
평소와 같이 medium을 탐방하던 중 재미있는 내용이 있어 공유해보고자 한다.
그동안 아무 생각 없이 레디스를 사용해왔었기 때문에 정작 나는 왜 레디스가 빠른지에 대해서는 별 다른 궁금증을 가지지 못했던 것 같다.
레디스는 어떻게 이렇게 빠르고, 어떻게 커넥션들을 관리할까?
레디스의 특별한 자료구조
B Tree는 (데이터베이스 인덱스 구조 등에서) 흔하게 사용되는 자료구조이다.
그런데 B Tree는 여러 단점을 가지고 있다.
- B Tree는 복잡하다.
- 리밸런싱의 비용이 높다.
- 멀티 프로세싱 (또는 쓰레딩) 환경에서는 B Tree를 다루기 더 복잡해진다.
Skip List는 B Tree보다 동시성 문제를 더 잘 해결할 수 있는 자료구조이다.
Skip List의 특징
- 키들이 정렬되어 있다.
O(log n)수준 복잡도를 가진다.- 각각의 상위 레벨은 하위 레벨보다 절반 개수의 원소를 가진다.
Skip List의 장점으로는 속도가 있다.
- 모든 연산 (검색, 삭제, 삽입)에 대해서
O(log N)복잡도가 보장된다. - B Tree의 밸런싱 비용에 비해 보다 구현하기 쉽고 조금 덜 소모적이다. (링크 재조정이 이뤄지는 횟수가 더 적기 때문이다)
- B Tree에 비교하여 병렬 처리가 좀 더 용이하다.
단점으로는 메모리 사용량이 있다.
- 각각의 레벨에 대해서 보다 많은 수의 링크를 필요로 하기 때문에,
N * (N+1) / 2만큼의 공간이 추가적으로 필요하다.
레디스는 어떤 최적화된 자료구조를 사용하는가
레디스의 Sorted Set은 Skip List를 사용한다.
또한 레디스는 LRU를 곁들인 Double List를 활용하여 캐시로써의 기능을 효율적으로 수행할 수 있었다.
https://mecha-mind.medium.com/redis-sorted-sets-and-skip-lists-4f849d188a33
레디스가 Sorted Set을 구현하기 위해서 우선순위 큐를 사용하지 않는 점이 매우 독특했다. 우선순위 큐는 실제로 많은 시나리오에서 널리 사용되고 있기 떄문인데, 우선순위 큐의 장점은 아래와 같다.
- 최댓값과 최솟값의
get연산에 대해 매우 빠르다.- Minimum priority queue의 경우에 최솟값을 획득하는 비용은
O(1)이다. 반대로 Maximum priority queue의 경우 최댓값을 획득하는 비용 또한O(1)이다. - 하지만 동일한 우선순위 큐에서 최솟값과 최댓값을 획득하는 비용이 모두
O(1)일 수는 없다.
- Minimum priority queue의 경우에 최솟값을 획득하는 비용은
- 최솟값 / 최댓값을 제거하는 비용은
O(logN)이다.- 마찬가지로 동일한 우선순위 큐에서 최댓값과 최솟값을 제거하는 비용이 모두
O(logN)일 수는 없다.
- 마찬가지로 동일한 우선순위 큐에서 최댓값과 최솟값을 제거하는 비용이 모두
- 우선순위 큐에 새로운 원소를 삽입하는 비용은
O(logN)이다. 기존 원소를 삭제하는 비용은O(logN)이다. - 존재하는 인덱스나 키를 업데이트하는 비용 또한,
O(logN)이다.
이 글에서 우선순위 큐에 대해 자세하게 다룰 것은 아니기 때문에, 우선순위 큐가 어떻게 동작하는지 궁금한 분들은 이 글을 참고하는 것이 좋을 것 같다.
레디스는 그럼 왜 정렬된 집합인 Sorted Set을 구현할 때 Skip List을 사용할까?
Skip List를 사용하는 이유는 링크드 리스트에 대한 검색 시간을 최적화하기 위해서이다.
정렬된 배열과 정렬된 링크드 리스트의 차이가 뭘까?
