📕 오늘의 목표
오늘은 Java에서 Selenium을 사용해서
동적 크롤링을 도전해보겠습니다.
※ 환경설정 까다로움 주의
(하나하나 천천히 따라해주세요^^)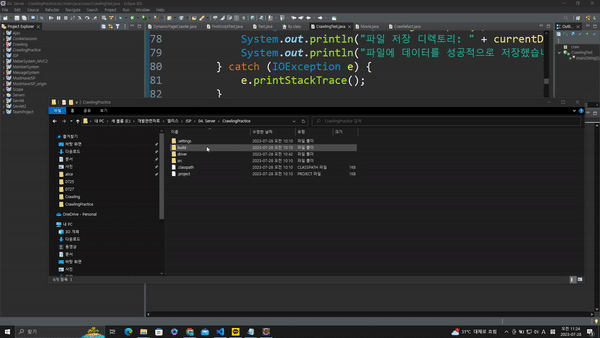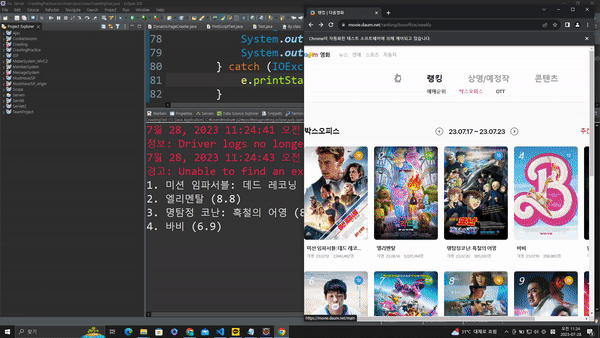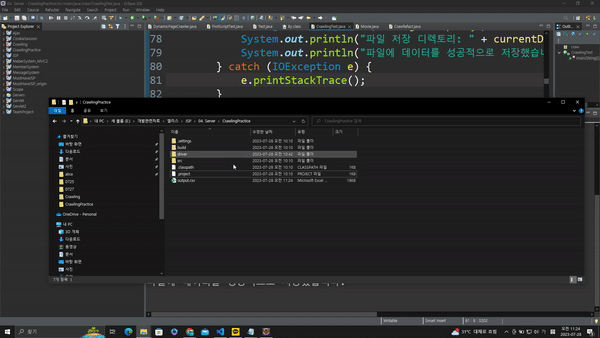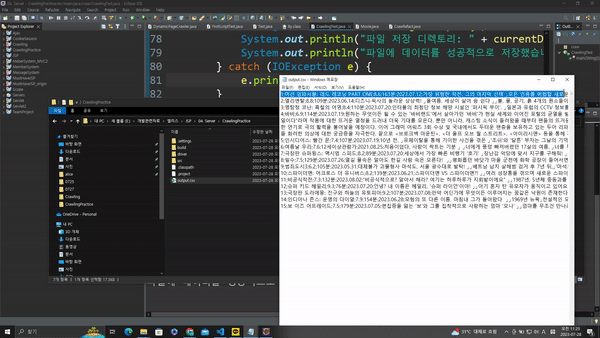
