[천재교육] selenium 기본 사용법

📕 들어가며
이 글은 selenium 패키지 기본 사용 방법 에 대해
(역시나 제가 이해하기 쉽게) 정리한 글입니다.
재미(?!)를 위하여
프로젝트 형식으로
구글에서
아이유라고 검색했을 때
나오는 뉴스기사의 제목을
가져오는 크롤링 프로그램
을 만들어 보도록 하겠습니다.
📕 프로젝트
✏️1. 기본 세팅
# 1) 필요한 패키지 불러오기
from selenium import webdriver # 동적 사이트 수집
from webdriver_manager.chrome import ChromeDriverManager # 크롬 드라이버 설치
from selenium.webdriver.chrome.service import Service # 자동적 접근
from selenium.webdriver.chrome.options import Options # 크롭 드라이버 옵션 지정
from selenium.webdriver.common.by import By # find_element 함수 쉽게 쓰기 위함# 2) 옵션 지정 및 크롬 드라이버 실행하기
# 크롬 세팅: 크롬 브라우저 창이 화면에 보이지 않게 하는 기능
# 고수들은 창을 화면에 안띄우고 크롤링 하던데
# 저는 디버깅할 때 불편해서 options 빼고 크롬 드라이버 실행했습니다.
# options = Options()
# options.add_argument('--headless')
# options.add_argument('--no-sandbox')
# options.add_argument('--disable-dev-shm-usage')
# options.add_argument("--window-size=2560,1440")