- 정렬된 배열에서 특정 원소를 검색하는 비용은
O(logN)이 소요된다 (이진 탐색) - 하지만 정렬된 링크드 리스트에서 원소를 검색하는 비용은
O(logN)이 될 수가 없다. - 정렬된 링크드 리스트에서는 반드시 포인터를 통해서 다음 노드를 탐색해야 하기 때문이다.
Skip List에서는 여러 레벨의, 정렬된 리스트가 존재한다.
그리고 기본적으로 각각의 노드는 다수의 '이전 또는 다음 노드로 가는 포인터들'이 존재할 수 있다.
Skip List에 존재하는 각각의 노드들은 랜덤한 레벨 L을 할당 받는데, Skip list의 레벨 i에 대해서 레벨이 i 이상인 노드들 사이에는 다음 노드로 이동할 수 있는 포인터가 존재한다.
- Skip list에 저장되는 값들은 저장되어 있다.
- 각각의 노드들은 서로 다른 레벨을 가진다.
- 가령 값 6을 가지는 노드가 포인터 4개를 가진다면 '4 레벨에 있다' 고 표현할 수 있다.
- 값 6을 가지는 노드가 서로 다른 레벨 4개에 대한 포인터를 가지고 있기 때문이다.
헤드 노드는 모든 레벨에 대한 포인터를 가지고 있기 때문에 할당 가능한 최대 레벨을 가진다.
그리고 이 레벨들은 확률적으로 할당된다. 가장 흔한 시나리오에서 레벨 i를 가지는 노드가 레벨 i+1로 승급될 확률은 50%이다.
즉 1~4까지의 레벨을 가지는 위와 같은 시스템에서,
- 노드가 레벨 1에 할당될 확률은 100%이다.
- 노드가 레벨 2에 할당될 확률은 50%이다.
- 노드가 레벨 3에 할당될 확률은 25%이다.
- 노드가 레벨 4에 할당될 확률은 12.5%이다.
이러한 구조를 가지는 시스템에서 동작하는 검색 알고리즘이 가질 수 있는 장점은: 단일 레벨 링크드 리스트에서 전체 노드를 전부 순회해야 했던 것과는 달리 노드들은 스킵할 수 있다.
때문의 레디스의 Sorted Set은 다음과 같은 이점을 가질 수 있었다.
1. 단순히 최솟값과 최댓값을 획득하거나, min-pop이나 max-pop과 같은 연산을 지원할 수 있다. (힙과 같은 자료구조에서는 최소 힙과 최대 힙을 따로 저장했어야 했던 것과는 대조적이다)
2. 데이터의 특정 시각 스냅샷을 필요로 하는 스트리밍 데이터 분석에 매우 유용하다.
1. 수들의 Stream에 대한 중간값을 계산하거나, 값 x보다 작은 수의 개수를 구하는 등의 연산이 예시이다.
3. 정렬된 리스트 자체를 획득하는 비용을 O(N)에 수행할 수 있다. (우선순위 큐에서는 O(NlogN) 비용이 소모된다)
이외에도..
- 레디스의
Strings자료구조는 Simple Dynamic String을 사용한다. - 레디스의
List자료구조는 링크드 리스트와 Zip List를 사용한다. - 레디스의
Hashed자료구조는 Zip List와 해시 테이블을 사용한다. - 레디스의
Set자료구조는 해시 테이블과 정수 집합을 사용한다. - 레디스의
Sorted Set자료구조는 지금까지 설명했던 Skip List 이외에도, Zip List도 사용한다.
다시 말해 - 각 연산을 최적화된 자료구조로 구현한다는 점이 레디스의 연산을 효율적으로 만들 수 있었다.
레디스는 어떻게 커넥션을 관리하는가
레디스는 소켓 기반 서버이기 때문에, 들어오는 요청에 대해서 listen 하고 있다가 커넥션을 생성한다.
그럼 동시다발적인 10000개의 커넥션이 요청되면 어떻게 될까? 레디스는 10000개의 쓰레드를 핸들링할까? (10000개의 쓰레드를 핸들링 하는 일은 거의 불가능하다)
레디스는 요청이 들어올 때마다 커넥션을 생성하지 않는다. 레디스의 I/O 모델에 대해 좀 더 알아보자.
