Introduction
자바로 자료구조를 공부한 적이 있었다. 구현을 직접 해보긴 했는데, 이번에 구현한 내용을 정리하고자 한다. 자료구조도 구현할 겸, 그 이전에 자바에서 자료구조를 제공해주는 고마운 Java Collection FrameWork에 대해 소개를 하고 각 자료구조를 뜯어보면서 넘어가고자 한다.
java.util.Collection
자바에서는 믾이 사용하는 자료구조를 따로 만들어두었다. 그것이 바로 컬렉션 프레임워크(Collection Framework)이고, 기본적으로 Collection<E>와 같이 제네릭 기반으로 되어있다.
아래 이미지(출처)는 Collection의 class diagram이다. 다양한 자료구조가 있는 것을 볼 수 있다.
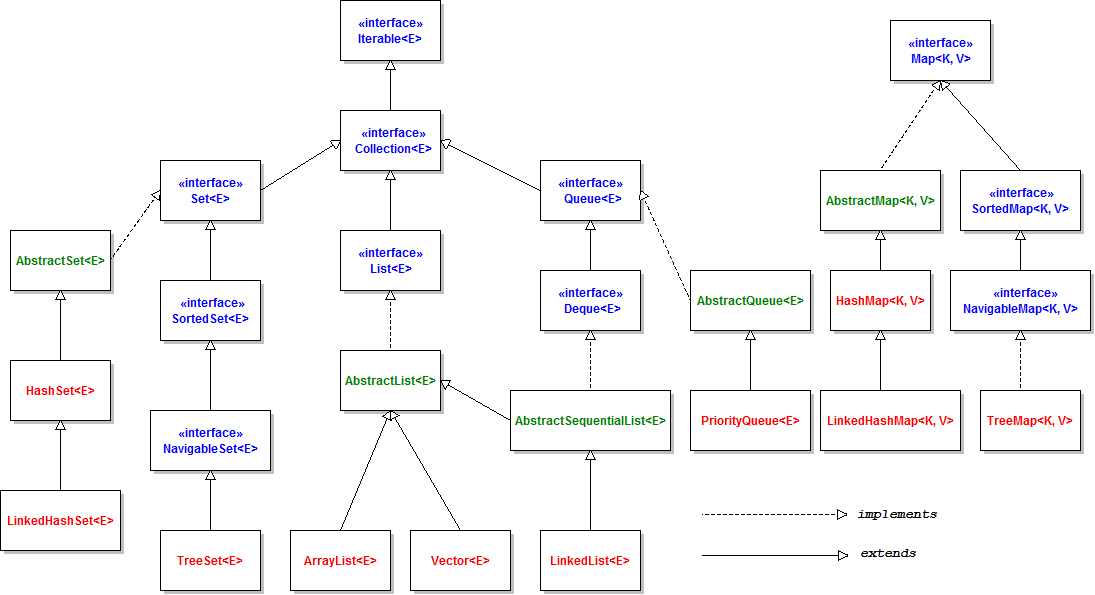
위 다이어그램에서 몇 가지 사실을 확인할 수 있다.
-
Collection에 해당하는 자료구조는 모두 Iterable 인터페이스를 상속받는다. 이는 해당 인터페이스를 상속받는 모든 자료구조들을 반복문으로 데이터들을 관리할 수 있게 한다. 크게 두가지 방법이 있는데, 하나는 for-each문이고, 하나는 Iterable 내부 iterator() 메소드를 사용하는 방법이 있다.
-
Map 자료구조는 Collection을 상속받지 않는다. 즉 Iterable 인터페이스를 상속받지 않으므로 아무런 자료구조 도움 없이 위에 언급한 for-each문이나 iterator() 사용이 불가능하다.
위 사실에 따라 자바의 자료구조를 크게 나누면 아래와 같음을 알 수 있다. (물론 LinkedList처럼 List도 속하고 Queue도 속하는 것도 존재하므로 참고용으로만 파악하기 바란다.)
