
Shenandoah ?
Shenandoah GC는 Red Hat 에서 개발하고 OpenJDK 12에 출시된 Garbage Collector다. 일명 low-pause GC라고 불리며 '큰 GC 작업을 적은 횟 수로 수행하는 것 보다 작은 GC 작업을 여러번 수행하는 게 낫다'라는 컨셉이다. Shenandoahs는 작은 단위의 GC 수행을 자주하기 위해 Concurrency를 보장한다. 이 말 뜻은 GC가 CPU 를 더 사용하는 대신 pause(Stop-The-World) 시간을 줄이겠다는 의미다.
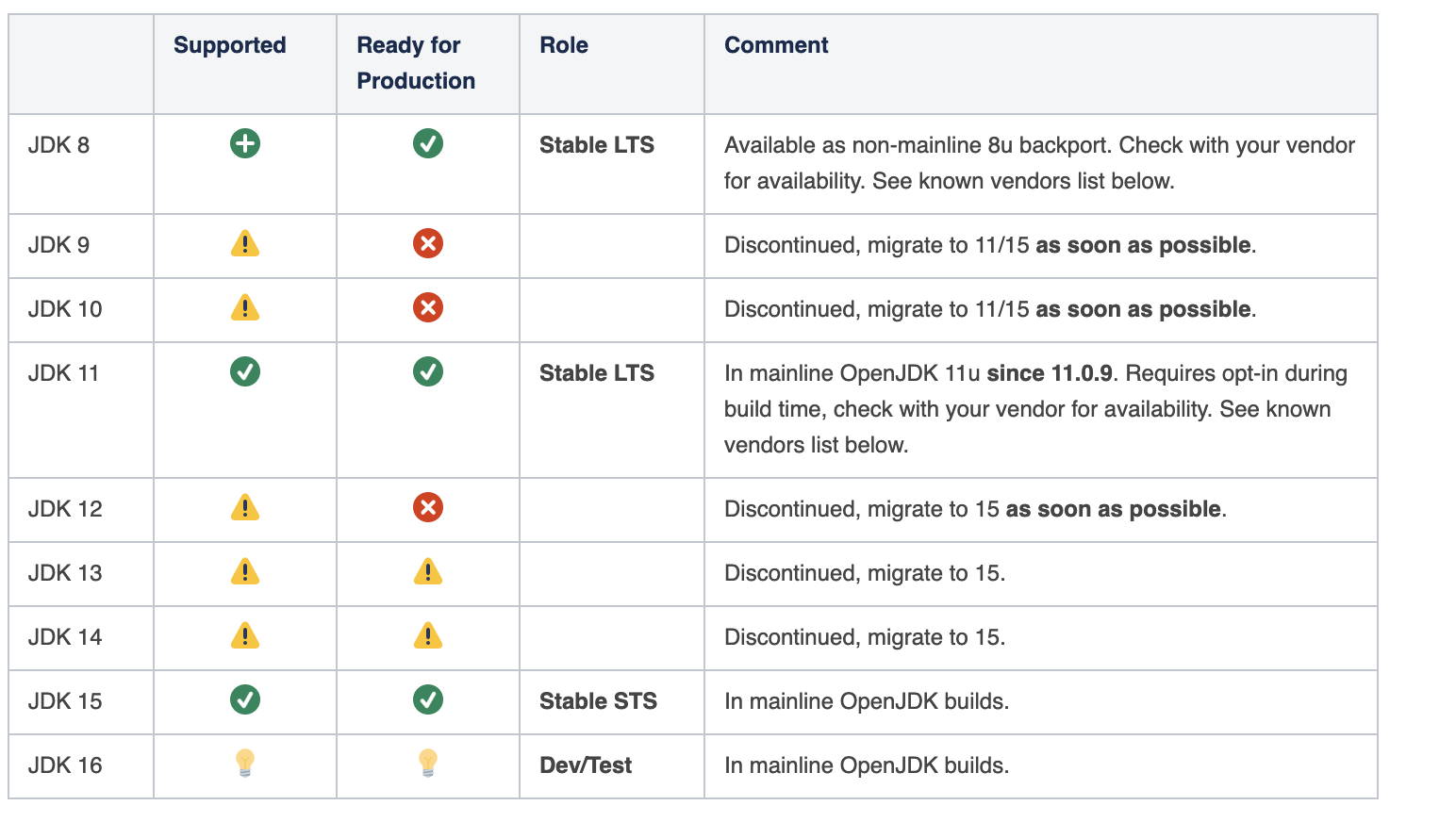
Support
또 다른 차세대 low-pause GC로 Oracle의 ZGC가 존재한다. Shenandoah와 거의 비슷한 메커니즘을 가지고 있지만 Shenandoah는 OpenJdk 12에 등장하여 jdk11, jdk8까지 backporting 지원 을 하였다. 반면, ZGC는 jdk11 이상의 버전만 지원한다.
JDK Support
https://wiki.openjdk.java.net/display/shenandoah/Main
문서에서는 openJdk12 upstream 이라고 표기해두었지만 어떤 이유에선지 작성일기준(2021.07.13) JDK 12버전은 support가 안되고 있는 상황이다.
Performance
Shenandoah는 기존 CMS가 가진 Fragmentation(단편화), G1이 가진 Stop-The-World 의 이슈를 시원하게 해결하였다. 강력한 Concurrency와 가벼운 GC 로직으로 heap 사이즈에 영향을 받지 않고 일정한 Pause 시간이 소요된다.
어떻게 해결하였는지는 아래에서 살펴보자.
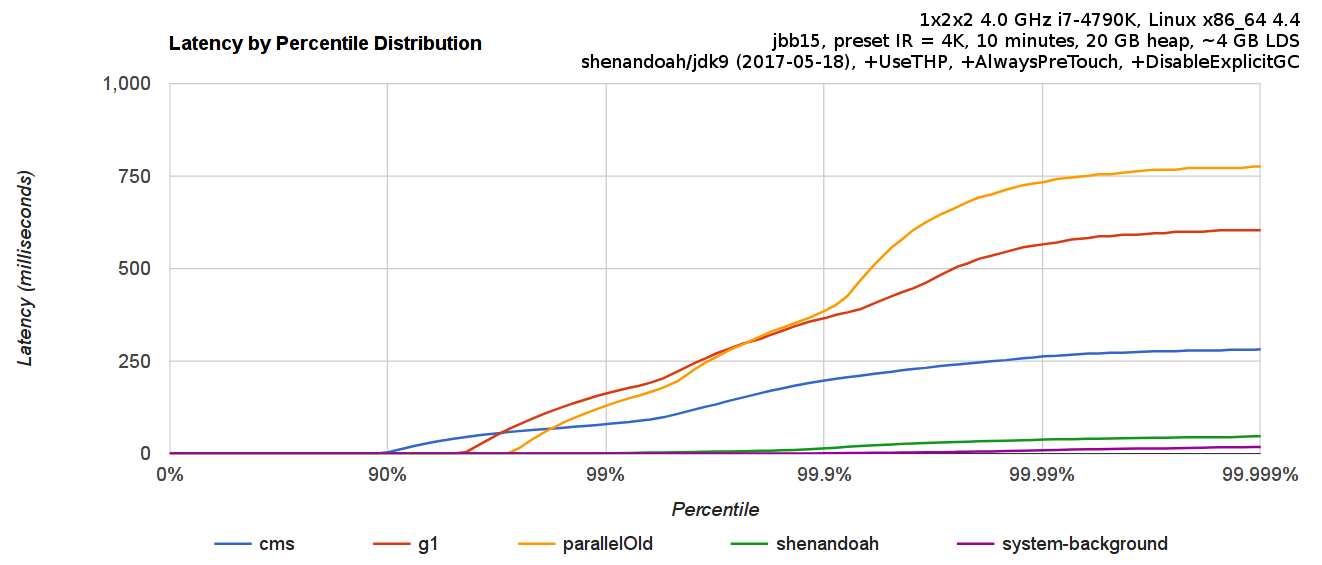
(GC 구현방식별 지연시간 그래프. 보시다시피 많이 빠르다.)