# driver= webdriver.Chrome(service=Service(ChromeDriverManager().install()), options= options)
driver= webdriver.Chrome(service=Service(ChromeDriverManager().install()))
실행 결과 : 성공하면 이런 화면이 뜹니다.
✏️2. url 이용해서 페이지 이동
이제 구글 홈페이지로 이동해 보겠습니다.
# driver.get(url) : url로 이동하는 코드
driver.get('https://www.google.com/?hl=ko')실행 결과 :
✏️3. 요소 선택
사실 요소 선택이 제일 어려운 부분인데요
F12 누리면 나오는개발자 도구와약간의 센스가 필요합니다.
우선 F12를 누르면 요런 화면이 뜨는데
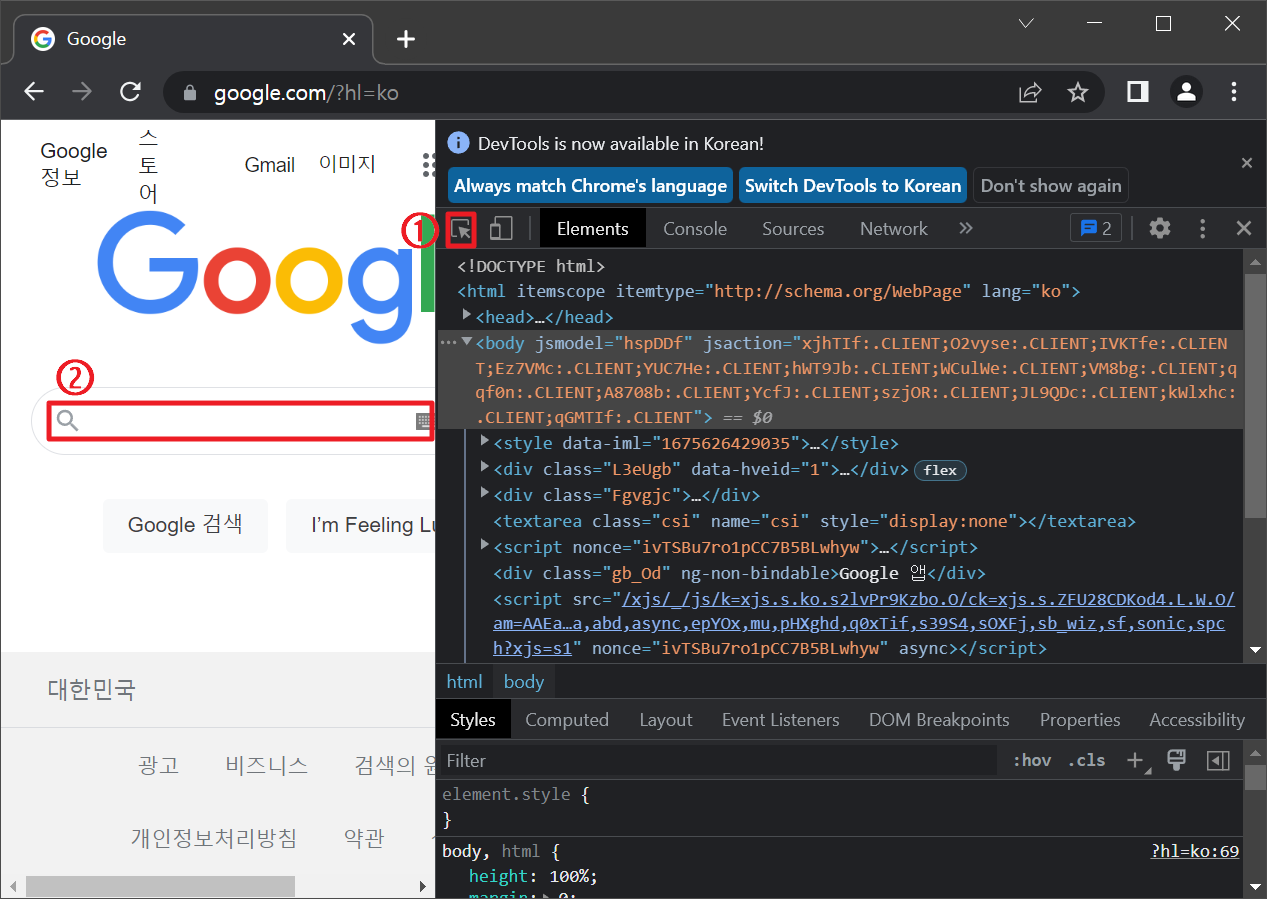
여기서
① 버튼 클릭하고