Collection : List, Set, Queue
Non-Collection : Map
Collection
Iterable interface
Iterable 오라클 문서
Iterable 인터페이스를 살펴보면 메소드를 몇가지 볼 수 있는데, 그 중 눈에 띄는게 보인다. 바로 forEach(Consumer<? super T> action) 와 iterator()이다. 이 메소드는 이 인터페이스를 구현 또는 상속받을 경우 for-each 문이나 iterator()를 통해서 자료구조를 다룰 수 있다는 것을 의미한다. 사용 예를 보도록 하자.
- for-each
public class Test {
public static void main(String[] args) {
List<String> list = new ArrayList<>();
list.add("Hello");
list.add("Data");
list.add("Structure");
list.add("World!");
for(String str : list) {
System.out.print(str + " ");
}
}
}- iterator()
public class Test {
public static void main(String[] args) {
List<String> list = new ArrayList<>();
list.add("Hello");
list.add("Data");
list.add("Structure");
list.add("World!");
Iterator<String> iter = list.iterator();
while (iter.hasNext()) {
System.out.print(iter.next() + " ");
}
}
}- 출력결과(둘 다 동일)
Hello Data Structure World!
- Iterable과 별개로 존재하는 인터페이스이다. 메소드는 단 세 개, hasNext, next, remove가 있다. 각각 반복할 원소가 존재여부 반환하기(boolean), 현재 원소를 반환하기, 그냥 제거하기의 역할이다.
- Iterable을 구성(Composition)하고(
Iterator<T> iterator();) 요소들을 하나씩 긁어오는 역할을 한다.
List interface
리스트(List)는 무엇일까? 기본적으로 리스트라는 것을 일렬로 연결된 자료구조를 의미한다. 자바에서는 이러한 리스트 인터페이스를 구현한 클래스로 크게 ArrayList, Vector, LinkedList를 제공한다.
-
ArrayList: 배열을 기반으로 한 가장 기본적인 리스트의 형태이다. 필드로 배열이 들어가는 만큼 배열과 비슷한 점이 많으나 크기 변경이나 값 삽입, 제거를 할 수 있다는 점에서 배열과 다르다. -
Vector: 역시 배열을 기반으로 하는 자료구조로 언듯보면 ArrayList와 차이점이 잘 눈에 띄지 않는다. 다만, Vector는 동기화(synchronized)를 지원한다는 점이 다르다. 다만, 동기화 및 Thread-safe할 필요가 없다면 ArrayList를 사용할 것을 권장하고 있다. (If a thread-safe implementation is not needed, it is recommended to use ArrayList in place of Vector. [출처])Stack: 대표적인 후입선출(Last-In-First-Out) 자료구조인 Stack이 Vector를 상속받는다. 당연한 말이지만 Vector와 마찬가지로 동기화로 인해 Thread-safe 하다. 다만, 이 역시도 다른 자료 구조 Deque를 사용할 것을 권장하고 있다. (A more complete and consistent set of LIFO stack operations is provided by the Deque interface and its implementations, which should be used in preference to this class. [출처])
동기화(synchronized)
- 자바는 기본적으로 Multi-thread를 지원한다. 스레드가 여러개라는 뜻인데, 사실 한 프로세스 내에 존재하게 되고, 각 스레드는 메모리를 공유한다.
- 비동기일 경우 원래 한 스레드 내에서만 처리해야 되는 것이 있다고 하더라도 메모리를 공유하게 된다. 그러므로 다른 스레드가 공유하는 메모리에 동시에 함부로 접근하게 되어 개발자가 원하는 결과가 나오지 않을 수도 있다. 이를 경쟁 상태(Race Condition)라 한다.
- 이를 막는 것이 바로 동기화 작업이다. 그리고 이렇게 동기화를 할 경우 다른 스레드의 동시 접근을 막는다. 이를 Thread-safe하다고 한다.
