FULLTEXT 이론
얼마 전 프로젝트를 하면서 제목 + 본문 검색, 태그 검색을 만들 일이 있었다. 제목과 본문 검색을 할 때 흔히 생각할 수 있는 방법은 특정 컬럼에 대해서 like '%keyword%' 이런 형태로 작성할 수 있다. 그런데, 이렇게 작성을 하면 성능이 정말 좋지 못하다.
본인이 데이터베이스라면 어떻게 이 작업을 처리하겠는가? 우선 'keyword%' 형태라면 해당 컬럼에 인덱스라도 걸려있는 경우, 인덱스를 탈 수 있지만, keyword의 앞 부분을 임의의 단어로 변경시켜버렸기 때문에 인덱스를 탈 수 없다.
따라서, 아마도 모든 테이블 내의 컬럼을 뒤져서 해당 title에 대해서 내부에 있는 단어가 있는 지 살펴볼 것이다. 그러면 대략적인 시간 복잡도는 검색해야 하는 컬럼 수가 N개이고 평균 컬럼의 title 길이가 20이라고 하자. 그러면 KMP 같은 선형의 알고리즘을 사용한다고 했을 때 시간복잡도는 N * (20 + keyword의 길이)가 될 것이다.
좋지 못하다. N이 늘어날수록 좋은 성능을 기대하기는 어렵다. 특히나 본문이라면...? 더 엄청난 검색을 해야 할 것이다.
게다가 검색을 할 때에 보통 한 단어로 검색을 하는가? 문장이나 여러 단어로 하고 싶을 수도 있다. 만약에 '내가 만든 쿠키'라는 단어를 검색하고 싶다고 할 때, '엄마손 쿠키'로 검색을 해도 검색을 할 수 있다면? 이전의 like 절의 경우에는 이런 경우는 데이터를 못 가져왔을 것이다. 특히 이런 검색이 가능하다면 초기 서비스가 작아서 데이터 셋이 적을 때 더 좋은 결과를 가져오지 않을까?
사실 elastic search 같은 좋은 솔루션을 사용하는 방법도 있다. 하지만, MySQL의 FULL TEXT를 이용해볼 수도 있다! 원래는 MyISAM 스토리지 엔진에 있었던 기능이었는데 MySQL 5.6부터 Innodb 스토리지 엔진에서도 사용할 수 있게 되었다.
해당 기능의 대략적인 아이디어는 아래의 이미지를 보면 조금 더 잘 이해할 수 있다.

위와 같은 토큰 작업과 검색어의 길이를 정하기 위해 이전 글에서 아래와 같은 설정을 my.ini나 my.cnf에 해준 것이다.
ngram_token_size = 2
innodb_ft_min_token_size = 2
ft_min_word_len = 2위를 보면 '철학은 어떻게 삶의 무기가 되는가'라는 검색 대상이 될 문장을 어떻게 분해할 수 있는 지 볼 수 있다.
- 각각의 띄어쓰기 단위로 나누어준다.
- 띄어쓰기를 token 사이즈 별로 한 칸씩 슬라이딩하여 인덱싱한다.
그럼 이제 반대로 어떻게 검색어를 분해하는 지도 알아보자.
- 검색어를 입력하면 검색어도 같은 방식으로 토큰화하고 슬라이딩한다.
- 컬럼에 토큰 별 인덱싱을 찾아 일치 여부를 판단한다.
만약에 '철학은'을 검색어로 한다면 똑같이 '철학/학은' 이렇게 두 개의 토큰이 생길 것이다. 해당 단어와 일치하는 지는 title 컬럼 중 '철학'과 '학은'이라는 토큰을 모두 가지고 있는 컬럼이라면 일치하는 것으로 판단한다.
※ 여기에 존재하는 함정
위처럼 검색을 하기 때문에 '철학은 어떻게 삶의 무기가 되는가'를 검색할 때, '철학 무기'로 검색해도 검색을 할 수 있게 만드는 방법이 있다. 그런데 문제는 '기가 떻게'는 검색이 될까??라는 질문에는 '아니오'라고 답할 수 밖에 없다. 왜냐하면 FULLTEXT 인덱스는 '단어의 시작'을 기준으로 하기 때문이다. 위와 같은 검색은 불가능하다. 그런데 어떻게 보면 합리적인 선택일 수도 있다고도 생각이 든다.
