
정규식(Regular Expression)
정규식Regular Expression이란 텍스트 데이터 중에서 원하는 조건패턴과 일치하는 문자열을 찾아내기 위해 사용하는 것으로, 미리 정의된 기호와 문자를 이용해서 작성한 문자열을 말해요.
정규식을 사용하면 대량의 텍스트에서 원하는 데이터를 손쉽게 뽑을 수 있고, 입력 데이터가 형식에 맞는지 확인이 가능해요.
기본적인 사용법은 아래와 같아요.
Java에서 정규식 사용법
1. 정규식을 매개변수로Pattern클래스의 static 메서드인Pattern.compile(String regex)을 호출해서Pattern인스턴스를 얻어요Pattern pattern = Pattern.compile("c[a-z]*");2. 정규식으로 비교할 대상을 매개변수로
Pattern클래스의Matcher.matcher(CharSeqeunce input)을 호출해서Matcher인스턴스를 얻어요Matcher matcher = pattern.matcher(/* 체크할 대상 문자열 */);3.
Matcher인스턴스에boolean matches()를 호출해서 정규식에 부합하는지 확인해요if(matcher.matches())
Pattern p = Pattern.compile("a*"); // 맨 앞에 a를 포함한 모든 문자열,
//a 자체도 포함되요
Matcher m = p.matcher("a");
m.matches(); // true
m = p.matcher("ab");
m.matches(); // true
m = p.matcher("baa");
m.matches(); // false패턴 키워드
자주 쓰일 만한 키워드를 정리해봐요. 모든 걸 정리하기엔 양이 꽤나 많기에, 빈도가 높은 걸 정리해봐요 ㅎㅎ.
| 패턴 | 설명 |
|---|---|
| [a-z] | 모든 소문자 |
| [A-Z] | 모든 대문자 |
| [a-zA-Z] | 모든 영문자 |
| [a-zA-Z0-9] | 모든 영문자와 숫자 |
| * | 0개 이상의 모든 문자, a*이라면 a부터 시작하는 모든 문자열 |
| . | 모든 문자열 |
| [a|b] | a 또는 b |
| c.*t | c로 시작하고 t로 끝나는 모든 문자열 |
| \w | 모든 문자열 |
| \d | 모든 숫자 |
| + | 하나 이상의 문자, *와 달리 1개는 있어야 해요 |
| .{2} | 두 자리 문자열, {}는 개수를 표현해요 |
| .{1,2} | 하나 이상 둘 이하 문자열 |
| {^b|c} | b가 아니거나 c(근데 이러면 모든 문자열이네요 ㅎㅎ) |
일단 아래 소스들 돌려보시면서 익히는 것도 추천해요.
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class RegularEx2 {
public static void main(String[] args) {
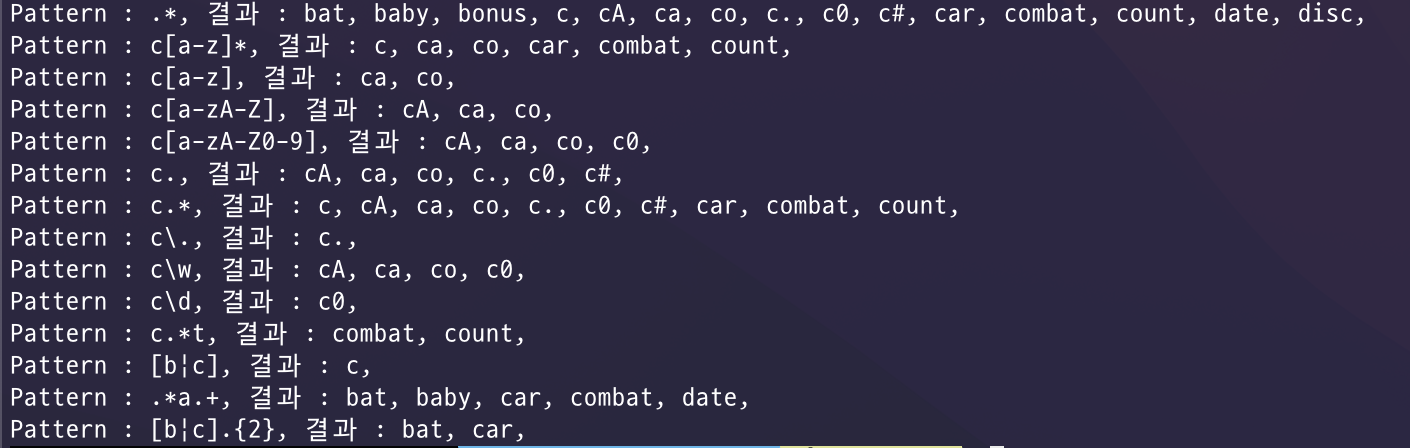
String[] data = {
"bat", "baby", "bonus", "c", "cA", "ca", "co",
"c.", "c0", "c#", "car", "combat", "count", "date", "disc"
};
// 역슬래쉬는 두번 쳐야 인식되요
String[] pattern = {
".*", "c[a-z]*", "c[a-z]", "c[a-zA-Z]",
"c[a-zA-Z0-9]", "c.", "c.*", "c\\.", "c\\w", "c\\d",
"c.*t", "[b|c]", ".*a.+", "[b|c].{2}"
};
for(int x = 0; x < pattern.length; ++x){
Pattern p = Pattern.compile(pattern[x]);
System.out.print("Pattern : " + pattern[x] + ", 결과 : ");
for(int i = 0 ; i < data.length; ++i){
if(p.matcher(data[i]).matches()){
System.out.print(data[i] + ", ");
