- State-Action Value Function
- state과 action에 모두 dependent
- 이전까지의 value function은 state에만 dependent
- state과 action에 모두 dependent
- 현재 state s에서, action a를 취했을 때, 우리가 앞으로 얻을 최대 누적 reward 기대값 구하기
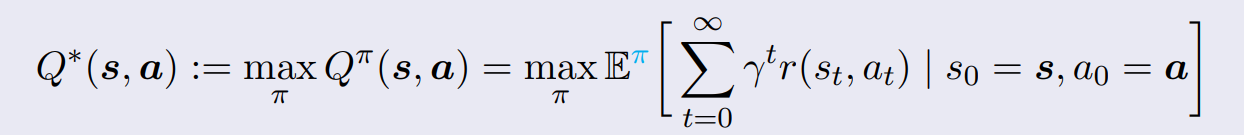
- policy 대신 action 최적화 가능하다.
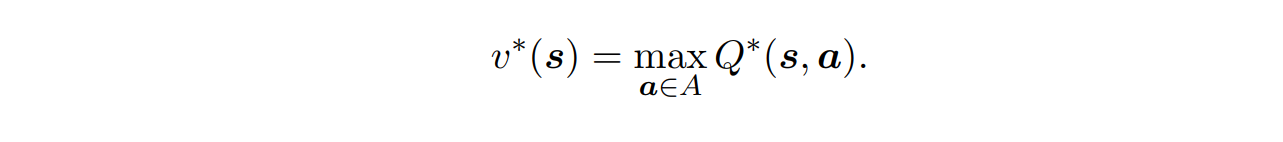
Bellman Equation for Q-Learning

LP formulation

policy iteration

Data-Driven PI


기억은 나 대신 컴퓨터가