
프로세스 구조
프로그램의 실행 단위를 프로세스라고 해요. 그럼 프로세스는 '일반적'으로 아래와 같이 구성되어 있어요.
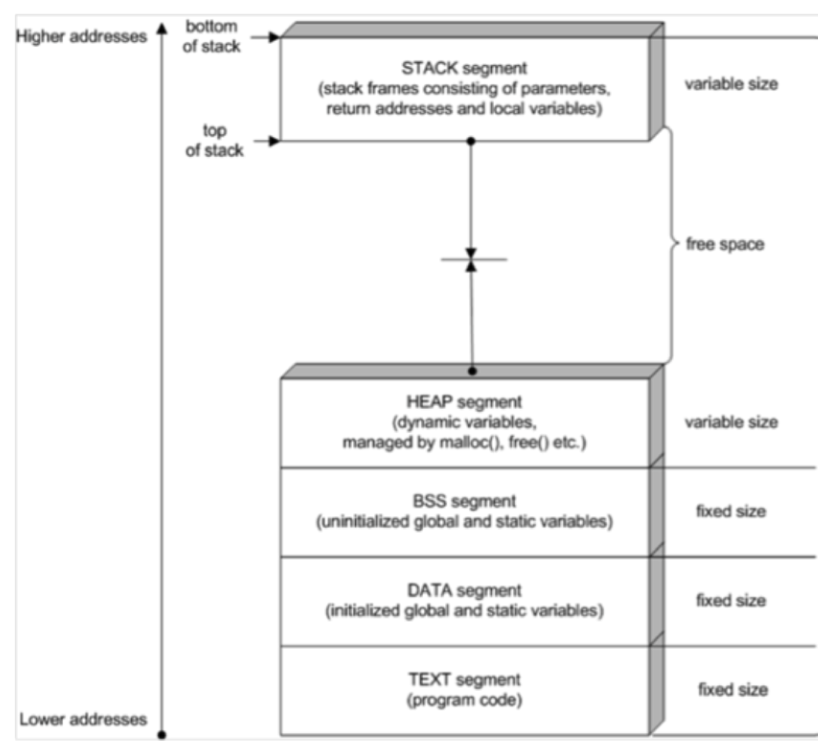
개인적으로 너무 전공 서적같은 디자인이라 복잡해보이네요 ㅎㅎ. 하지만 이것만큼 잘 설명하는 그림은 없다고 생각해요.
위 그림은 프로세스의 구조에요. 아래로 갈 수록 lower한 주소를 표기하니 아래부터 설명할게요.
프로세스 구조
1. TextCode: 프로세스의 프로그래밍 코드에요. 기계어로 번역되어 적재되어 있어요.
2. Data : 정적 및 전역 변수가 적재되어 있어요.DATA와BSS로 나뉘는데, 각각 초기화된 것과 초기화되지 않은 것을 관리해요.
3. Heap : 메모리 할당된 변수들을 관리해요. C언어의malloc을 통해 할당된 변수가 여기에 있어요.
4. Stack : 지역 변수 및 함수 호출 같은 임시 데이터들을 관리해요.
프로세스에서 Text, DATA, BSS는 실행되자마자 고정된 메모리를 가져요. 하지만 Stack은 위 아래, Heap은 아래 위로 메모리 적재량이 유동적으로 바뀌어요. 둘 다 Stack 자료구조 형식으로 LIFO이에요.
내부 동작
프로세스 내부 동작에 대해 살펴봐요. 쬐금 복잡하지만 중요한 부분이에요. 그전에 사전에 알아야할 PCB부터 알아봐요.
Process Control Block(PCB)
PCB는 특정 프로세스를 관리할 필요가 있는 정보를 포함하는 운영체제 커널의 자료구조에요.
프로세스 스케줄링을 위해서 프로세스에 관한 중요한 정보를 담고 있는 자료에요. 프로세스가 생성될 때마다 고유의 PCB가 생성되고 당연히 프로세스가 종료되면 제거되요.
