1. 소개
붓꽃(Iris) 데이터는 세 가지(Iris setosa, Iris versicolor, Iris virginica)로 구성돼 있으며, 네 가지 특성이 있다. 목표는 이 특징을 기반으로 붓꽃을 분류하는 신경망 모델을 만드는 것이다.
붗꽃데이터 분류
-
학습데이터 100개, 테스트데이터 50개로 구성
-
neural network layer는 10,10,10,3(최종분류)로 설정
2. 정규화
Iris 데이터셋을 불러왔으며, 이 데이터를 학습데이터 100개, 테스트데이터 50개로 분리한다.
그리고 이 데이터를 정규화하여, 옵티마이저가 더 효율적으로 학습할 수 있게 한다.
여기서는 StandardScaler를 사용하였다. 이는 학습데이터의 평균과 표준편차를 구하고, 이것으로 각 특징이 평균이 0, 표준편차가 1이 되도록 스케일링했다.
3. 모델 구조
TensorFlow와 Keras로 신경망 모델을 만들었다.
입력층에서는 4개의 특징을 받았다.
은닉층은 총 3개로, 각 10개의 뉴런을 가지며 ReLU를 썼다.
출력층은 3개의 뉴런을 가지며, Softmax를 사용했다.
4. 모델 학습
옵티마이저는 Adam
손실 함수는 Sparse Categorical Crossentropy
metrics는 Accuracy로 했다.
또한, Accuracy를 높이기 위해, 에포크를 100으로 했다. 배치 크기는 5이다.
5. 결과
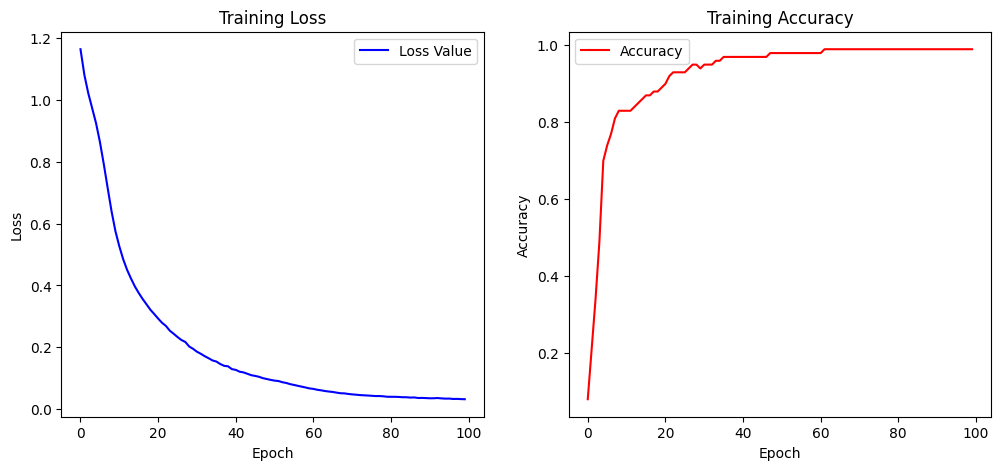
평가 Loss는 0.0633
평가 Accuracy는 97.33%가 나왔다.
이와 같이 테스트 세트에서 높은 Accuracy를 보였으므로 성능이 좋다고 할 수 있다. 또한, 이를 시각화한 그래프를 보면, 모델이 100 에포크 동안 효과적으로 학습했음을 알 수 있다.
import numpy as np
import tensorflow as tf
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from tensorflow import keras
import matplotlib.pyplot as plt
# Iris 데이터셋
iris_ds = load_iris()
# 학습데이터 100개, 테스트데이터 50개로 구성
x_train, x_test, y_train, y_test = train_test_split(
iris_ds['data'], iris_ds['target'], train_size=100, random_state=0
)
# 정규화
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
x_train = scaler.fit_transform(x_train)
x_test = scaler.transform(x_test)
# neural network layer는 10,10,10,3(최종분류)로 설정
model = keras.models.Sequential([
keras.layers.Dense(10, activation='relu', input_shape=(4,)),
keras.layers.Dense(10, activation='relu'),
keras.layers.Dense(10, activation='relu'),
keras.layers.Dense(3, activation='softmax')
])
# 컴파일
model.compile(
optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy']
)
print('model 학습중...')
# 모델 학습 history에 저장
hist = model.fit(x_train, y_train, epochs=100, batch_size=5, verbose=1)
print('model 테스트 결과:')
eval_loss, eval_acc = model.evaluate(x_test, y_test)
print('평가 손실:', eval_loss)
print('평가 정확도:', eval_acc)
# 시각화
plt.figure(figsize=(12, 5))
# Loss 그래프
plt.subplot(1, 2, 1)
plt.plot(hist.history['loss'], 'b-', label='Loss Value')
plt.title('Training Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend()
# Accuracy 그래프
plt.subplot(1, 2, 2)
plt.plot(hist.history['accuracy'], 'r-', label='Accuracy')
plt.title('Training Accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.legend()
plt.show()