[천재교육] pymysql 대용량파일 밀어넣기
📕 들어가며
이번 글에서는
pymysql을 활용해서
대용량 CSV파일의 데이터를
MySQL 데이터베이스 서버에
밀어넣는 작업을 해보겠습니다.
📕 실습준비
✏️ 1. csv 파일 다운로드
이 자료 다운 받아주세요 ^^
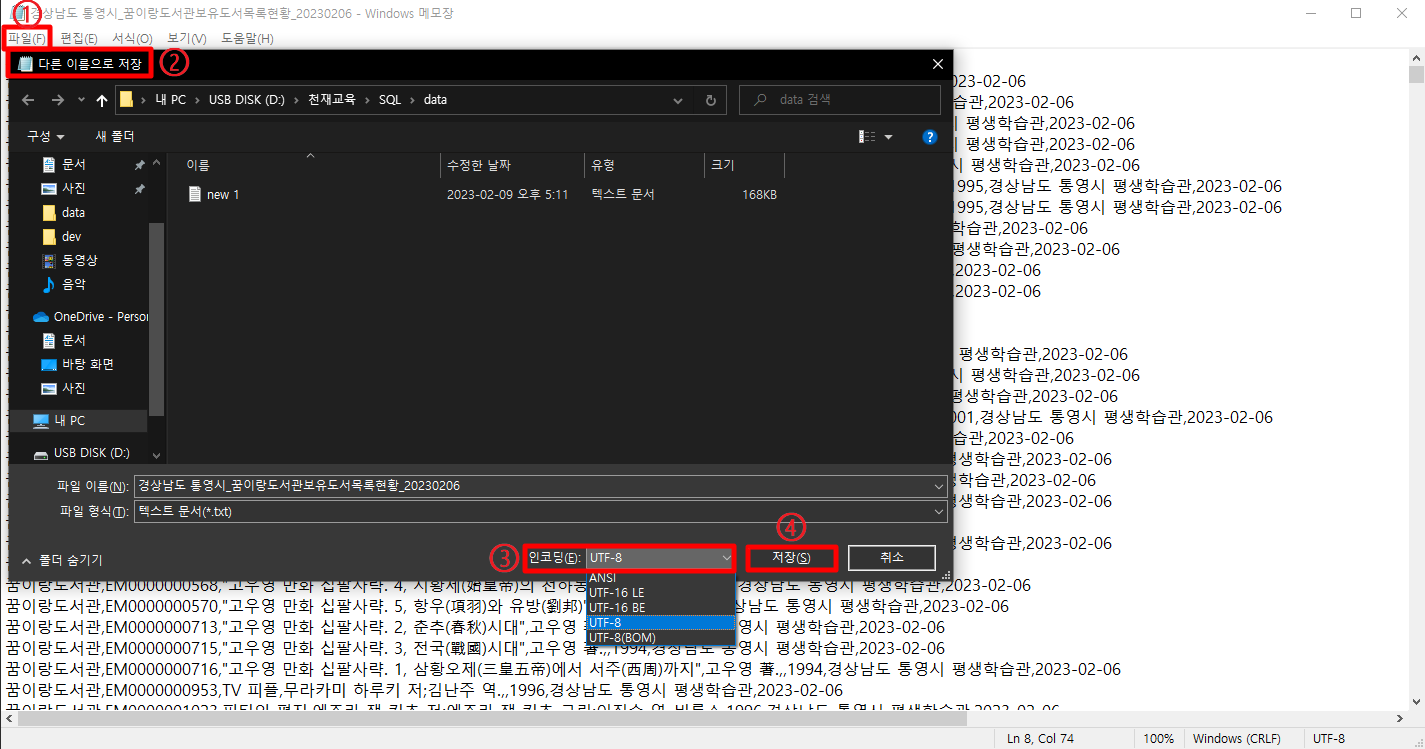
✏️ 2. csv 파일 utf-8로 인코딩하기
메모장으로 방금 다운 받은 csv파일을 열어서
[파일] -> [다른 이름으로 저장] -> 인코딩: UTF-8 선택 -> [저장]
해주시면 됩니다.