Single-Generational
위에서 언급했듯 Shenandoah는 G1을 기반으로 한다.
Jvm heap을 Region 별로 나누고 mark-sweep & evacuation을 진행한다.
그러나 Shenandoah는 G1과 다르게 Generation으로 영역을 나누지 않는다.
"GC에 익숙한 사람이라면 모두 Generational GC가 최고라고 이야기합니다. 'generational hypothesis 는 대부분 상황에서 Young Object는 Old Object 보다 죽을 가능성이 클 것으로 내다본다.' 2008년에는 맞는 말이었죠. 하지만 지금은 설득력이 떨어집니다."
Red Hat 개발자 Christine Flood - DevNation 2016 中
Shenandoah GC: Java Without The Garbage Collection Hiccups (Christine Flood)


(Shenandoah VS G1 BenchMark에서도 볼 수 있드시 Shenandoah는 압도적인 성능을 보여준다.)
Generation에 따라 영역을 나누고 Evacuation 과정에서 메모리 copy가 계속해 일어난다. Shenandoah는 generational hypothesis이 더 이상 유효하지 않기에 Generational copy의 대한 비용을 차라리 없애버리겠다라고 이야기한 것이다.
그래서 Shenandoah 는 Single-Generational 이다.
Generational Shenandoah
지속 가능한 처리량, 로드 스파이크 복원력 및 메모리 활용률 향상 등 이유로 Generation Shenandoah가 등장했다.
가장 최근 update가 2021.07.12에 인 것으로 보아 한창 개발 중인 것으로 보인다.
그래도 Single-Generational Shenandoah는 유지된다.
"Generational을 의무화하는 것은 목표가 아닙니다. 성능 저하 또는 기능 저하 없이 단일 세대 Shenandoah를 사용할 수 있는 옵션은 유지됩니다."
JEP 404: Generational Shenandoah
Low-Pause

위 그림을 살펴보자.
low-pause 의 대표 ZGC와 Shenandoah가 있고 이 두 가지는 이전 GC 들과 확연한 차이를 드러낸다. 앞 서 언급하였듯, Young Generation -> Old Generation으로의 Copy로 인한 pause는 이미 제거하였다. 또한, 기존 G1에서 해결하지 못하였던 Compact 단계의 pause 또한 Concurrent Compact로 해결하였다. 결국 CMS의 Mark-Sweep, G1의 Compact 의 장점을 모두 Concurrent 하게 구현하여 이점을 챙겼다.
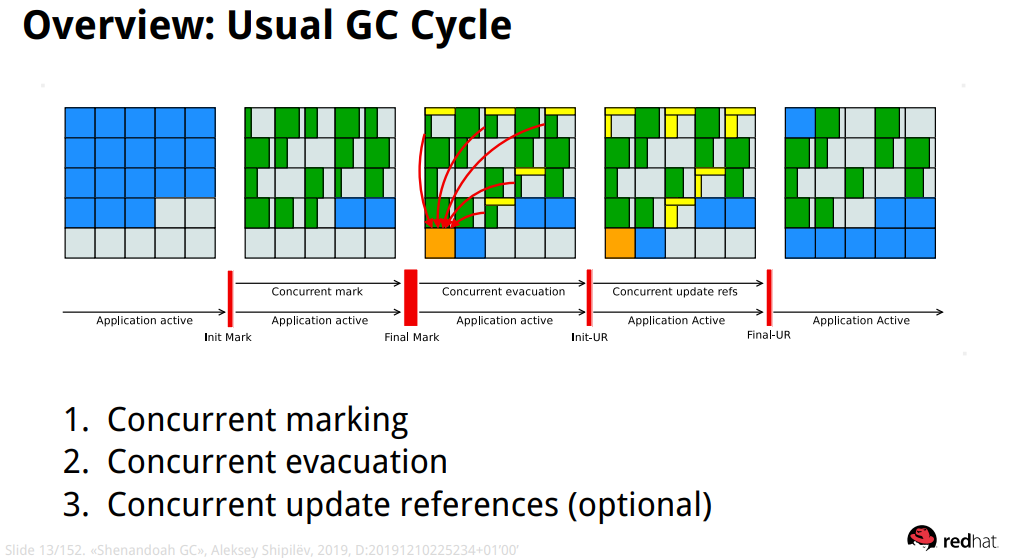
GC Cycle
GC(3) Pause Init Mark 0.771ms
GC(3) Concurrent marking 76480M->77212M(102400M) 633.213ms
GC(3) Pause Final Mark 1.821ms
GC(3) Concurrent cleanup 77224M->66592M(102400M) 3.112ms
GC(3) Concurrent evacuation 66592M->75640M(102400M) 405.312ms
GC(3) Pause Init Update Refs 0.084ms
GC(3) Concurrent update references 75700M->76424M(102400M) 354.341ms
GC(3) Pause Final Update Refs 0.409ms
GC(3) Concurrent cleanup 76244M->56620M(102400M) 12.242ms-
Init Mark는 concurrent marking를 시작합니다. Heap과 스레드는 concurrent marking를 위한 준비를 하고 다음 root set을 검사합니다. 이는 사이클간 첫번째 pause이며, root set scan이 가장 큰 부하로 작용합니다. 따라서 root set 의 크기가 pause 시간을 결정합니다.
-
Concurrent Makring는 Heap을 전반에 걸쳐 Reachable object를 추적합니다. 이 단계는 애플리케이션 중지 없이 실행되며, live object의 수와 Heap object graph structure 에 따라 소요 시간이 결정됩니다. 이 단계에서 애플리케이션은 자유롭게 new 데이터 할당이 가능하여, Concurrent Makring 간 heap 점유율이 증가합니다.
-
Final Mark는 보류 중인 marking/update queue를 모두 비우고 root set를 재탐색하여 Concurrent Makring을 완료합니다. 또한 이동 가능한 region을 파악하여 Evacuation 초기화 및 일부 root를 이동시킵니다. 일반적으로 다음 단계를 위한 runtime을 준비합니다. 이 작업의 일부는 Concurrent Pre-cleaning 단계에서 동시에 수행할 수 있습니다. 이것은 사이클 간 두번째 pause를 발생시킵니다. Queue를 비우고 root scanning 하는 것에 대부분 시간을 소요합니다.
-
Concurrent Cleanup은 즉시 garbage 영역, 즉 concurrent mark 후 live 객체가 없는 영역을 비웁니다.
-
Concurrent Evacuation은 collection set에서 벗어난 object를 다른 region으로 복사합니다. 이 단계는 애플리케이션과 다시 실행되므로 애플리케이션을 자유롭게 메모리 할당이 가능한데, 이는 다른 GC와의 가장 큰 차이점입니다.. collection set크기 설정에 따라 소요시간이 결정됩니다. (Collection Set (CSet): GC가 수행될 region이 저장되어 있는 자료구조)
-
Init Update Refs는 Update References 단계를 초기화합니다. 모든 GC, 스레드가 evcuation을 종료하였는지 확인하고 다음 단계를 준비하는 것 외에는 거의 아무것도 하지 않습니다. 이번이 사이클에서 세 번째 pause 이며 가장 짧습니다.
-
Concurrent Update References는 Heap 전반에 걸쳐 concurrent evacuation된 Object 참조를 갱신합니다. 이 또한 GC와의 가장 큰 차이점입니다. Heap 존재하는 Object수에 따라 소요시간이 결정되지만, Heap을 연속적으로 탐색하기 때문에 object graph structure는 영향을 끼치지 않습니다. 이 단계는 애플리케이션과 동시에 실행됩니다.