📕 개발환경
- 운영체제 : Windows 10
- IDE : Ecipse IDE for Enterprise Java and Web Develpoers (2023-03)
- 브라우저 : 크롬(Chorme) 115.0.5790.110 (64bit)
- 자바 버전 : JavaSE-17📕 본문
✏️ 1. 프로젝트 생성
0. Eclipse 실행
1. Project Exploler 빈 칸 우클릭
2. New -> Dynamic Web Project 클릭
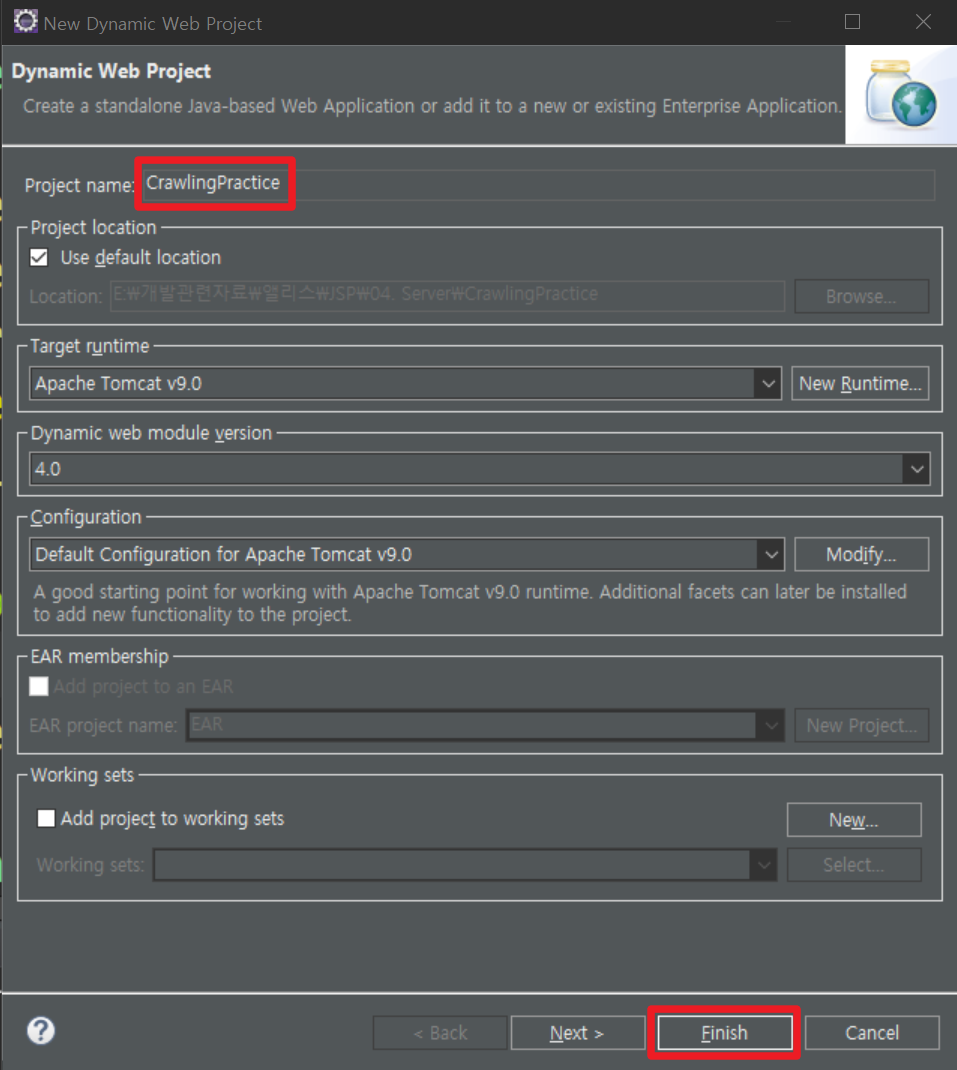
3. 환경 설정 후 Finish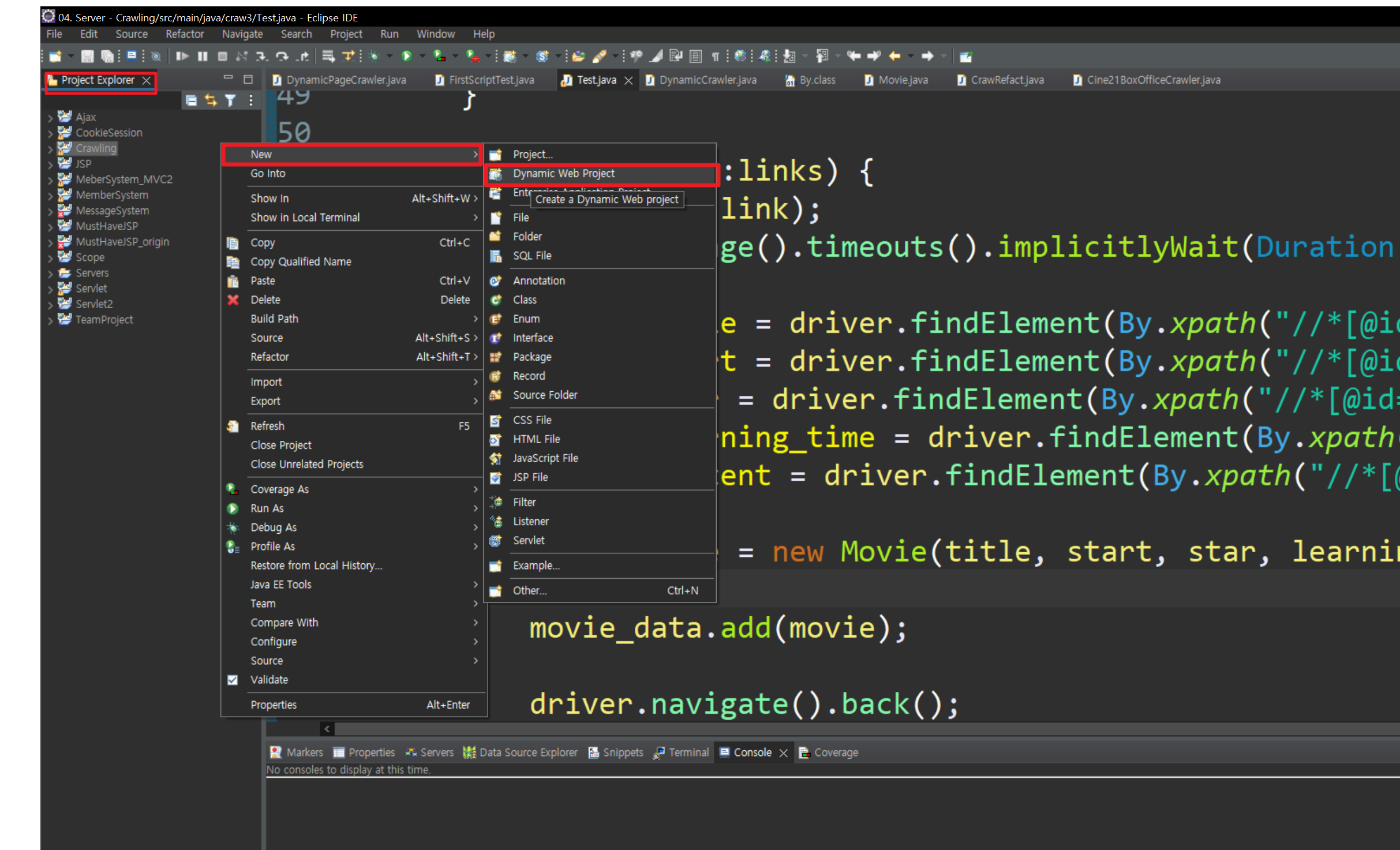
✏️ 2. Selenium과 ChromeDriver 다운로드
<Selenium Download>
1. https://www.selenium.dev/downloads/ 접속
2. Downloads -> Selenium Server(Grid) -> 4.10.0 클릭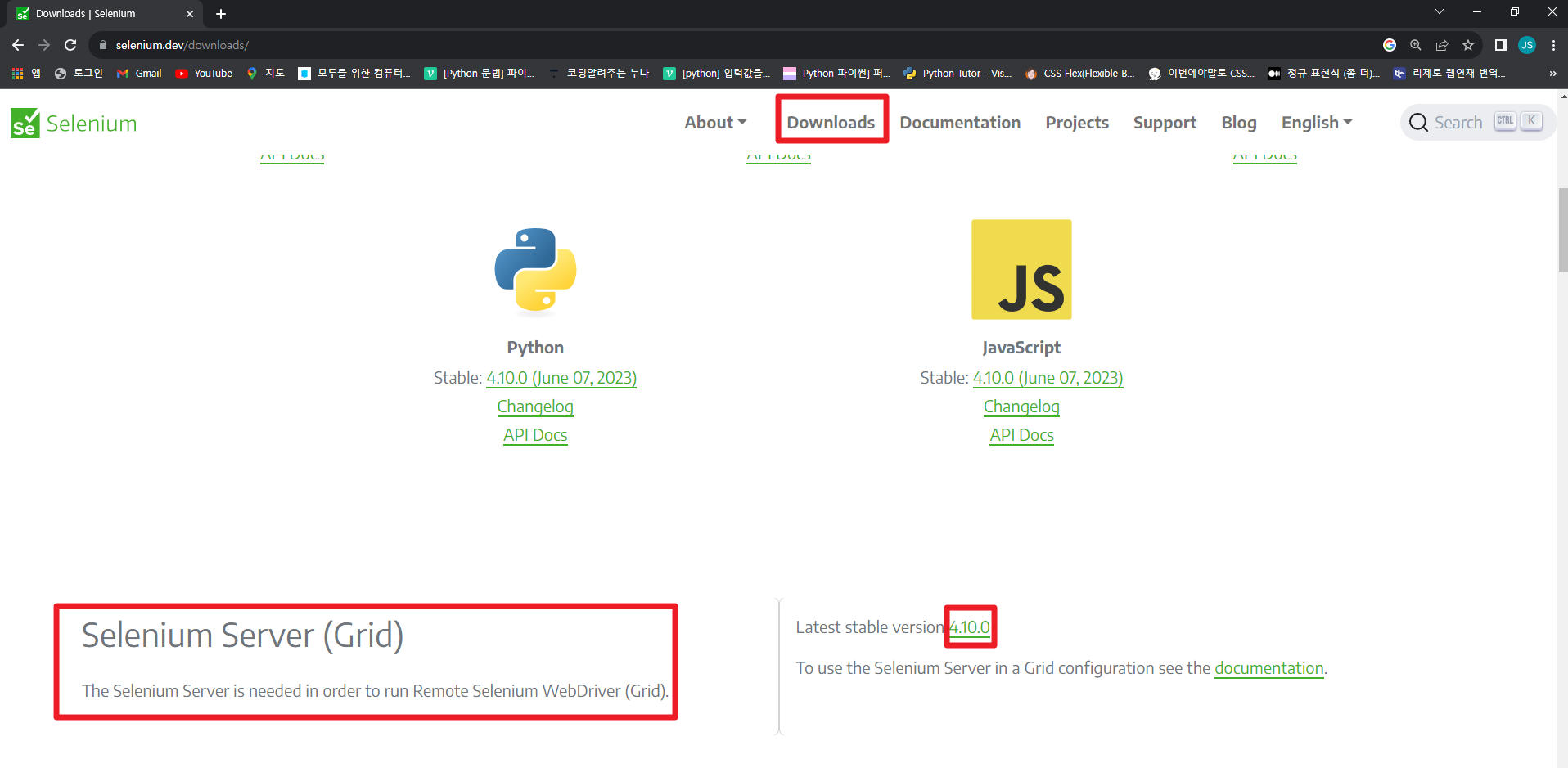
