[천재교육] pymongo 활용 대용량파일 DB에 밀어넣기

📕 들어가며
이번 글에서는
pymongo 패키지를 활용해서
대용량 CSV파일의 데이터를
MongoDB 데이터베이스 서버에
밀어넣는 작업을 해보겠습니다.
📕 사전준비
✏️ 1. MongoDB 설치
아래 글 참고해서 MongoDB 설치해주세요 ^^
<참고자료> : MongoDB 설치방법
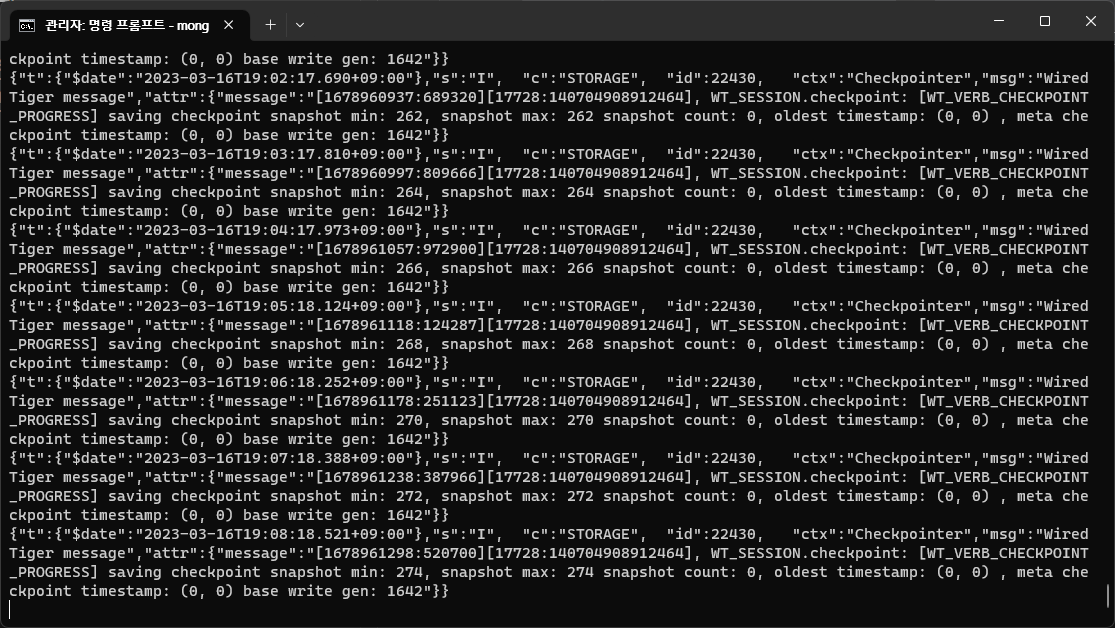
✏️ 2. MongoDB 서버 실행
CMD 창에서 다음과 같이 입력해줍니다.
mongod<실행결과> : MongoDB 서버가 켜졌습니다.
✏️ 3. csv 파일 다운로드
이 자료 다운 받아주세요 ^^
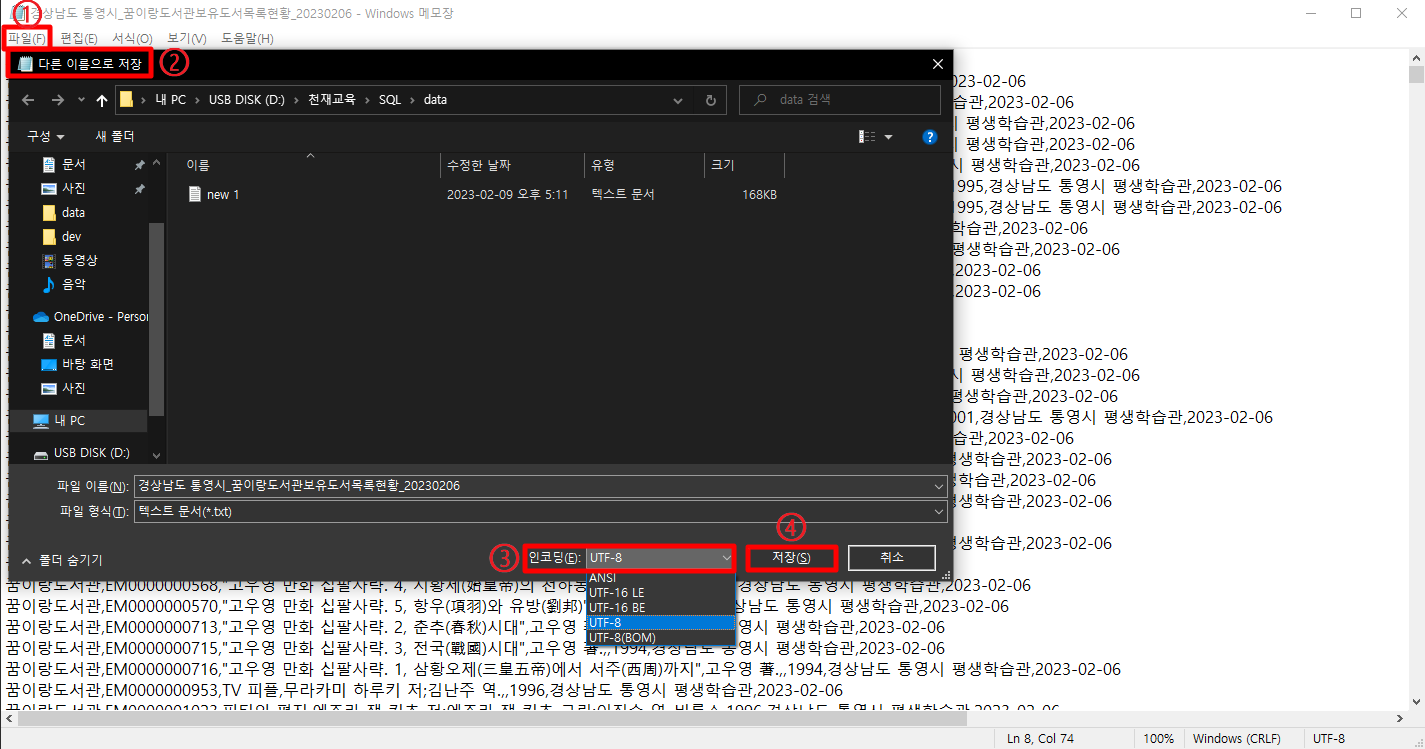
✏️ 4. csv 파일 utf-8로 인코딩
메모장으로 방금 다운 받은 csv파일을 열어서
[파일] -> [다른 이름으로 저장] -> 인코딩: UTF-8 선택 -> [저장]
해주시면 됩니다.
📕 csv 파일 DB에 밀어넣기
✏️ 1. csv 패키지 활용 데이터 읽어오기
# csv 파일에서 데이터 불러오기
import csv
from datetime import datetime
#. 파일을 읽습니다.
file = open("./data/경상남도 통영시_꿈이랑도서관보유도서목록현황_20230206.csv",
'r',
encoding = 'UTF-8')
#. csv 라이브러리가 csv 파일을 읽을 수 있도록 변환합니다.
reader = csv.reader(file)
is_header = True
books = []
datetime_format = "%Y-%m-%d"
for line in reader:
# line[0], line[1], line[2], line[3], line[4], line[5], line[6], line[7]
# 도서관명, 등록번호, 자료명, 저자명, 발행처, 발행연도, 관리기관명, 데이터기준일자
if is_header == True:
is_header = False
continue
if len(line) < 8 :
continue
book = {
"library_name" : line[0],
"book_number": line[1],
"book_name": line[2],
"author" : line[3],
"publisher": line[4],
"publish_year": line[5],
"sido" : line[6],
"create_date": datetime.strptime(line[7], datetime_format)
}
books.append(book)
print(len(books))<실행결과> : books에 34851건의 데이터가 담겨있습니다.