-
Concurrent Cleanup은 참조가 없는 region을 회수합니다.
Concurrency
이와 같이 Shenandoah는 애플리케이션 수행과 동시에 background에서 GC 알고리즘 수행을 목적으로 두고 있다. 다만, GC 알고리즘 간 Heap의 Concurrency를 보장하는 것이 쉽지 않을 것으로 보이는데, Shenandoah 아래와 같이 이 문제점을 해결하였다.
Snapshot at the beginning (SATB)
SATB는 Concurrent marking 이 가능하게 해주는 방식이다. CMS, G1에서도 사용하는 방식인데 Red Hat 개발자 Christine Flood 가 직접 G1 쓰던 코드를 그대로 사용했다라고 얘기한다.

기본적으로 Marking 알고리즘은 object를 3가지 색으로 나눈다.
1. 흰색 : 아직 도달하지 못한 object
2. 회색 : 도달했으나 해당 object의 참조내용이 탐색이 되지 않은 object
3. 검정색 : 도달, 참조내용 탐색이 완료된 object
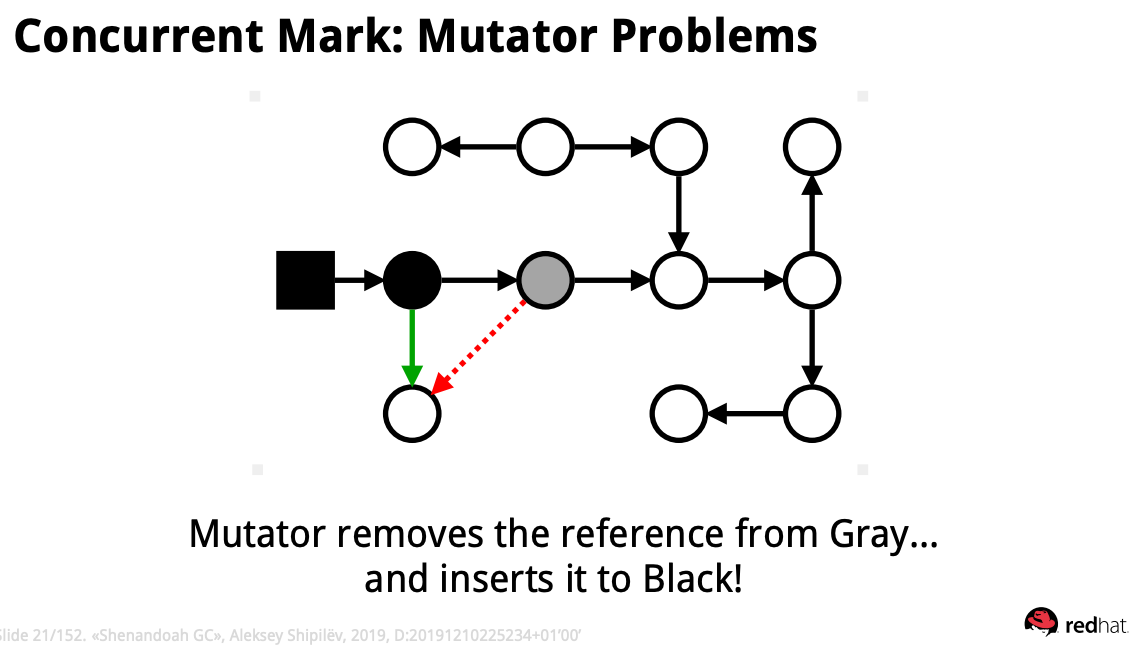
위 상황을 살펴보자.
회색으로 표시된 object에 도달하였고 reference scanning 를 하는 중이다.
그러나 애플리케이션에서 회색처리된 object을 삭제하고 검은색 object가 참조하도록 변경하였다면?
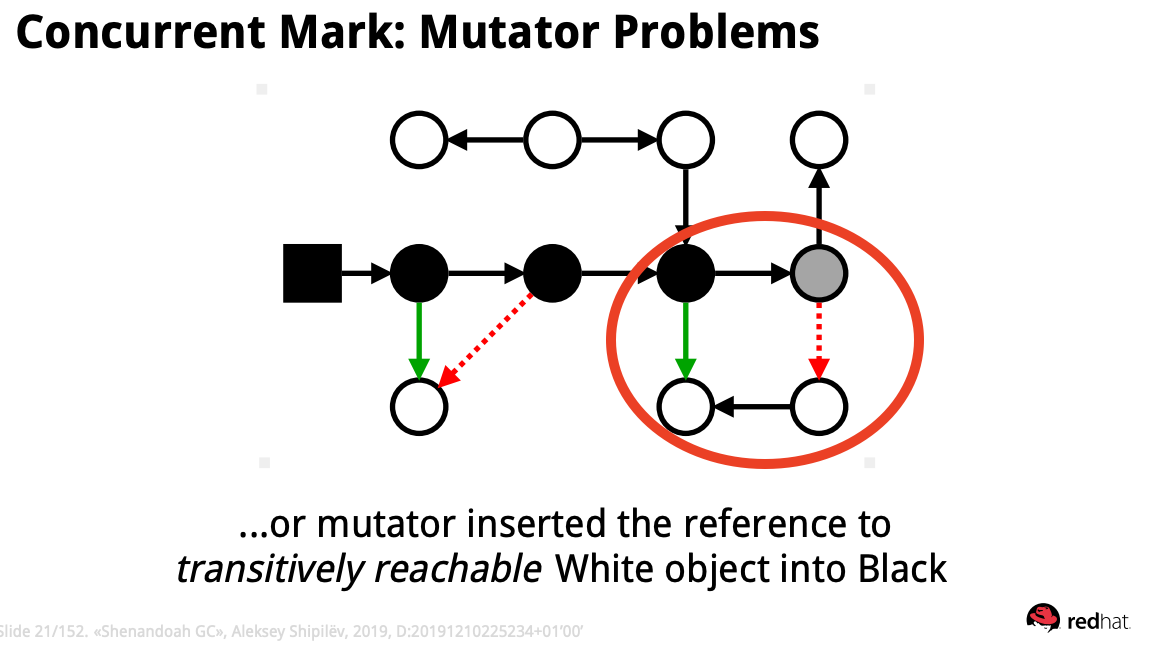
혹은 위와 같이 돌고 돌아 참조될 object(빨간색 동그라미 친부분)의 래퍼런스를 직접적으로 검은색 object가 참조하도록 변경하면?