② 우리가 찾고자 하는 대상 클릭해주면
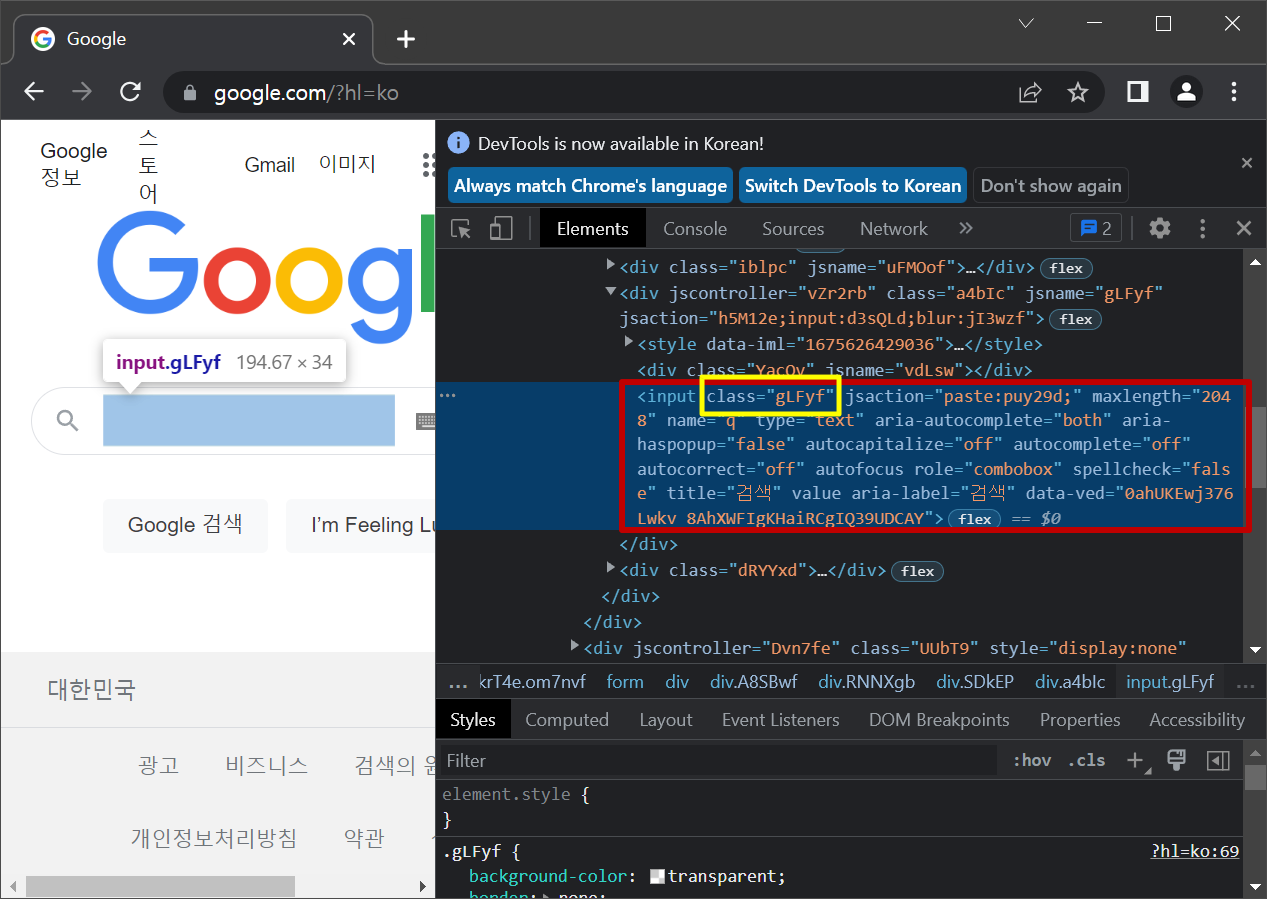
이렇게 우리가 찾고자 하는 대상의 정보를 표시해 줍니다.
1. 검색창에 글자 입력하기
# 1) 검색창을 찾아서 아이유라고 입력하는 코드 입니다.
# driver.find_element(By.CLASS_NAME,"찾을 클래스 이름") : 클래스 이름을 가지고 대상을 찾는 함수 입니다.
# (개발자 도구에서 검색창의 class가 gLFyf임을 확인하였습니다.)
# 대상.send_keys("key"): input tag에 값을 입력해 주는 함수 입니다.
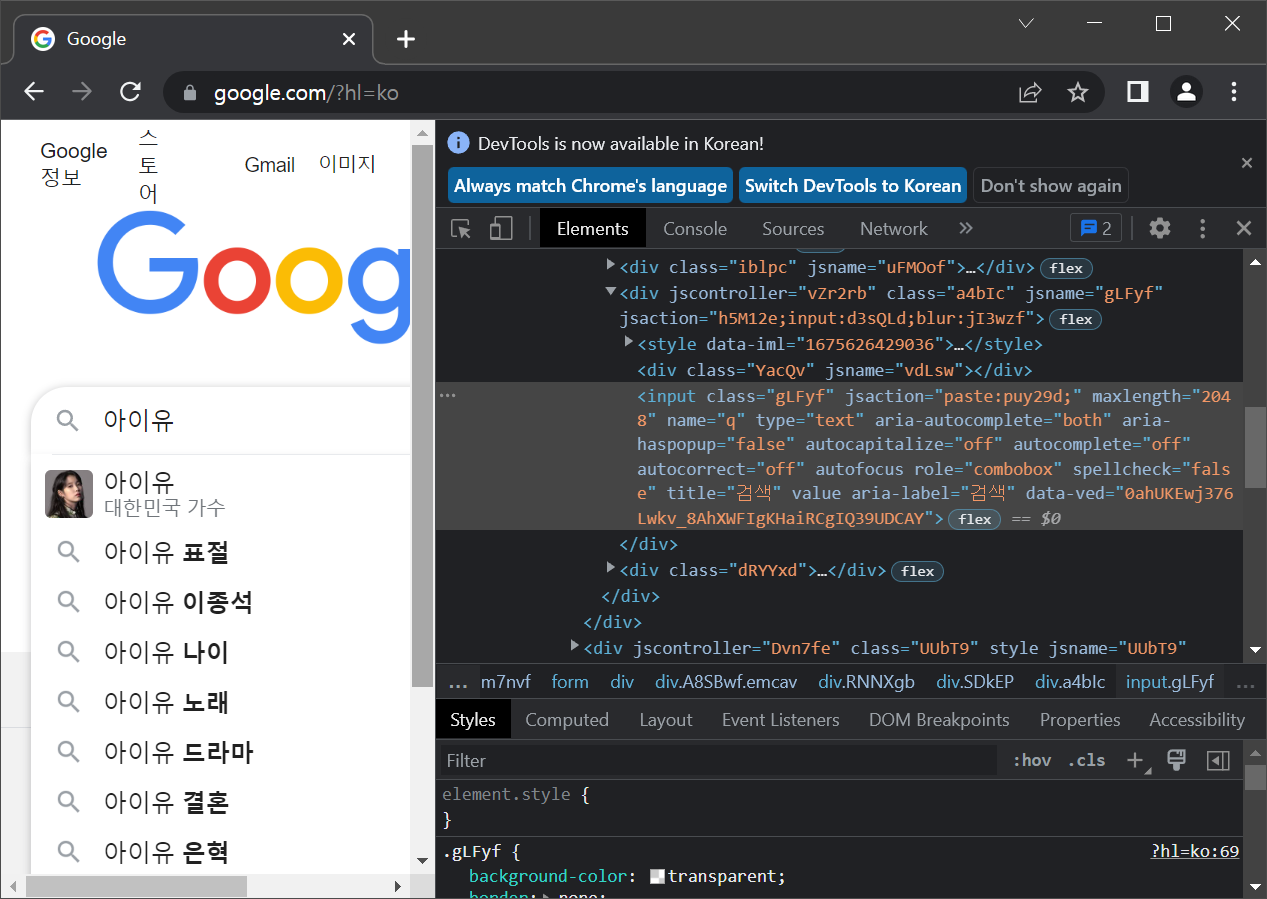
driver.find_element(By.CLASS_NAME,"gLFyf").send_keys("아이유")
실행 결과 : 검색창에 아이유란 글자가 입력 되었습니다.
