비교 정렬
1. 선택 정렬
- 우선 순위가 가장 높은 것을 하나 씩 찾아(선택) 리스트 맨뒤에 삽입한다.
- 실행시간 :
리스트에서 남은 원소를 순회하여 우선 순위가 가장 높은 것을 찾는 시간 : n
-> n + (n-1) + (n-2) ... + 1 = O() - 무순리스트 삽입/삭제와 같다.
A. 제자리 선택 정렬
- 일반적으로 이 방식을 사용한다.
- i번째~n번째 원소 중 가장 우선순위가 높은 것을 i번째 원소와 swap하는 과정을 i=1~n 동안 반복한다.
- 앞쪽이 정렬된 채로 유지된다.
2. 삽입 정렬
- 앞에서부터 차례로 하나씩 빼서, 정렬된 배열 중 적절한 위치에 삽입하는 과정을 반복한다.
- 실행 시간 :
정렬된 배열 속 원소들을 순회하며 삽입할 적절한 위치를 찾는 시간 : n
-> 1 + 2 + 3 ... + n = - 순서리스트 삽입/삭제와 같다.
A. 제자리 삽입 정렬
- 일반적으로 이 방식을 사용한다.
- 정렬되지 않은 첫 번째 원소 i를 i-1, i-2, ... 원소와 차례로 비교하며, 적절한 위치에 도달할 때까지 swap을 반복한다.
- 위 과정을 i=0~n까지 반복한다.
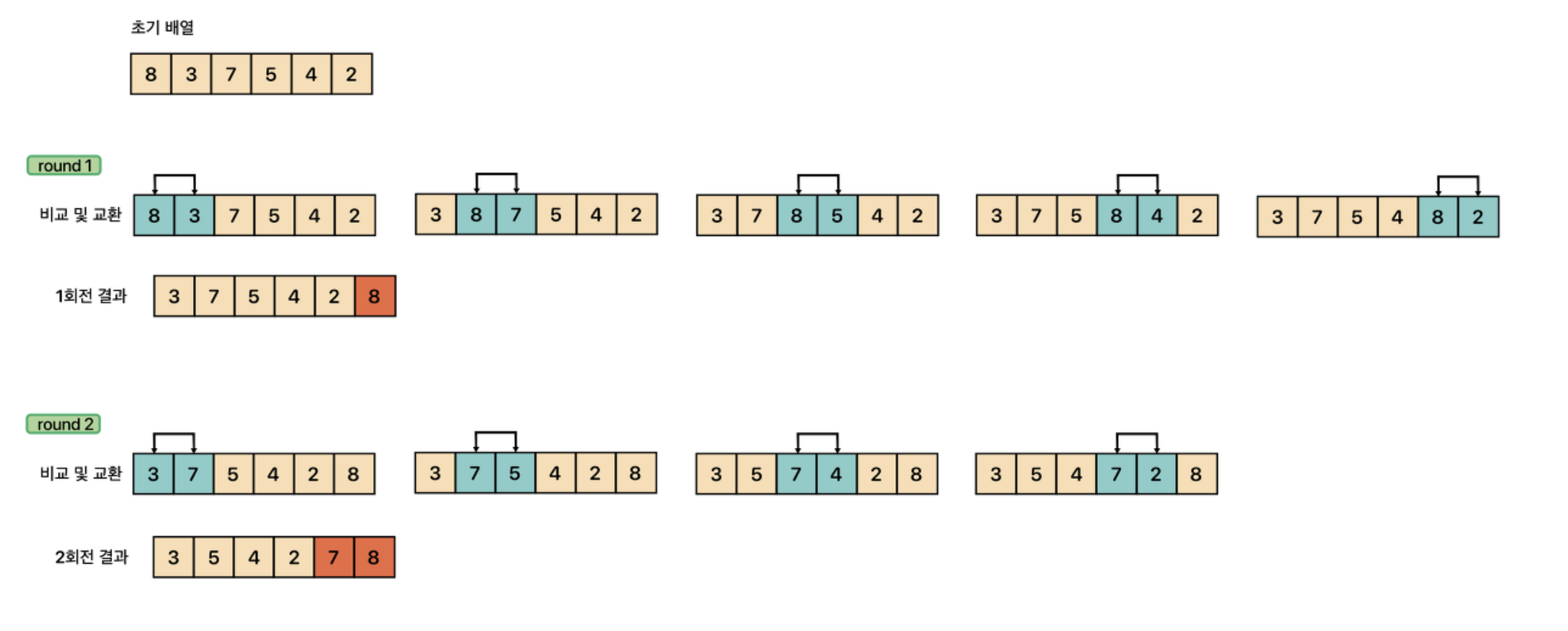
3. 버블 정렬
- 앞에서부터 2개씩 계속 비교하며, 앞이 더 크면 swap한다. 이렇게 1바퀴를 돌면 맨 뒤가 최대값이 된다.
