본 강의는 udemy의 Java Reactive Programming From Scratch를 듣고 알게 된 내용을 정리합니다.
- 전제 : 이 강의는 리액티브 프로그래밍을 하나도 다룰 줄 모르는 초심자가 듣는다는 것을 전제로 진행됩니다.
- 요구 사항 : Java 8+, Lambda나 함수형 스타일 (stream filter / map)에 대한 기본 지식
- 목표로 하는 것: Reactor / Reactive Programming에 대한 지식
- 목표로 하지 않는 것: Spring Webflux에 대한 지식
전통적인 쓰레드 / 요청 모델
데이터베이스에 어떤 수행하는 작업들 == 파일 IO 작업들
대부분의 어플리케이션은 이런 형태의 작업들을 주로 한다.
- 이 작업들은 처리하는데 시간이 오래 걸림
- 요청을 처리하는 쓰레드들은 그 시간 동안 wait 상태에 돌입, 다른 요청을 처리할 수 없음
그래도 모놀리식한 구조에서는 괜찮다.. 리소스를 좀 더 할당하면 되니까.
MSA에서의 쓰레드 / 요청 모델
서비스 A에서 서비스 B로 요청을 전달하고, 서비스 B에서 파일 IO 를 통해 필요한 정보를 얻고 쓰는 경우를 생각해보자.
이 경우 서비스 B 뿐만 아니라 서비스 A도 블락킹 상태가 된다. 즉 서비스에 대한 요청을 더 이상 수용할 수 없게 되는 것이다.
전통적인 서버 모델에서는 이러한 방식으로 서비스를 설계해왔었고, MSA 구조가 점점 커지고 복잡해짐에 따라서 이런 방식의 모델로는 리소스를 효율적으로 사용하는 것이 거의 불가능해졌다.
이벤트 드리븐 프로그래밍
간단한 Node.js 어플리케이션을 생각해보자.
아주 단순하게 말하면 이 어플리케이션에는 크게 3가지 모델이 존재한다.
- 요청에 대한 큐 (실제로는 이런 큐가 존재하지 않지만)
- 큐를 페치하는 이벤트 루프
- 실제 데이터가 저장되는 파일 시스템 (데이터베이스 등)
전통적인 쓰레드 요청 모델과 가장 큰 차이점은 요청에 대해 서버의 리소스들이 pending 상태로 존재하지 않는다는 것이다.
요청에 대한 응답이 올 때까지 이벤트 루프는 끊임없이 다른 요청에 대한 처리를 수행한다.
요청에 대한 응답이 온다면, 그제서야 이벤트 루프는 응답에 대한 후속처리 (콜백)를 수행한다.
콜백 지옥
상기 방식의 어플리케이션을 작성할 때에는 한 가지 문제가 있었는데..
- 사용자의 정보를 데이터베이스에서 가져와서,
- 사용자의 정보를 바탕으로 결제 정보를 불러와서,
- 불러온 결제 정보를 바탕으로 결제 상태나 배송 상태의 정보를 불러와서,
- ...
실제 어플리케이션을 설계 할 때에는 복잡한 비즈니스 로직을 구현해야 하기 때문에, 단순히 콜백 함수 하나에서 끝나는 것이 아니라 콜백 함수가 다른 콜백 함수를 불러 일으키고, 완료되면 또 콜백함수를 불러 일으키는 등의 체이닝을 계속해서 수행하게 된다.
이것을 콜백 지옥이라고 부르고, 유지 보수 불가능한 코드를 만든다.
IO 모델
실제로는 조합에 따라 조금 더 많은 IO 모델이 현실 세계에 존재하지만 간단하게만 살펴본다.
동기 + 블락킹
우리가 기본적으로 배우는 프로그래밍 방식이다.
요청에 대한 대부분의 시간이 블락된 상태로 존재하게 된다.
예시로는 콜센터에 전화를 걸어 어떤 요청을 하는 경우이다.
- 콜센터의 (실시간으로 응대를 할 수 있는) 인력은 한정적이다.