레디스의 I/O 모델
우리가 레디스에 대해 논의할 떄는 흔히 어떤 데이터가 캐시될 것인지에 대해 고민한다.
그보다 중점을 두고 살펴볼 것은 (비단 레디스 뿐만 아니라 많은 모던 시스템에서 차용하는) I/O 멀티플렉싱이다.
그리고 이는 레디스를 빠르게 만드는 또 하나의 요인이다.
레디스는 싱글 쓰레드 어플리케이션임에도 이전 주제에서 남겼던 c10k 문제를 효율적으로 풀었다. 바로 epoll 모델을 사용했기 때문이다.
전통적인, 블락킹 I/O 모델
학부 때 과제로 주어졌었던, 아주 간단한 소켓 서버를 작성하기 위해서는 아래와 같은 방법을 사용할 수 있다.
- 포트를 열어놓고 요청에 대한 새로운 커넥션이 맺어지기를 기다린다.
- 새로운 커넥션이 생성되면, 요청한 작업을 수행한다.
- 작업을 완료한다면 커넥션을 종료한다.
- 이후에 새로운 커넥션에 대해 맺어지기를 기다린다.
이 모델은 아주 전통적인 블락킹 I/O 모델이고, 학부 과제 수준에서 네트워크 지식을 이해하기 위해 아직도 가끔 거론되는 모델이다.
하지만 이 모델은 절대로 운영 환경에서 사용할 수 없다. 다수의 커넥션을 요청하게 되는 순간 큐잉이 발생하기 때문이다.
그렇다면 이 모델의 멀티 쓰레드 버전은 상황이 좀 나아질까?
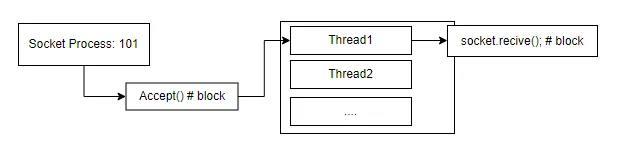
위 모델에서 각각의 포트는 프로세스이고, 새로운 커넥션이 맺어진다는 것은 새 쓰레드가 생성된다는 것을 의미한다.
위 모델을 가지는 어플리케이션 또한 c10k 문제에 직면하게 될 것이다. 너무 많은 커넥션을 핸들링하기 이전에 리소스가 다 고갈될 것이기 때문이다.
때문에 c10k 문제를 해결하기 위해서는 새로운 쓰레드나 프로세스를 생성하지 않고 더 많은 커넥션들에 대해 listen하고 handle할 수 있어야 한다.
select 모델
select는 논블락킹 I/O 모델이다. 하지만 그렇게 효율적이지는 않다.
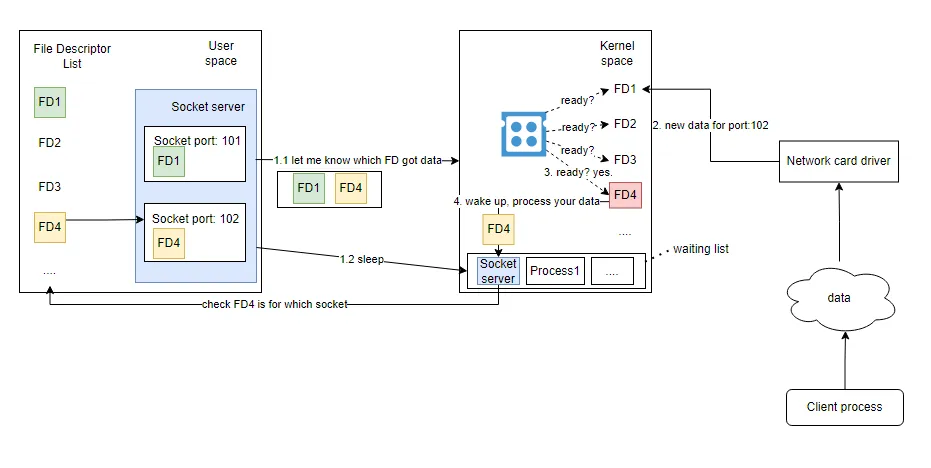
- 소켓 서버가 시작된다면, 커널로 파일 디스크립터의 목록 복사본을 보낸다.