- 다만, 역시 스레드 접근을 막다보면 실행 시간이 늘어나는 성능 이슈가 있기 마련이다. 그래서 구지 동기화가 필요 없다면 ArrayList를 쓰자.
LinkedList: 배열기반의 ArrayList와는 내부 구조가 다르다. 기본적으로 정점(Node)으로 구성되어 있는 자료구조로, 이 정점에는 현재의 데이터와 다음 정점의 주소가 들어가 있다. ArrayList 와 같은 배열기반 자료구조에 비해 탐색은 시간복잡도상 불리하지만, 자료의 추가, 삭제는 다음 정점의 주소만 바꿔주는 방법으로 훨씬 간단하고 시간복잡도상 유리하다.
Set interface
Set은 순서를 보장하지 않고, 중복된 자료가 없는 자료구조이다.
HashSet: 가장 기본적인 Set이며, 무작위 순서이다. hashCode를 기반으로 중복을 제거하며, 다른 객체를 만들어서 Set에 넣어줄 때, equals, hashCode를 오버라이딩하여 중복 기준을 정하는 것이 중요하다.LinkedHashSet: 입력 순서로 저장하는 Set이다. HashSet을 상속받아 구현한다.TreeSet: 기본적으로 오름차순 정렬이 이뤄지는 Set이고, 이진 탐색 트리(Binary Search Tree, BST)를 활용한다. 추후에 다루겠지만, Tree를 사용한 정렬은 정렬 중에서도 아주 효율적이다.
Set의 경우에는 단순 리스트로 중복이 되는 자료를 제거해줄 때 쓰이고, (스포) Map에서도 쓰인다!
Queue interface
가장 기본적인 Queue는 Stack과는 달리 선입선출(First-In-First-Out, FIFO) 자료구조이다. 일반적인 자료구조에서는 FIFO로 정의하는데, 상속받는 인터페이스나 추상 클래스 등에 따라 용도가 많이 다양해진다.
LinkedList: 어디선가 많이 본 녀석이다. 그렇다. 리스트에서 본적이 있는 바로 그 친구다. 우리가 잘 아는 FIFO 형식의 Queue, 가장 기본적인 것이 바로 LinkedList이다.Deque: 이건 Queue를 상속받는 인터페이스이다. 이건 기본적인 Queue에서 Stack의 기능까지 추가한다고 생각하면 아주 편하다. 그냥 처음이든 끝에서는 원하는대로 삽입하고 빼낼 수 있다. 역시 인터페이스이기 때문에 구현한 클래스가 필요한데, 이는 ArrayDeque, 그리고... 또 LinkedList가 있다.(LinkedList 당신은...)PriorityQueue: 우선 순위가 높은 요소가 우선 순위가 낮은 요소보다 먼저 제공되는 자료구조이다. 마침 활용을 간단하게 정리해둔 제 포스트가 있으니 참고하면 된다.
Map interface
Key, Value로 구성된 자료구조가 바로 Map이다. 배열에서 인덱스의 역할을 하는 것이 Map에서는 Key, 값이 Value이다. 이는 인덱스가 0,1,2,3,... 으로 고정되어있는 다른 자료구조들과 달리 Key는 정말 마음대로 설정이 가능하다(물론 제네릭으로 적은 타입은 맞춰야 한다.). Collection을 상속받지 않기 때문에 단순하게 for-each문이나 iterator()를 사용할 수가 없는 것이 특징이다. 하지만 다른 자료구조의 도움을 받으면 사용 가능하다. 바로 Set이다.
이러한 Map 자료구조는 Set의 도움을 받아 출력이 가능한데, 크게 두가지 방법이 있다.
keySet(): Key만을 모아놓은 Set이다. 이를 동해서 KeySet을 for-each문이나 iterator()를 활용해 Value에 접근하는 방식으로 반복문을 작성 가능하다. 그 외에는 어차피 기존 사용법과 동일하므로 편의상 for-each문의 케이스만 작성하도록 하겠다.
public class Test {
public static void main(String[] args) {
Map<String, String> map = new HashMap<>();
map.put("안녕", "Hello");
map.put("자료", "Data");
map.put("구조", "Structure");
map.put("세상", "World!");
for(String key : map.keySet()) {
System.out.print(map.get(key) + " ");
}
}
}Structure World! Data Hello다만... 리스트와는 다르게 출력결과를 보장하지 않는다. 당연하지만 기반이 Set이기 때문이다. 아래를 꼭 염두해두자.
