V 가 임의의 벡터 공간이고 S={v1,v2,⋯,vn}가 V를 생성(span)하는 선형독립인 V의 부분집합일 때, S 를 V의 기저라고 한다. 좀 더 자세히 살펴보자.
Linear Combination
벡터의 집합 S={u1,u2,⋯,un}과 스칼라 a1,a2,⋯,an에 대해
v=a1u1+a2u2+⋯+anun
을 S의 일차 결합 또는 선형 결합(Linear Combination)이라고 한다. 이때 a1,a2,⋯,an를 이 일차결합의 계수(Coefficient)라고 한다.
Trivial Representation of 0
v=0이 되게 하는 경우를 생각해 보자. a1,a2,⋯,an가 모두 0일 때 v=0를 만족시킬 수 있다. 이를 S의 일차결합에 대한 영벡터의 자명한 표현(Trivial Representation of 0)이라고 한다.
Linear Dependence
영벡터를 나타내는 S의 일차결합에 대해, 자명하지 않은 표현이 존재하면 집합 S는 일차종속(Linearly Dependent)이다. 예를 들어, S={(10),(20)}은 0=−2(10)+(20)으로 나타낼 수 있으므로 이 집합은 일차종속이다.
Linear Independence
벡터들의 집합 S가 일차종속이 아닐 경우, 이 집합을 일차독립(Linearly Independent)이라고 한다. 예를 들어, S={(10),(01)}의 경우 영벡터의 자명한 표현 이외에 영벡터를 구성하는 방법이 존재하지 않으므로 이 집합은 일차독립이라 할 수 있다.
Subspace
체 F위의 벡터공간 V의 부분집합 W이 덧셈과 스칼라곱이 정의되는 벡터공간일 때, W를 V의 부분공간(Subspace)이라고 한다. 모든 벡터공간 V은 V와 ∅를 부분공간으로 가진다.
Span
S가 ∅이 아닌 V의 부분집합이라고 하자. S의 벡터를 사용하여 만든 모든 일차결합의 집합을 S의 생성공간(Span)이라고 표현하고, 기호로 span(S)와 같이 표현한다. V의 부분집합 S의 모든 span은 V의 부분집합 W이고, 이를 기호로 W=span(S)와 같이 표현한다.
Dimension
Row Space & Column Space
m×n행렬 A를 생각하자. 이때 행벡터와 열벡터는 각각 Rn,Rm에서의 벡터공간을 생성할 수 있다. 행벡터로 생성된 Rn의 벡터공간을 행공간(Row Space)라고 하고, 열벡터로 생성된 Rm의 벡터공간을 열공간(Column Space)라고 한다.
Dimension
벡터공간 V의 기저 벡터의 개수를 V의 차원(Dimension)이라고 하며, 기호로 dim(V)와 같이 나타낸다. 이때, 영벡터로 이루어진 벡터공간의 차원을 0차원이라고 한다. 즉, 벡터 공간을 구성하는 데에 필요한 최소한의 벡터 개수가 차원이다. 행렬 A의 행공간과 열공간의 차원은 항상 같음을 기억하자.
Nullspace
Ax=0를 만족하는 모든 벡터 x의 집합으로 생성한 공간을 행렬 A의 영공간(Nullspace)라고 한다. 행공간, 열공간, 영공간을 통틀어 행렬공간(Matrix Space)라고 한다.
Rank & Nullity
행렬 A의 열공간 또는 행공간의 차원을 Rank라고 하며, 기호로 rank(A)와 같이 나타낸다. 또 영공간의 차원을 Nullity라고 하고, 기호로 nullity(A)와 같이 나타낸다.
Four Fundamental Matrix Spaces
행렬 A과 전치 행렬 AT를 생각해 보자. 이 행렬을 이용해 나타낼 수 있는 벡터공간은 다음의 6개이다.
row space of Arow space of ATcolumn space of Acolumn space of ATnullspace of Anullspace of AT
이때, AT의 행벡터는 A의 열벡터와 같고, AT의 열벡터는 A의 행벡터와 같음을 고려하면 다음의 4개의 벡터공간을 고려할 수 있다.
row space of Acolumn space of Anullspace of Anullspace of AT
이 네 개의 행렬공간을 행렬 A의 주요 행렬공간(Fundamental Matrix Spaces)라고 한다.
