필요성
우리가 사전과 같이 어떤 여러 문자열을 가지고 있는 구조에서 특정 문자열을 조회한다고 가정해보겠습니다. 그렇다면 이 방법은 무엇이 있을까 생각하보면 사실 단순히 일일이 비교해보는 방법이 존재하기는 합니다. 최대 문자열의 길이가 m인 문자열 n개의 집합에 대해 모든 상황을 가정하겠습니다.
하지만 문자열의 단순 비교는 시간복잡도가 O(nm)이 발생하게 되어 비효율적입니다. 이것보다 효율적인 방법을 생각해보면 이진 탐색을 통한 방법이 있습니다. 이렇게 되면 단순 조회 과정에서는 O(mlogn)이 걸립니다.
하지만, 후술할 트라이 자료구조는 시간복잡도가 O(m), 즉 문자열의 길이에만 비례하게 됩니다. 어떻게 이것이 가능한지 알아보겠습니다.
트라이(Trie)

트라이(Trie)는 탐색 트리(Retrieval Tree)에서 나온 말로, 기본적으로 K진 트리 구조를 가지고 있습니다.
사용되는 문자 종류의 수가 적은 경우(ex. 알파벳)에는 단순히 배열로(C++의 경우에는 동적 할당으로 필요한 메모리만 확보하는 것이 유리합니다) 구현합니다. 다만, 문자 종류가 많은 경우 쓸모 없는 공간을 배열로 잡아두고 있기 때문에 메모리 절약을 위해 Map으로 구현을 많이 합니다.
삽입
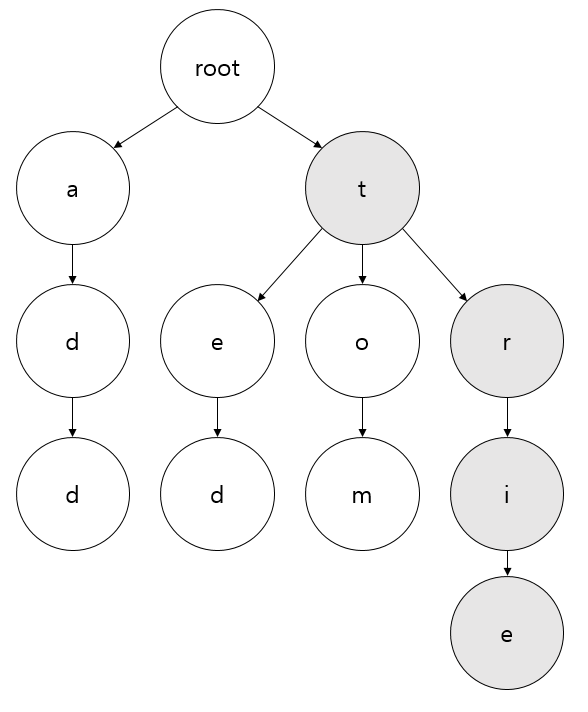
처음 자료를 삽입할 때 어떻게 진행하는지 알아보도록 하겠습니다. 예시는 trie로 하겠습니다.
- 아무것도 없는 루트 노드부터 출발합니다.
- 각 과정별로 문자 하나하나
t,r,i,e에 대해 다음과 같은 과정을 진행합니다.- 만약 해당하는 노드가 없다면 새로 생성 후 현재 노드를 생성한 노드로 변경합니다.
- 있을 경우에는 그 노드로 현재 노드를 변경합니다.
- 끝 노드까지 이동하면 문자열의 끝이라고 표시해줍니다. (
node.isEnd = true)
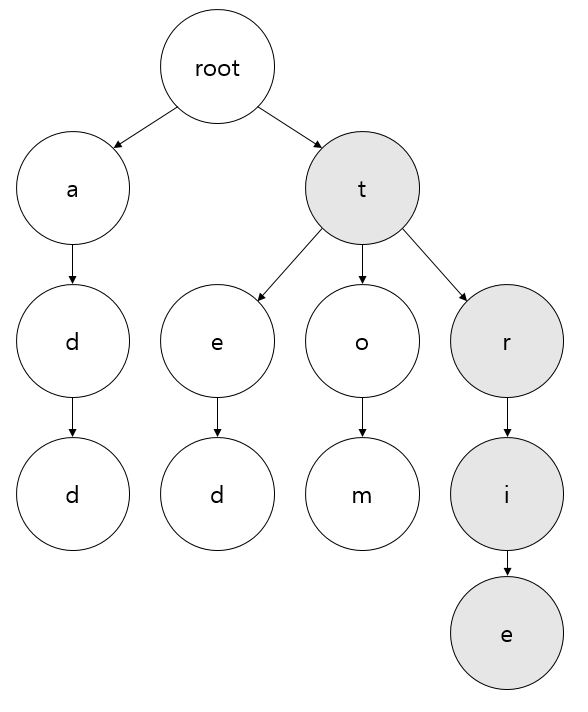
조회
예를 들어 trie라는 단어를 조회한다고 했을 때, 어떻게 조회할까 알아보겠습니다.
- 아무것도 없는 루트 노드부터 출발합니다.
- 아래 과정 중 없는 노드가 있을 시에는 문자열이 없다고 판단합니다.
- 자식 노드에서
t노드를 찾습니다. 현재 노드를t노드로 변경합니다. - 자식 노드에서
r노드를 찾습니다. 현재 노드를r노드로 변경합니다. - 자식 노드에서
i노드를 찾습니다. 현재 노드를i노드로 변경합니다. - 자식 노드에서
e노드를 찾습니다. 현재 노드를e노드로 변경합니다.
- 자식 노드에서
- 마지막 노드에 도달했으면 문자열의 끝여부를 판단합니다.
조회 과정을 확인해보면 알 수 있지만, 문자가 앞에서부터 하나하나씩 쌓이는 과정이기 때문에 접두사를 기준으로 조회가 되고 있음을 알 수 있습니다. 이에 자동완성 또는 사전검색 등에 특화되어 있는 자료구조임을 볼 수가 있습니다.
또한, 삽입과 조회 모든 과정에서 처리 시간에 관련된 항목으로는 문자열의 길이에만 비례하고 있음을 알 수 있습니다(기본적으로 배열 사용시 노드 하나 조회하는 데 O(1)의 시간복잡도만을 가지고 있기 때문).
따라서 시간복잡도는 최대 문자열의 길이가 m에 비례하는 O(m)이 됨을 알 수 있습니다.
구현
Node
배열 또는 Map으로 다음에 나올 문자 후보들을 저장할 수 있습니다. 시간복잡도 상으로 이득을 챙기려면 배열, 메모리 상으로 이득을 챙기려면 Map으로 구현합니다. 여기서는 배열로 구현하도록 하겠습니다.
class Node {
Node[] nodes = new Node[26]; // a ~ z까지 0 ~ 25 인덱스를 가짐
boolean isEnd = false;
}Trie
필드에는 루트 노드를 설정해줍니다.
삽입시 insert 메소드, 조회시 search 메소드를 실행합니다.
search 메소드를 실행시 문자열이 존재하면 true, 아니면 false를 반환하도록 합니다.
class Trie {
private Node root = new Node();
public void insert(String str) {
Node node = root;
for(int i = 0; i < str.length(); i++) {
int idx = str.charAt(i) - 'a';
if(node.nodes[idx] == null)
node.nodes[idx] = new Node();
node = node.nodes[idx];
}
node.isEnd = true;
}
public boolean search(String str) {
Node node = root;