- 때문에 전화를 걸었을 때 (요청) 자동화된 기계음성으로 잠시만 기다려달라는 메시지를 듣는다.
- 실시간으로 응대를 할 수 있는 인력인 상담원분께서 busy 상태에서 벗어났을 때, 다음 상담 대상자가 있는지 찾는다.
- 내 차례가 되면 비로소 내 요청을 상담원분께 드릴 수 있다.
비동기
내가 처리할 일이 따로 있고, 내 요청에 대해 대신 처리할 부하 직원이 따로 있다고 생각해보자.
내가 부하 직원에게 이러 이러한 요청을 대신 좀 수행해줘~ 하면
- 부하 직원이 그 요청을 다 알아서 해준다.
- 나는 부하 직원이 내 요청을 알아서 해주는 동안 다른 작업을 수행한다.
- 부하 직원은 내 요청을 다 완료한 후에 나에게 다 되었다고 알려준다.
이러한 상황에서 나는 비동기이지만, 부하 직원은 동기 / 블락킹으로 요청을 수행한다.
논블락킹
똑같이 콜센터에 전화를 걸어 어떤 요청을 하는 경우를 생각해보자.
그런데 콜센터가 내 전화번호를 기억하게 되는 케이스인 것이다. (이 때 실제로는 OS 레벨의 로우 레벨 코딩이 좀 필요하다.)
이 경우에는 콜센터의 상담원분들이 남아 있는 요청을 처리할 때까지 내가 기다리는 것이 아니라,
- 나는 그 동안 다른 작업을 수행할 수 있다.
- 콜센터의 상담원분들이 남아 있는 요청을 다 처리하게 된다면 적혀 있는 번호로 연락을 준다.
- 나는 다른 작업을 수행하다가 연락이 오는 순간 필요한 사항에 대해 요청할 수 있다.
비동기 + 논블락킹
비동기와 논블락킹을 합친 것이다.
내가 부하 직원에게 콜센터에 전화를 걸어 어떤 요청을 수행해달라고 부탁하는 케이스인 것이다.
- 나는 부하 직원에게 요청 대리를 맡기고 다른 작업을 수행할 수 있다.
- 부하 직원은 콜센터에 전화를 걸고, 대기하지 않고 자신 (부하 직원)의 연락처를 남기고 다른 작업을 수행한다.
- 콜센터의 상담원분들이 남아 있는 요청을 수행하고 적혀 있는 번호로 연락을 준다.
- 부하 직원이 콜센터의 상담원분께 연락을 받고 (나에게 받은) 필요한 요청을 수행한다.
- 부하 직원이 나에게 콜센터에 대한 요청이 완료되었음을 알린다.
리액티브 프로그래밍은 이렇게 실제로 behind the scene에서 일어나는 많은 일들을 높은 수준의 추상화를 통해 쉽게 어플리케이션을 비동기 + 논블락킹으로 작성할 수 있도록 돕는 모델이다.
마이크로 서비스에서의 통신
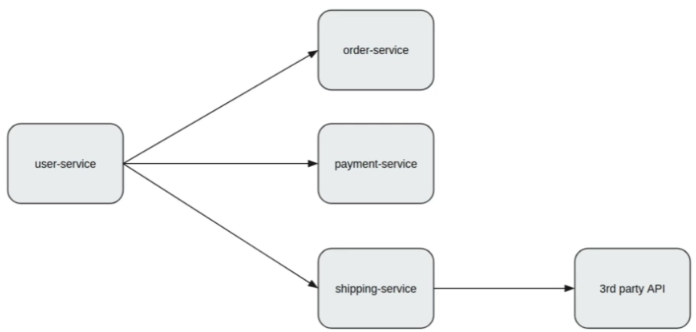
- user-service가 order-service에서 주문에 대한 id를 조회해 오고
- 주문에 대한 id를 기반으로 결제에 대한 정보를 payment-service로부터 조회해 와서
- 다시 shipping-service에게 현재 진행 중인 배송에 대한 정보를 요청하는 상황을 가정해보자.