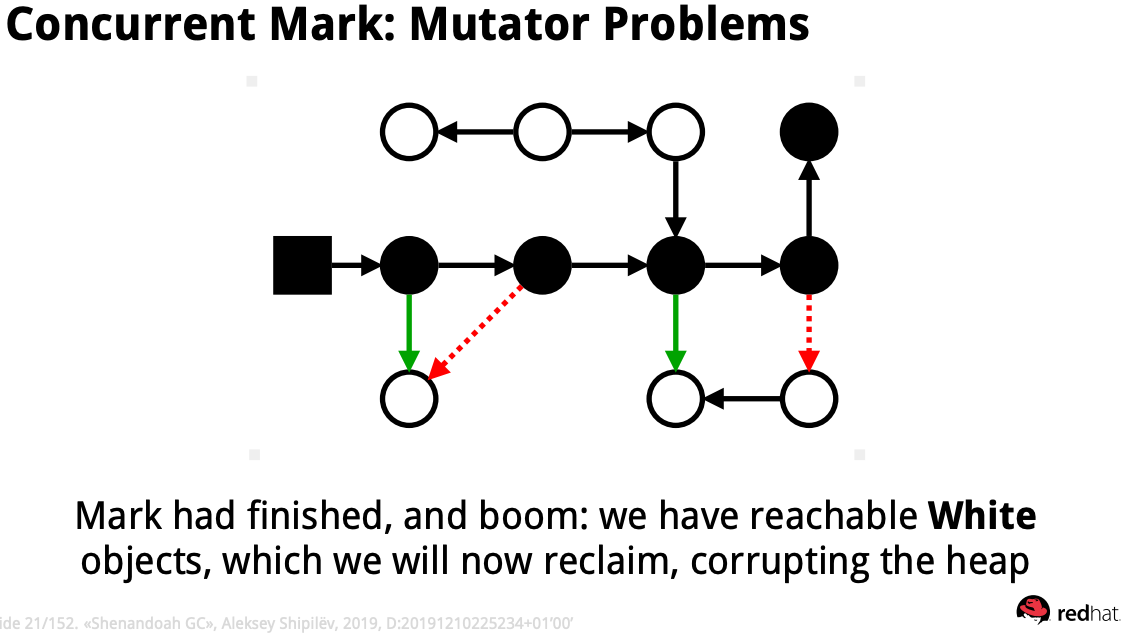
이대로 두면 위 그래프에서 marking된 검정색 object는 살아남을 것이고, 흰색 object들은 GC에 의해 제거될 것이다. 완전히 망했다고 보면된다.
이를 막기위해 Snapshot at the begining 필요한 것이다.
말 그대로 처음 object 그래프를 스냅샷하는 것으로 marking 후 그래프와 marking 전 그래프를 비교하여 위와 같은 상황을 보완하는 것이다.
SATB는 어떻게 동작할까? - Shenandoah 개발자 Roman Kennke의 글 中
Marking 간 SATB는 어떻게 동작할까?
우리는 write barrier 를 사용한다.
이는 mutator 스레드가 Object의 참조 필드를 쓸 때 마다 호출되는 별도의 hook이다. (또 다르게 barrier라 불리는 memory fences 혼동하지 않도록 한다).
write barrier는 reference가 수정되기 이전 원래 내용을 linked list에 기록한다. 모든 concurrent marking 단계가 완료되어 Stop The World가 발생하면, linked-list의 모든 object를 표시하고 SATB-list를 만든다. 앞선 모든 작업이 끝나 애플리케이션은 작동을 재개하였을 때, Marking 단계의 시작에서 모든 object들이 live인 것으로 표시됨을 확인할 수 있다. 또한 marking 동안 live object의 수를 카운팅하여 얼마나 많은 object가 각 region에 존재하는지 알 수 있다.
Shenandoah GC: Concurrent parallel marking
이렇게 만들어진 SATB가 가진 정보를 갖고 추가적인 marking이 진행된다.
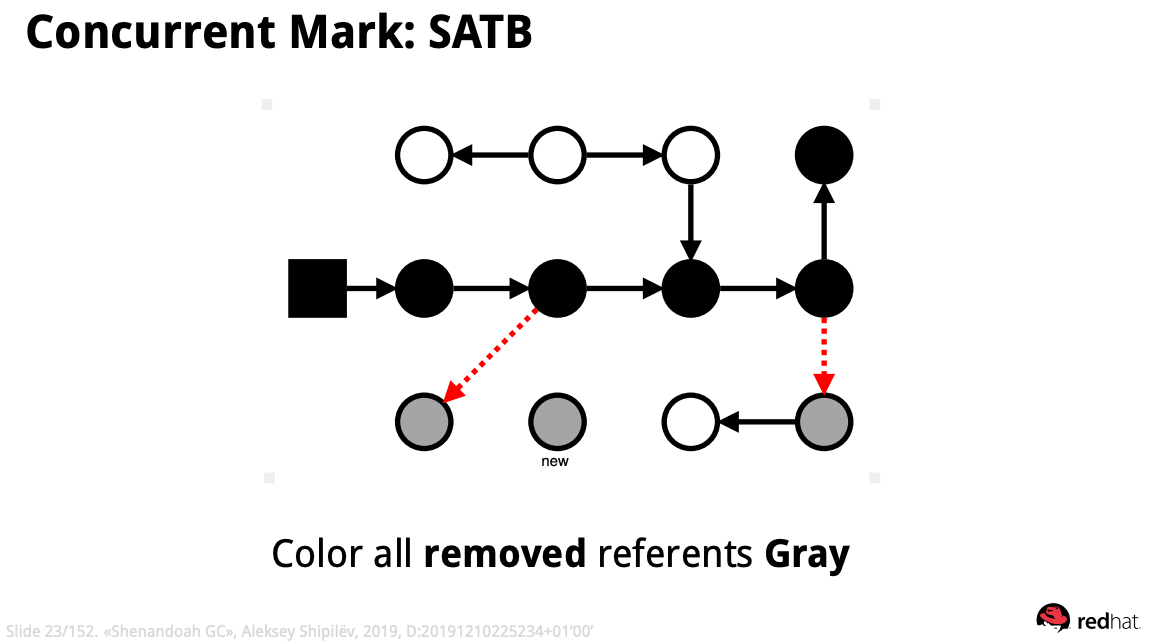
첫번째로 제거된 모든 참조를 회색으로 칠한다.
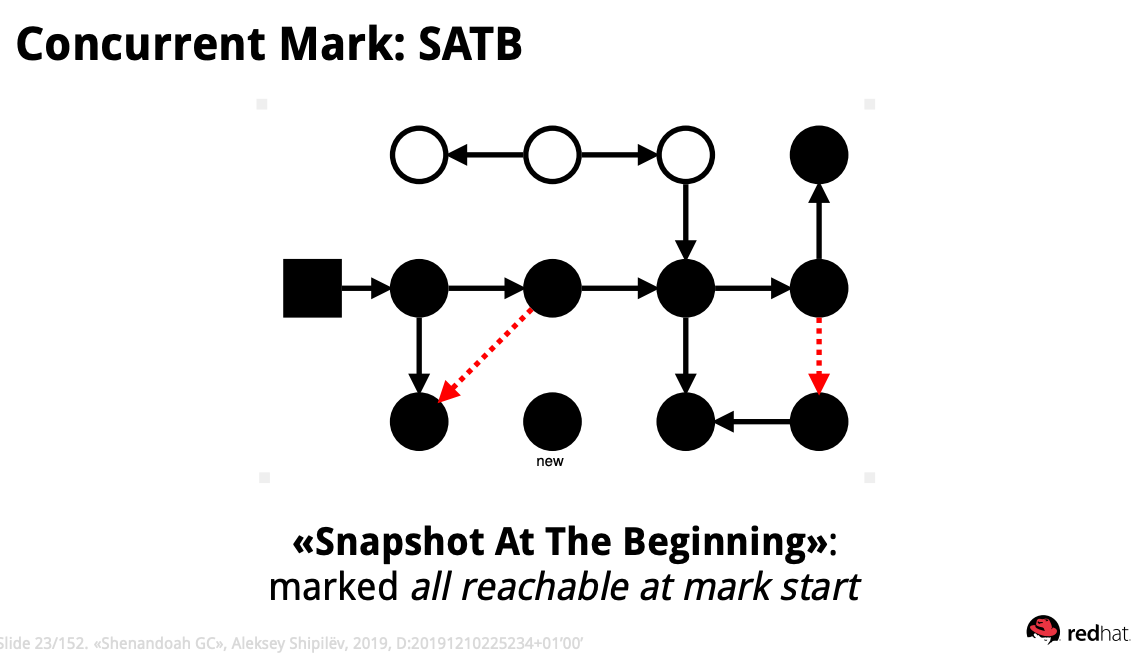
그리고 새로 할당된 object는 모두 검정색으로 칠한다. 위 그림과 같이 모든 참조가 정상적으로 연결되었음을 확인할 수 있다.