- 비교하는 길이를 1씩 줄여가며 끝날 때까지 반복한다.
- 실행시간 :
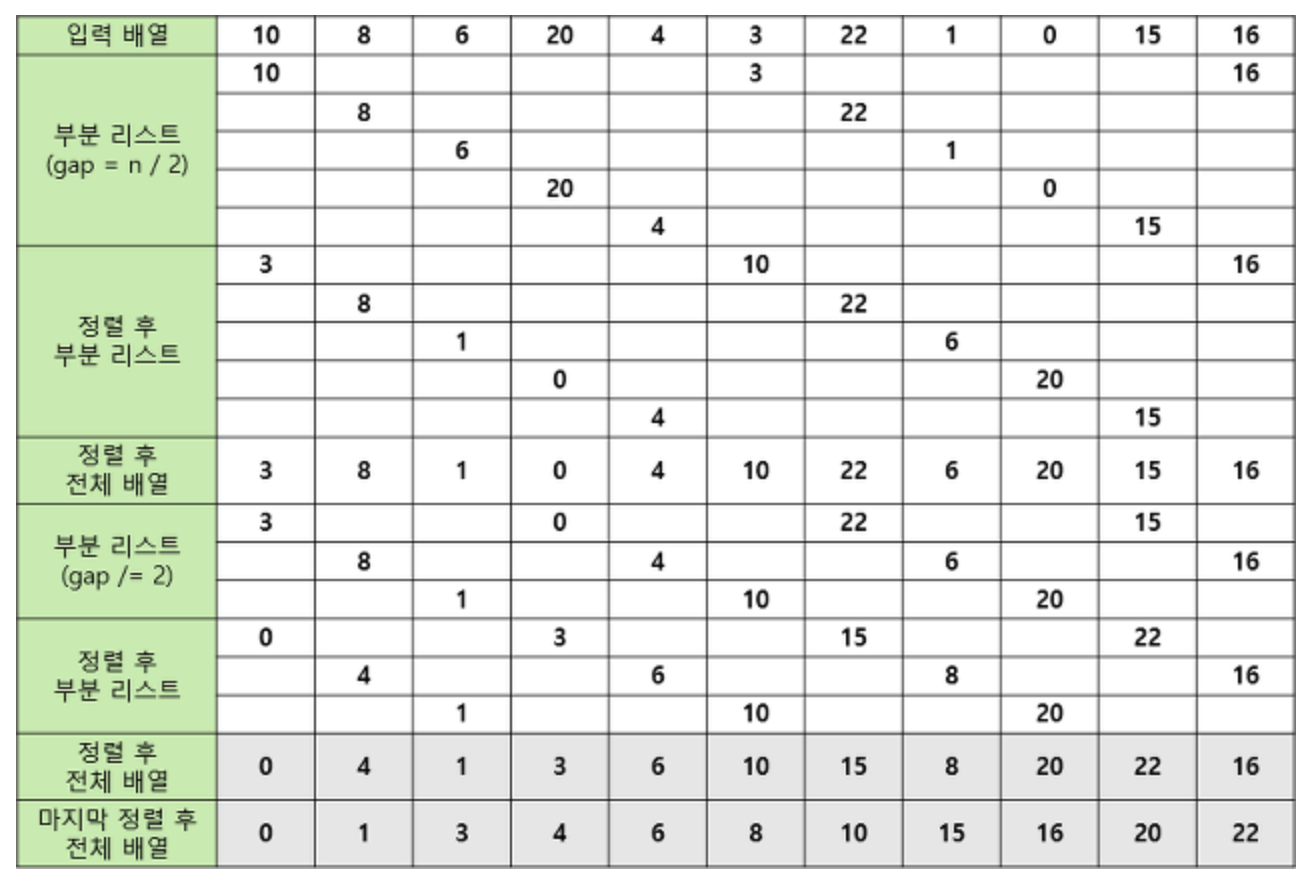
4. 쉘 정렬
- 삽입 정렬이 어느 정도 정렬된 리스트에선 매우 빠름에서 착안
- Gap(전체 개수/2) 마다 1개씩 원소들을 선택하여 substring으로 보고, substring을 삽입정렬로 정렬한다.
