[부스트캠프 AI tech CV] week08 (2022.03.08) Semantic Segmentation / Object Detection
부스트캠프 AI tech 3기
목록 보기
23/40
04 Sementic Segmentation
- 픽셀단위로 여러 카테고리로 분류
- 의료영상, 자율주행, computational photography 등에 사용
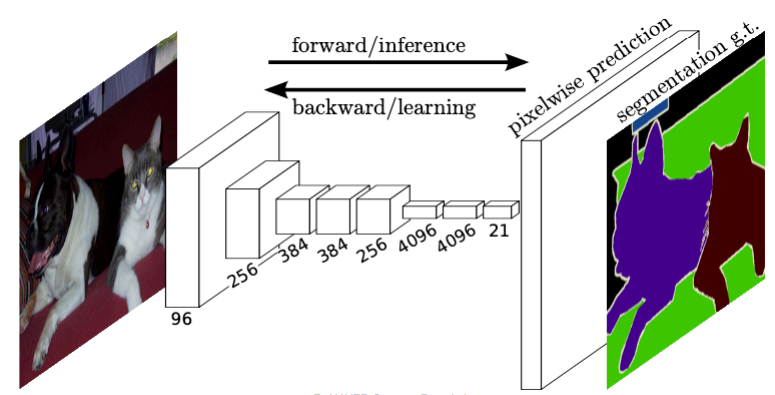
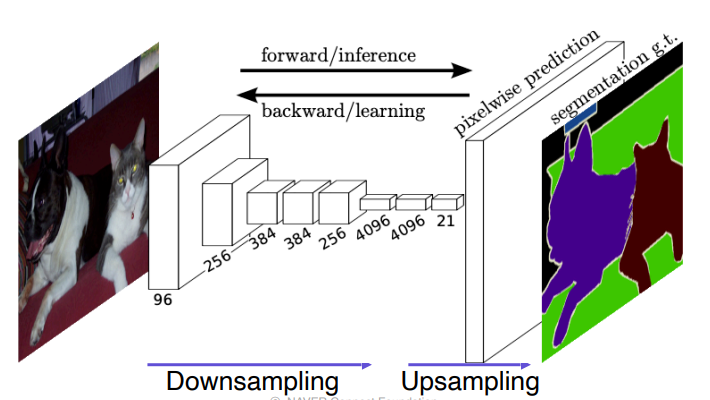
Fully Convonlutional Networks(FCN)
- 임의의 사이즈의 영상을 사용해도 호환성이 높음
- sementic segmentation을 위한 end-to-end 구조
- 공간정보를 고려하는
classification map을 출력함- 주로
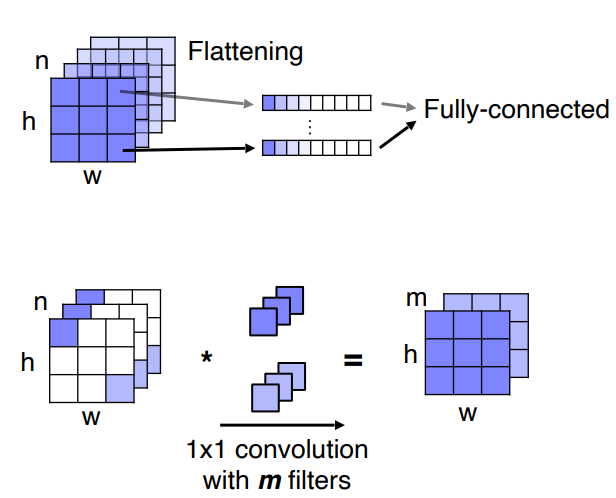
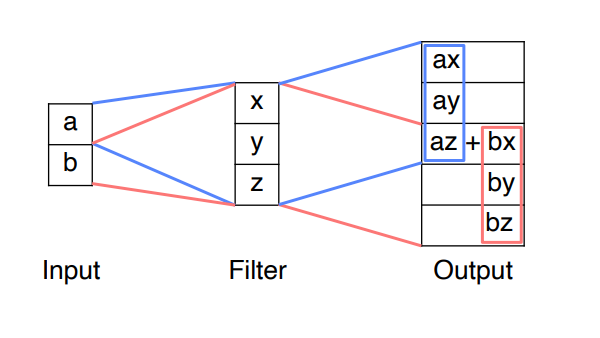
1x1 conv layer를fc layer대신 사용
- channel 축으로 flatten을 하면 위치정보를 고려할 수 있음 (=