<Chromdriver Download>
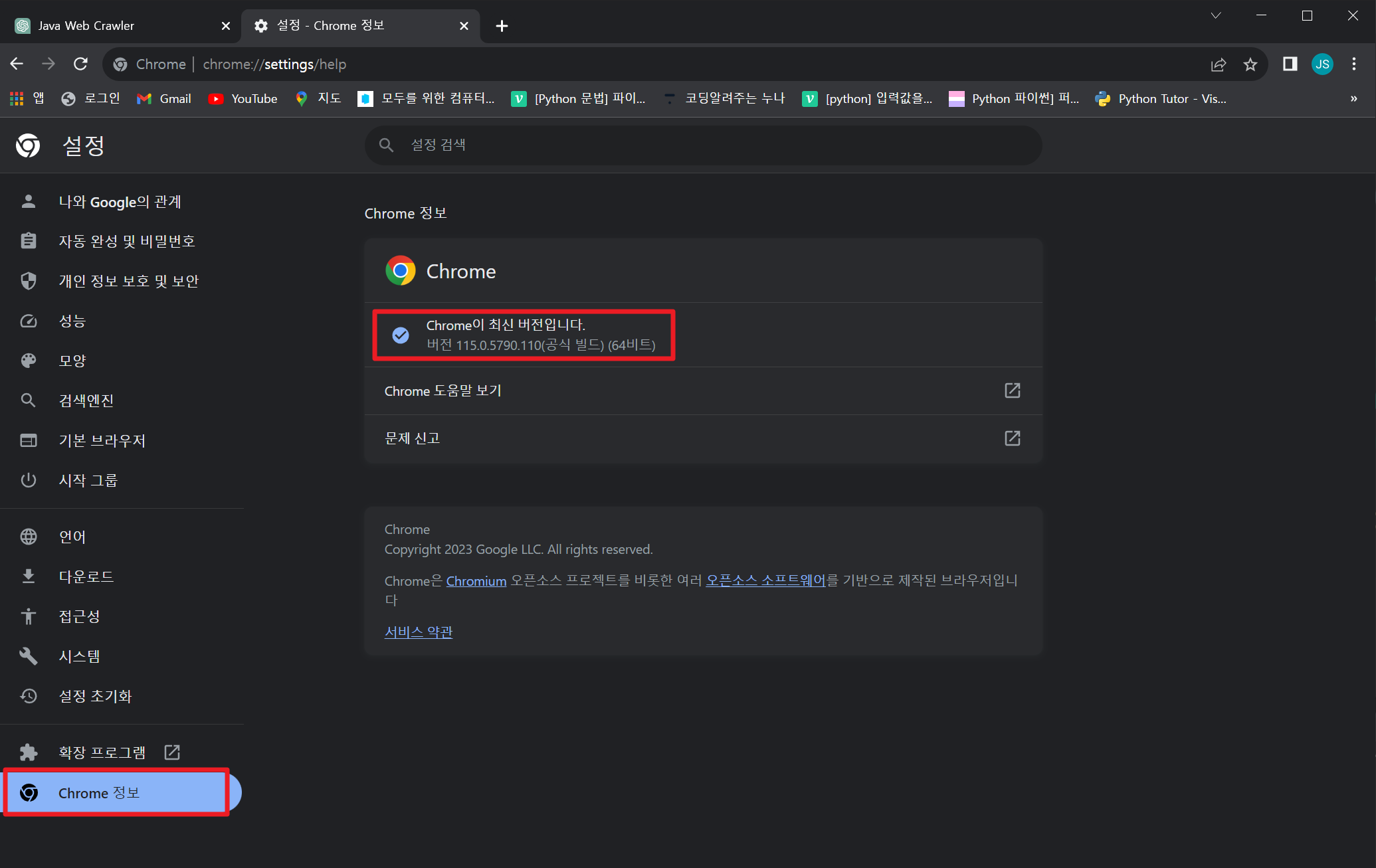
1. 자신의 크롬브라우저 버전 체크
(크롬브라우저 열기 -> 점 3개 클릭 -> 설정 -> Chrome 정보)
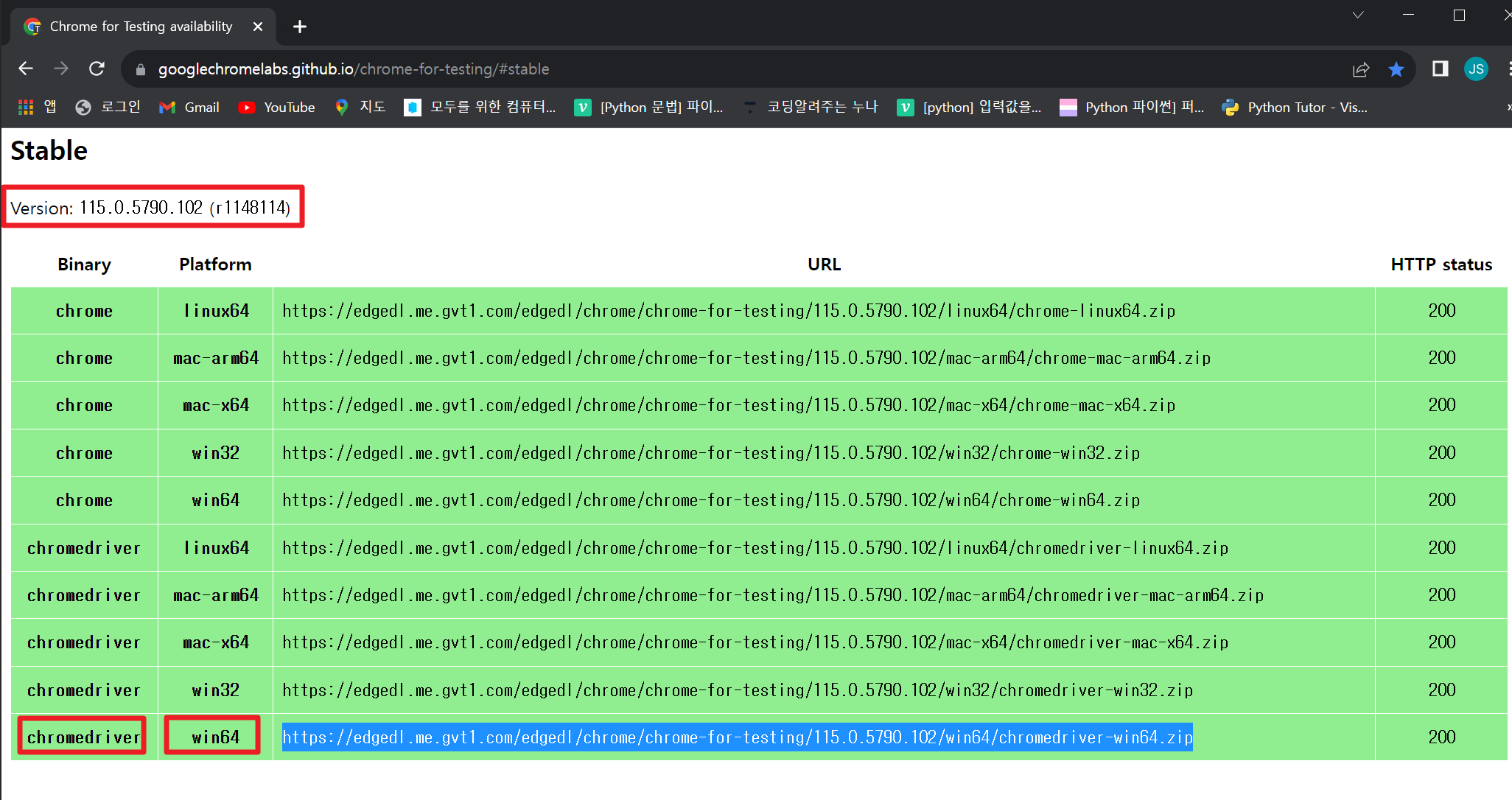
2. https://chromedriver.chromium.org/downloads 접속