검색 실습 테이블과 인덱스
Board 테이블
@Table(
name = "board",
indexes = {
}
)
public class Board {
@Id @GeneratedValue(strategy = IDENTITY)
@Column(name = "board_id")
private Long id;
@Column(name = "title", length = 100, nullable = false)
private String title;
@Column(name = "author", length = 50, nullable = false)
private String author;
@Enumerated(STRING)
@Column(name = "board_status", nullable = false)
private BoardStatus status;
}BoardDescription 테이블
@Table(
name = "board_description",
indexes = {
@Index(name = "idx_board", columnList = "board_id, board_description_id desc")
}
)
public class BoardDescription {
@Id @GeneratedValue(strategy = IDENTITY)
@Column(name = "board_description_id")
private Long id;
@Lob
@Column(name = "description", nullable = false, columnDefinition = "TEXT")
private String description;
@Column(name = "board_id", nullable = false)
private Long boardId;
@Enumerated(STRING)
@Column(name = "board_description_status", nullable = false)
private BoardStatus status;
}BoardStatus Status
public enum BoardStatus {
PUBLISHED, DELETED
}FULLTEXT 인덱스 설정
ALTER TABLE board ADD FULLTEXT(title);
ALTER TABLE board_description ADD FULLTEXT(description);사실 특별하지 않은 설정이지만 Board에 Description을 분리해봤다. 사실 Description 부분을 Board에 넣어도 된다. 하지만 위와 같이 시도를 해본 이유는 Status 때문이다. 실제로 Board처럼 목록으로 조회할 때에는 Description이 빠진 게 좋을 거 같았다.특히나 인덱스를 타지 못하는 경우에 추가적인 조작이 메모리에서 일어나는 경우 description은 필요없는데 메모리만 잡아먹을 가능성이 높다고 생각을 했다. 그리고 크론 잡을 하나 돌려서 상태를 변경해주고 싶을 때에 JPA에서 Update를 쳤을 때에도 Board 데이터를 로딩해서 변경 감지로 변경을 하게 된다. 그런 경우 불필요하게 Description은 실제로 쓰이지도 않는데 불려서 서버의 메모리를 낭비하게 된다.
그래서, 프로젝트에서는 위와 같이 나눠봤었다. 이거에 대해서 같이 스터디에서 한참 얘기를 했었다. 저 선택이 과연 옳은 것인가. 조인을 하더라도 실제로는 상세보기할 때 1개의 데이터만 board_id를 인덱스를 타고 가져오니까 (board_id, board_description_id desc)로 설정해놓으면 나쁘지 않지 않을까?라는 생각이었다.
개인적으로는 잘 모르겠다. 그냥 Update를 JPQL로 그냥 작성해도 될 것 같다. 그리고 읽기는 무조건 DTO로 가져오는 거 어차피 상관이 없을 것 같다는 생각이 들기도 한다. 이 부분은 조금 더 문제를 경험해봐야지 고민해야 될 것 같다.
아무튼 사족이 길었는데 위와 같은 두 개의 테이블만 가지고서 진행을 해보려고 한다.