SATB에 대하여 더 알아보기 - Write Barriers in G1 GC

Load Reference Barrier (LRB)
Shenandoah의 Concurrent Evacuation와 Concurrent Update References 단계를 다른 GC의 가장 큰 차이라고 이야기 하였다. 이것을 가능하게 해주는 것이 Load Reference Barrier다. Evacuation간 Object를 새로운 Region으로 이동할 때 변경사항을 일관되게 유지할 수 있도록 해주는 포인터라고 볼 수 있다.
(Load Reference Barrier 는 Shenandoah 1.0 에서 Read & Write barrier 였던 기능이 통합 개선된 것이다. 개선 사항은 아래에서 자세히 다루겠다.)
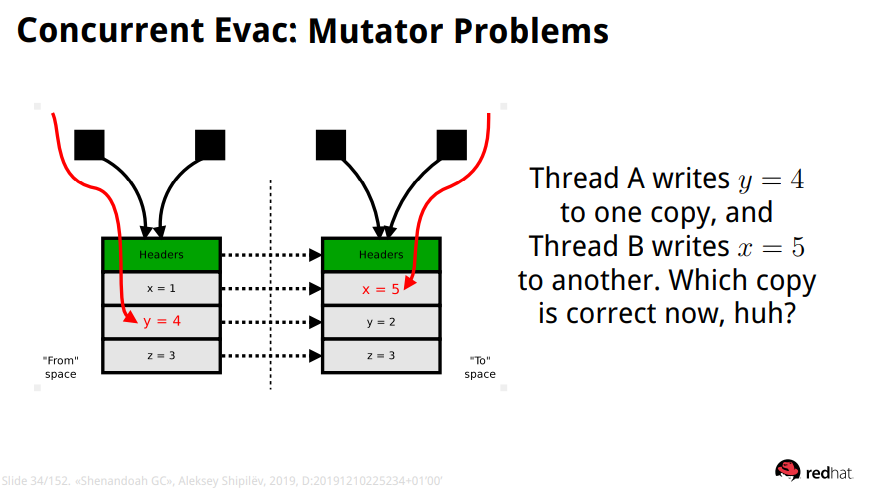
기존 Evacutaion에는 위와 같은 Conccrency 문제점이 발생한다.
from space(기존 할당된 region 영역) 에 발생하는 old object와 to space(새롭게 할당된 region 영역)으로 복사된 new object 가 존재한다.
그림 상단 4개의 사각형을 thread stack의 root object 라고 봤을 때 오른쪽 2개의 root object는 무사히 to space로 reference update를 진행하였다. 반면, 왼쪽 2개의 root object는 미처 reference update를 진행하지 못한 상황이다.
이 순간 thread A는 from space 영역의 값을 변경하고 thread B는 to space의 영역의 값을 변경한다. 이렇게 되면 모든 root object의 reference update가 완료었을 때 y=4라는 값을 잃게되는 것이다.
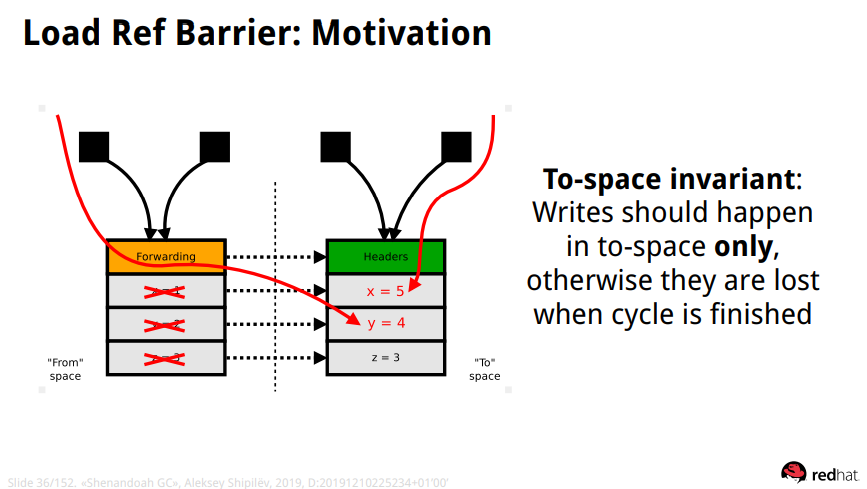
개념은 간단하다. to space 영역에 object copy가 일어나면 from space영역 object header가 to space 영역을 바라보도록 하는 것이다. copy가 일어나면 더 이상 old object는 object가 아닌 pointer로 작동하게 된다.
이렇게 되면 어느 thread가 참조 & 변경을 하던간에 to space를 바라보는 것이 보장된다.
Shenandoah 1.0 -> 2.0
LRB에 관하여 간단하게 이야기 포인터 처럼 이야기 하였는데 안을 들여다보면 별도의 영역으로 나누어져있는 것을 볼 수 있다.
HopSpot jvm의 Object layout이다. 주목할 것은 Mark Word인데, 이곳에는 hashcode, GC의 marking, Thread lock 등 여러가지 정보가 저장된다.

Shenandoah 1.0
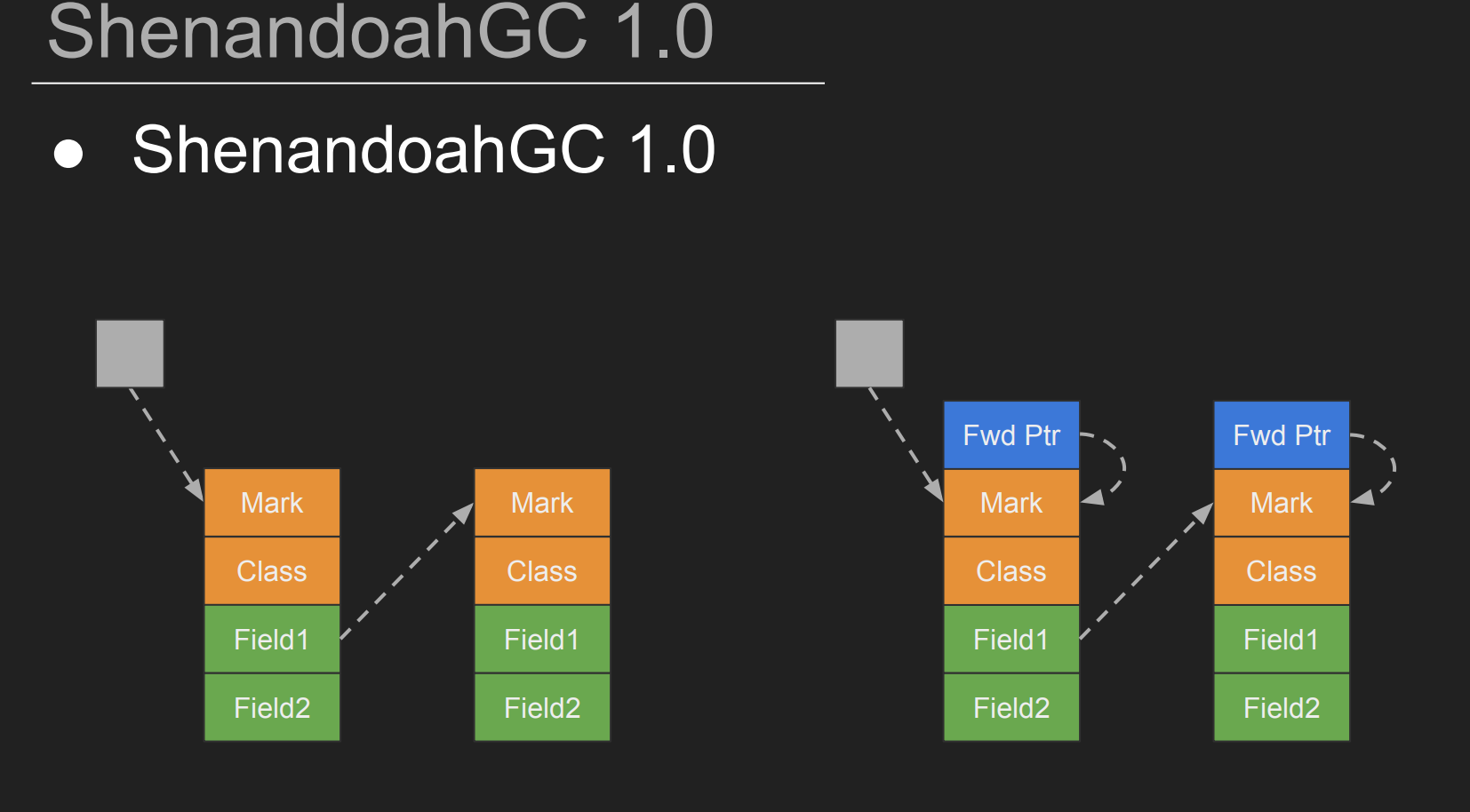
Shenandoah 1.0 에서는 LRB 이전에 Read, Write, Equal 등 복잡한 Barrier 들이 존재하였다. 이를 구현하기 위해 object header 앞에 forward pointer 를 두었다. 그리고 매 참조마다 mark word 지점에서 8byte 뒤로 이동해 forward pointer가 가리키는 필드를 참조한다. 물론 대부분이 자기 자신을 가리키는 mark word로 간다. 이 forward pointer 때문에 worst case에는 총 50%, 대체적으로 5~10%의 추가적인 메모리 할당 이슈가 존재하였다.