3. 자신의 크롬브라우저 버전에 맞는 chromedirever 다운
(저는 115버전, 윈도우, 64bit)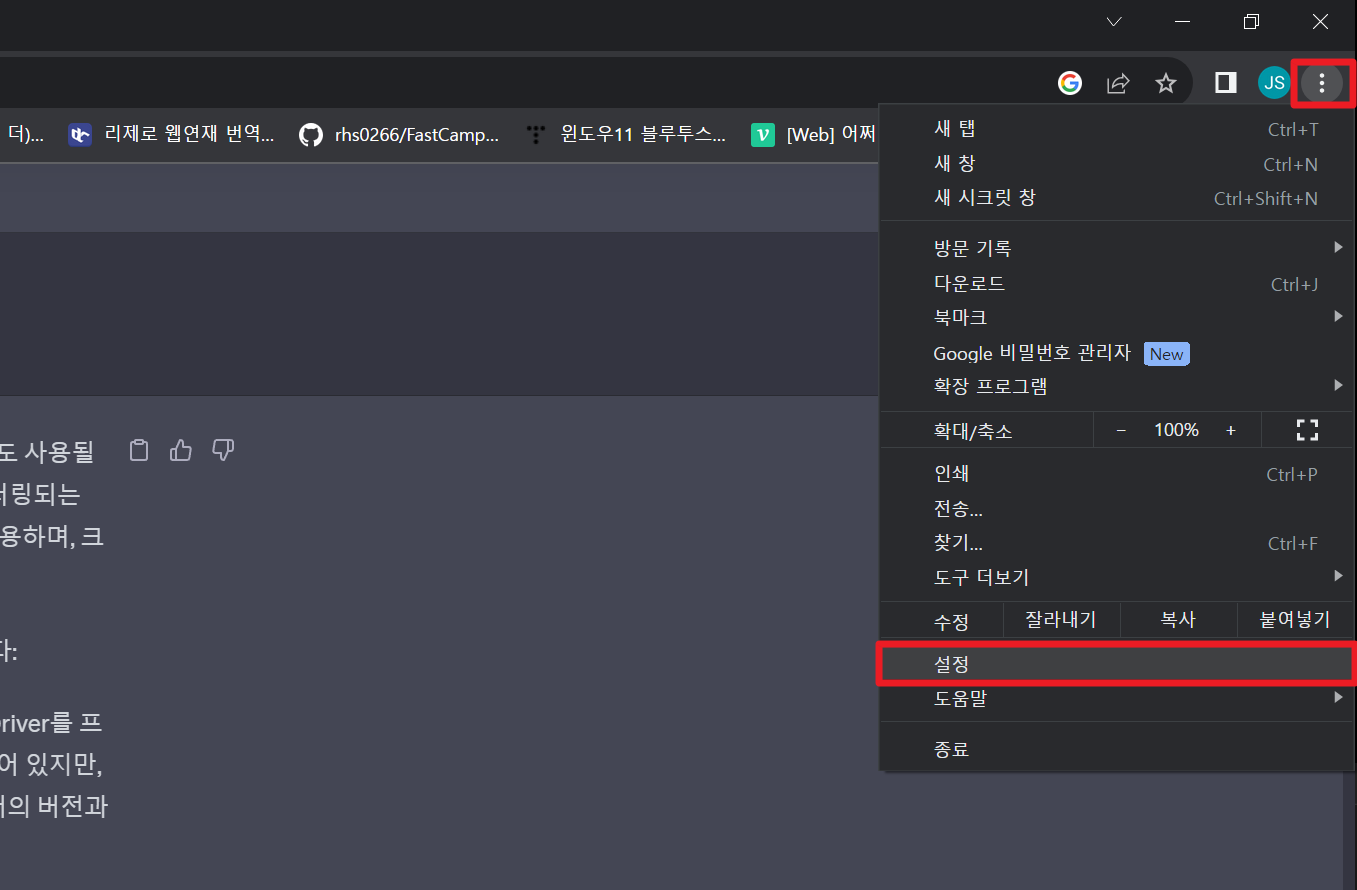
✏️ 3. Java 프로젝트에 Selenium 라이브러리 추가
1. selenium-server-4.10.0.jar (2.에서 다운 받은) 파일 복사
2. 프로젝트 폴더의 src/main/webapp/WEB-INF/lib 위치에 붙여넣기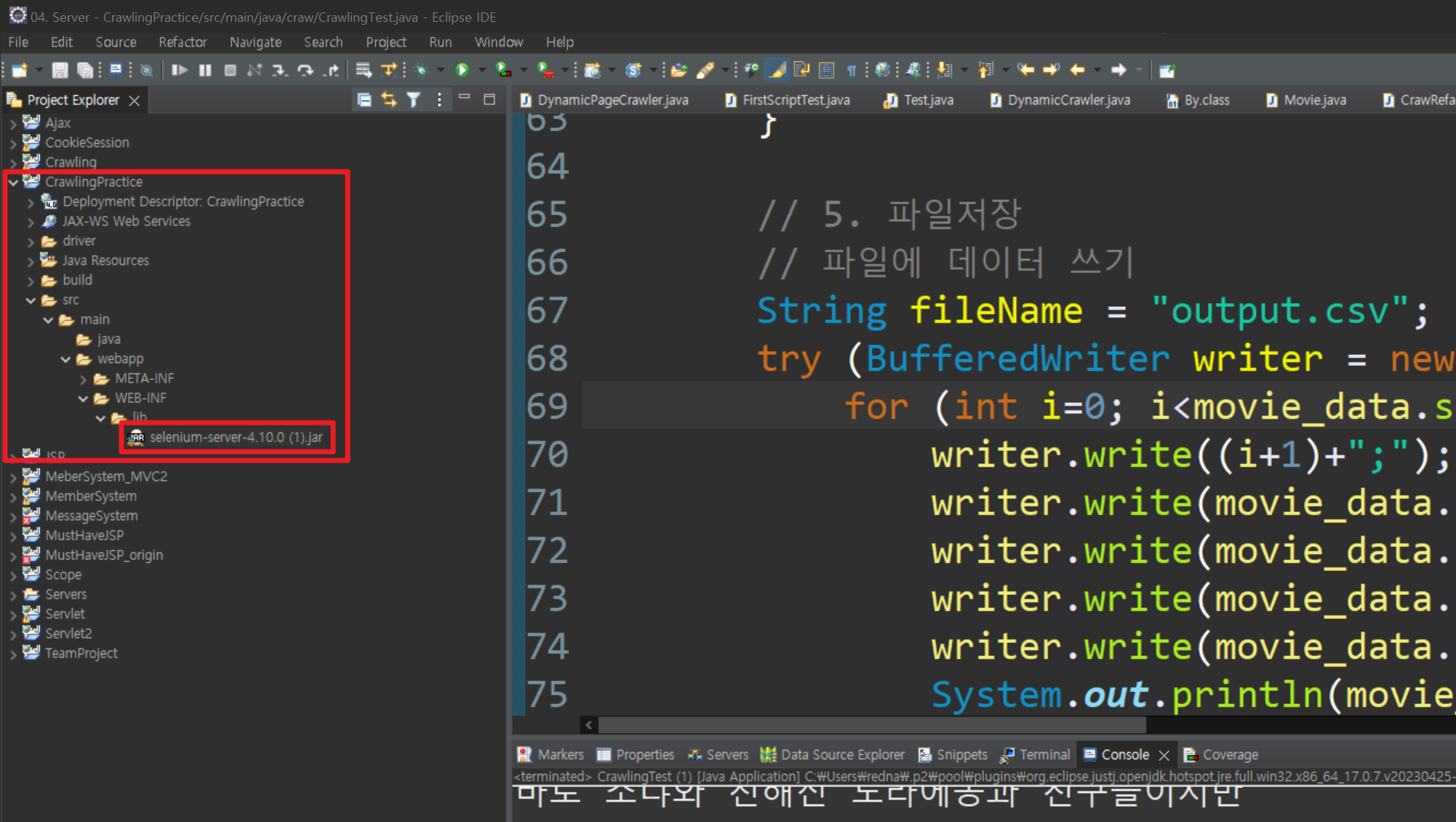