- "그리고 이 소켓들에 새 데이터가 들어오면 날 깨워줘" 하고 잠에 든다.
- 새로운 데이터가 들어오게 되면, 네트워크 하드웨어가 CPU 인터럽션을 트리거해서 데이터가 저장되었음을 알려준다.
- 그리고 CPU가 유휴 상태에 빠진 프로세스를 깨운다. "일어나! 여기 네가 보내 준 파일 디스크립터 목록이 있으니까 누가 널 필요로 하는지 한번 찾아봐~"
- 프로세스가 깨어난 이후에는 어떤 소켓이 해당 파일 디스크립터에 해당하는지 탐색한다. (
O(N)소요)
때문에 블락킹 I/O에 멀티쓰레딩을 적용했던 모델과는 달리 select 모델은 c10k 문제를 해결할 수 있었다.
다수의 소켓 포트는 단일 프로세스에 의해 핸들링 될 수 있었기 때문에 새 커넥션이 생성될 때마다 새 쓰레드를 열지 않아도 되었기 때문이다.
그렇다면 왜 select 모델은 모던 어플리케이션에서 잘 쓰이지 않을까?
select 모델의 단점
- 파일 디스크립터 목록을 복사해서 유저 스페이스와 커널 스페이스 간에 이를 전달하는 것은 아주 많은 비용을 필요로 한다. (즉 속도가 빠를 수 없다)
- 커널이 유저 프로세스에게 새로운 데이터가 도달했음을 알려줄 때, 어떤 소켓 포트에 데이터가 인입되었는지를 알려줄 수 없다는 단점도 존재한다. 즉 사용자 프로세스가 올바른 소켓 포트와 프로세스를 찾기 위해서
O(N)탐색을 수행해야 한다. select자체에는 1024개의 제한이 걸려있다. 즉 select 모델을 사용하는 어플리케이션이 핸들링할 수 있는 최대 커넥션 개수는 1024개 된다.- 이는 파일 디스크립터 목록이 비트 마스크를 사용하기 때문이고, 1024로 고정되어 있는
__FD_SETSIZE에 영향을 받는다.
- 이는 파일 디스크립터 목록이 비트 마스크를 사용하기 때문이고, 1024로 고정되어 있는
poll 모델
우리가 잘 알고 있는 모델에는 poll 모델이 있다. 그리고 이 모델은 select 모델과 거의 유사하기 때문에 c10k 문제를 풀 수 있었다.
하지만 여전히 아래와 같은 단점이 존재했다.
- 1024개의 커넥션 제한이 여전히 존재한다.
- poll 모델에서 파일 디스크립터 목록을 관리하는 것은 select 모델보다 더 비쌌다.
- select 모델이 비트 마스킹을 사용하기 떄문에 더 적은 데이터를 다뤘기 때문이다.
때문에 poll 모델은 select 모델과 비교해서 딱히 그렇다고 말할 수 있는 진보를 낳지는 못했다.
epoll 모델
리눅스의 epoll 모델은 이런 프로세스를 더 효율적으로 만들어준다. 그리고 레디스는 이 epoll 모델을 사용한다.
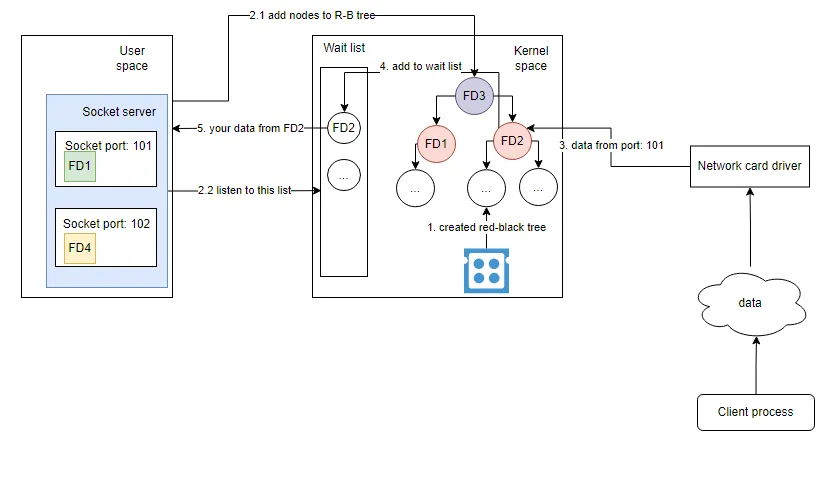
- OS는 Epoll Red Black Tree와 waitlist 큐를 생성한다. 두 개의 자료구조는 모두 커널 스페이스에 저장된다. (때문에 select 모델에서 유저 스페이스 - 커널 스페이스 간 필요했던 데이터 복사가 불필요하다)
- 유저 프로세스는 하나 이상의 소켓 파일 디스크립터를 epoll API를 호출해서 RB 트리에 저장한다.