Dimension Theorem
A가 n열의 행렬일 때,
rank(A)+nullity(A)=n
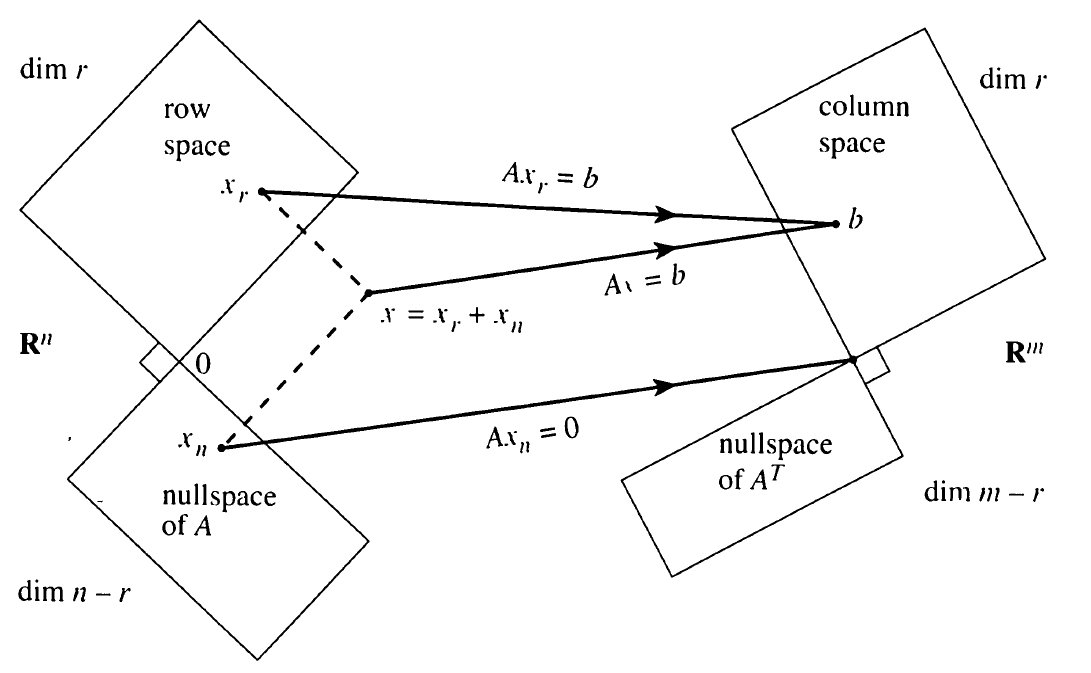
을 만족하는데, 이를 차원정리(Dimension Theorem)이라고 한다. 다음 그림을 보자. 행렬 A의 n차원 행공간을 Rn, m차원 열공간을 Rm과 같이 표현한다. 이때 행공간의 차원과 열공간의 차원은 동일하게 r이다. 아래 그림에서 행렬 A는 행공간의 벡터 x를 열공간의 벡터 b로 선형 변환하는 의미를 가짐을 알 수 있다. 이때 행렬 A의 영공간의 차원은 n−r이고, 행렬 AT의 영공간의 차원은 m−r이 된다.
Orthogonal Matrix
Inner Product
내적에 대해 다시 한 번 살펴보자. 체 F 위에서 정의된 벡터공간 V의 원소 u,v,w에 대해 다음을 만족시키는 함수 ⟨⋅,⋅⟩:V×V→F를 내적이라고 정의한다.
1. ⟨u,v⟩=⟨v,u⟩
2. ⟨u+v,w⟩=⟨u,w⟩+⟨u,w⟩
3.⟨ku,v⟩=k⟨u,v⟩
4. ⟨v,v⟩≥0where⟨v,v⟩⟺v=0
이 중 이전 포스트에서 다룬 것과 같이 정의되는 내적을 유클리드 내적(Euclidian Inner Product)라고 한다.
Inner Product Space
체 F 위에서 정의된 벡터공간 V에서 어떤 내적, 즉 ⟨⋅,⋅⟩:V×V→F가 정의될 때, V를 내적공간(Inner Product Space)라고 한다. F=C일 경우, V를 복소내적공간(Complex Inner Product Space)라고 하고, F=R일 경우, V를 실수내적공간(Real Inner Product Space)라고 한다.
