1. EfficientNet
- 기존 방법론에서는 heuristic하게 모델의 구조를 변환하여 사용하였음
- 어느 정도 이상의 크기가 되면 더 이상의 성능향상은 없고 속도만 느려짐
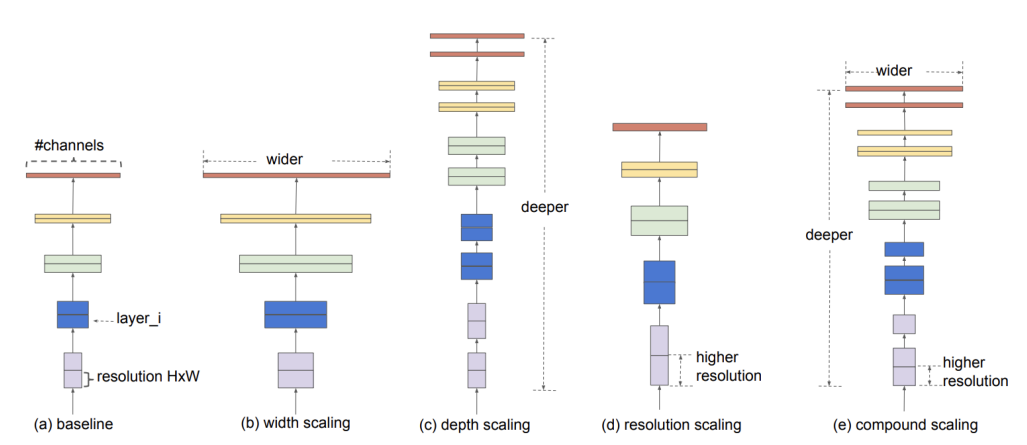
Width Scaling
- 작은 모델에서 주로 사용됨 ex. Mobilenet, MnasNet
wide한 네트워크는 미세한 특징을 잘 잡아내는 경향이 있고, 학습이 쉬움- 극단적으로 넓지만 얕은 모델은
high-level특징을 잘 못잡아내는 경향도 있음Depth Scaling
- 많은 ConvNet에서 쓰임 ex. DenseNet, Inception-v4
- 더 풍부하고 복잡한 특징을 잡아낼 수 있음
- 새로운 task에도 잘 일반화 됨
- gradient vanishing 문제가 있어 학습이 어려움
Resolution Scaling
- 고화질의 input을 사용하면 convNet은 미세한 패턴들 잘 잡아낼 수 있음
- Gpipe는 이미지를 이용하여 imageNet SOTA를 달성함
Object function
- : model
- 한정된 resource에서 model의 accuracy를 최대로하는 을 찾는 것이 목표
Observation
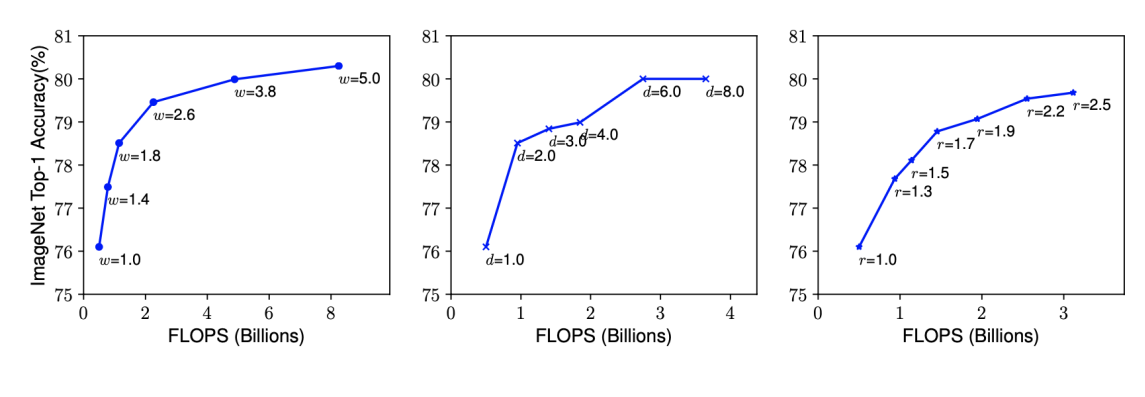
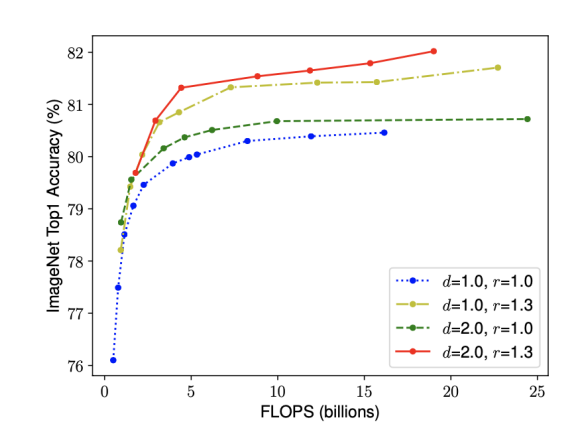
- 네트워크의 폭, 깊이, 혹은 해상도를 키우면 정확도가 향상되지만 더 큰 모델에 대해서는 정확도 향상 정도가 감소한다
- 더 나은 정확도와 효율성을 위해서는, ConvNet 스케일링 과정에서 네트워크의 폭, 깊이, 해상도의 균형을 잘 맞춰주는 것이 중요하다.