또한 재참조를 한다고 해서 무조건 Concurrency를 해결할 수 있는 것이 아니었다. read barrier 같은 경우 worst 케이스로 old object를 참조할 수 있는 경우가 생기는 것이다.
Shenandoah 2.0

기존 Shenandoah 1.0 버전에서 forward pointer 로 인한 추가적인 메모리 할당 필요, 복잡한 barrier 메커니즘, 부족한 최적화 등의 문제점을 지녔다.
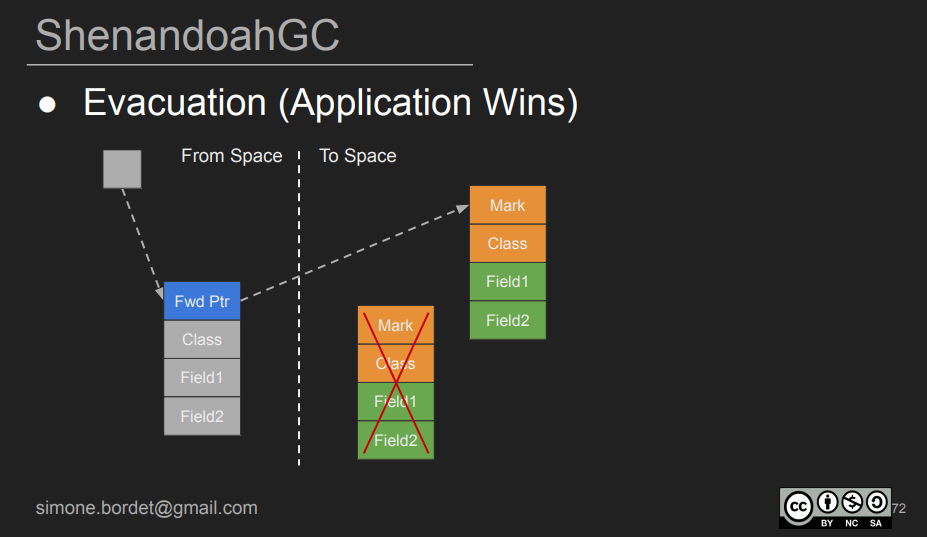
Shenandoah 2.0은 1.0의 고민을 단순하게 해결하였는데, 이는 to space에 object가 copy되면 old object는 더 이상 사용하지 않는다는 개념 이다. 따라서 old object의 mark word를 forward pointer로 대체하였다.
1.0 버전에서 매번 자기 자신을 재참조하면서 to space에 copy된 object가 존재하는지 확인 하였던 것이 이제는 forward pointer가 존재하는지 여부만 체크하게 되었다. 이것이 Load Reference Barrier다. 이로써 모든 참조가 무조건 to space 의 object를 향하도록 하였다.
(만약 GC와 application 동일한 object를 copy하였다면 application이 copy한 object가 to space로 취급된다)

단순한 forward pointer 참조로 더 이상 read,write 등의 barrier를 사용하지 않아도되었다.

자연스럽게 추가 메모리 할당이 해결이 해결 되었고, 같은 양의 할당에도 더 적은 GC cycle이 진행되었다. 이로써 Shenandoah 1.0에서 문제가 되었던 내용들이 모두 해결된 걸 확인할 수 있다.
Shenandoah 1.0과 2.0 의 자세한 차이는 아래 두 영상을 참고하면 좋다.
Shenandoah 2.0 (2020.08.06)
[VDT19] Concurrent Garbage Collectors: ZGC & Shenandoah by Simone Bordet [IT](2019.10.12)
Configuration (Performance Guidelines and Diagnostics)
*아래내용은 openJDK의 Performance Guidelines and Diagnostics 부분을 번역한 내용입니다.
Heap sizes: Shenandoah 의 성능안 다른 GC 성능과 같게 Heap size 영향을 받습니다. Concurrent 단계가 실행되는 동안 할당을 수용할 수 있는 Heap 공간이 충분한 경우 성능이 더 우수 합니다(아래 "Failure Modes를 참고하세요). Concurrent 단계의 소요시간은 live data set(LDS -- live data에 의해 할당에 공간)의 크기와 연관이 있습니다. 그러므로, LDS와 할당 pressure 에 따라 적절한 Heap사이즈가 달라질 수 있습니다.
지정된 할당 속도의 경우 LDS가 클수록 더 큰 힙 크기가 필요하며, LDS의 경우 할당률이 클수록 힙 크기가 커집니다.
대체 적인 workload 경우 Live Data Set가 작고 할당 pressure가 보통 수준 경우 1 - 2GB 힙이 적합합니다.
우리는 4 ~ 128 GB Heap이 80% 이상의 LDS를 가진 상태에 대해 다양한 workload를 지속적으로 테스트 했습니다. 주저하지 말고 어떤 heap size가 workload에 알맞는지 다양하게 시도해보세요.
Pauses:
Shenandoah의 pause 동작은 root를 탐색하고 업데이트 하는 것과 같은 root set 작동에 의해 결정됩니다.
Root Set은 로컬 변수, generated된 코드내부 참조, interned Strig, classloader의 참조(static final과 같은 참조), JNI 참조, JVMTI 참조를 포함합니다. JDK버전이 Shenandoah가 사용가능한 Concurrency 수행 기능이 없는 한, 큰 사이즈의 root set은 대체적으로 긴 pause를 이야기합니다.
2차적인 효과는 a) 처리가 필요한 참조에서만 동작하는 weak reference 처리(Final Mark Pause에서 발생합니다). 그리고 b) class unloading과 기타 JDK 정리(이 역시 Final Mark Pause에서 발생). 처리 빈도를 조작할수 있는 추가적인 option (전체 실행 중지를 포함한)설정으로 이러한 2차 효과를 완화할 수 있습니다. 혹은 애플리케이션 수정을 통하여 더 나아질 수 있습니다.