Orthogonality
내적공간 V의 원소 u,v에 대해, ⟨u,v⟩=0일 때 두 벡터 u,v가 직교한다(Orthogonal)고 한다. 또 내적공간의 부분공간 W에 대해 u가 W의 모든 벡터와 직교할 때, 벡터 u는 W에 직교한다고 한다.
Orthonormal Basis
내적공간의 부분집합의 벡터가 모두 서로 직교하고, 각 벡터의 norm이 1인 경우, 이 집합을 정규 직교 집합(Orthonormal Set)이라고 한다. 기저가 orthonormal한 경우, 이를 정규 직교 기저(Orthonormal Basis)라고 한다.
Orthogonal Matrix
A−1=AT인 행렬을 직교 행렬(Orthogonal Matrix)이라고 한다. 이를 다음과 같이 표현하기도 한다.
AAT=ATA=I
n×n 행렬 A에 대해, 다음은 모두 동치이다.
1. A는 직교 행렬이다.
2. A의 행벡터는 행공간의 정규 직교 기저를 이룬다.
3. A의 열벡터는 열공간의 정규 직교 기저를 이룬다.
직교 행렬은 다음과 같은 성질을 가진다.
1. 직교 행렬의 전치 행렬은 직교 행렬이다.
2. 직교 행렬의 역행렬은 직교 행렬이다.
3. 직교 행렬끼리의 곱은 직교 행렬이다.
4. 직교 행렬의 행렬식은 1 또는 -1이다.
Eigenvalue & Eigenvector
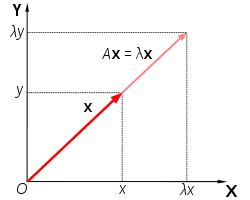
일반적으로 n×n행렬 A와 Rn의 벡터 x에 대해 x와 Ax 사이에는 아무런 기하학적 연관성이 없다. 하지만 Ax가 x의 스칼라배가 되게 하는 0이 아닌 벡터 x가 존재하는 경우가 있는데, 이때 이 벡터를 고유 벡터(Eigenvector)라고 한다. 좀 더 자세히 알아보자.
Eigenvalue & Eigenvector
n×n행렬 A와 Rn의 0이 아닌 벡터 x에 대해 다음을 만족하는 x를 A의 고유 벡터(Eigenvector)라고 한다.
Ax=λx
이때, λ는 A의 고윳값(Eigenvalue)라고 한다. 고윳값은 다음 방정식의 해이다.
det(A−λI)=0
다음 그림은 고유 벡터를 도시화한 것이다.
Eigenspace
고유 벡터의 해공간을 고유 공간(Eigenspace)라고 한다. 고유 벡터의 정의를 다시 한 번 보자.
Ax=λx
양변에 I를 곱하고 이항하여 정리하면
(A−λI)x=0
를 얻는다. 이 방정식의 자명하지 않은 해 x의 집합을 고유공간이라고 한다.
Singular Value Decomposition
Similarity
두 행렬 A,B가 다음을 만족할 때, 두 행렬을 닮음(Similar)이라고 한다.
P−1AP=B
닮음인 두 행렬 사이에는 다음이 성립한다.
1. 동일한 행렬식을 가진다.
2. A가 가역 행렬이면 B도 가역 행렬이고, A가 가역 행렬이 아니면 B도 가역 행렬이 아니다.
3. 동일한 Rank를 가진다.
4. 동일한 Nullity를 가진다.
5. 동일한 고윳값을 가진다.
6. A와 B의 고윳값 λ에 대한 고유공간의 차원이 동일하다.
특히, P가 직교 행렬인 경우 B는 A에 직교 닮음(Orthogonally Similar)이라고 한다.
Orthogonal Diagonalization
직교 닮음에서, 다음을 만족하는 경우 직교 행렬 P는 A를 직교 대각화(Orthogonally Diagonalize)한다고 하고, A는 직교 대각화 가능(Orthogonally Diagonalizable)하다고 한다.
P−1AP=D
직교 대각화가 가능하려면 A는 대칭 행렬, 즉 다음을 만족하는 행렬이어야 한다.
AT=A
P−1AP가 n차 대각 행렬일 때, A는 n개의 일차독립인 고유벡터를 갖는다.
Eigenvalue Decomposition
고윳값 분해(Eigenvalue Decomposition)은 직교 대각화의 한 종류이다. 직교 대각화 식에서, 다음을 쉽게 도출할 수 있다.