✏️ 2. pymongo 패키지 활용 데이터 저장
book에 담긴 데이터를
pymongo 패키지를 활용하여
MongoDB 데이터베이스에 넣어줍니다.
import pymongo
# Mongodb와 연결합니다.
client = pymongo.MongoClient("mongodb://localhost:27017")
# 데이터베이스를 찾는다.
database = connection["test"]
# 데이터베이스에서 컬렉션을 찾는다.
collection = database['books']
# 대량의 데이터를 Insert 한다. insert_many
print("--------------------------------- START ------------------------")
result = collection.insert_many(books)
print("--------------------------------- END ---------------------------")
# 데이터 잘 입력 되었는지 확인
print("성공여부:", result.acknowledged)
print("입력건수:", len(result.inserted_ids))
client.close()<실행결과> : 34851건의 데이터가 입력되었습니다.

✏️ 3. 입력결과 확인
입력된 데이터를 pandas 데이터프레임 형태로 출력해보겠습니다.
import pymongo
import pandas as pd
# Mongodb와 연결합니다.
client = pymongo.MongoClient("mongodb://localhost:27017")
# 데이터베이스를 찾는다.
database = connection["test"]
# 데이터베이스에서 컬렉션을 찾는다.
collection = database['books']
# 데이터 잘 입력 되었는지 확인
datas = collection.find({})
# pandas 데이터프레임 형태로 변환
datas = pd.DataFrame(list(datas))
# 데이터베이스와 연결종료
client.close()
# 5개만 출력
datas.head()<실행결과> : 이제부터 데이터 분석 작업을 진행하시면 됩니다. ^^

📕 느낀 점
똑같은 크기의 데이터(
34851건)를 밀어넣는데
MongoDB는0.5s가 걸리고
mySQL은25m 51s가 걸렸습니다.
역시 수업시간에 배운대로
MongoDB가 구조가 유연하며
대용량 데이터를 다루는데 유리하다는 것을
실습을 통해 직접 체험하였습니다. ^^

1.01^365