- 이후 유저 프로세스는 waitlist 큐에 listen을 시작하여 새 데이터가 인입되는 것을 주시한다.
- 네트워크 드라이버로부터 새 데이터가 인입되면, OS는 소켓 포트에 기반하여 파일 디스크립터를 찾고 파일 디스크립터를 waitlist 큐에 삽입한다.
- 유저 프로세스는 waitlist 큐로부터 파일 디스크립터와 인입된 데이터를 획득한다.
select I/O 모델과 비교하여서 epoll 모델이 가지는 3가지 주요한 포인트는 아래와 같다.
- 더 이상 유저 스페이스와 커널 스페이스 간 데이터 복사가 이뤄지지 않는다.
- 커널에서 폴링이 더 이상 필요하지 않게 된다.
- 파일 디스크립터 리스트 대신 커널은 waitlist를 관리하여 활성화된 커넥션을 RB 트리에서 꺼내어 저장할 수 있다.
- RB 트리 자료구조를 사용함으로써 모든 연산을
O(logN)안에 수행할 수 있다. (삽입, 삭제, 검색)
epoll의 두 가지 모델
epoll에는 Edge-Triggered와 Level-Triggered 모델이 존재한다.
- Edge-triggered 모델을 사용할 때에는 프로그램은 데이터를 처리할 단 하나의 기회만 가지게 된다.
- Level-triggered 모델을 사용할 때(default)에는 OS가 데이터가 처리될 때까지 프로그램에게 계속 노티를 준다.
- 즉 프로세스가 콜백이 단 한번만 필요하다는 것이 보장된다면 OS의 부하를 줄이고 리소스를 더 효율적으로 사용할 수 있게 된다.
그리고 레디스는 Edge-Triggered 모드를 사용하는 epoll 모델을 사용한다.
여러 유명한 캐시들, 예를 들어 Memcached 또한 epoll 모델을 사용한다.
Nginx, Cassandra, Kafka 모두 epoll 모델을 사용한다.
싱글 쓰레드, 리액터 모델
레디스는 왜 멀티 쓰레드 기반으로 동작하는 이점을 포기하고 대신 싱글 쓰레드 기반으로 작성되었을까?
멀티 쓰레드 어플리케이션에 비해 싱글 쓰레드 어플리케이션이 가지는 이점은 아래와 같다.
- 쓰레드 생성과 회수에 소모되는 CPU 사용량을 최소화할 수 있다.
- 쓰레드 간 컨텍스트 스위팅에 소모되는 CPU 사용량을 최소화할 수 있다.
- 멀티 쓰레드 어플리케이션이 락이나 쓰레드 동기화와 같은 버그에 취약한 방어 로직이 필요한 반면 싱글 쓰레드 어플리케이션은 락에 대한 오버헤드가 없다.
- 많은 시스템에서 쓰레드 세이프하지 않은
lpush와 같은 여러 연산을 지원할 수 있다.
실제로 레디스를 사용하면서 가장 편했던 점은 쓰레드 세이프한 연산의 성능 문제에 대해서 깊게 생각할 필요가 없이 그저 연산을 사용하면 된다는 점이었다.
인 메모리 스토리지
그리고 레디스는 다른 무엇보다도 인 메모리 스토리지이다.