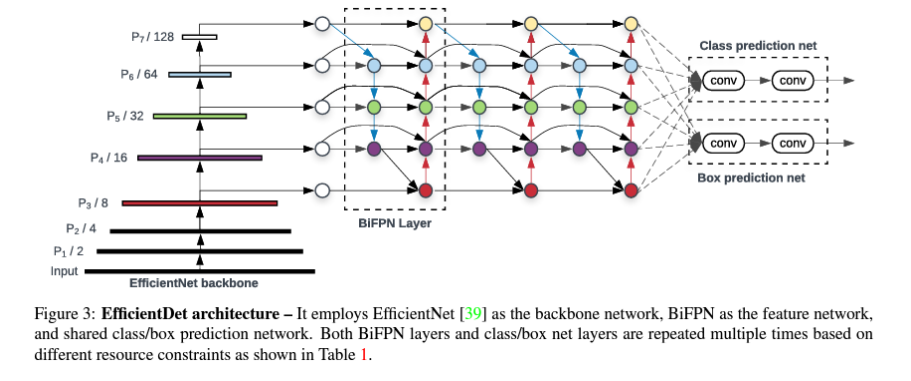
2. EfficientDet
Efficient multi-scale feature fusion
- 기존에는
FPN,PANet,NAS-FPN등 Neck사용- 대부분의 기존 연구는
resolution구분없이feature map을 단순 합- input을 위한 학습 가능한 웨이트를 두는
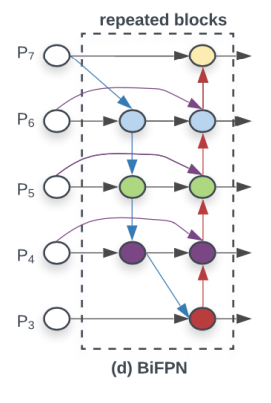
Weighted Feature Fusion방법으로 BiFPN(bi-directional feature pyramid network)를 제안cross-scale connection방법 이용
- BiFPN
- 하나의 간선을 가진 노드는 제거
- ouput 노드에 input 노드 간선 추가
- 양방향 path 각각을 feature layer로 취급하여
repeated blocks활용
biFPN구조를 3번 반복함
- 단순 합을 하던
FPN구조와 달리weighted sum을 사용함- 가중치들은
ReLU를 통과시켜 항상 0이상의 값이 되도록하고, 분모가 0이 되지 않도록 을 더해줌Model scaling
:depth, :resolution
- 네트워크의
width(channel 수)와depth(layer 수)를 compound 계수에 따라 증가시킴- 는 greed search로 찾은 파라미터
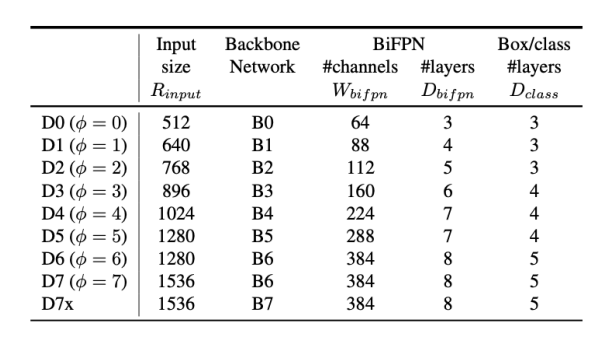
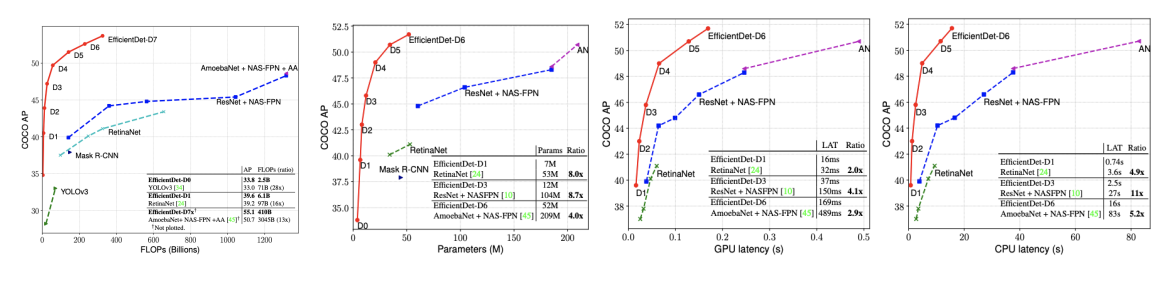
result


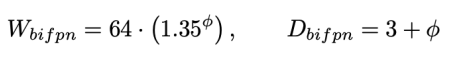
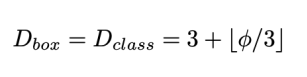
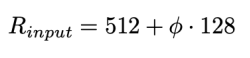

인공지능 꿈나무