이때 X가 대각화 가능, 즉 모든 고유벡터가 선형독립이라면 위 식을 다음과 같이 쓸 수 있다.
A=XΛX−1
위와 같이 정사각행렬을 고윳값과 고유 벡터로 이루어진 행렬의 곱으로 표현하는 것을 고윳값 분해(Eignevalue Decomposition)이라고 한다.
Singular Value Decomposition
특이값 분해(Singular Value Decomposition)란 고윳값 분해를 m×n행렬로 일반화시킨 것으로, 행렬의 차원 축소에 이용된다. 좀 더 자세히 알아보자.
먼저, 특이값(Singular Value)에 대해 알아보자. 행렬 A의 크기가 n×p라는 것은 p차원에 n개의 점이 존재한다고 생각할 수 있다. 행렬 A에 대한 차원 축소란, n개의 점을 표현하는 기존의 p보다 작은 차원 d의 부분 공간을 찾는 문제라고 할 수 있다. 이때, 부분 공간은 각 점과의 수직 거리가 최소가 되어야 한다. 이때, 직선거리의 최소화는 제곱합의 최소화 문제로 바꾸어 볼 수 있다.
어떤 행렬의 제곱은 ATA 또는 AAT와 같이 표현할 수 있다. 행렬 A의 특이값(Singular Value)이란, ATA의 고우값에 루트를 씌운 값으로 다음과 같이 표현된다.
σi=λi
ATA는 직교 대각화가 가능한 행렬이므로, 이를 직교 대각화하여 고유값을 구하여 루트를 취하면 A의 특이값을 구할 수 있다. 이때 각 특이값은 Axi벡터의 길이로 생각할 수 있다.
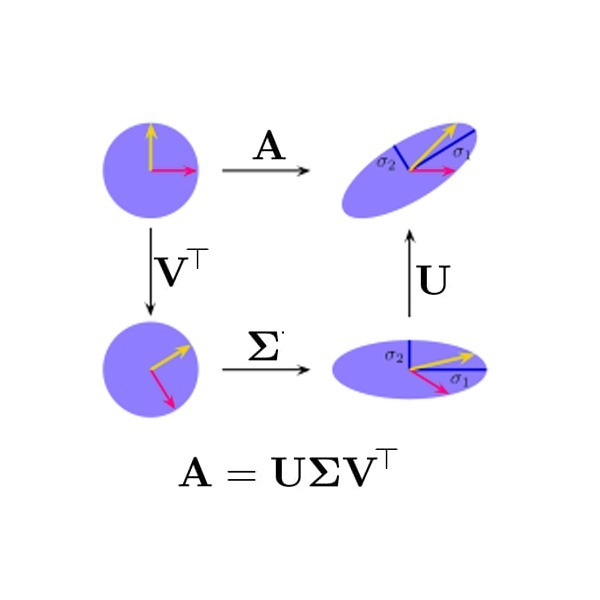
앞서 고윳값 분해를 A=PDPT와 같은 형태로 나타내었다. 특이값 분해(Singular Value Decomposition)은 다음과 같은 꼴로 나타내어진다.
A=UΣVT
AAT의 고유 벡터가 u1,u2,⋯,un이고, ATA의 고유 벡터가 v1,v2,⋯,vn일 때 각각의 벡터는 다음과 같이 나타내어진다.
특이값 분해를 그림으로 나타내면 다음과 같다.
그림에서 확인할 수 있는 것과 같이, 특이값 분해는 선형 변환 A를 회전, 팽창 또는 축소, 회전의 세 단계로 나누어 생각하게 하는 도구이다.
참고 자료
[1] 장철원, "Chapter 3: 머신러닝을 위한 선형대수" in 선형대수와 통계학으로 배우는 머신러닝. 비제이퍼블릭.
[2] Howard Anton, Elementary Linear Algebra, 7th edition, John Wiley & Sons, Inc.
[3] S. Friedberg et al., Linear Algebra, 4th edition, Pearson.
[4] David C. Lay et al., Linear Algebra And Its Applications, 5th edition, Pearson.
[5] 김창일 외, 고급 수학 II, 전라북도교육청.
[6] 공돌이의 수학정리노트 (Angelo's Math Notes), 고윳값 분해(eigen-value decomposition)[online]