더미데이터 삽입
BoardDummyService.java
@Transactional
public void insertThousandData(List<String> titles) {
titles.forEach(title -> {
Board board = newBoard(title, "레프리");
boardJpaRepository.save(board);
BoardDescription description = createDescription(title, board.getId());
boardDescriptionJpaRepository.save(description);
});
}BoardDesciptionTest.java
@Autowired
BoardDummyService boardDummyService;
List<String> front = Arrays.asList(
"나의", "너의", "우리의", "시대의", "오늘의", "어제의", "내일의", "그녀의", "그의", "누군가의",
"모두의", "아무의", "이별의", "운명의", "기억의", "추억의", "사랑의", "인생의", "여행의", "꿈의",
"행복의", "슬픔의", "기쁨의", "젊음의", "노래의", "음악의", "기술의", "역사의", "마음의", "생각의",
"말의", "글의", "소리의", "시간의", "공간의", "자유의", "진실의", "거짓의", "빛의", "어둠의",
"희망의", "절망의", "청춘의", "밤의", "낮의", "계절의", "바람의", "바다의", "하늘의", "별의",
"달의", "태양의", "시작의", "끝의", "처음의", "마지막의", "친구의", "가족의", "연인의", "아이의",
"어른의", "이름의", "존재의", "나무의", "꽃의", "길의", "강의", "산의", "도시의", "시골의",
"비밀의", "전설의", "마법의", "모험의", "운명의", "축제의", "그림자의", "미지의", "먼 곳의", "가까운 곳의",
"차가운", "따뜻한", "뜨거운", "고독의", "위로의", "치유의", "상처의", "약속의", "기적의", "우연의",
"필연의", "미소의", "눈물의", "전쟁의", "평화의", "욕망의", "믿음의", "신념의", "내가", "우리가"
);
List<String> middle = Arrays.asList(
"우아한", "사랑한", "차가운", "뜨거운", "따뜻한", "찬란한", "어두운", "밝은", "고요한", "시끄러운",
"화려한", "소박한", "외로운", "다정한", "고독한", "행복한", "슬픈", "기쁜", "쓸쓸한", "푸른",
"붉은", "하얀", "검은", "투명한", "희미한", "선명한", "잔잔한", "거친", "부드러운", "어설픈",
"완벽한", "특별한", "평범한", "기묘한", "신비한", "조용한", "위대한", "작은", "커다란", "지나간",
"새로운", "오래된", "낯선", "익숙한", "몽환적인", "현실적인", "환상적인", "달콤한", "씁쓸한", "비밀스러운",
"순수한", "위험한", "안전한", "강렬한", "연약한", "피곤한", "지친", "활기찬", "생생한", "애틋한",
"아름다운", "추억의", "잊혀진", "잃어버린", "찾아낸", "흐린", "맑은", "무거운", "가벼운", "친절한",
"무심한", "성실한", "불안한", "평화로운", "우울한", "명랑한", "겸손한", "거만한", "매력적인", "비참한",
"용감한", "소심한", "감미로운", "무서운", "잔인한", "위태로운", "독특한", "단순한", "복잡한", "날카로운",
"부끄러운", "당당한", "조심스러운", "대담한", "솔직한", "은밀한", "지혜로운", "어리석은", "풍요로운", "메마른"
);
List<String> last = Arrays.asList(
"프로그래밍", "알고리즘", "데이터베이스", "자바스크립트", "프레임워크", "아키텍처", "인터페이스", "애플리케이션", "마이크로서비스", "네트워크",
"오픈소스", "라이브러리", "컨테이너", "쿠버네티스", "가상현실", "인공지능", "클라우드컴퓨팅", "머신러닝", "블록체인", "비트코인",
"데이터사이언스", "빅데이터", "함수형프로그래밍", "모바일디바이스", "그래픽디자인", "사물인터넷", "시스템엔지니어링", "유저인터페이스", "객체지향언어", "하이퍼바이저",
"가상머신", "오토메이션", "패턴인식", "네트워크보안", "딥러닝모델", "데이터분석가", "소프트웨어엔지니어", "프로덕트매니저", "데이터엔지니어", "소프트웨어테스팅",
"컴퓨터그래픽스", "인터랙티브미디어", "리눅스운영체제", "소프트웨어아키텍트", "소프트웨어품질관리", "사용자경험디자인", "내추럴랭귀지프로세싱", "프론트엔드개발자", "백엔드엔지니어링", "프로그래밍언어론",
