1. Model serving
Production(real world)환경에 모델을 사용할 수 있도록 배포하는 것머신러닝모델->현실세계사용=서비스화input에 대해output을 반환
- 크게 아래와 같은
serving이 존재
1)Online serving
2)Batch serving
3)Edge serving
- 용어정리
Serving: 모델을 웹/앱 등 서비스에 배포하는 과정, 모델을 활용하는 방식, 모델을 서비스화하는 관점Inference: 모델에 데이터가 제공되어 예측하는 경우, 사용하는 관점Online serving/Online inference는 주로 구분되어 사용Batch serving의 경우Inference개념이 포함되어 사용되기도 함
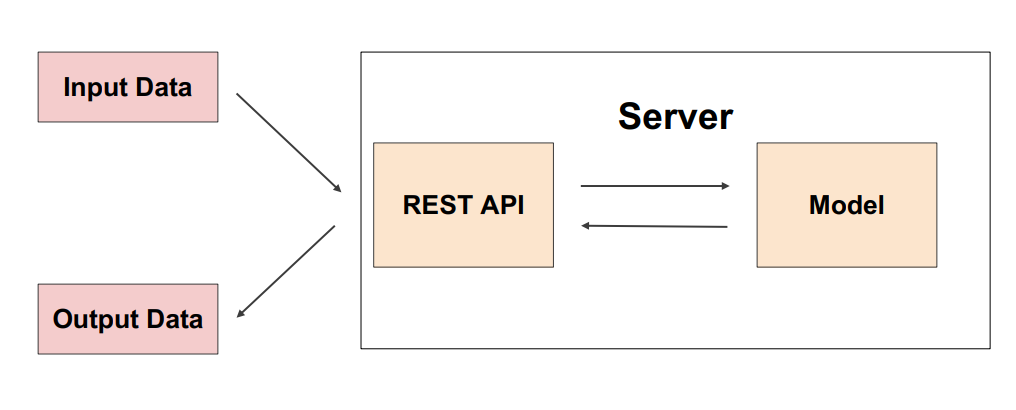
2. Online serving
- 요청이 올 때마다 실시간으로 예측
1) 클라이언트에서 ML 모델 서버에 HTTP요청(Request)하고,
2) 머신러닝 모델 서버에서 예측한 후,
3) 예측 값을 반환(Response)- ML 모델 서버에 요청할 때 필요시 ML 모델 서버에서
데이터 전처리해야할 수 있음
1) 직접 API 웹 서버 개발:
Online Serving을 구현하는 방식Flask,FastAPI등을 사용해 구축
2) 클라우드 서비스 활용: AWS의SageMaker, GCP의Vertex AI등
- 직접 구축해야하는 MLOps의 다양한 부분이 만들어지고 학습코드만 제공하면 API 서버가 만들어지는 편리함이 있음
- 클라우드 서비스가 익숙해야 잘 활용할 수 있고, 직접 만드는 것보다는 더 많은 비용이 든다는 단점이 있음
3) Serving 라이브러리 활용:Tensorflow Serving,Torch Serve,MLFlow,BentoML등
추천방식
1) 프로토타입 모델을클라우드 서비스를 활용해 배포
2) 직접FastAPI등을 활용해 서버 개발
3)Serving라이브러리를 활용해 개발
고려할 부분
: 실시간 예측을 위해지연시간(Latency)를 최소화 해야함
:Input data를 기반으로Database에 있는 데이터를 추출해서 모델 예측해야하는 경우
: 모델이 수행하는 연산
: 결과값에 대한 보정이 필요한 경우(ex. 음수값처리)
:데이터전처리 서버분리/feature 미리가공,모델 경량화,병렬처리(Ray),예측결과 캐싱등의 방법으로 해결
3. Batch serving
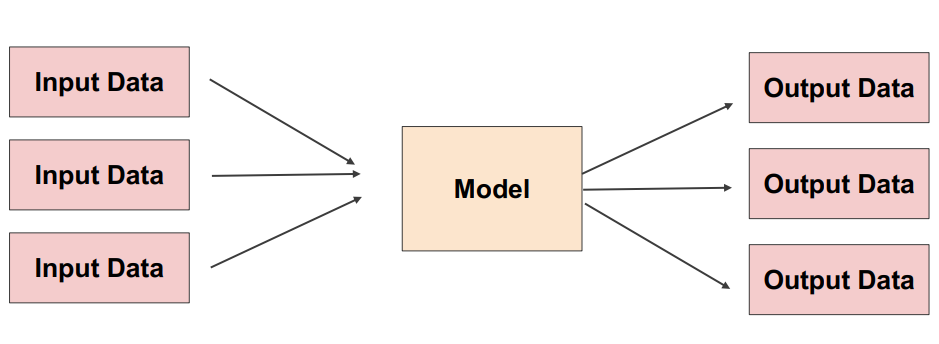
- 특정 기간 단위로 작업을 반복 수행
- 라이브러리는 따로 존재하지는 않음 ->
Airflow,Cron Job등으로 스케줄링 작업(Workflow Scheduler)Online Serving보다 구현이 수월- 한번에 많은 데이터를 처리하므로
Latency가 문제되지 않음- 주기적으로 업데이트되기 때문에 실시간으로 활용할 수 없음
->Cold Start문제

인공지능 꿈나무