1x1 conv와 동일한 결과)
- FCN로 인해 해상도가 작아진 activation map을 원래 입력사이즈와 맞춰주기 위해
upsampling이 필요함recptive field는 최대로 키워주는게 성능이 좋음, 그 후에upsampling을 통해 크기를 맞춤
upsampling 방법
Transposed convolution
- 중첩되기 부분 때문에 checkerboard현상이 나타날 수 있음
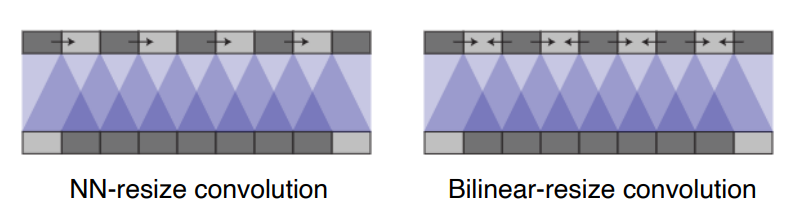
Upsample and convolution
Nearest-neighbor(NN),Bilinear등의 기존 interpolation방법 적용 후에 3x3 등 convolution을 적용함
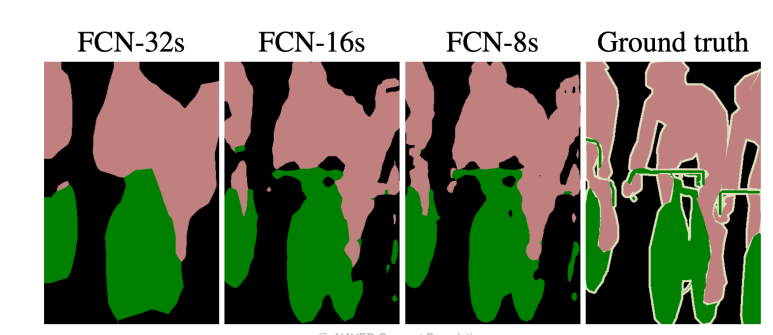
Activation map
- 얕은 layer일수록
local feature를 보고, 깊은 layer일수록global feature를 봄
- 좋은
sementic segmentation을 위해 여러 layer를 동시에 사용할 필요가 있음upsampling해서 해상도를 맞추고concatenation해서 모델을 만듦