- 기본적으로 Set, Map은 순서를 보장하지는 않는다.
- HashMap에서
keySet()이든 다음에 나오는entrySet()이든 모두 그렇다.
entrySet(): Key, Value를 모두 저장한 Entry 객체로 구성된 Set으로, Key, Value를 모두 한번에 접근하고자할 때 사용하는 Set이다. 예시부터 보도록 하겠다. 결과 역시 순서를 보장하지는 않는다.
public class Test {
public static void main(String[] args) {
Map<String, String> map = new HashMap<>();
map.put("안녕", "Hello");
map.put("자료", "Data");
map.put("구조", "Structure");
map.put("세상", "World!");
for (Entry<String, String> entry : map.entrySet()) {
// Key를 얻고 싶으면 entry.getKey() 사용
System.out.print(entry.getValue() + " ");
}
}
}Structure World! Data Hello그리고 Map을 구현한 클래스는 아래와 같다.
HashMap: 가장 대표적인 Map이다. 추후에 다루겠지만, Hash Funtion을 사용하여 배열과 같이 탐색하는데 뛰어난 성능을 보이며 Entry객체를 저장하는 구조를 가지고 있다.Hashtable: HashMap보다 이전에 구현된 것이다. HashMap과 다르게 Thread-safe하기에 해당 환경이 꼭 필요한 것이 아니면 HashMap 사용을 권장하고 있다. 그리고 Hashtable은 key로 null 사용이 불가능하다. (HashMap은 가능)TreeMap: TreeSet과 동일하게 BST를 사용하지만, Entry 객체 형태로 저장한다는 점이 다르다.
마치며...
Collection Framework를 대략적으로 살펴보았다. 남은 것은 각각의 자료구조의 작동원리에 대한 자세한 설명 및 구현이 남아있다. 이 시리즈 다음부터 하나씩 살펴보도록 하자.
참고
- https://17billion.github.io/java/2017/06/18/java_collection_vector_arraylist_linkedlist.html
- Class diagram of Java Collections framework
http://www.codejava.net/java-core/collections/overview-of-java-collections-framework-api-uml-diagram - Iterable 오라클 문서 https://docs.oracle.com/javase/8/docs/api/java/lang/Iterable.html
- Iterator 오라클 문서 https://docs.oracle.com/javase/8/docs/api/java/util/Iterator.html
- List 오라클 문서 https://docs.oracle.com/javase/8/docs/api/java/util/List.html
- Vector 관련
- 동기화 https://inpa.tistory.com/entry/JCF-%F0%9F%A7%B1-ArrayList-vs-Vector-%EB%8F%99%EA%B8%B0%ED%99%94-%EC%B0%A8%EC%9D%B4-%EC%9D%B4%ED%95%B4%ED%95%98%EA%B8%B0
- Vector 오라클 문서 https://docs.oracle.com/javase/8/docs/api/java/util/Vector.html
- Stack 오라클 문서 https://docs.oracle.com/javase/8/docs/api/java/util/Stack.html
- Set 오라클 문서 https://docs.oracle.com/javase/8/docs/api/java/util/Set.html
- Queue 오라클 문서 https://docs.oracle.com/javase/8/docs/api/java/util/Queue.html
- Map 오라클 문서 https://docs.oracle.com/javase/8/docs/api/java/util/Map.html
- HashMap https://github.com/wjdrbs96/Today-I-Learn/blob/master/Java/Collection/Map/Java%20HashMap%20%EB%8F%99%EC%9E%91%EC%9B%90%EB%A6%AC.md
