
2020년도 당시 실무 간 구현한 것을 개인블로그로 정리한 내용입니다.
들어가기
요즘 서버는 대부분이 동일한 애플리케이션 - 인스턴스를 여러대 두는 것이 대부분입니다.
이러한 멀티 서버 환경은 트래픽 분산 등의 이점을 누릴 수 있으나 스케줄을 사용하는 경우는 그 이야기가 다릅니다.
특정 일시에 한 번만 실행되어야하는 스케줄 작업이 있다고 할 때 해당 작업이 서버의 대 수 만큼 중복되어 진행될 위험성이 있기 때문입니다.
ShedLock은 이러한 중복실행을 방지할 수 있도록 해줍니다.
ShedLock 의 대한 간략한 설명
(공식 링크 : https://github.com/lukas-krecan/ShedLock)
if one task is already being executed on one node, execution on other nodes does not wait, it is simply skipped.
*만약 하나의 테스크가 하나의 노드에서 진행 중이라면 다른 노드는 테스크를 대기하지 않고 지나간다.
shedlock은 데이터 저장소에 스케줄링 작업에 대한 데이터를 삽입/갱신하여
각 인스턴스들이 해당 작업의 진행여부를 공유 할 수 있도록 합니다..
다양한 데이터 저장소(MySQL, Elastic Search, MongoDB, Redis 등) 를 통해 구현이 가능하지만 여기서는 MySQL을 사용하도록 하겠습니다.
ShedLock을 사용하려면..
Java 8
slf4j-api
자바 8을 사용하며 slf4j-api 의존성이 추가 되어야합니다.
위 환경 세팅을 마무리한 뒤에 다음과 같이 의존성 추가를 진행합니다.
(작성일 2020.11.04 기준 최신버전)
ShedLock Dependency
implementation 'net.javacrumbs.shedlock:shedlock-spring:4.14.0'
implementation 'net.javacrumbs.shedlock:shedlock-provider-jdbc-template:4.14.0'의존성이 추가 되었다면 @EnableSchedulerLock 애노테이션과 LockProvider config를 추가해줍니다.
(defaultLockAtMostFor은 작업을 진행 중이 노드가 예기치 않게 종료된 경우 Lock을 유지할 기본시간을 뜻합니다. )
@EnableSchedulerLock(defaultLockAtMostFor = "PT30S")
@EnableScheduling
@SpringBootApplication
public class ApiApplication
{
public static void main(String[] args) {
SpringApplication.run(ApiApplication.class, args);
}
}LockProvider는 데이터 저장소를 사용하여 Lock정보를 삽입/갱신할 수 있도록 합니다.
@Log4j2
@Configuration
public class DatabaseConfig
{
private final DataSourceProperty dataSourceProperty;
@Autowired
DatabaseConfig(
DataSourceProperty dataSourceProperty)
{
this.dataSourceProperty = dataSourceProperty;
}
private DataSource createDataSource(dataSourceProperty.Base dataSourceProperty, String dbUser, String dbPassword)
{
HikariDataSource hikariDataSource = (HikariDataSource) DataSourceBuilder.create()
.driverClassName(dataSourceProperty.getDriverClassName())
.url(dataSourceProperty.getJdbcUrl())
.username(dbUser)
.password(dbPassword)
.build();
log.info(String.format("DB Setting // username: %s", dbUser));
hikariDataSource.setMaximumPoolSize(dataSourceProperty.getMaximumPoolSize());
return hikariDataSource;
}
// ..중략
//Schedlock config
@Bean
public LockProvider lockProvider()
{
DataSource masterDataSource = createDataSource(dataSourceProperty.getMaster(),
dataSourceProperty.getMaster().getUsername(),
dataSourceProperty.getMaster().getPassword());
return new JdbcTemplateLockProvider(masterDataSource);
}
}마지막 데이터베이스에 다음과 같은 테이블을 생성해야 합니다.
CREATE TABLE `shedlock` (
`name` varchar(64) NOT NULL COMMENT '스케줄잠금이름',
`lock_until` timestamp(3) NULL DEFAULT NULL COMMENT '잠금기간',
`locked_at` timestamp(3) NULL DEFAULT NULL COMMENT '잠금일시',
`locked_by` varchar(255) DEFAULT NULL COMMENT '잠금신청자',
PRIMARY KEY (`name`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4위 테이블에 스케줄과 lock에 대한 정보가 삽입/갱신 됩니다.
*위 테이블의 데이터를 수동으로 삭제하지 말아야 합니다. shedlock은 인 메모리 캐시를 지니고 있기 떄문에 애플리케이션이 다시 시작될 때 까지 row를 재생성하지 않습니다.
다시 말해 row가 수동으로 삭제될 경우 lock에 대한 update 정보가 누락되게 됩니다.
ShedLock 사용하기
모든 준비가 끝났습니다.
사용법은 간단합니다. 스케줄이 걸려있는 메소드 위에 ShedLock 애노테이션을 달아주면 됩니다.
private static final String ONE_MIN = "PT1M"; // 1분동안 Lock
private static final String SEC_59 = "PT59S"; // 59초동안 Lock
//60초 마다 실행
@Scheduled(cron = "*/60 * * * * *")
@SchedulerLock(name = "testShedLockJob", lockAtLeastFor = SEC_59, lockAtMostFor = SEC_59)
public void testShedLockJob() throws InterruptedException
{
log.info("================task has been stared===============");
log.info("================Server Port : " + port + " ===============");
Thread.sleep(3000L);
log.info("================task has been ended===============");
}- name : 스케줄 작업의 고유 이름입니다. 해당 문자열은 shedlock 테이블의 name 칼럼으로 기본키 역할을 하게 되므로 스케줄 작업의 고유한 이름을 입력해야합니다.@SchedulerLock 애노테이션을 살펴보면 다음과 같습니다.
- lockAtLeastFor : 작업이 lock 되어야 할 최소한 시간을 입력합니다. 짧은 작업일 경우 노드간의 클럭 차이로 중복 실행되는 것을 막기 위함입니다.
- lockAtMostFor : 작업을 진행 중인 노드가 소멸될 경우에도 lock 이 유지될 시간을 입력합니다. 해당 시간은 실제 작업에 소요되는 시간보다 훨씬 길게 해야합니다. 그렇지 않을 경우 예상치 못한 스케줄 작업이 일어날 수 있습니다.
해당 시간을 따로 입력하지 않으면 @EnableSchedulerLock의 디폴트 값으로 세팅 됩니다.
*Lock 시간은 보통 실행 주기 -1 을 권장하고 있습니다.
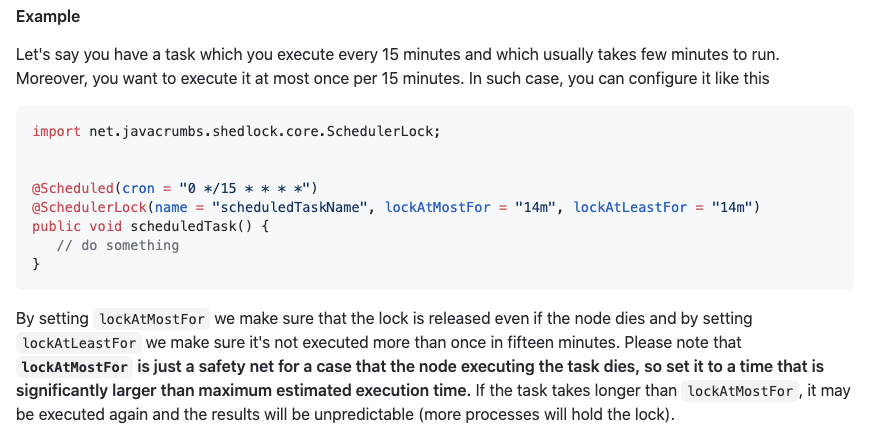
몇 분의 실행시간이 걸리는 작업을 15분 단위로 진행한다고 하였을 때 권장되는 Lock시간은 14분입니다.
실행시간이 짧은 경우 주기 내에 한 번 이상의 실행을 방지하기 위함입니다.
때문에 위에서 말한 대로 lockAtMostFor 시간은 실제 실행시간보다 훨씬 길게 입력되어야 합니다.
테스트하기
아래 스케줄 작업은 60초마다 실행이 되며 3초의 실행시간 59초의 Lock 타임을 지니고 있습니다.
이를 8080포트와 8090 포트를 사용하는 각 두 개의 서버로 실행시켰습니다.
private static final String ONE_MIN = "PT1M"; // 1분동안 Lock
private static final String SEC_59 = "59S"; // 5분동안 Lock
//60초 마다 실행
@Scheduled(cron = "*/60 * * * * *")
@SchedulerLock(name = "testShedLockJob", lockAtLeastFor = SEC_59, lockAtMostFor = SEC_59)
public void testShedLockJob() throws InterruptedException
{
log.info("================task has been stared===============");
log.info("================Server Port : " + port + " ===============");
Thread.sleep(3000L);
log.info("================task has been ended===============");
}
8080 포트를 사용하는 서버입니다. 작업이 시작된 때에 shedlock(최초에는 insert가 먼저 실행됩니다.) 업데이트를 진행합니다.
locked_at 을 보시면 17:33:00.019 로 업데이트가 진행되었고 해당 서버가 정상적으로 작업을 진행한 것을 볼 수 있습니다.