사용자가 한 달 간의 모든 주문에 대한 배송 현황과 상태를 조회하는 대시보드를 만들어야 하는 요구상황이 주어졌을 때, 어떻게 구현할 것인가?
잘 구현된 MSA에서는 바로 payment-service에 사용자에 대한 결제 현황을 볼 수 없다.
도메인에 대한 책임을 분산시키는 것이 MSA의 목적이기 때문에, 정보를 조회할 수 있다면 잘못 설계된 MSA이다.
결국 이런 방식으로는 실제 원하는 정보를 얻기 위해서 소모되는 IO 비용이 너무 많아지게 된다.
모든 사용자가 이러한 대시보드를 원한다면..?
IO as a Service
좀전에 예시로 들었던 비동기 + 논블락킹에서의 '부하 직원이 콜센터에 전화를 대신 걸어 문제를 해결하는 모델'이 소문이 나서 이젠 나 뿐만이 아니라 많은 사람들이 부하 직원에게 콜센터 전화를 맡기는 상황이 생겼다.
- 나의 입장에서는 : 요청에 대한 처리를 위임하기 때문에 리소스를 조금 더 효율적으로 사용할 수 있게 되었다.
- 요청을 처리하는 부하 직원 입장에서는 : 많은 고객들을 보유하게 되었기 때문에 일이 끝나지 않게 된다.
부하 직원 입장에서는 끝나지 않는 요청의 연속을 연속적으로, 효율적으로 처리해야 했기 때문에 조금 더 복잡해졌다.
때문에 Netflix, Twitter에서는 이렇게 일하는 방식에 대한 표준을 세우는 것이 어떨까요? 라고 제안했고, 그렇게 해서 나온 표준이 바로 Reactive Streams이다.
옵저버 패턴
많은 사람들이 트위터를 사용한다.
굉장히 유명한 셀럽 A가 있다고 가정하자.
- 많은 사람들은 셀럽 A를 팔로우하고 있다.
- 다른 셀럽 B는 A만큼 유명하지는 않지만 A를 팔로우한다.
- 일반인 C씨는 셀럽 B만 팔로우한다.
A가 어떤 정보를 트윗으로 게시한다.
- B가 그 트윗에 대한 자신의 생각을 담아서 다시 트윗한다.
- B의 트윗은 C에게 전달된다. C가 그 트윗을 좋아요 한다.
이 모델에서 A의 트윗에 대한 B의 행동은 다시 A에게 전달되지 않는다.
마찬가지로 B의 트윗에 대한 C의 행동은 다시 B에게 전달되지 않는다.
이 모델에서 A는 가장 상위에 있는 발행자 (Publisher) 이다.
발행자를 구독하는 구독자 (Subscriber)는 변화를 관찰하고, 변화가 없을 경우에는 무시한다. (신경쓰지 않는다)
Reactive Streams Specification
옵저버 패턴은 리액티브 스트림 정의에서 아주 핵심적으로 사용된다.
객체 간 구독 관계에 대한 간단한 인터페이스를 선언함으로써, 수많은 종류의 관계를 정의할 수 있다.
예를 들어, 이전 예시에서 B는 셀럽 A를 팔로우하는 Subscriber였지만, 동시에 C에게는 관찰의 대상인 Publisher가 될 수 있었다.
마찬가지로 리액티브 스트림의
Processor<T, R>는Subscriber<T>가 될 수도 있고,Publisher<R>이 될 수도 있다.
Reactive Programming
이전까지 설명한 개념을 모두 이해했다면,
리액티브 프로그래밍은 사실 '데이터가 파이프라인 / 체인에 들어왔을 때 실행될 콜백들과 리스너에 대한 집합을 미리 선언하는' 비동기 프로그래밍의 부분집합이자 특정 케이스이다.
전통적인 선언적 스타일 프로그래밍에서는..
