08 Multi-GPU 학습
강의 소개
PyTorch에서 Multi GPU를 사용하기 위해 딥러닝 모델을 병렬화 하는 Model Parallel의 개념과 데이터 로딩을 병렬화하는 Data Parallel의 개념을 학습합니다. 이를 통해 다중 GPU 환경에서 딥러닝을 학습할 때에 효율적으로 하드웨어를 사용할 수 있도록 하고, 더 나아가 딥러닝 학습 시에 GPU가 동작하는 프로세스에 대한 개념을 익힙니다.
Model parallel
- 모델을 병렬화 하는 방법
- Alexnet에서도 사용됨
Data parallel
- 데이터를 나눠 GPU에 할당 후 결과의 평균을 취하는 방법
- minibatch 수식과 유사한데 한번에 여러 GPU에서 수행
- GPU 사용 불균형 발생
- DataParallel 코드
parallel_model = torch.nn.DataParallel(model)- DistributedDataParallel 코드(참고)
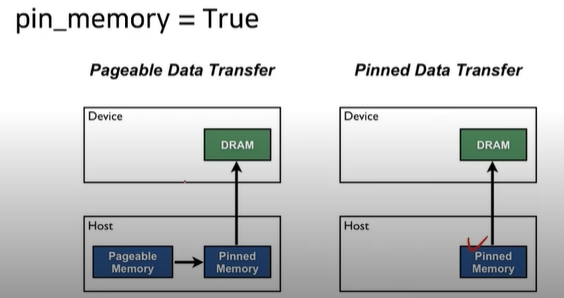
train_sampler = torch.utils.data.distributed_DistributedSampler(train_data) shuffle = False pin_memory = True trainloader = torch.utils.data.DataLoader(train_data, batch_size=20, shuffle=True, pin_memory, num_workers=3, shuffle=shuffle, sampler=train_sampler)def main(): n_gpus = torch.cuda.device_count() torch.multiprocessing.spawn(main_worker, nprocs=n_gpus, args=(n_gpus,)) def main_worker(gpu, n_gpus): ...
- pin_memory
09 Hyperparameter Tuning(colab)
강의 소개
PyTorch 기반으로 여러 config들을 통해 학습할 때에 사용되는 parameter들을 실험자가 손 쉽게 지역 최적해를 구할 수 있도록 도와주는 Ray Tune 프레임워크로 최적화하는 방법을 학습합니다. 이를 통해 Grid & Random, 그리고 Bayesian 같은 기본적인 Parameter Search 방법론들과 Ray Tune 모듈을 사용하여 PyTorch 딥러닝 프로젝트 코드 구성을 하는 방법을 익히게 됩니다.
Further Question
모델의 모든 layer에서 learning rate가 항상 같아야 할까요? 같이 논의해보세요!
ray tune을 이용해 hyperparameter 탐색을 하려고 합니다. 아직 어떤 hyperparmeter도 탐색한적이 없지만 시간이 없어서 1개의 hyperparameter만 탐색할 수 있다면 어떤 hyperparameter를 선택할 것 같나요? 같이 논의해보세요!
Tuning
- 모델 바꾸기
- 데이터 추가*
- Hyperparameter Tuning
Hyperparameter Tuning
- 베이지안 기반 기법 -> BOHB(2018)
Ray
- multi-node multi processing 지원 모듈
- ML/DL의 병렬 처리를 위해 개발된 모듈
- 기본적으로 현재의 분산 병렬 ML/DL 모듈의 표준
- Hyperparameter Search를 위한 다양한 모듈 제공
config: search spaceASHAScheduler: 성능이 안좋은 H/P를 걸러내며 튜닝CLIRporter: 결과 출력 양식tune.run: 병렬처리 양식으로 학습 시행- 항상 함수형태로 저장해야 ray에서 사용할 수 있음

10 PyTorch Troubleshooting
강의 소개
PyTorch를 사용하면서 자주 발생할 수 있는 GPU에서의 Out Of Memory (OOM) 에러 상황들의 예시를 보고 해결하는 법까지 학습합니다. 프로그래밍 도중 디버깅하기 어려운 GPU 사용시 발생할 수 있는 문제들이 발생할 때 GPU 메모리 디버깅을 도와주는 툴과 초보자가 쉽게 놓칠 수 있는 사소한 실수들의 예제들을 확인합니다.
OOM
- 해결하기 어려운 이유
- 왜/어디서 발생했는지 알기 어려움
- Error backtracking이 이상한데로 감
- 메모리의 이전상황의 파악이 어려움
- 간단한 해결법
- Batch Size ↓
GPUUtil 사용하기
- nvidia-smi 처럼 GPU 상태를 보여주는 모듈
- colab은 환경에서 GPU 상태 보여주기 편함
- iter마다 메모리가 늘어나는지 확인!!
!pip install GPUtil import GPUtil GPUtil.showUtilization()

empty_cache()
torch.cuda.empty_cache()- 사용되지 않은 GPU상 cache를 정리
- 가용 메모리를 확보
- del과는 구분이 필요(del은 관계를 끊음 --> garbage collector 후 비워짐)
- reset 대신 쓰기 좋은 함수
- loop(학습) 시작 전 한번하는게 좋음
training loop에서 tensor로 축적되는 변수
- tensor로 처리된 변수는 GPU 상에 메모리 사용
- 해당 변수 loop 안의 연산에 있을 때 GPU에 computational graph를 생성(메모리 잠식)
>> 1-d tensor의 경우 python 기본 객체로 변환하여 처리
iter_loss-->iter_loss.itemorfloat(iter_loss)
>> del 명령어를 적절히 사용하기
del(i)
- 필요가 없어진 변수는 적절한 삭제가 필요함
- python의 메모리 배치 특성상 loop이 끝나도 메모리를 차지함
>> 가능 batch 사이즈 실험해보기
- 학습시 OOm이 발생했다면 batch 사이즈를 1로 해서 실험해보기
>> torch.no_grad() 사용하기
- inference 시점에서는 torch.no_grad() 사용
- backward pass로 인해 쌓이는 메모리에서 자유로움
>> 그외 에러(참고)
- CUDNN_STAUTS_NOT_INIT
- device-side-assert


인공지능 꿈나무