"휴먼컴퓨터인터랙션", "리액티브프로그래밍", "지속적통합배포", "퍼포먼스최적화", "소프트웨어유지보수", "시스템모니터링툴", "소프트웨어개발방법론", "네트워크인프라스트럭처", "모바일어플리케이션개발", "클라우드서비스프로바이더",
"엔터프라이즈애플리케이션", "소프트웨어디벨롭먼트킷", "멀티플랫폼프로그래밍", "데이터베이스매니지먼트", "컴퓨터비전엔지니어링", "소프트웨어개발프로세스", "가상프라이빗네트워크", "오브젝트오리엔티드프로그래밍", "인티그레이티드디벨롭먼트환경", "인터넷서비스프로바이더",
"풀스택소프트웨어개발자", "콘텐츠매니지먼트시스템", "모바일인터페이스디자인", "데이터시각화대시보드", "소프트웨어라이선스관리", "오픈소스컨트리뷰터", "비즈니스인텔리전스", "트랜잭션처리시스템", "소프트웨어버전컨트롤", "소프트웨어배포자동화",
"분산컴퓨팅시스템", "하이퍼텍스트마크업언어", "소프트웨어프로젝트관리", "그래픽사용자인터페이스", "소프트웨어테스트자동화", "크로스플랫폼개발환경", "메시지큐잉시스템", "소프트웨어빌드도구", "애자일소프트웨어개발", "하이퍼텍스트전송프로토콜",
"모델뷰컨트롤러패턴", "지속적인통합환경", "프로세스자동화도구", "테스트주도개발방법론", "시스템통합테스트환경", "소프트웨어성능테스트", "데이터웨어하우스모델링", "클라이언트서버아키텍처", "이벤트드리븐아키텍처", "소프트웨어요구사항분석"
);
@Test
void test() {
for (int i = 0; i < 1000000; i++) {
if (i > 0 && i % 500 == 0) {
List<String> titles = new ArrayList<>();
for (int j = 500; j > 0; j--) {
String word1 = "우리의"; // front.get(((i-j) / 10000) % 100);
String word2 = middle.get(((i-j) / 100) % 100);
String word3 = last.get((i-j) % 100);
StringBuilder sb = new StringBuilder();
titles.add(sb.append(word1).append(" ").append(word2).append(" ").append(word3).toString());
}
boardDummyService.insertThousandData(titles);
}
}
}더미 데이터는 다음과 같이 총 100만 개의 데이터를 front가 '우리의'로 고정된 데이터 100만 개 1번, 그 다음은 임의의 100개 단어로 100만 개를 총 200만 개를 넣었다.
100만 개는 넣어야... 속도가 느려지는 걸 볼 수 있지 않을까..?
다양한 검색 관련 내용과 더미데이터 실험
자연어 검색 모드(NATURAL LANGUAGE MODE)
MySQL의 자연어 검색은 검색어에 제시된 단어들을 많이 가지고 있는 순서대로 정렬해서 결과를 반환한다. 다음과 같이 검색을 해보면 얼마만큼 일치하는 지 여부와 함께 확인해볼 수 있다.
Select b.board_id
FROM board b
WHERE MATCH(title) AGAINST ('너의' IN BOOLEAN MODE);이러면 '너의'라는 단어가 들어간 모든 title에 대해서 검색을 한 뒤 얼마나 일치하는지 여부를 보여준다. 이 때 제시된 단어를 많이 가지고 있는 순서대로 정렬해서 가져온다.
위의 예제는 좋지 않은 예제이지만, Real MySQL 책에서는 'Real MySQL, 이 책은 지금까지의 메뉴얼 번역이나 단편적인 지식 수준을 벗어나 저자와 다른 많은 MySQL 전문가의...' 이런 예시를 줬었다. 이 경우는 'MySQL'이라는 값을 기준으로 검색하면 MySQL이 많은 경우가 조금 더 우선일 것이다.
또한 문장으로도 검색을 할 수 있다. 문장으로 검색하는 예시는 다음과 같다.
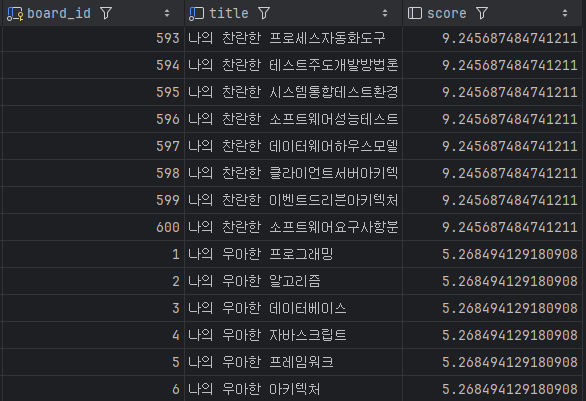
SELECT board_id, title, MATCH(title) AGAINST ('나의 찬란한' IN NATURAL LANGUAGE MODE) AS score
FROM board b
WHERE MATCH(title) AGAINST ('나의 찬란한' IN NATURAL LANGUAGE MODE);문장이 검색어로 사용되면 MySQL 서버는 똑같이 검색어를 공백을 기준으로 분리하고 n-gram 파서로 토큰을 생성한 후 각 토큰에 대해 일치하는 단어의 개수를 확인해서 일치율을 계산한다. 이 경우에는 검색어에 사용된 모든 단어가 포함되지 않더라도 일부만 포함하는 결과도 가지고 온다. 또한 이 떄에는 .이나,와 같은 문장 기호는 생략된다.