학부 운영 체제 시간에 배우듯이, 메모리 접근에는 계층 구조가 존재한다.
그리고 랜덤 디스크에 행해지는 I/O보다는 RAM에 대한 데이터 접근 속도가 훨씬 빠르다.
순수하게 메모리에 접근하는 방식은 높은 읽기 / 쓰기 성능을 보장하기에 낮은 latency를 가져다 줄 수 있다는 이점이 있다.
하지만 그에 대한 트레이드 오프로 데이터 셋의 크기 자체가 메모리 보다 커질 수 없다는 단점을 안고 있다.
하지만 인 메모리 자료구조는 디스크의 자료구조들보다 훨씬 구현하기 쉽기 때문에 코드가 간결해질 수 있었고, 결과적으로 안정성에도 어느정도를 기여를 할 수 있었다.
그렇다면 레디스는 큰 데이터를 저장하기 위해서 가상 메모리를 사용할까? 그렇지 않다는 것이다.
레디스는 메모리보다 큰 크기의 데이터 셋들을 저장할 수 없다. 저장되는 데이터의 크기를 포기한 대신 빠른 성능을 보장해준다고 생각하면 될 것 같다.
https://redis.io/docs/getting-started/faq/
레디스 FAQ에 따르면, 64비트 인스턴스가 각각의 rough한 상황에 차지하는 메모리 사용량은 아래와 같다.
- 빈 인스턴스는 최대 3MB의 메모리를 사용한다.
- 백만 개의 작은 키를 가지는 인스턴스는: 문자열 값 쌍들을 사용하고, 최대 85MB의 메모리를 사용한다.
- 백만 개의 키를 가지는 인스턴스는: 해시 값을 사용하여 5개의 필드를 가진 객체를 나타내고, 최대 160MB의 메모리를 사용한다.
레디스의 이론 상 수용 가능한 최대 키 개수는 2^32개로, 인스턴스마다 최소 2억 5천만개의 키들을 처리하도록 테스트되었다. 당연하게도 시스템의 하드웨어 메모리가 먼저 한계를 맞이하기 때문에 시스템의 메모리에 맞춰서 사용하면 된다.
레디스는 물론 시스템 하드웨어의 메모리를 전부 소모하지 않게 하기 위한 방어 로직도 가진다. maxmemory 옵션으로 대표되는 설정이 그 예시이다.
이 제한값에 도달하게 되면 레디스는 모든 쓰기 연산에 대해 에러를 응답한다. 반면 읽기 전용 연산들은 여전히 잘 수행할 수 있다.
레디스는 또한 최대 메모리 제한에 도달하게 되었을 떄 키를 evict하는 전략도 사용한다.
요약
-
레디스는 Skip List, Zip List와 같은 자료구조를 사용하여 대한 레디스가 지원하는 특정 연산에 대한 효율성을 높일 수 있었다.
-
또한 레디스가 사용하는 epoll I/O 모델 덕분에 인입되는 각각의 요청에 대해 쓰레드를 생성하는 소모적인 작업 없이 요청을 처리할 수 있었다. (여러 시스템이 epoll 모델을 사용하지만, epoll 모델을 사용한다고 시스템이 싱글 쓰레드 기반일 필요는 없다)
-
레디스는 싱글 쓰레드 기반의 리액터 패턴을 사용한 시스템이다. 모든 연산들은 비동기 논블락킹으로 쓰레드 세이프하게 실행된다.
-
레디스는 인 메모리 데이터베이스로, 데이터 스토리지가 가지는 계층 구조 덕분에 더 빠른 읽기 / 쓰기 성능을 가질 수 있었다.

4개의 댓글

레디스의 이론 상 수용 가능한 최대 키 개수는 2^32개로, 인스턴스마다 최소 2억 5천만개의 키들을 수용할 수 있다.
표현을 조금 수정하는게 나을 것 같습니다. (ref) 글은 잘 읽었습니다.

저도 레디스를 사용할때 인메모리 싱글쓰레드라 빠르고 편해서 좋다! 라는 생각만하고
정작 어떻게 돌아가는지는 몰랐었는데 이 글을 통해 동작원리를 어느정도 알게 되었습니다.
좋은 글 감사합니다!