Segmentation 대회 2주차 수행 내용 정리
강의
- segmentation 연구동향
대회 수행 내용
1. Visualization Utils
1) Multi Models Visualization
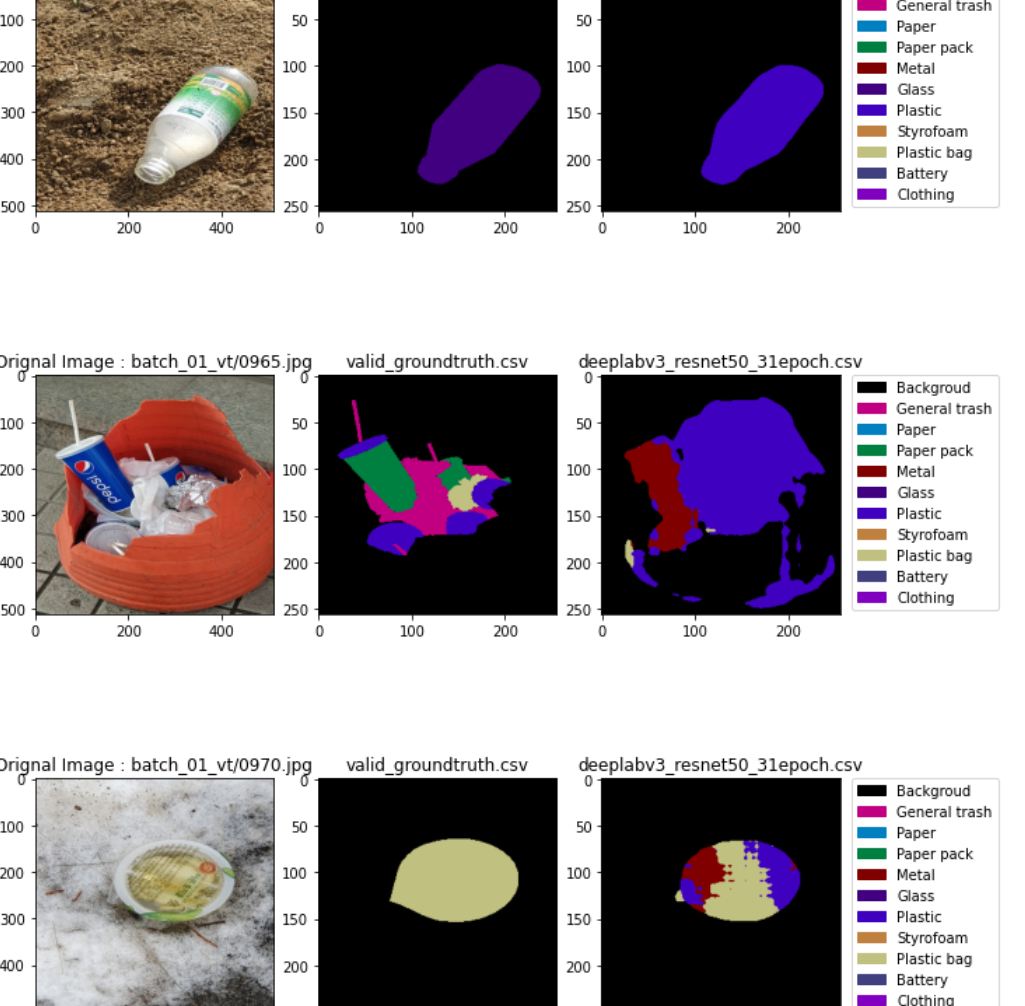
대회 중 제공된 모델 prediction visualization 코드를 변형하여, 여러 모델의 시각화 결과를 한 번에 비교할 수 있도록 만들었다.
코드 앞 쪽에 리스트 형태로 inference 결과로 나온 csv 파일 경로들을 입력하면, 아래와 같은 형태로 나란히 시각화된다.

2) Ground Truth 시각화
- valid annotation을 이용하여, ground truth를 submission과 같은 형태의 csv파일로 변환 & 저장한다.
코드 :make_valid_csv.ipynb
결과 : valid_groundtruth.csv
- valid data로 inference 수행하여 csv 파일을 만든다.
- 앞서 만든 visualization 코드를 활용해서, 동시에 시각화하여 비교해 본다.