Throughput:
Shenandoah는 barrier를 사용하여 collection cycle간 불변을 유지하는 concurrent GC 입니다. 이 barrier들은 측정가능한 처리량 손실을 발생시킬 수 있습니다. 아래 diagnostic 섹션을 참고하여 어떤 일이 일어나는지 확인해보세요. brrier 사용으로 인한 처리량 손실은 Concrruent GC 작업이 idle 혹은 spare core 로 자연히 넘어감으로써 보상된다고 몇몇 사용자들은 보고 합니다. 어떤 경우에는 높은 애플리케이션 처리량을 위해 애플리케이션 + JVM의 사용를을 높힙니다.
대부분의 경우, Pause 시간은 0~10ms 이내이며 처리량 손실은 0~15% 이내입니다. 실제 성능 수치는 애플리케이션, 부하 profile 등에 크게 의존합니다.
root가 많지 않거나 weak reference, 혹은 class churn 일 경우 pause는 밀리초 미만일 수 있습니다. 애플리케이션의 heap이 크게 변치 않거나 컴파일러에 알맞게 최적화 되어있다면, barrier의 overhead는 거의 없을 수 있습니다.
나머지 섹션에서는 Shenandoah를 통해 성능 동작을 테스트하고 진단하는 방법을 설명합니다. 만약 사용 케이스에 구체적으로 의심가는 것이 있다면 개발자들에게 알려주십시오. 다루기 쉬운 버그이거나 일시적인 버그일 수 있습니다.
Basic configuration
Basic configuration and command line options:
-
-Xlog:gc (since JDK 9) or -verbose:gc (up to JDK 8) 개별 GC의 시간을 기록합니다.
-
-Xlog:gc+ergo (since JDK 9) or -XX:+PrintGCDetails (up to JDK 8) 이상 징후를 밝힐 수 있는 heuristics 의 내용을 출력합니다.
-
-Xlog:gc+stats (since JDK 9) or -verbose:gc (up to JDK 8) 실행이 끝났을 때 Shenandoah의 내부 시간 기록이 담긴 요약 테이블을 출
언제나 로깅이 가능할 때 사용하는 것이 좋습니다. 이 요약 테이블은 GC의 성능에 관한 중요한 정보를 전달합니다. 그리고 이를 버그 리포트에 사용할 수 있습니다. Heuristics 로깅은 문제점을 파악하는데 유용합니다.
Other recommended JVM options are:
-
-XX:+AlwaysPreTouch: Heap 페이지를 메모리에 커밋하면 지연 시간을 줄이는 데에 도움을 줍니다.
-
-Xms and -Xmx: -Xms = -Xmx 사용하여 Heap 의 사이즈를 조절 불가하게 하면 heap 관리의 지연을 줄일 수 있습니다. AlwaysPreTouch와 마찬가지로 시작 시 -Xms = -Xmx는 모든 메모리를 커밋하여 최종적으로 메모리가 사용될 때 지연을 피할 수 있습니다.
-Xms 는 낮은 수준의 메모리 커밋에 한도를 결정하므로 -Xms = -Xmx는 모든 메모리가 커밋된 것으로 유지됩니다. 만약, 낮은 수준의 footprint를 원한다면 -Xms 세팅을 낮게 설정하는 것이 좋습니다. commit/uncommit의 오버헤드와 메모리 footprint 사이에서 밸런스위해 얼마나 낮은 수준의 -Xms를 설정할지 결정해야합니다. 대부분의 경우 -Xms 를 낮게 설정하는 것이 좋습니다.
- 큰 페이지를 사용하는 것은 큰 heap에서 큰 성능 개선을 보여줍니다. 여기 두 가지 설정 방법이 있습니다. -XX:+UseLargePages 는 hugetlbfs (Linux)와 Windows (적절한 권한 필요) 지원을 가능케 합니다. -XX:+UseTransparentHugePages 는 이를 유용하게 사용할 것입니다. transparent huge pages는 "madvise"를 위해 /sys/kernel/mm/transparent_hugepage/enabled 그리고 /sys/kernel/mm/transparent_hugepage/defrag를 "madvise" 로 세팅하길 권장합니다. 이는 AlwaysPreTouch가 실행될 때 단편화에 대한 비용을 미리 지불할 것입니다.
-
-XX:+UseNUMA:
아직 Shenandoah 가 직접적으로 NUMA를 지원하지만, 다중 소켓 호스트에서 NUMA interleaving을 사용하기 위해 활성화 하는 것이 좋습니다. AlwaysPreTouch와 마찬가지로 제공되는 기본 구성보다 더 나은 성능을 보입니다. -
-XX:-UseBiasedLocking:
비경쟁의 locking 처리량과 필요에 따라 JVM을 활성화/비활성화 safepoints는 사이에는 트레이드 오프가 존재합니다.
지연 지향 workload의 경우 비경쟁(biased) locking을 해제하는 것이 좋습니다. -
-XX:+DisableExplicitGC:
사용자 코드에서 강제로 System.gc() 를 발동하는 것은 Shenandoah의 추가적인 GC cycle을 수행시킵니다. System.gc()가 악용되는 것으로부터 보호하기 위해 이를 비활성화하는 것이 유리할 수 있습니다. -XX:+ExplicitGCInvokesConcurrent 가 default로 활성화되어, stop-the-world full GC가 아닌 cocurrent GC cycle이 발동되므로 보통은 치명적이지 않습니다.
Modes
Modes 는 Shenandoah 작동의 주된 방법을 설정합니다. Shenandoah 가 어떠한 barrier라도 사용한다면 성능 특징을 설정 할 수 있습니다. 다음과 같이 설정할 수 있습니다. -XX:ShenandoahGCMode=<name>.
-
normal/satb (product, default) : 이 mode 는 Snapshot-At-The-Beginning (SATB) marking을 사용하여 concurrent GC를 실행합니다. 이 mode는 write와 mark를 previouse object를 통해 가로채는데, 이는 G1의 방식과 비슷합니다.
-
iu (experimental) : 이 mode 는 Incremental Update (IU) marking을 사용하여 concurrent GC를 실행합니다. 이 marking mode는 SATB mode를 미러링하는데 : write, mark 행위를 "new" object를 통해 가로챕니다. 특히 weak references 접근하는 것에 적극적일 수 있습니다.
-
passive (diagnostic) : 이 mode는 stop-the-world GC 입니다. 이 mode는 기능 테스트에 사용될 수 있습니다. 때때로 GC barrier로 인한 성능 변화를 분별 해내거나 애플리케이션 내에 실제 live 데이터의 양을 확인할 수 있습니다.
Heuristics
mode를 선택한 후, heuristics는 Shenandoah의 GC cyle을 언제 시작할지 그리고 evacuation을 위한 region 을 알려줍니다. Heuristics 다음과 같이 설정합니다.
- XX:ShenandoahGCHeuristics=<name>
몇몇 heuristics는 사용 케이스에 맞게 설정할 수있는 파라미터를 받습니다.
- adaptive (default) : 해당 heuristics는 이전 GC cycle을 관측하고 다음 GC를 시작하여 Heap이 소진되기 전에 완료될 수 있도록 합니다.
- -XX:ShenandoahInitFreeThreshold=#: "learning" collections를 작동할 초기 임계값
- -XX:ShenandoahMinFreeThreshold=#: 무조건 heuristics를 작동시키는 free 영역의 임계값
- -XX:ShenandoahAllocSpikeFactor=#: 영역 할당 급증에 따른 spike 를 대비하기 위한 heap의 양
- -XX:ShenandoahGarbageThreshold=#: marking 전 포함해야 하는 garbage region 퍼센트 설정
- static (previously and ironically known as dynamic) : 해당 heuristics는 heap 점유율에 따라 GC cycle을 시작합니다. 다음 튜닝 값들은 heuristics에 유용하게 작용합니다 :
- -XX:ShenandoahMinFreeThreshold=#: GC cycle을 시작하기 위한 가용 Heap 퍼센트 설정
- -XX:ShenandoahGarbageThreshold=#: marking 전 포함해야 하는 garbage region 퍼센트 설정
-
compact (previously erroneously known as continuous) : 해당 heuristics는 영역 할당이 일어나는 이상, 이전 GC cycle이 끝나자 마자 계속해서 실행합니다. 이 heuristics 는 보통 처리량 부하를 일으키지만, 즉각적인 공간 확보를 제공하기도 합니다.