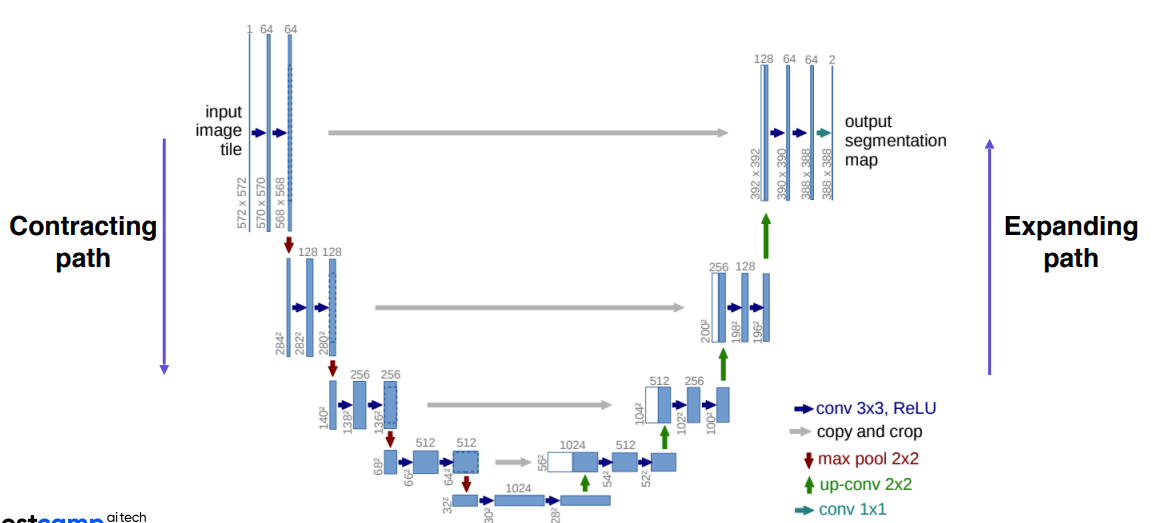
U-Net
- fully convolutional Network
contracting path와expanding path로 나뉨- similar to skip connection in FCN
Contracting Path
3x3 convdoubling channelsExpanding Path
2x2 convTransposed2d(stride=2)
-> 중첩이 없기 때문에checkerboard현상이 안생김halving channelsconcatenating maps from the contracting path
DeepLab
Deeplab v3+

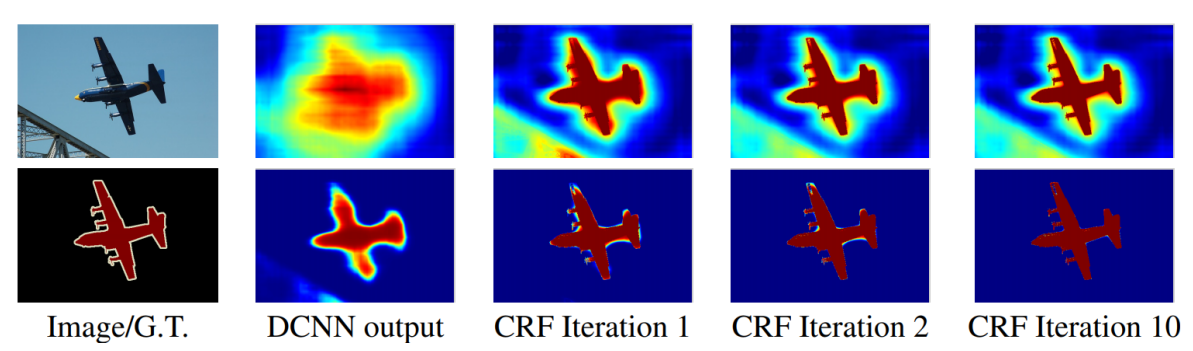
Conditional Random Fields(CRFs)
- 픽셀과 픽셀사이의 관계를 이어줌
출력 score 값과이미지의 경계선을 활용
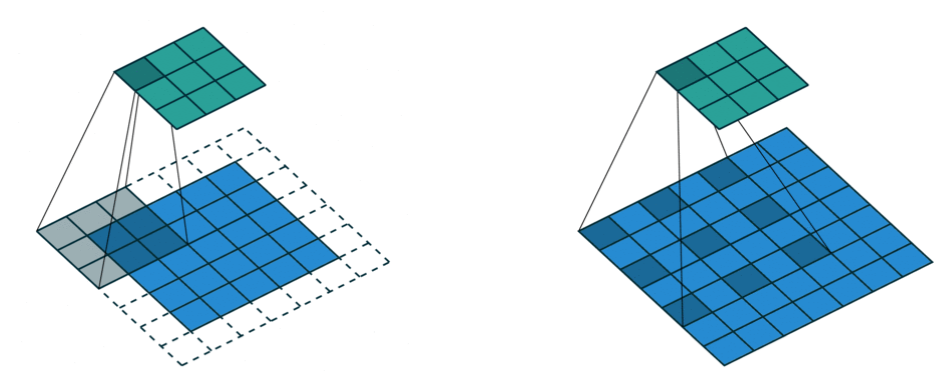
Dilated Convolution (atrous convolution)
receptive field의 해상도를 동일한 파라미터 수로 exponential하게 증가시킬 수 있음- semantic segmantation map의