목적
- 틀리는 부분 빠르게 한눈에 확인
- 안되는 이유가 annotation 부정확인지, model 성능 문제인지 바로 확인
2. Model 간 비교
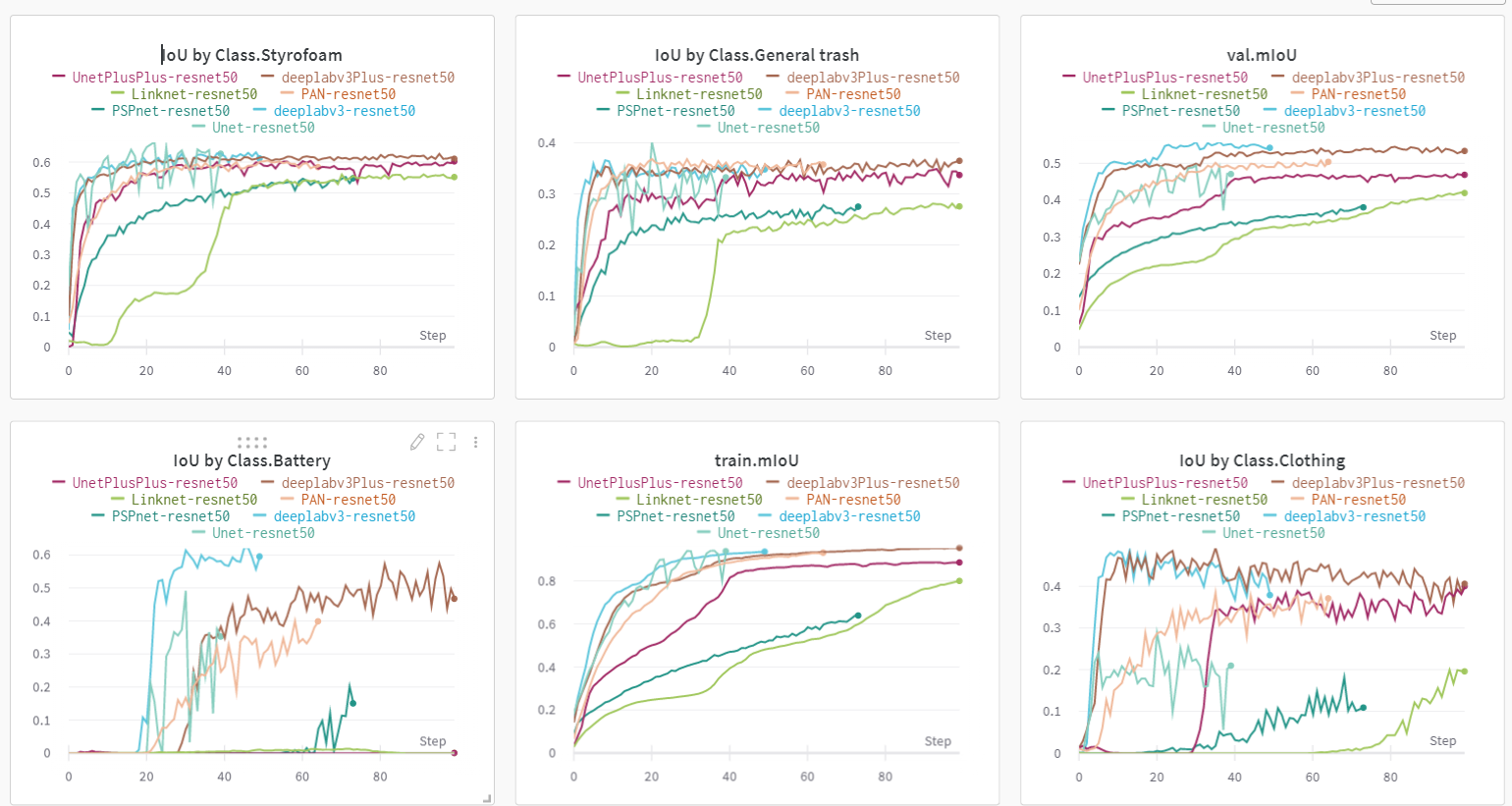
SMP library를 이용해서 바로 사용할 수 있는 기본적인 모델들을 돌려보며 성능을 비교하였다.
동일 조건으로 실험한 결과 DeepLabV3가 가장 성능이 좋아, 이후 기본으로 사용하였다.
3. Resize
-
가설1
: visualization을 했을 때, 한 덩어리의 물체가 여러 class로 나누어져 예측 되는 경우가 많이 보였다. 따라서 이미지 크기를 줄이면 좀 더 대략 적으로 보게 되어 성능이 올라갈 것으로 예측하였다.- 결과 : mIoU가 오히려 하락하였으며, class 별 IoU도 대부분 하락하였다.
- 해석 : visualization을 했을 때 눈으로 보기엔 대부분 결과가 나쁘지 않아 보였다. 대략적으로 보게 되며 우리 눈으로는 구분하기 어렵지만, 경계선 등이 제대로 학습되지 않는 것을 원인으로 추측하고 있다.
-
가설 2
: 가설 1과 같은 이유로 정확도가 떨어졌다면, 반대로 resize를 통해 크기를 키우면 정확도가 올라갈 것을 기대하였다.- 결과 : mIoU가 소폭 상승하였다.
[제출 기준 mIoU]
원본(512) : 0.580 → resize(1024) : 0.597 - 단 육안으로, 3가지 사이즈들을 비교해보면, 이미지를 크게 학습한 것이 더 좋은 것이 잘 느껴지지 않았다. 정확한 이유가 요소는 더 분석이 필요할 것으로 보인다.