for(int i = 0; i < str.length(); i++) {
int idx = str.charAt(i) - 'a';
if(node.nodes[idx] == null)
return false;
node = node.nodes[idx];
}
return node.isEnd;
}
}BOJ 14425 문자열 집합
해당 문제는 Set을 사용하면 쉽게 풀 수 있는 문제입니다.
각각의 케이스에 대해서 알아보고, 시간 및 메모리를 알아보겠습니다.
https://www.acmicpc.net/problem/14425
Set
import java.io.*;
import java.util.*;
public class Main {
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
StringTokenizer st;
st = new StringTokenizer(br.readLine());
int n = Integer.parseInt(st.nextToken());
int m = Integer.parseInt(st.nextToken());
Set<String> set = new HashSet<>();
int ans = 0;
for(int i = 0; i < n; i++) {
set.add(br.readLine());
}
String str = null;
for(int i = 0; i < m; i++) {
str = br.readLine();
if(set.contains(str)) {
ans++;
}
}
System.out.println(ans);
br.close();
}
}Trie
import java.io.*;
class Node {
Node[] nodes = new Node[26];
boolean isEnd = false;
}
class Trie {
private Node root = new Node();
public void insert(String str) {
Node node = root;
for(int i = 0; i < str.length(); i++) {
int idx = str.charAt(i) - 'a';
if(node.nodes[idx] == null)
node.nodes[idx] = new Node();
node = node.nodes[idx];
}
node.isEnd = true;
}
public boolean search(String str) {
Node node = root;
for(int i = 0; i < str.length(); i++) {
int idx = str.charAt(i) - 'a';
if(node.nodes[idx] == null)
return false;
node = node.nodes[idx];
}
return node.isEnd;
}
}
public class Main {
public static void main(String args[]) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
Trie trie = new Trie();
String[] info = br.readLine().split(" ");
int n = Integer.parseInt(info[0]);
int m = Integer.parseInt(info[1]);
for(int i = 0; i < n; i++) {
trie.insert(br.readLine());
}
int result = 0;
for(int j = 0; j < m; j++) {
if(trie.search(br.readLine())) result++;
}
System.out.println(result);
br.close();
}
}메모리, 시간
- Set 사용시

- Trie 구현시

해당 문제의 경우 단순 조회를 통해 문자열 존재여부만을 확인하는 문제입니다. Set에 비해 Trie가 메모리, 시간 모두 크게 나타난 것을 볼 수 있습니다. 그 이유는 다음과 같습니다.
메모리
- Set의 메모리
단순히 문자열의 갯수에만 비례합니다. - Trie의 메모리
모든 가능한 문자열에 대해서 각 과정마다 저장하고 있습니다. 여기서는 (알파벳 수 * 최대 문자열 길이)에 비례하게되어 Set과는 다릅니다.
시간
가지고 있는 문자열의 수를 n, 조회할 문자열의 수를 m, 최대 문자열 길이를 k라 하면,
- Set은 해쉬코드를 통해 조회합니다. 시간복잡도는
O(m)가 됩니다. - Trie는 최대 문자열 길이에 비례합니다. 시간복잡도는
O(m * k)가 됩니다.
후자가 훨씬 크기에 시간적으로 차이가 나게 됩니다.