✏️ 4. Java 프로젝트에 chromedriver추가
1. driver폴더 만들기
2. chromedriver.exe (2에서 다운받은) 파일 복사 붙여 넣기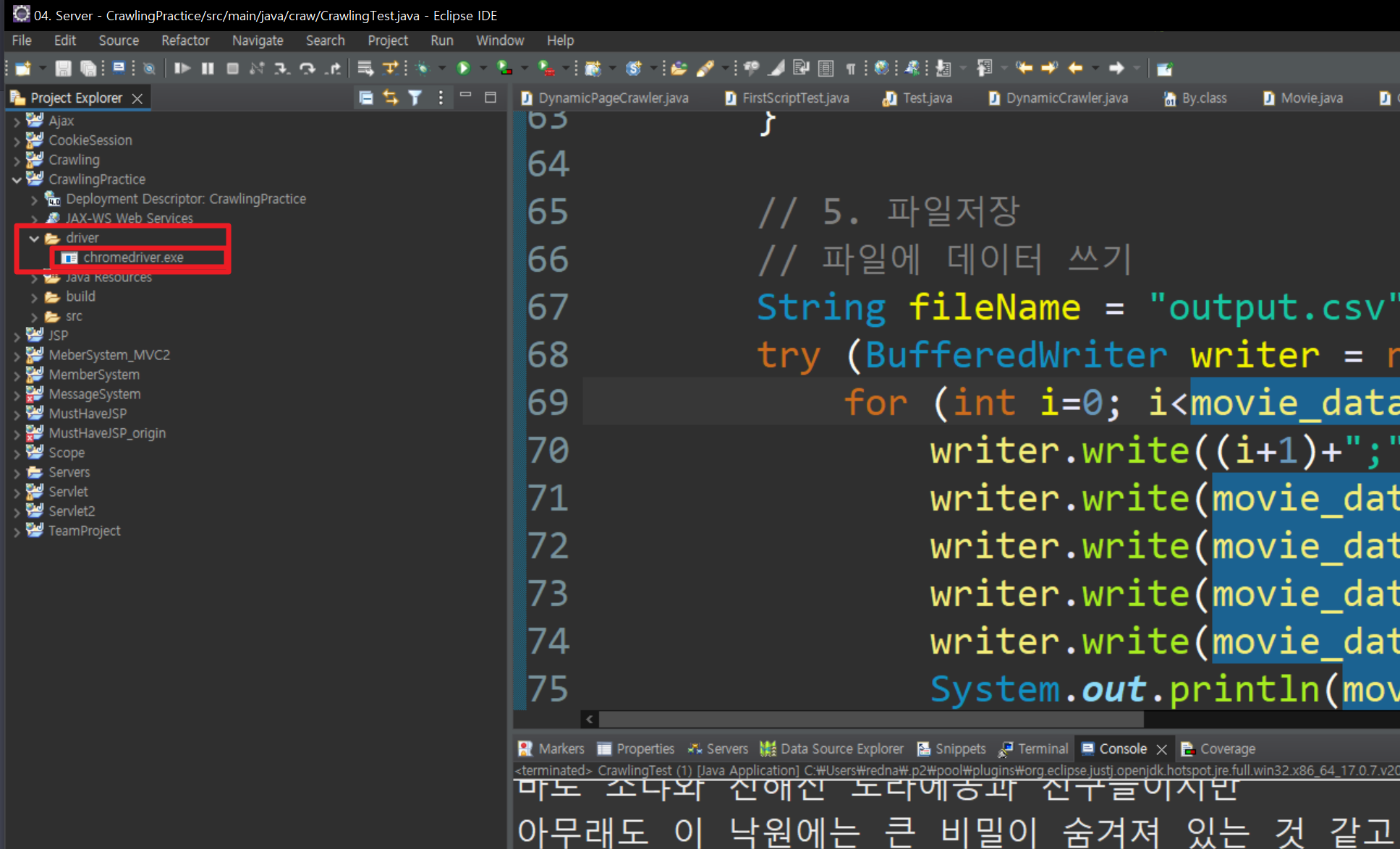
✏️ 5. 크롤링 코드 작성
https://movie.daum.net/ranking/boxoffice/weekly
에서 영화정보 가져오는 코드 작성해보았습니다.