8090 포트를 사용하는 서버입니다. 해당 서버 역시 update를 진행합니다. locked_at는 17:33:00.025로 8080 포트 보다 아주 근소하게 늦은 차이로 lock을 시도한 것을 볼 수 있습니다.
하지만 해당 서버는 스케줄 작업을 진행하지 못하였습니다.

db의 shedlock 테이블의 locked_at 칼럼 값을 보면 8080서버가 업데이트를 한 것과 동일합니다.
db update를 통해 lock을 선점한 노드가 작업을 실행하고 이 외의 노드는 작업을 skip 하는 것으로 나타났습니다.
마무리
현업 이메일 발송 부분에 shedlock 이 적용되어 운영 중입니다.
실제 실행 주기에 따라 shedlock 이 정상적으로 업데이트 된 것을 볼 수 있습니다.
추후 locked_by 칼럼 데이터를 커스터마이징 할 수 있다면 어떤 인스턴스에서 실행 되었는지를 보다 손쉽게 파악할 수 있을 것으로 보입니다.

안녕하세요 정리해두신 글 잘 읽었습니다. 스케쥴 락을 걸어 다른 was에서 실행시 최초 insert가 되면
제약조건에 걸려 한쪽 서버에서는 에러가 발생하고 그 이후부터는 락이 걸렸다고 나옵니다.
최초에 insert시 해결 방법이 있을까요/?