위의 문장의 결과는 다음과 같다. 일치하는 정도가 클수록 더 높은 점수가 나온다.
불리언 검색(BOOLEAN MODE)
자연어 검색은 단순히 검색어에 포함된 단어들이 존재하는 결과만 가져오는 반면에 불리언 검색은 쿼리에 사용되는 검색어의 존재 여부에 대해서 논리적인 연산이 가능하다.
+연산
반드시 특정 단어를 포함해야 한다면? +연산을 사용하면 된다. 이전에는 '나의 찬란한'을 검색했지만 '나의 우아한'이 포함된 단어들도 검색이 되었었다. 하지만 +연산을 사용하면 그런 일이 발생하지 않는다.
SELECT board_id, title
FROM board b
WHERE MATCH(title) AGAINST ('+나의 +찬란한' IN BOOLEAN MODE);-연산
특정 단어를 포함하고 싶지 않은 경우에는? 반대로 -연산을 사용하면 된다. 이전에는 '나의'는 포함이 되어있지만 '찬란한'을 포함하고 싶지 않다면 -연산을 사용하면 된다.
SELECT board_id, title
FROM board b
WHERE MATCH(title) AGAINST ('+나의 -찬란한' IN BOOLEAN MODE);~연산
부정연산으로 특정 단어를 포함하는 단어의 순서를 조정한다. 해당 단어가 포함된 것이 후순위로 검색이 되어 나오게 된다. 신기한 게 -랑 비슷하게 제외를 시키는 것 같지만 없애는 정도까지는 아니고 순위만 낮춘다. 시도를 해봤을 때 10000개 중 offset 100번으로 500번 이후로 검색이 되었다.
SELECT board_id, title
FROM board b
WHERE MATCH(title) AGAINST ('+나의 ~찬란한' IN BOOLEAN MODE);*연산
부분 검색으로 꼭 일치하지 않아도 검색이 된다. 위에서 '나*'로 검색하면 '나의', '나는', '나도' 이런 단어가 포함되어도 검색이 되는 것이다. 그래서 단어만 기준으로 검색할 때 조사에 관계없이 검색이 가능하다.
SELECT board_id, title
FROM board b
WHERE MATCH(title) AGAINST ('나* +찬란한' IN BOOLEAN MODE);그렇다고 단어에 꼭 '나*'를 포함해도 되는 건 아니기 때문에 '찬란한'만 포함되어있다면 아래처럼 검색이 된다.
이 기능에 대해서는 사실상 의미가 없는 기능으로 보는 것 같기는 한데, 어차피 조사를 날려야되는 거라면 *나 그냥 검색하는거나 별반 다를 게 없어 보이긴 한다.
""검색
FULLTEXT 인덱스가 불편한 점은 특정 단어와 정확하게 매칭되고 싶지 않은데 우선순위로 나올 수도 있다. 그럴 때에는 정확하게 검색을 할 수 있게 만들어 줄 수도 있다. 위의 경우에는 '+나의 +알고리즘'으로 검색을 하면 '나의 XXX 알고리즘'이 검색이 된다.
SELECT board_id, title
FROM board b
WHERE MATCH(title) AGAINST ('+나의 +알고리즘' IN BOOLEAN MODE);그런데 '"나의 알고리즘"'으로 검색을 하면 결과가 검색이 되지 않는다.
SELECT board_id, title
FROM board b
WHERE MATCH(title) AGAINST ('"나의 알고리즘"' IN BOOLEAN MODE);
stopword
불용어를 만들 수도 있다. 그런데, 불용어는 한국어에서는 의미가 좀 덜할 가능성이 높다. 왜냐하면 미국에서는 'This', 'There', 'is', 'are'과 같이 사실상 검색을 기준으로 사용하기엔 모호한 단어들이 존재한다. 그런데 한국어는 조사와 단어가 결합한 형태로 '나는'이 '난'이 될 수도 있고, '나를'과 같이 되어있지 '를' 자체를만 검색을 할 일은 없기 때문이다.