blurring현상을 감소시킴
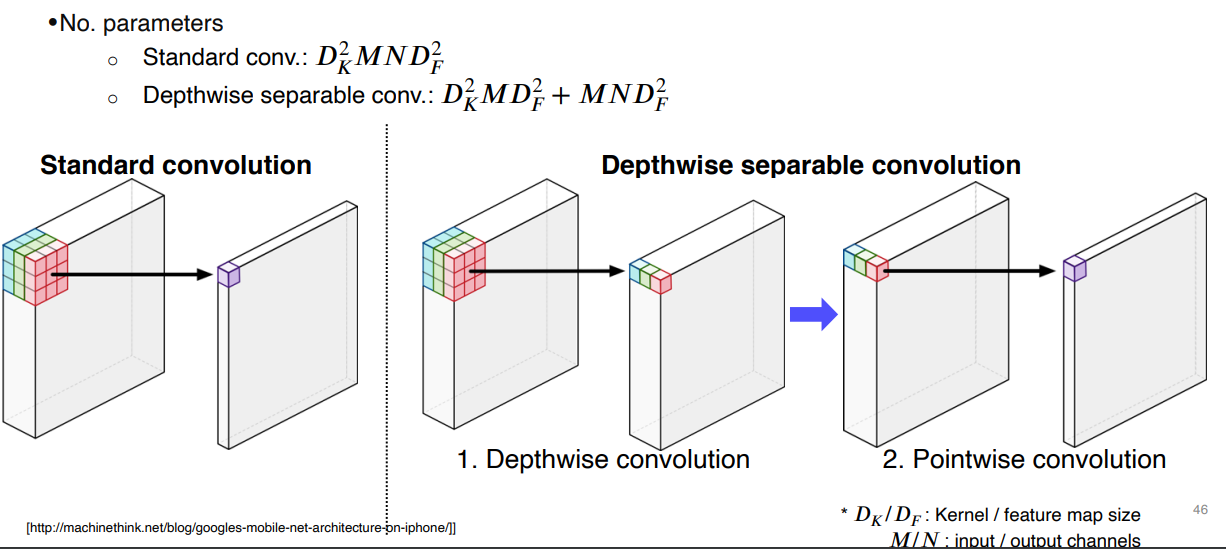
Depthwise separable convolution
- 표현력은 어느정도 유지되면서 계산량을 줄임
others
Instance segmentationPanoptic segmentation
05 Object Detection
- classification + Box Localization
- 자율주행, OCR 등
Two-stage detector
- Gradient-based detector(e.g. HOG)
- selective search
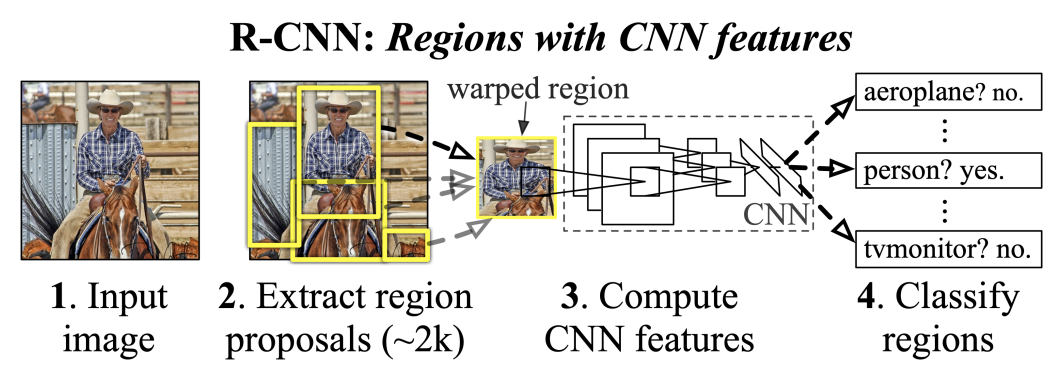
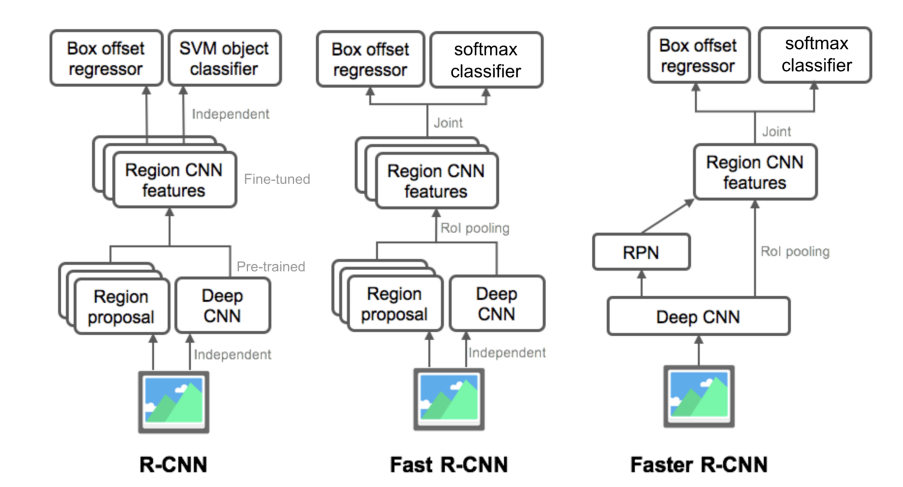
- R-CNN
-Extract region proposal:selective search와 같은 방법으로 추출
-Compute CNN features: pretrain된 CNN모델을 이용하여 임베딩 추출
-Classify regions: CNN에서 얻은 feature를 SVM을 통해 classification