2. 검색 버튼 클릭 하기
# 2) 검색 버튼을 찾아서 눌려주는 코드 입니다.
# driver.find_element(By.CSS_SELECTOR,"css selector") : css selector를 활용해서 대상을 찾아주는 함수 입니다.
# 대상.click(): 버튼이나 링크 등을 클릭해주는 코드 입니다.
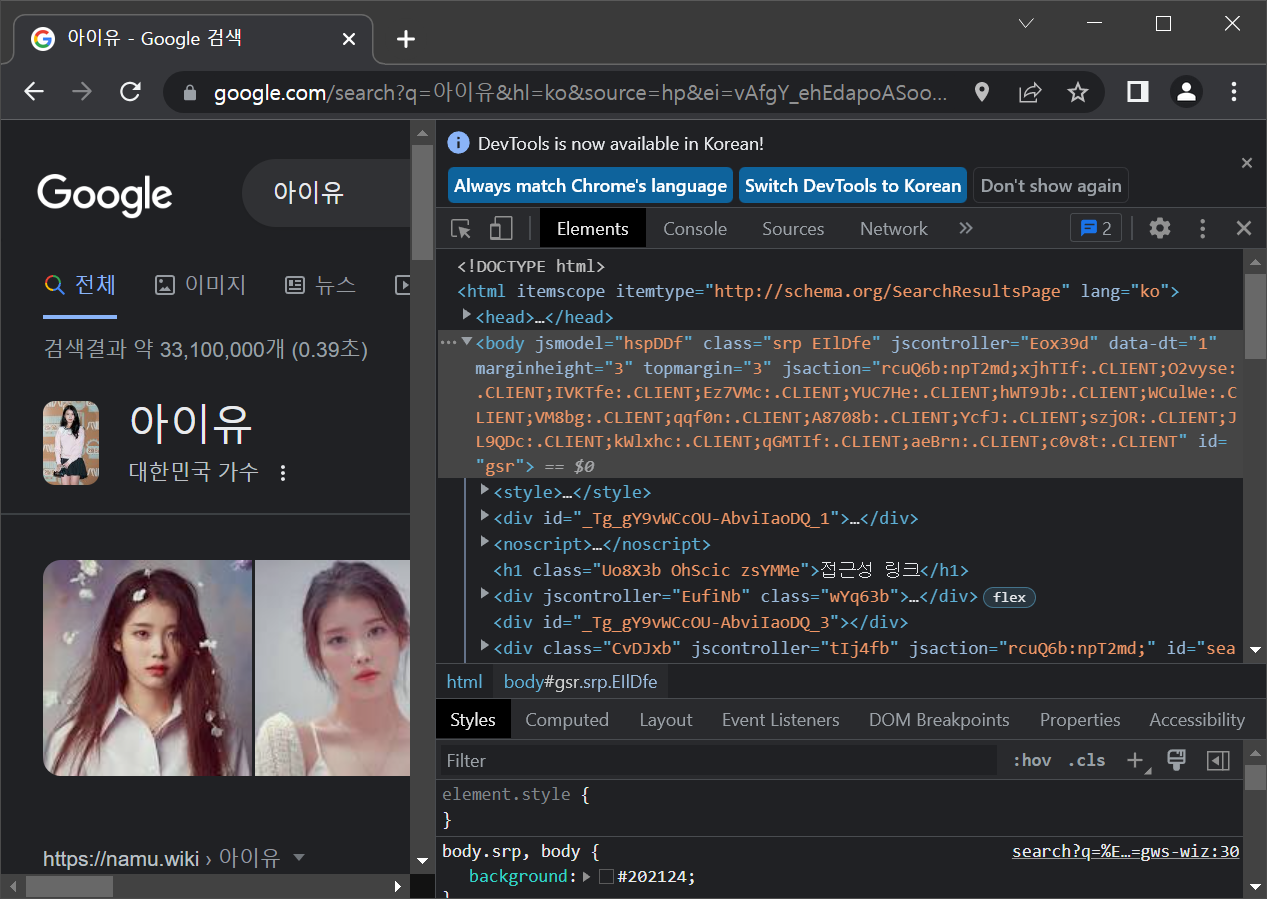
driver.find_element(By.CSS_SELECTOR,"center > input.gNO89b").click()
실행 결과 : 검색 버튼을 눌렸습니다.