관리되고 있는 정보를 나열하자면,
- Process ID
PID: 프로세스를 식별하는 ID- 프로세스 상태
Process State: 생성Create, 준비Ready, 실행Running, 대기Waiting, 완료Terminated상태- 프로그램 계수기
Program Counter: 코드 한 줄을 가리키는 주소 레지스터. 다음에 실행할 명령어의 주소를 가리켜요.- CPU 레지스터 및 일반 레지스터
- CPU 스케줄링 정보 : 우선 순위, 최종 실행시간, CPU 점유 시간 등
- 메모리 관리 정보 : 해당 프로세스의 주소 공간
- 프로세스 계정 정보 : 페이지 테이블, 스케줄링 큐 포인터, 소유자, 부모 등
- 입출력 상태 정보 : 프로세스에 할당된 입출력 장치 목록, 열린 파일 목록 등
- 포인터
Stack Pointer: 부모 프로세스에 대한 포인터, 자식 프로세스에 대한 포인터, 프로세스가 위치한 메모리 주소에 대한 포인터, 할당된 자원에 대한 포인터 정보. 함수 실행 될때Stack최상단 주소 레지스터.
- 참고 : jwprogramming님 블로그
PCB를 먼저 설명드리는 이유는, 프로세스는 프로그램 계수기PC와 포인터SP를 통해 프로세스가 다음에 어떤 Code를 수행하고, 어디 Stack의 주소에 데이터를 메모리에 적재할지 구분해요. 이 두 개념은 PCB에서 관리하고 있어요.
프로세스 내부 로직을 설명하기에 앞서 해당 정보는 어디서 관리되고 있는지를 미리 말씀드리고 싶었어요. 그리고 이 두 정보를 사용할 땐 PCB에서 가져다 쓰는게 아니라 CPU 레지스터라는 곳에서 따로 관리해요. 문맥 교환(Context Switching)이 일어나서 CPU 레지스터에 있는 Running Waiting 상태의 프로세스의 두 정보를 PCB에 저장해두었다가, Running 상태가 된 다른 프로세스의 PC와 SP를 CPU 레지스터에 적재해서 실행시키기 위함이죠.
사전 개념을 파악했으니 이제 동작하는 방식에 대해 알아봐요.
동작 예

앞서 설명 못드린 부분이 있네요.
여기서 EAX는 함수의 반환 값을 저장해요. 그리고 EBP는 Stack의 최상단 주소를 담은 레지스터에요. 함수를 타고 들어가다 문제가 발생했을 때 빠르게 추적하기 위해 존재해요.
위 그림을 기준으로 프로세스 내부에 대해 설명하면 아래와 같아요참고로 해당 .Code는 Python이에요
프로세스 내부
1. 컴파일 후 코드는Text영역에 들어가요
(원래Text는 위 그림과 달리 기존에 짠 코드와 반대 형식, 즉 Stack 형식으로 적재가 되요. 좌측에 있는 코드처럼요).
2.0000h: 함수 선언부라 아무일도 일어나지 않아요.
(PC=0000h,SP=1000h)
3.0001h: 함수 구현부라 아무일도 일어나지 않아요.
(PC=0001h,SP=1000h)
4.0002h:c = 0를DATA영역에 적재해요.
(PC=0002h,SP=1000h)
5.0003h:c = func(1,2)실행해요. 두개로 나눈 이유는 기계어로 나누면 함수를 실행 결과 값을c에 초기화하기 때문이에요.
5-1.1000h: 이 때Stack과EBP에SP값을 적재해요.
(push1000h,EBP=1000h)
5-2.0FFFh:그리고Stack에 해당 함수가 끝났을 때 수행할 다음 주소를 적재해요.
(push0004h(ret=0004h))
(PC=0003h,SP=0FFEh)
5.0FFEh&0FFDh:a=1&b=2, 각 인자를 넣어줘요.