package craw;
import java.time.Duration;
import java.util.ArrayList;
import java.util.List;
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.chrome.ChromeDriver;
public class CrawlingTest {
public static void main(String[] args) {
// 1. WebDriver와 ChromeDriver 설정
// 프로젝트 폴더 기준으로 chromedirver.exe 파일의 위치를 작성
System.setProperty("webdriver.chrome.driver", "driver/chromedriver.exe");
WebDriver driver = new ChromeDriver();
// 2. 웹 페이지 접속
String baseUrl = "https://movie.daum.net/ranking/boxoffice/weekly";
// String searchTerm = "Java";
// String url = baseUrl + "/wiki/" + searchTerm;
driver.get(baseUrl);
// 3. 데이터 추출
ArrayList<Movie> movie_data = new ArrayList<>();
WebElement movie_container = driver.findElement(By.cssSelector(".list_movieranking"));
List<WebElement> movie_links = movie_container.findElements(By.cssSelector(".tit_item>a"));
for(int i= 0; i < movie_links.size(); i++) {
String link = movie_links.get(i).getAttribute("href");
// links.add(link);
driver.get(link);
driver.manage().timeouts().implicitlyWait(Duration.ofMillis(500));
String title = driver.findElement(By.xpath("//*[@id=\"mainContent\"]/div/div[1]/div[2]/div[1]/h3/span[1]")).getText();
String start = driver.findElement(By.xpath("//*[@id=\"mainContent\"]/div/div[1]/div[2]/div[2]/div[1]/dl[1]/dd")).getText();
String star = driver.findElement(By.xpath("//*[@id=\"mainContent\"]/div/div[1]/div[2]/div[2]/div[2]/dl[1]/dd")).getText();
String learning_time = driver.findElement(By.xpath("//*[@id=\"mainContent\"]/div/div[1]/div[2]/div[2]/div[1]/dl[5]/dd")).getText();
String content = driver.findElement(By.xpath("//*[@id=\"mainContent\"]/div/div[2]/div[2]/div[1]/div/div/div")).getText();
Movie movie = new Movie(title, start, star, learning_time, content);
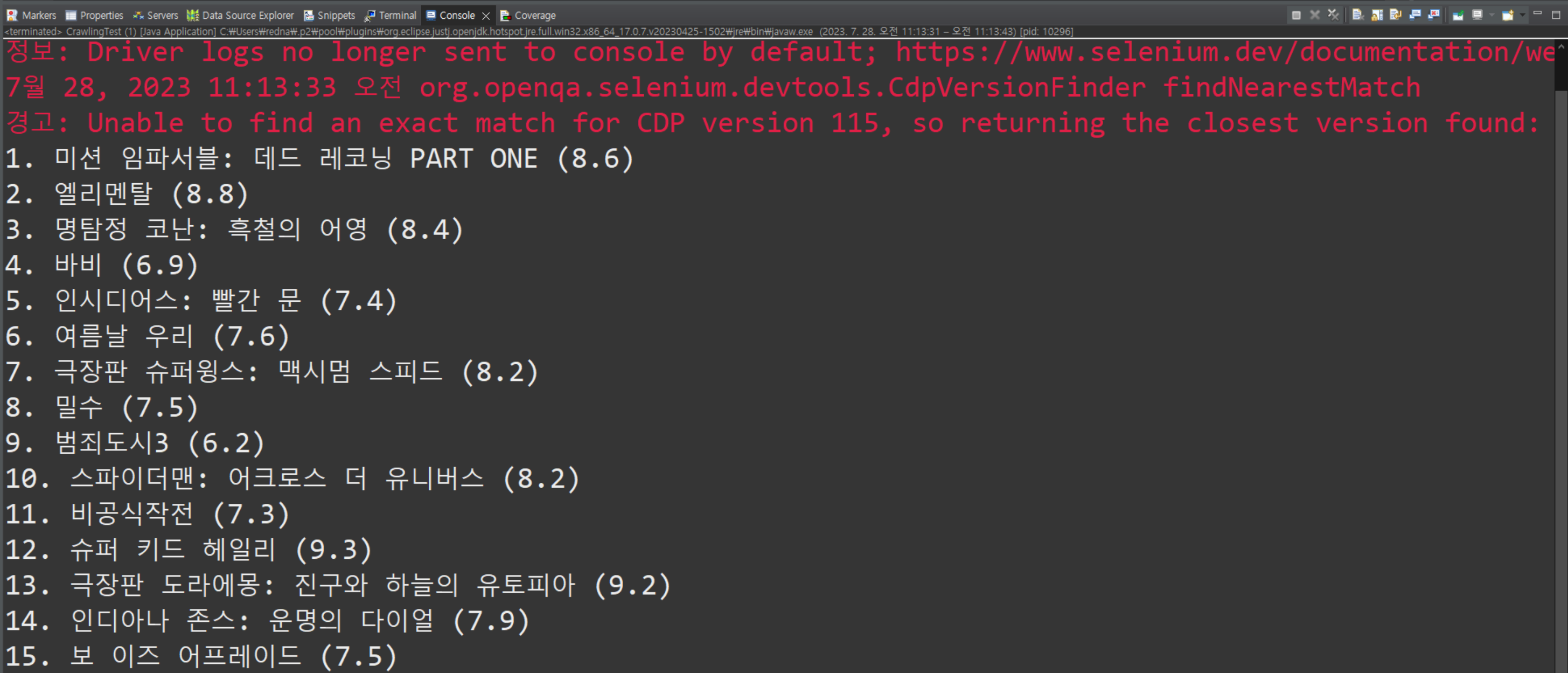
System.out.println((i+1)+". "+ title + " (" + star + ")");
movie_data.add(movie);
driver.navigate().back();
// System.out.println(link);
}
// 4. WebDriver 종료
driver.quit();
}
}
// Movie 정보 담는 자료구조
package craw;
public class Movie {
private String title;
private String start;
private String star;
private String learning_time;
private String content;
public Movie(String title, String start, String star, String learning_time, String content) {
this.title = title;
this.start = start;
this.star = star;
this.learning_time = learning_time;
this.content = content;
}
public String getTitle() {
return title;
}
public String getStart() {
return start;
}
public String getStar() {
return star;
}
public String getLearning_time() {
return learning_time;
}
public String getContent() {
return content;
}
@Override
public String toString() {
return "Movie [title=" + title + ", start=" + start + ", star=" + star + ", learning_time=" + learning_time
+ ", content=" + content + "]";
}
}
✏️ 6. 크롤링 한 내용 CSV 파일로 저장
// 4. 파일저장
// 파일에 데이터 쓰기
String fileName = "output.csv";
try (BufferedWriter writer = new BufferedWriter(new OutputStreamWriter(new FileOutputStream(fileName), "UTF-8"))) {
for (int i=0; i<movie_data.size(); i++) {
writer.write((i+1)+";");
writer.write(movie_data.get(i).getTitle()+";");
writer.write(movie_data.get(i).getStar()+";");
writer.write(movie_data.get(i).getLearning_time()+";");
writer.write(movie_data.get(i).getStart()+";");
System.out.println(movie_data.get(i).getContent());