- SVM으로 분류
- 속도가 느림
- region proposal방법으로 인한 학습을 통한 성능향상의 한계
- Fast R-CNN(참고블로그)
- selective search 사용
- ROI Pooling 사용
- Faster R-CNN
- Region proposal 개선
- end-to-end 모델
- IoU(Intersection over Union)
- Anchor Boxes
- selective search를
Region Proposal Network(RPN)로 대체- Non-Maximum Suppression(NMS): IoU기준으로 겹치는 bbox를 제거


One-stage detector
- 정확도 대신 속도를 선택
- ROI관련 요소가 없음
- YOLO
- SSD
- RetinaNet
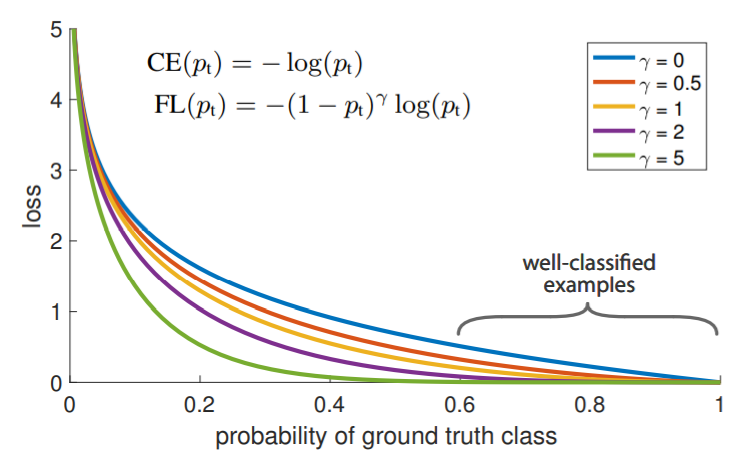
Focal Loss
- loss가 큰 부분에 대해
crossentropy에 비해 경사가 커지면서 역전파시 학습에 도움이 됨- class imbalance 문제를 해결하기 위한 방안
Transformer
- DETR

인공지능 꿈나무