3. 클릭 버튼 누르기
# 3) 뉴스 버튼을 눌려주는 코드 입니다.
# driver.find_element(By.XPATH,"대상의 xpath") : xpath를 활용해서 대상을 찾아주는 함수 입니다.
# 대상.click(): 버튼이나 링크 등을 클릭해주는 코드 입니다.
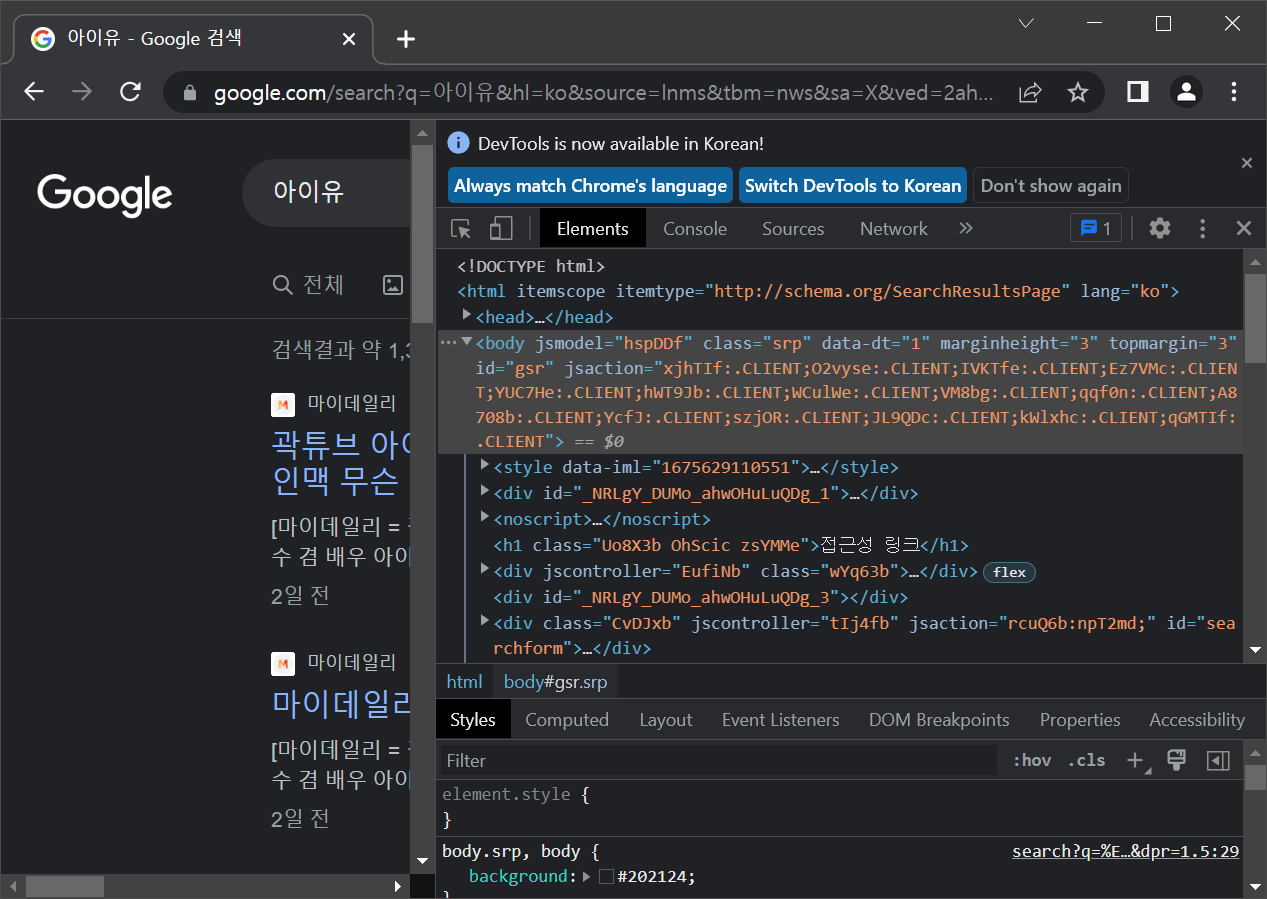
driver.find_element(By.XPATH,'//*[@id="hdtb-msb"]/div[1]/div/div[3]/a').click()실행 결과 : 뉴스창으로 이동했습니다.