- 사용자의 정보를 데이터베이스에서 가져와서~
- 만약 사용자의 정보가 비어있지 않다면 (null check)
- 사용자의 id 값으로 다시 주문에 대한 정보를 가져와서~
- 만약 주문의 정보가 비어있지 않다면
- 새로운 트랜잭션을 생성해서 리스트에 추가하고~
- ...
이 일련의 과정이 너무 느려서, 2초 간의 타임 아웃 안에 실행해야 한다는 요구 사항이 생기면
- 2초 동안에 모든 과정이 일어나는지를 또 체크하고
- 만약 2초 안에 실행되지 않는다면 모든 변경 사항을 취소해야 한다.
계속 설명하지만 처리해야 할 데이터가 많고, 복잡해진다면 이게 쉽지 않다!
리액티브 프로그래밍에서는..
모든 작업을 스텝 단위로 쪼갤 수 있다.
- 다음 스텝은 이전 스텝의 결과를 바탕으로 실행된다.
- 기다리고 있는 것이 아니라는 점을 명심해야 한다.
- 모든 과정은 비동기 + 논블락킹으로 실행된다.
리액티브 프로그래밍의 3가지 기둥 개념 (Pillars)
- 비동기적인 데이터 처리
- 논블락킹
- 함수형, 선언형 스타일
구현체
리액티브 스트림은 표준 인터페이스를 정의한 것이기 때문에, 그 구현체에는 여러 종류가 있을 수 있다.
- Akka Streams
- rxJava2
- Reactor > 우리가 배울 것
Publisher / Subscriber 간 통신
Step 1 : Subscriber가 연결을 희망
Subscriber, Publisher 두 인스턴스가 있다고 가정해보자.
이 단계에서는 Subscriber는 Publisher로부터 업데이트를 받기 원하기 때문에 subscribe() 를 통해서 구독 관계를 형성하고 싶다는 요청(request)을 Publisher에게 알린다.
Step 2 : Publisher가 onSubscribe를 호출
이 단계에서는 Publisher가 Subscriber의 구독 요청을 수락하고 구독 객체의 존재를 Subscriber에게 전달한다.
구독을 해지하고 싶을 때에도 구독 해지를 요청하는 쪽은 Subscriber이다. (구독 해지를 요청할 때에도 Subscriber가 Publisher에게 요청하는 식으로 이루어진다)
Step 3 : Subscription
Publisher와 Subscriber의 '구독 관계'는 Step 2가 끝난 시점에 구독 객체를 통해 이루어진다.
Subscriber가 구독 해지를 원하는 경우, 이 구독 객체의 cancel() 을 통해 구독 해지가 이루어진다.
Step 4 : Publisher가 데이터를 onNext로 발행
Subscriber가 Publisher에게 어떤 데이터를 받기를 원한다는 것을 구독 객체의 생성으로 약속해두었기 때문에, Publisher 가 어떤 데이터를 발행할 때 Publisher는 onNext()로 데이터를 Subscriber에게 전달한다.
만약 5개의 데이터를 전달해야 한다면, onNext()는 5번 호출된다.
이 때 발행할 데이터가 없을 때에는 onNext는 호출되지 않는다. (바로 onComplete를 호출한다)
Step 5-1: onComplete 호출
Publisher가 더 이상 발행할 아이템이 없을 때, 혹은 이미 Subscriber에게 데이터를 이미 전부 전달했을 때 Publisher는 onComplete()를 호출해서 Subscriber에게 작업이 다 끝났다는 것을 알린다.
이 이후에는 Publisher는 어떠한 데이터도 Subscriber에게 전달하지 않는다.
Step 5-2: onError 호출
Publisher가 데이터를 Subscriber에게 전달하던 도중 예상하지 못한 어떤 것이나 문제를 만났다면 onError()를 호출해 에러에 대한 정보를 Subscriber에게 전달한다.
이 이후에는 Publisher는 어떠한 데이터도 Subscriber에게 전달하지 않는다.
Publisher / Subscriber 용어 정리
| Publisher | Subscriber |
|---|---|
| Source | sink |
| Observable | Observer |
| Upstream | Downstream |
| Producer | Consumer |

👍