writer.write(movie_data.get(i).getContent().replace("\n","」"));
writer.newLine();
}
String currentDir = System.getProperty("user.dir");
System.out.println("파일 저장 디렉토리: " + currentDir);
System.out.println("파일에 데이터를 성공적으로 저장했습니다.");
} catch (IOException e) {
e.printStackTrace();
}
✏️ 7. 전체 코드 (리팩토링 안함)
package craw;
import java.io.BufferedWriter;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.OutputStreamWriter;
import java.time.Duration;
import java.util.ArrayList;
import java.util.List;
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.chrome.ChromeDriver;
public class CrawlingTest {
public static void main(String[] args) {
// 1. WebDriver와 ChromeDriver 설정
// 프로젝트 폴더 기준으로 chromedirver.exe 파일의 위치를 작성
System.setProperty("webdriver.chrome.driver", "driver/chromedriver.exe");
WebDriver driver = new ChromeDriver();
// 2. 웹 페이지 접속
String baseUrl = "https://movie.daum.net/ranking/boxoffice/weekly";
// String searchTerm = "Java";
// String url = baseUrl + "/wiki/" + searchTerm;
driver.get(baseUrl);
// 3. 데이터 추출
ArrayList<Movie> movie_data = new ArrayList<>();
WebElement movie_container = driver.findElement(By.cssSelector(".list_movieranking"));
List<WebElement> movie_links = movie_container.findElements(By.cssSelector(".tit_item>a"));
for(int i= 0; i < movie_links.size(); i++) {
String link = movie_links.get(i).getAttribute("href");
// links.add(link);
driver.get(link);
driver.manage().timeouts().implicitlyWait(Duration.ofMillis(500));
String title = driver.findElement(By.xpath("//*[@id=\"mainContent\"]/div/div[1]/div[2]/div[1]/h3/span[1]")).getText();
String start = driver.findElement(By.xpath("//*[@id=\"mainContent\"]/div/div[1]/div[2]/div[2]/div[1]/dl[1]/dd")).getText();
String star = driver.findElement(By.xpath("//*[@id=\"mainContent\"]/div/div[1]/div[2]/div[2]/div[2]/dl[1]/dd")).getText();
String learning_time = driver.findElement(By.xpath("//*[@id=\"mainContent\"]/div/div[1]/div[2]/div[2]/div[1]/dl[5]/dd")).getText();
String content = driver.findElement(By.xpath("//*[@id=\"mainContent\"]/div/div[2]/div[2]/div[1]/div/div/div")).getText();
Movie movie = new Movie(title, start, star, learning_time, content);
System.out.println((i+1)+". "+ title + " (" + star + ")");
movie_data.add(movie);
driver.navigate().back();
// System.out.println(link);
}
// 4. 파일저장
// 파일에 데이터 쓰기
String fileName = "output.csv";
try (BufferedWriter writer = new BufferedWriter(new OutputStreamWriter(new FileOutputStream(fileName), "UTF-8"))) {
for (int i=0; i<movie_data.size(); i++) {
writer.write((i+1)+";");
writer.write(movie_data.get(i).getTitle()+";");
writer.write(movie_data.get(i).getStar()+";");
writer.write(movie_data.get(i).getLearning_time()+";");
writer.write(movie_data.get(i).getStart()+";");
writer.write(movie_data.get(i).getContent().replace("\n","」"));
writer.newLine();
}
String currentDir = System.getProperty("user.dir");
System.out.println("파일 저장 디렉토리: " + currentDir);
System.out.println("파일에 데이터를 성공적으로 저장했습니다.");
} catch (IOException e) {
e.printStackTrace();
}
// 5. WebDriver 종료
driver.quit();
}
}📕 결론
오늘 작업을 하면서
다음 2가지 이유로
역시 크롤링은 Python으로 하는 것이
훨씬 편하다고 느꼈습니다.
Java로 크롤링 했을 때 단점
1. 초기 환경설정의 어려움
2. 데이터 분석 라이브러리 상대적으로 약세 (Python은 pandas 활용가능)
3. 파일 읽기 쓰기 시 조금 불편 (CSV파일을 억지로 만들었음ㅜ)
1.01^365
많은 도움이 되었습니다, 감사합니다.