}
}
System.out.println();
}
}
}
정규식 그룹화
정규식의 일부를 괄호로 나누어 묶어서 그룹화Grouping할 수 있어요. 그룹화된 부분은 하나의 단위로 묶이는 셈이 되어서 하나 이상의 반복을 의미하는 +나 *가 뒤에 오면 그룹화된 부분이 적용대상이 되요. 그리고 그룹화된 부부분은 group(int i)를 이용해서 나누어 얻을 수 있어요.
String source = "HP:011-1111-1111, HOME:02-9999-9999";
// 괄호로 그룹화!
String pattern = "(0\\d{1,2})-(\\d{3,4})-(\\d{3,4})";
Matcher m = Pattern.compile(pattern).matcher(source);
int i = 0;
while(m.find()){
System.out.println(++i + ": " + m.group() + " -> " + m.group(1)
+ ", "+ m.group(2) + ", " + m.group(3));
}
// 결과 :
// 1: 011-1111-1111 ->011, 1111, 1111
// 2: 02-9999-9999 ->02, 9999, 9999예제를 보시면 괄호로 그룹화하는 것을 아실 수 있어요. 그리고 group()이나 group(0)은 문자열 전체를 나누니 않은 채로 반환하는 것을 확인하실 수 있어요.
find()는 주어진 소스 내에서 패턴과 일치하는 부분을 찾으면 true를 반환하고 찾지 못하면 false를 반환해요. 이는 내부적으로 일종의 커서가 있어서 한번 수행할 때 이전에 발견한 패턴과 일치하는 부분의 다음부터 패턴이 일치하는 다음 것을 찾아줘요.
또한 Matcher의 find()로 정규식과 일치하는 부분을 찾으면, 그 위치를 start()와 end()로 알아 낼 수 있고 appendReplacement(StringBuffer sb, String replacement)를 이용해서 원하는 문자열로 치환할 수 있어요. 그 결과는 매개변수인 sb에 저장되요.
String source = "A broken hand works, but not a broken heart.";
String pattern = "broken";
StringBuffer sb = new StringBuffer();
Matcher m = Pattern.compile(pattern).matcher(source);
int i = 0;
while(m.find()){
System.out.println(++i + "번째 매칭 : " + m.start() + "~" + m.end());
// broken을 drunken으로 치환하여 sb에 저장해요.
m.appendReplacement(sb, "drunken");
}
m.appendTail(sb);마지막에 appendTail이 추가되었는데요, 이에 대해 설명드리자면, while 문에서는 원래 문자열의 broken을 drunken으로 바꿔주기 위한 동작을 수행해요.
첫번째 find() 메소드 호출에서는 true가 반환되고 Matcher 인스턴스는 원래 문자열에서 첫번째 broken 부분을 가리켜요.
이 때, Matcher.group 은 broken를 반환해요. 그리고 이것을 sb에 붙여 넣게 되는데, 이 시점에서 sb에는 아래와 같은 값이 들어와요.
"A drunken"이렇게 패턴 매칭되는 부분까지 붙여 넣어요. 그리고 두번째 broken을 찾아서 replace하면 sb엔 아래와 같은 문자열이 들어와요.
"A drunken hand works, but not a drunken"그러니 Matcher.appendTail(sb)를 실행시켜서 나머지 부분이 들어올 수 있게 해요. 이 메서드의 의미는 마지막 매칭 직후의 문자열들을 sb에 추가해주는 메서드 인거죠.
"A drunken hand works, but not a drunken heart."그래서 실제로 API 설명에도 appendReplacement 수행 이후에 호출을 시켜줘야 한다고 써 있어요.
참고