너무 베낀 거 같아서... 아래의 참고 자료를 보면 INPA님의 블로그에 있다.
대신, 엄청나게 중복되 발생하는 단어가 있다면 강제로라도 이걸 활용해서 막는 게 나을 수도 있다. 이건 나중에 이유를 설명하겠다.
검색을 할 때 주의사항
일단 검색을 FULLTEXT 인덱스를 활용하여 만든다면 Join은 무조건 피해야 한다. 처음에 쿼리를 이렇게 짜봤었다. 데이터가 몇 건 없을 때는 괜찮겠지만 100만 건이 들어간 이상 굉장히 검색 속도가 좋지 못하다.
@Query(value = """
SELECT b.board_id
FROM board b
JOIN board_description bd
ON b.board_id = bd.board_id
WHERE (MATCH(b.title) AGAINST(:keyword IN BOOLEAN MODE)
OR MATCH(bd.description) AGAINST(:keyword IN BOOLEAN MODE))
LIMIT :pageSize OFFSET :pageOffset
""", nativeQuery = true)
List<Long> searchBoardIdByKeyword(
@Param("keyword") String keyword,
@Param("pageSize") Long pageSize,
@Param("pageOffset") Long pageOffset
);위처럼 쿼리를 짜고 workbench에서 돌려본 결과는 아래와 같았다. 16초면 검색이 사실상... 불가능한 것에 가깝지 않을까..?

하지만 Join을 하지 않는다면?? 0.015초로 이 정도면 200만 건이지만 쓸만한 쿼리라고 생각이 든다.

또한, FULLTEXT 인덱스가 있으면 검색 결과에 대해서 다른 인덱스를 사용할 수 있을까?? 그래서 PK로는 어차피 기본적으로 정렬이 되어있으니 다음과 같이 쿼리를 작성해봤다.
@Query(value = """
SELECT b.board_id
FROM board b
WHERE MATCH(b.title) AGAINST(:keyword IN BOOLEAN MODE)
ORDER BY b.board_id DESC
LIMIT :pageSize OFFSET :pageOffset
""", nativeQuery = true)
List<Long> fromBoardGetIdByKeyword(
@Param("keyword") String keyword,
@Param("pageSize") Long pageSize,
@Param("pageOffset") Long pageOffset
);실제로 workbench에서 돌려보면? 약간의 시간이 오른다! 이전에는 0.015초였는데에 비해 0.078초로 0.063초가 올랐다.

이렇게 오른 이유는 MySQL에서 자체적으로 board_id를 기준으로 다시 메모리에서 정렬을 하기 때문이다. 이걸 확인해보고 싶다면, 아래와 같이 명령어를 쳐보자.
EXPLAIN SELECT b.board_id
FROM board b
WHERE (MATCH(b.title) AGAINST('내가*' IN BOOLEAN MODE))
ORDER BY b.board_id desc
LIMIT 500;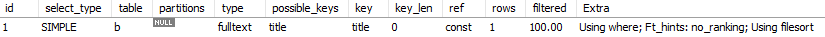
그럼 위와 같은 말들이 나오게 될텐데, FULLTEXT는 당연히 MATCH - AGAINST로 검색했으니 적용이 되는 건 당연한 것이다. 그런데 Using filesort가 나온다. 해당 명령어의 의미는 MySQL 내부에 있는 세션 별로 존재하는 정렬 버퍼에서 데이터를 정렬한 후 너가 원하는 LIMIT 500개 만큼의 데이터를 가지고 왔다는 것을 의미한다.
앞에서 데이터 100만 건은 앞 부분을 '우리의'로 놓고 100만 건을 넣었었다. 특히, 이게 위험한 순간은 '우리의' 같은 단어를 검색할 때이다. 이게 정렬 버퍼의 메모리보다 크다고 하면, 디스크 영역까지 써서 어떻게든 MySQL에서는 정렬을 해서 결과를 가져오려고 들 것이고 다음과 같은 결과를 보게 된다.

그나마 LIMIT으로 줄이고, board_id만 가져와서 fetch 시간이라도 줄여서 그렇지 정말 난리가 났을 것이다. 만약에 내가 임의로 모임을 만들었을 때 '칵테일 모임' 이렇게 뒤에 모임을 붙여서 데이터를 서버에 넘겨줬다고 해보자. 이런 경우 '모임'이 들어간 검색을 FULLTEXT로 사용을 하게 되면 이런 결과가 나오게 될 것이다.