- 간격을 반으로 줄여가며 반복한다.
- 실행시간(실험적, 경험적)
- 최악 : O()
- 평균 : O()
5. 힙정렬
- 정렬되지 않은 리스트의 모든 원소를 하나씩 힙에 삽입한다.
원소의 수 n * 힙에 삽입&재정렬 시간 log - 힙의 루트를 차례로 하나씩 삭제해서 리스트 맨 뒤에 삽입한다.
원소의 수 n * 힙에서 min삭제&재정렬 시간 log
으로 총 시간복잡도 : ( log )
A. 제자리 힙 정렬
- 힙 정렬의 공간 사용을 줄인다.
- 0~i 첨자의 원소들을 힙, i+1 ~ n 의 원소들을 정렬되지 않은 리스트로 본다. i를 0부터 하나씩 늘리며, 그때마다 새 원소를 heap에 삽입된 것으로 보고 재정렬한다.
- 힙삽입 (시간복잡도 O(log))을 원소 수(n)만큼 반복
- 0~i 첨자의 원소들을 힙, i+1 ~ n의 원소들을 정렬된 리스트로 본다. i를 n부터 하나씩 줄이며, 0번째 원소와 i+1번째 원소를 swap하고 힙을 downheap으로 재정렬 하는 과정을 반복한다.
- 힙삭제(시간복잡도 O(log))을 원소 수(n)만큼 반복
으로 추가 공간 없이, 앞의 일반 힙정렬과 같은 성과를 보인다.
B. 상향식 힙 생성
- 힙 정렬의 속도를 높인다.
- 힙 정렬 중 1단계인 힙 생성 부분을 (하나씩 삽입 대신) 상향식 힙 생성법으로 바꾼다.
- 재귀적 방법
- 전체 구조를 완전이진트리로 본다.
- 후위탐색 순으로 방문하며, downheap을 반복한다.
- 비재귀적 방법
- 배열로 주어진 경우에만 가능하다.
- 번째 원소에서 1번째 원소(루트)까지 차례로 downheap을 진행한다.
- (외부노드는 제외하고) 내부 노드들에서 차례로 downheap을 진행하기 때문에 log 의 시간이 걸리게 된다.O( log )이지만, 사실상 O(n)정도의 시간이 걸린다.
- 1단계 실행시간이 줄고, 2단계 실행시간은 그대로O( log )의 시간이 걸린다.
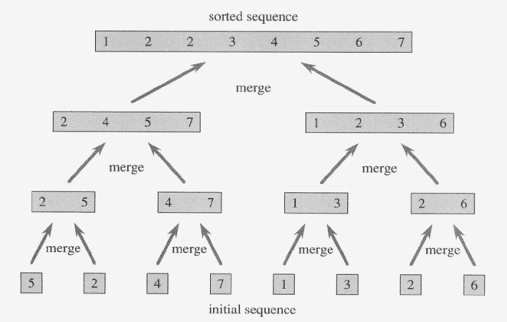
6. 합병 정렬
- 분할통치법
- 리스트를 반으로 나누어 sublist로 만드는 과정을 재귀적으로 수행
- (오름차순 정렬된) 두 sublist에서 각각의 맨 앞 원소를 비교해서 더 작은 것부터 삽입을 반복하는 방식으로 두 리스트를 합친다. 이 과정을 재귀적으로 수행한다.