- 또한 클래스 별로 학습이 잘되는 사이즈가 다른 것으로 나타났다. 클래스별로 따로 시각화 등으로 분석해 볼 필요가 있다.
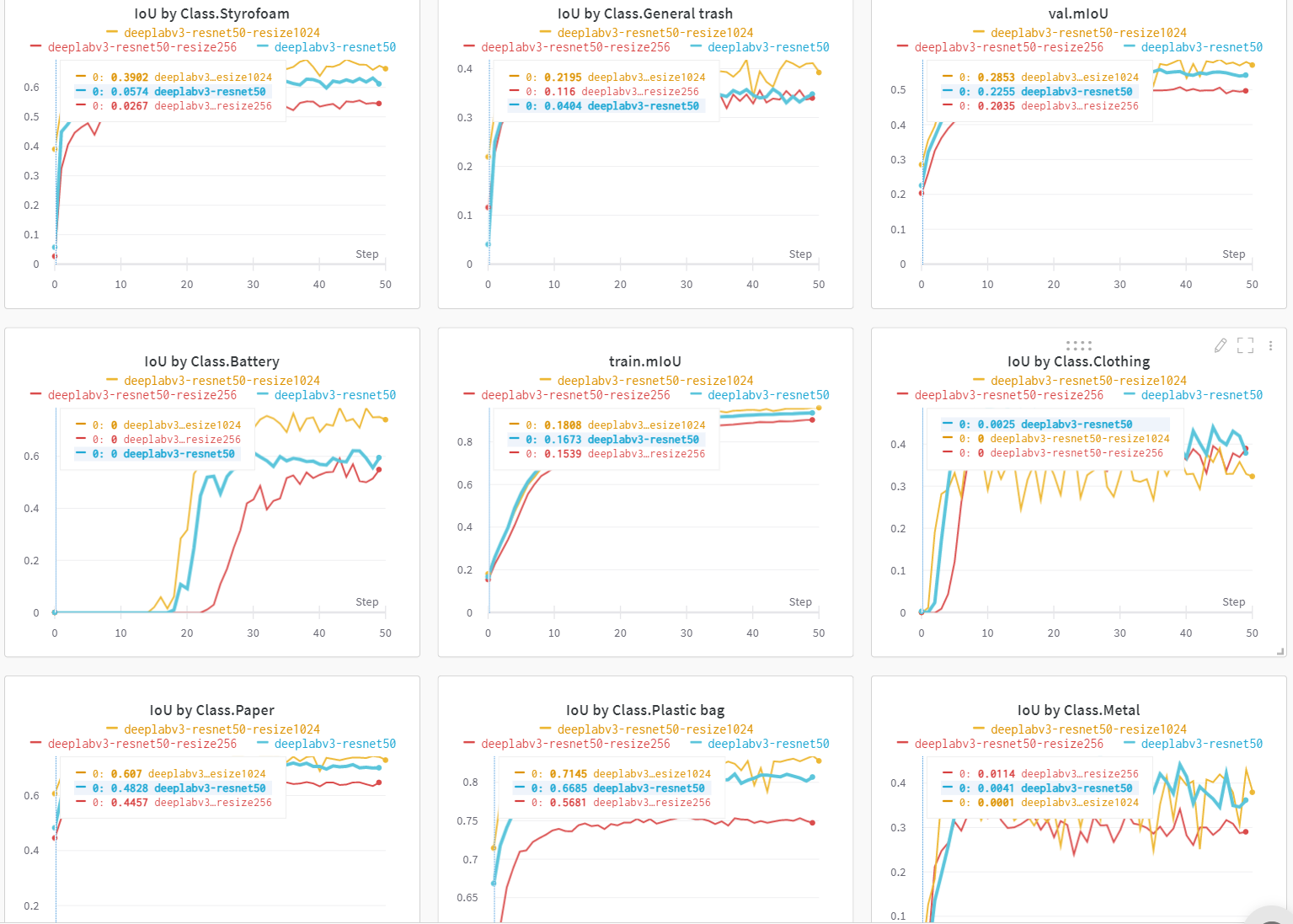

- 결과 : mIoU가 소폭 상승하였다.
회고
- 대회를 진행할수록 인공지능이 블랙박스라는 것이 실감이 된다. 성능이 좋아져도, 나빠져도 정확한 원인을 알기 어렵고, 모델의 중간 과정은 마냥 추측하는 느낌이 든다. 그 추측하는 시간이 흥미롭고 재미있기도 하고, 막막하기도 하다.
- 그럼에도... 유독 틀리는 클래스들 해결하기, class imbalance로 인한 특정 class overfitting문제, 클래스 별 시각화, 정답 정도에 따른 시각화, hyperparameter tunning, pseudo labeling 등 아직 해볼 것들이 많이 남은 것 같다. 남은 1주일도 안되는 시간 동안 어떤 것을 해보는 것이 가장 유의미한 도전이 될지 고민해보아야겠다.

기억은 나 대신 컴퓨터가