따라서, 이런 경우에는 강제로 stopword로 등록하여 막아주는 게 좋을 수도 있을 것 같다는 생각이 든다. 특히 FULLTEXT 인덱스는 특정 단어가 굉장히 쏠릴 수 있는 경우 검색을 조심해야 한다. 또한, 엄청 데이터가 큰 경우에는 사용하지 말라는 이유도... 이런 것에 있는 것 같다.
아무튼 이런 것에 대해서 다 고려했다고 치고 다시 그나마 나은 '제목 + 본문' 검색 최적화를 한다면 다음과 같이 검색을 위한 쿼리를 날릴 것 같다. 내부 단어에 대해서 검색 연산은 제외하였다.
아이디어는 다음과 같다.
- 쿼리를 두 개로 나눠서 description과 title을 둘 다 가지고 온다. 대신 내림차순으로 ids 값을 기준으로 정렬을 적용한다.
- 어플리케이션에서 두 개를 합친 다음 내림차순으로 정렬해서 11개만 제외하고 남긴다.
BoardJpaRepository.java
@Query(value = """
SELECT b.board_id
FROM board b
WHERE MATCH(b.title) AGAINST(:keyword IN BOOLEAN MODE)
ORDER BY b.board_id DESC
LIMIT :pageSize OFFSET :pageOffset
""", nativeQuery = true)
List<Long> fromBoardGetIdByKeyword(
@Param("keyword") String keyword,
@Param("pageSize") Long pageSize,
@Param("pageOffset") Long pageOffset
);
@Query(value = """
SELECT bd.board_id
FROM board_description bd
WHERE MATCH(bd.description) AGAINST(:keyword IN BOOLEAN MODE)
ORDER BY bd.board_id DESC
LIMIT :pageSize OFFSET :pageOffset
""", nativeQuery = true)
List<Long> fromDescriptionGetIdByKeyword(
@Param("keyword") String keyword,
@Param("pageSize") Long pageSize,
@Param("pageOffset") Long pageOffset
);BoardService.java
@Transactional(readOnly = true)
public List<BoardDto> getBoardByTitleOrDescription(String keyword, Long pageNumber) {
List<Long> board_ids = fromBoardGetIdByKeyword(keyword, pageNumber);
board_ids.addAll(fromDescriptionGetIdByKeyword(keyword, pageNumber));
List<Long> resultIds = getResultIds(board_ids);
return getBoardsByIds(resultIds);
}
private List<Long> getResultIds(List<Long> board_ids) {
return board_ids.stream()
.distinct()
.sorted(comparing(Long::longValue).reversed())
.limit(PAGE_SIZE + 1)
.toList();
}
private List<Long> fromDescriptionGetIdByKeyword(String keyword, Long pageNumber) {
return boardJpaRepository.fromDescriptionGetIdByKeyword(keyword, PAGE_SIZE + 1, (pageNumber - 1) * PAGE_SIZE);
}
private List<Long> fromBoardGetIdByKeyword(String keyword, Long pageNumber) {
return boardJpaRepository.fromBoardGetIdByKeyword(keyword, PAGE_SIZE + 1, (pageNumber - 1) * PAGE_SIZE);
}
private List<BoardDto> getBoardsByIds(List<Long> boardIds) {
return boardJpaRepository.findAllById(boardIds)
.stream()
.map(board -> new BoardDto(board.getId(), board.getTitle(), board.getAuthor()))
.sorted(comparing(BoardDto::boardId).reversed())
.toList();
}그러면 JOIN한 것과 똑같은 결과지만 27초 대로 가져오던 쿼리를 다음과 같이 0.268초 대로 개선을 할 수 있다. 하지만... 다시 한 번 강조하지만 FULLTEXT 자체로의 문제는 개선하기가 어려워 보인다. 다음에 프로젝트를 한다면 FULLTEXT 인덱스 대신에 Elastic Search로 다음엔 검색을 만들어야 겠다...