- 두 sublist를 합치는 것에는 두 리스트 길이의 합 만큼의 시간이 걸린다.
- 수행시간 : O(n log n)
- 각 층마다 O(n)의 시간이 걸린다.
- 완전이진트리 구조로 총 높이는 log n이다.
7. 퀵 정렬
- 분할통치법
- pivot을 중심으로 pivot보다
작은 값, 같은 값, 큰 값3가지로 비균등 분류해서통치(결합)하는 과정을재귀적으로 실행한다. - 시간복잡도
- 최악의 경우 : O() - 이미 거의 정렬된 리스트가 주어질 경우
- 일반적으로 : O(log) - 각 층마다 O(n) * 기대 높이 log
- 평균적으로 같은 O(n log n)인 힙정렬이나 합병정렬보다 더 빠르다.
- 힙 정렬보다 swap 횟수가 적다.
- 합병 정렬과 달리 추가적인 메모리를 필요로 하지 않으며, locality가 높아서 page 교체(-> 메인 메모리 접근) 없이 cache에서 바로 참조할 수 있다.
https://medium.com/pocs/locality%EC%9D%98-%EA%B4%80%EC%A0%90%EC%97%90%EC%84%9C-quick-sort%EA%B0%80-merge-sort%EB%B3%B4%EB%8B%A4-%EB%B9%A0%EB%A5%B8-%EC%9D%B4%EC%9C%A0-824798181693
A. 제자리 퀵 정렬
- 맨 왼쪽 원소를 pivot, 그 옆을 left, 가장 오른쪽을 right라 둔다.
- left와 right를 하나씩 이동하다가, stop하면 둘을 swap하기를 반복한다.
- left를 하나씩 오른쪽으로 이동하다가 pivot보다 큰 값이 나오면 stop한다.
- right를 하나씩 왼쪽으로 이동하다가 pivot보다 작은 값이 나오면 stop한다.
- right < left가 되면, 경계과 pivot을 바꾼다. 이러면 pivot을 기준으로 나누어져있다.
- 좌우를 각각 sublist로 보고 재귀적으로 수행한다.

✨ 비교정렬의 하한 : O(n log n)
🎈 정렬의 안정성 : 동일한 키를 가진 원소들이 있을 때, 기존 순서가 보존되는가
- 선택, 삽입, 합병 : 안정적
- 힙, 퀵 : 불안정
일반정렬
1. 기수정렬
-
O(n log n) 깨는 유일한 정렬
-
비교정렬이 아니므로 비교정렬의 하한을 넘을 수 있다.
-
시간복잡도 : O(kn)
-
단점
- 추가적인 메모리를 많이 사용한다.
- 동일 길이의 숫자나 문자열만 정렬 가능하다.
-
방법
- i번째 자리 값을 기준으로, 해당하는 버킷에 차례로 넣다.(버킷 순서는 정해져 있다.)
- 버킷에서 차례로 뺀다.
- 작은 자리수 -> 큰 자리수로 차례로 진행한다.
위상정렬
- DAG(방향 비사이클 그래프)로부터 위상순서(진입차수가 0인노드에서 몇번째?)를 얻는 절차
- 위상순서를 여러 개 일 수 있다.
방향그래프에선, DAG <=> 위상순서를 가짐
1. topologicalSort
-
정점의 진입차수를 이용한 위상정렬
-
방법
- in에 진입차수(화살표 받는 수)들을 담고, in==0인 정점들을 큐에 담는다.
- 이때 큐에 들어가는 정점들의 위상순서는 1
- 큐에서 하나를 출력하고, 출력한 정점의 인접 정점들의 in을 하나씩 감소시킨다.(출력한 정점을 삭제/선택 한 것과 같다.)
- 새로 in==0이 된 정점들을 큐에 담고, 동일한 작업을 반복한다. 이때 삽입되는 정점들은 이전에 삽입된 정점들보다 위상순서가 +1 된다.
- in에 진입차수(화살표 받는 수)들을 담고, in==0인 정점들을 큐에 담는다.

기억은 나 대신 컴퓨터가