(PC=0000h,SP=0FFCh)
6.return이 호출 되었어요.return값은EAX라는 레지스터에 저장되요.
(PC=0001h,SP=00FCh)
7. 여태Stack적재된func()관련 메모리를 pop해줘요. 그러면ret=0004h를 통해 다음에 실행할 코드 주소를 알고 다음을 실행해요.
(PC=0004h,SP=1000h)
8.0004h:EAX에서 결과 값을 확인해서c=func()결과 값을 초기화해요.
9.0005h:print(c)를 수행해요.
휴, 꽤 길군요. 그런데 말이죠.
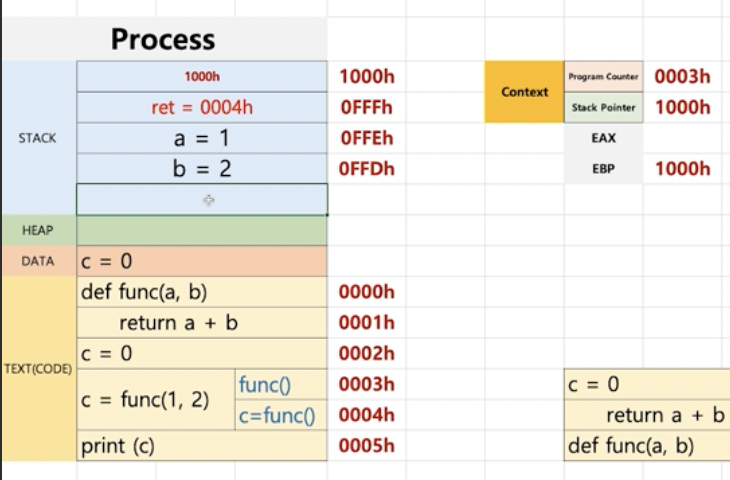
위 그림은 5까지 수행한 시점이에요. 그런데 만약에 func(a,b) 안에 다른 함수가 호출되면,
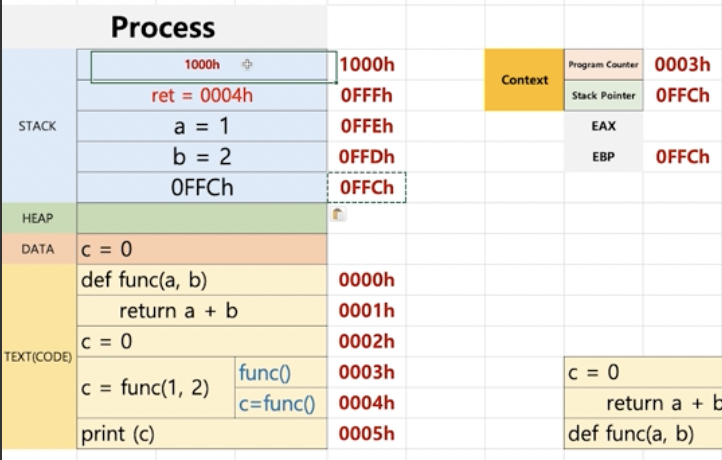
0FFCh에 0FFCh가 적재되고 EBP 값도 0FFCh로 변경되요. 굳이 이렇게 복잡하게 가는 이유는 문제가 발생했을 때 추적Tracking 하기 위해서에요.

이 때 EBP는 함수2의 최상단 SP를 가지게 되요.
함수2에서 문제가 발생하게 되면 EBP를 통해 함수2에서 문제가 발생했는지, 어느 시점에서 문제가 발생했는지를 알 수 있어요. 추가로 함수1이 수행된 시점까지도 알 수 있어 여러 로직으로 얽혀 있는 코드 이슈를 추적할 수 있게 되는거에요.
프로세스 내부 로직에 대한 설명은 여기까지에요. 매우 중요하면서 어려운 부분이라 당장은 이해하고 기억하겠지만 복습이 꾸준히 필요할 것 같네요 ㅎㅎ.