-
- -XX:ConcGCThreads=#: GC의 concurrent 스레드 수를 조절하여 application의 여유 공간을 마련합니다.
-
- -XX:ShenandoahAllocationThreshold=#: 마지막 GC 사이클에서 다른 GC를 시작하기 전, 할당된 메모리 할당 퍼센트 설정
-
aggressive (diagnostic) : 해당 heuristics는 GC가 완전히 활성화 됨을 이야기 합니다. compact와 같이 이전 GC가 끝나는대로 새로운 GC cycle을 시작합니다. 그리고 이는 모든 live object를 evacuation합니다.
이 heuristics는 GC 자체의 기능 테스트에 유용하지만 꽤 많은 성능 패널티를 일으킵니다.
Failure Modes
Shenandoah와 같은 Cocurrent GC는 애플리케이션 할당 속도보다 빠른 수집 속도를 암묵적으로 보장합니다.
만약 할당 pressure가 높아서 GC가 수행되는 동안 할당을 위한 충분한 공간이 없다면, 할당 실패가 결국 일어납니다. Shenandoah 는 이러한 상황을 타계하도록 도움이 되는 몇가지 단계를 가지고 있습니다. 단계는 다음과 같습니다.
- Pacing (-XX:+ShenandoahPacing, enabled by default) :
GC가 실행 중일 때, GC 작업이 얼마나 필요한지, 그리고 애플리케이션은 얼마나 많은 여유 공간이 있는지 알 수 있습니다. Pacer는 GC 진행이 충분히 빠르지 못할 때, 할당 스레드를 지연하도록 합니다. 보통의 경우에는, GC 컬렉터는 애플리케이션 할당보다 빠르기 때문에 pacer는 애플리케이션을 지연시키지 않습니다. pacing은 프로파일링 도구에 탐지 되지 않는 스레드 별 local 지연을 도입합니다.
그래서 지연이 따로 정의되지 않고 -XX:ShenandoahPacingMaxDelay=#ms에 의해 설정되는 이유입니다. 모든 지연이 만료되고나면 할당은 어떻게든 일어날 것입니다. 대부분의 경우 잔잔한 할당 spike는 pacer에 의해 해결됩니다. 할당 pressure가 매우 높을 때는 pacer 가 대처불가 상태일 수 있고 이는 다음 실패 단계로 이동시킵니다. 정상적 지연 시간 : <10 ms
-
Degenerated GC (-XX:+ShenandoahDegeneratedGC, enabled by default) :
만약 애플리케이션이 할당 실패로 진입하면, Shenandoah 는 stop-the-world 를 전체 application에 발생시키고, GC cycle을 시작합니다.
stop-the-world 상태에서도 Degenerated GC는 concurrent cycle을 지속합니다. 많은 경우에, 상당한 양의 GC 작업이 일어난 후 할당 실패가 일어납니다. 그리고는 GC 작업의 작은 부분에 걸쳐 완료가 필요합니다. 때문에 stop-the-world가 보통 그리 길지 않게 나타납니다.
GC pause는 모든 모니터링과 heartbeat스레드에 로그로 보고될 수 있는데, stop-the-world pause를 concurrent mode 실패로 명확히 관측하기 위한 이유 중 하나입니다.
GC cycle 시작이 너무 늦거나 너무 많은 양의 할당 spike가 일어날 때 Degenerated GC가 발생합니다.
Degenerated GC 은 concurrent cycle보다 빠를 수 있습니다. 이는 애플리케이션과 자원 경쟁을 하지 않기 때문입니다. 이는 스레드 풀 사이즈를 위해 -XX:ConcGCThreads가 아닌 -XX:ParallelGCThreads를 사용합니다. 정상적 지연 시간 : <100 ms, Degenerated 포인트에 따라 좀 더 늘어날 수도 있습니다. -
Full GC : Degenerated GC가 충분한 메모리를 해제하지 못하여 아무것도 도움이 되지 않는 경우, Full GC cycle이 발생하여 Heap을 최대치로 압축합니다. 특정한 예시로 구현간의 버그나 간과한 부분에 의해 비정상적인 Heap 단편화가 있는데, 이는 오로지 Full GC에 의해서만 해결됩니다.
이는 최후의 GC로, 최소한의 메모리 영역 존재할 경우 OOM 의해 애플리케이션이 실패하지 않음을 보장합니다. 정상적 지연 시간 : <100 ms, 큰 heap 점유율에 따라 좀 더 늘어날 수도 있습니다.
Benchmark
아래 링크로 대체.
https://ionutbalosin.com/2019/12/jvm-garbage-collectors-benchmarks-report-19-12/
마치며
GC를 공부하는 도중 Shenandoah GC를 알게 되었고 CMS나 G1비하여 국문자료가 얼마 없어 나름 조사 후 적어놓은 글 입니다.
조사한 자료에 비해 설명이 많이 빈약할 수 있어 아쉬운 감이 없지 않아 있지만 아래 첨부될 내용을 천천히 참고하여보면 어렵지 않게 이해하실 수 있을거라 생각합니다.
내용을 터득하는 과정에서 제가 잘 못 이해한 부분이 있을 수 있습니다. 해당 부분에 대해서는 가감없이 댓글 남겨주시면 감사하겠습니다.
Rereferneces
OpenJDK
https://wiki.openjdk.java.net/display/shenandoah/Main
https://openjdk.java.net/jeps/404
https://openjdk.java.net/jeps/189
(번역 https://sejoung.github.io/2019/12/2019-12-18-JEP_189)
Shenandoah GC 2.0
MoreVMs’20: “Shenandoah GC 2.0” by Roman Kennke (2020. 4. 15)
OpenJDK_in_the_new_Age_of_concurrent_Garbage_Collectors.pdf (2019.11)
영상 : [VDT19] Concurrent Garbage Collectors: ZGC & Shenandoah by Simone Bordet [IT](2019.10.12)
발표자료 : Simone_Bordet_Concurrent_Garbage_collectors_ZGC__Shenandoah.pdf
Shenandoah GC 1.0
Shenandoah GC - Part I: The Garbage Collector That Could (2018)
발표자료 : Shenandoah GC - Part I: The Garbage Collector That Could
Shenandoah GC: The Next Generation(2018. 10. 24)
발표자료 : Shenandoah GC - Part I: The Garbage Collector That Could
Shenandoah: The Garbage Collector That Could by Aleksey Shipilev (2017. 11. 10)
발표자료 : Shenandoah GC - Part I: The Garbage Collector That Could
Shenandoah 2 0: Now That We’ve Gotten the GC Pause Times Under Control, What’s Next? (2017. 10. 3)
Shenandoah GC: Java Without The Garbage Collection Hiccups (Christine Flood) (2016. 10. 18)
Etc
https://dev-punxism.tistory.com/entry/Shenandoah-gc
https://dzone.com/articles/java-garbage-collection-3
https://ichi.pro/ko/7-gaji-yuhyeong-ui-java-gabiji-sujibgi-108403385011842
https://www.baeldung.com/jvm-experimental-garbage-collectors

benchmark 자료
https://ionutbalosin.com/2019/12/jvm-garbage-collectors-benchmarks-report-19-12/