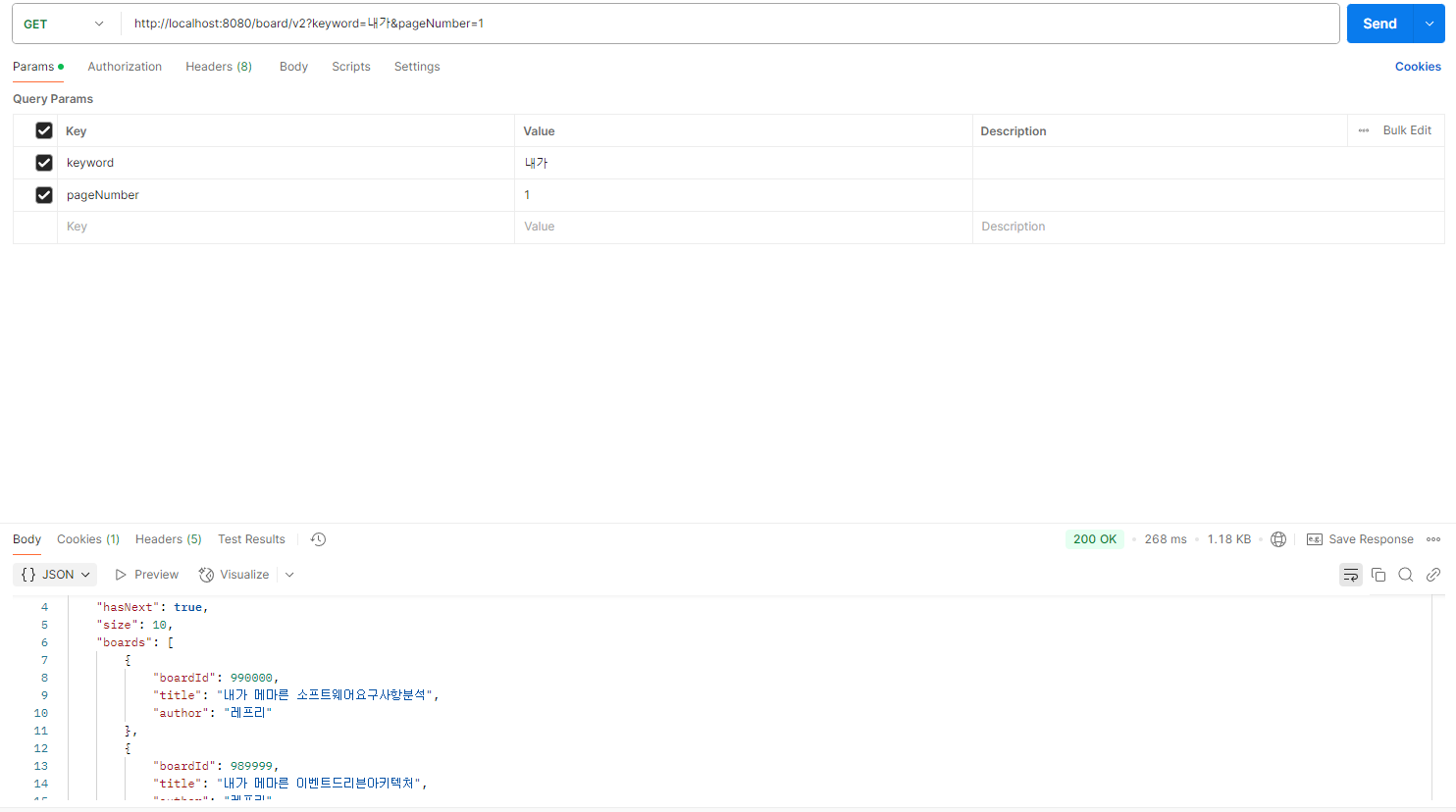
아무튼... 긴 긁 읽어주셔서 감사합니다.
참고자료
https://inpa.tistory.com/entry/MYSQL-%F0%9F%93%9A-%ED%92%80%ED%85%8D%EC%8A%A4%ED%8A%B8-%EC%9D%B8%EB%8D%B1%EC%8A%A4Full-Text-Index-%EC%82%AC%EC%9A%A9%EB%B2%95#%EB%B6%88%EB%A6%B0_%EB%AA%A8%EB%93%9C_%EA%B2%80%EC%83%89
Real MySQL 8.0 2권, 백은빈, 이성욱