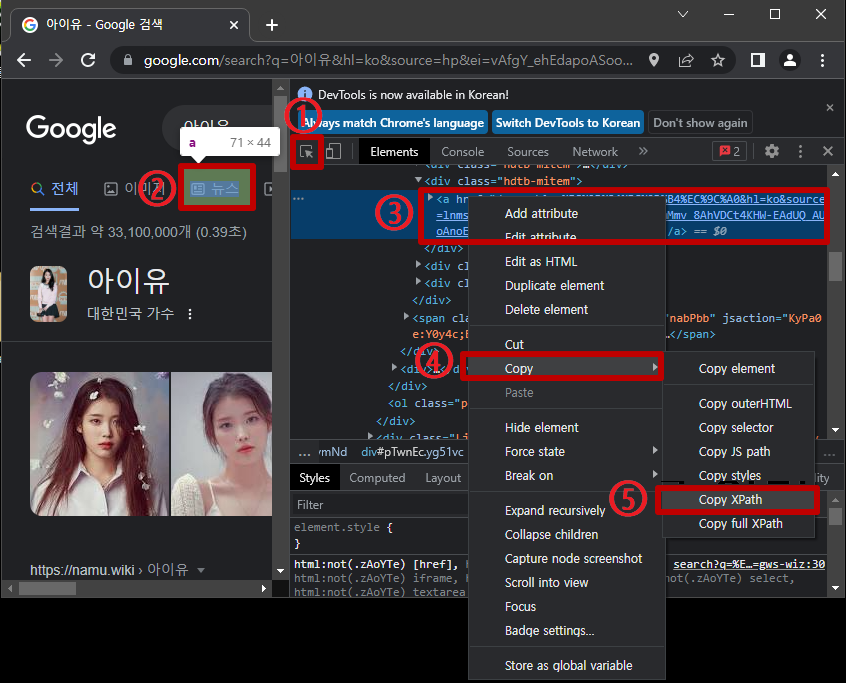
※ XPATH 는 다음과 같이 얻을 수 있습니다.
✏️4. 태그 안의 글자 가져오기
# 대상.text : 대상의 텍스트를 가져 옵니다.
titles = []
links = driver.find_elements(By.CSS_SELECTOR,".mCBkyc.ynAwRc.MBeuO.nDgy9d")
for link in links:
titles.append(link.text)
실행 결과 : titles에 뉴스 기사 제목이 담겼습니다.

📕 전체 코드
from selenium import webdriver # 동적 사이트 수집
from webdriver_manager.chrome import ChromeDriverManager # 크롬 드라이버 설치
from selenium.webdriver.chrome.service import Service # 자동적 접근
from selenium.webdriver.chrome.options import Options # 크롭 드라이버 옵션 지정
from selenium.webdriver.common.by import By # find_element 함수 쉽게 쓰기 위함
import time # 필요 시 시간 지연 시키기 위해 사용
driver= webdriver.Chrome(service=Service(ChromeDriverManager().install()))
# 구글 사이트 이동
driver.get('https://www.google.com/?hl=ko')
driver.implicitly_wait(10)
# 검색창에 아이유 입력
driver.find_element(By.CLASS_NAME,"gLFyf").send_keys("아이유")
# 검색 버튼 클릭
driver.find_element(By.CSS_SELECTOR,"center > input.gNO89b").click()
driver.implicitly_wait(10)
# 뉴스 버튼 클릭
driver.find_element(By.XPATH,'//*[@id="hdtb-msb"]/div[1]/div/div[3]/a').click()
driver.implicitly_wait(10)
# 결과 담을 리스트
titles = []
# 뉴스기사 태그들
links = driver.find_elements(By.CSS_SELECTOR,".mCBkyc.ynAwRc.MBeuO.nDgy9d")
# 반복문 돌리면서 기사제목 모으는 코드
for link in links:
titles.append(link.text)
# 기사 제목 출력 코드
print(*titles, sep="\n")
실행 결과 : 잘 동작 하네요 ^^ 종석님이랑 이쁘게 사귀시고 있는군요 (또르르..)

📕 과제
크롤링은 뭔가 센스가 많이 필요한 듯 합니다.
그래서 크롤링에 익숙해지기 위해
이번에 배운 내용을 활용해서
과제로 다음 프로젝트를 진행하고자 합니다.
구글 들어가서 원하는 검색어 입력했을 때
나오는 이미지 전부 크롤링 해오는 프로그램
(예) 네즈코
제가 한 과제가 궁금하시다면
요 밑에 링크 클릭 해주시면 됩니다 ^^

1.01^365