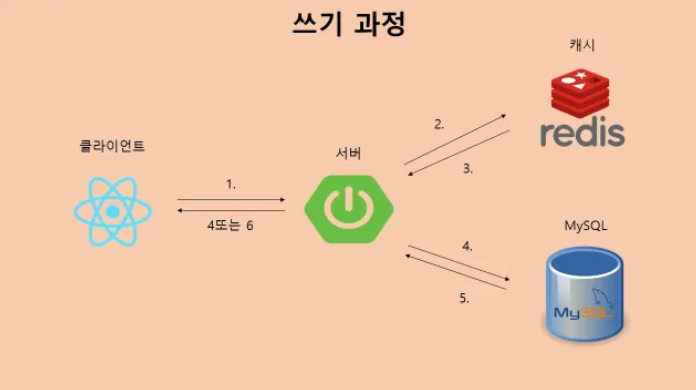
1. 클라이언트가 서버에게 채팅 쓰기 요청을 보낸다.(key는 사용자:시간 정보를 반드시 포함한다.)
2. Redis 서버에서 데이터를 쓸 수 있는 지 여부를 확인한다.
2-1. Redis 서버에서 설정한 buffer 크기를 초과하는 경우
3. buffer를 비운 뒤 서버로 전송한다.
4. MySQL 서버로 데이터를 저장한다.(key 값의 시간 정보를 복원해서 저장하되 나중에 인덱스를 (채팅방, 시간) 순으로 설정해놓는다.)
5-6. OK 메시지를 클라이언트에게 전달한다.
2-2. Redis 서버에서 설정한 buffer크기를 초과하지 않는 경우
3. Redis 서버에 해당하는 내용을 저장한다.
4. OK 메시지를 클라이언트에게 전달한다.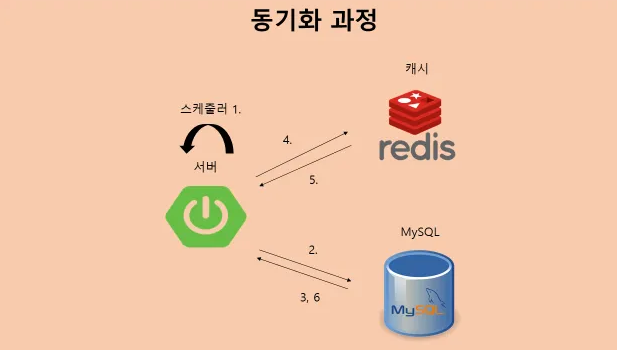
1. Spring 서버내의 스케줄러가 동작한다.
2. MySQL 서버에 채팅방 key 데이터를 요청한다.
3. MySQL 서버에서 채팅방 key 데이터를 가져온다.
4. 채팅방 key 데이터를 활용해서 Redis 서버 내의 key 값에 해당하는 Lists를 보면서 특정한 TTL이 미만인 데이터를 찾는다.
5. Redis에서 채팅 데이터를 가져온다.
6. MySQL 서버로 해당 동기화할 데이터를 전송한다.4번 부분에 대해서는 개인적으로 팀원들과 고민을 해봤는데두 가지 정도 방식이 있었다.
- 내가 처음에 제안한 방식은 Lists 전체에 TTL 8일정도로 생성되거나 버퍼가 한번 비워졌을 때 두어서 스케줄러가 돌 때마다 설정해주고 스케줄러가 체크했을 때 1일 미만이면 버퍼를 비운다. 이렇게 하면 내부 Lists를 돌면서 낭비되는 자원을 줄일 수 있다.
- 다른 사람은 key 값을 돌면서 오래된 것 중 7일 미만으로 남은 것만 비우자는 것이었는데 그러면 더 버퍼에 많은 양을 남길 가능성이 높아져 읽기에서 캐시 미스가 나는 횟수가 줄 것이다. 대신 스케줄 작업이 커진다.
사실 둘 다 가능하다고 생각했다. 그래서 이 방법에 대해서는 딱히 상관이 없을 것 같다. 사실 2번이 어떻게 보면 더 합리적인 것 같지만 개인적으로는 데이터가 얼마나 비워질 지를 모르기 때문에 사실 결과를 모르겠다. 이건 직접 측정해보고 실제로 운영 과정에서 얼마만큼의 데이터가 2번 안으로 놓았을 때 비워지는 지를 봐야 한다고 생각한다.
아무튼 이렇게 채팅 서버와 관련된 설계 부분에 대해서 개인적으로 고민하고 논의 과정에서 제안했던 내용에 대해서 기록을 마친다. 잘못된 부분이 있다면 댓글을 남겨준다면, 감사하겠다.