<참고> :
✏️ 3. 파이썬 csv 라이브러리 사용법
import csv
# 파일을 읽습니다.
file = open("./data/경상남도 통영시_꿈이랑도서관보유도서목록현황_20230206.csv",'r', encoding = 'UTF-8')
# csv 라이브러리가 csv 파일을 읽을 수 있도록 변환합니다.
reader = csv.reader(file)
# csv 파일의 한 line(줄)씩 읽어 들이는 과정입니다.
for i, line in enumerate(reader) :
if i==2:
break
# 도서관명,등록번호,자료명,저자명,발행처,발행연도,관리기관명, 데이터기준일자
print(line[0],line[1],line[2],line[3],line[4],line[5],line[6],line[7],sep='/')
print('데이터를 모두 입력하였습니다.')<실행결과>

📕 csv 파일 DB에 밀어넣기
✏️ 1. 테이블 생성
나중에 다른 도서관의 도서도 넣을 것으로 가정해
library 테이블과 author 테이블을 별도의 테이블로 구성했으며
book 테이블에는 library_id 와 author_id를 FK로 부여하였습니다.
CREATE DATABASE testdb;
DROP TABLE IF EXISTS `testdb`.`library`;
DROP TABLE IF EXISTS `testdb`.`book`;
DROP TABLE IF EXISTS `testdb`.`author`;
CREATE TABLE `library` (
`id` bigint NOT NULL AUTO_INCREMENT COMMENT 'PK' PRIMARY KEY,
`name` VARCHAR(50) NULL COMMENT '도서관 이름',
`create_date` datetime NOT NULL DEFAULT current_timestamp COMMENT '생성일',
`update_date` datetime NOT NULL DEFAULT current_timestamp COMMENT '수정일'
);
CREATE TABLE `book` (
`book_id` VARCHAR(50) NOT NULL COMMENT '도서이름(PK)',
`name` VARCHAR(2000) NULL COMMENT '책 이름',
`publisher` VARCHAR(500) NULL COMMENT '발행처 출판사',
`publish_yeard` VARCHAR(500) NOT NULL DEFAULT 1900 COMMENT '이 책의 발행 연도',
`Agency_name` VARCHAR(500) NULL,
`library_id` bigint NOT NULL COMMENT '도서관 식별자',
`author_id` bigint NOT NULL COMMENT '작가 식별자',
`create_date` datetime NOT NULL DEFAULT current_timestamp COMMENT '생성일',
`update_date` datetime NOT NULL DEFAULT current_timestamp COMMENT '수정일'
);
CREATE TABLE `author` (
`id` bigint NOT NULL AUTO_INCREMENT COMMENT 'PK' PRIMARY KEY,
`name` VARCHAR(500) NULL COMMENT '작가 이름',
`create_date` datetime NOT NULL DEFAULT current_timestamp COMMENT '생성일',
`update_date` datetime NOT NULL DEFAULT current_timestamp COMMENT '수정일'
);✏️ 2. 의사코드 작성
- csv파일을 한 줄씩 읽어온다.
(도서관명, 등록번호, 자료명, 저자명, 발행처, 발행연도, 관리기관명, 데이터기준일자)- 도서관명이 library 테이블에 있으면 해당 library_id 사용
도서관명이 library 테이블에 없다면 새로 생성후 생성된 library_id 사용- 저자명이 author 테이블에 있으면 해당 author_id 사용
저자명이 author 테이블에 없다면 새로 생성후 생성된 author_id 사용- 2번, 3번에서 얻은 library_id와 author_id를 활용해서 book 테이블에 데이터 추가
✏️ 3. 파이썬 코드 작성
import pymysql
# connection 객체 반환해주는 함수
def db_connect() :
connection = pymysql.connect(host = 'localhost', user = 'test', password = '1111', db = 'testdb', charset = 'utf8')
return connection
# connection 객체 닫아주는 함수
def db_close(connection):
connection.close()
# 도서관 이름을 입력하면 library_id를 반환하는 함수
def save_library(library_name):
connection = db_connect()
# cursor를 생성한다.
# cursor에 데이터 딕셔너리 옵션을 준다. (결과를 데이터 딕셔너리로 자동으로 바꿔주는 옵션)
cursor = connection.cursor(pymysql.cursors.DictCursor)
id = 0
# 1. 먼저 이름으로 검색
SQL = '''
SELECT *
FROM library
WHERE name = %s
'''
parameter = library_name
cursor.execute(SQL, parameter)
library = cursor.fetchone()
# 이미 생성된 도서관이라면, 그 도서관 id를 바로 반환
if library is not None :
id = library['id']
else :
# 만약 새로운 도서관이라면?!
# 1. 도서관 새로 생성
SQL = '''
INSERT INTO testdb.library (name, create_date, update_date)
VALUES(%s, CURRENT_TIMESTAMP, CURRENT_TIMESTAMP);
'''
parameter = library_name
cursor.execute(SQL, library_name)
# 데이터가 반영이 안되서 우선 한번 커밋
connection.commit()
# 2. 생성한 도서관 id 가져오기
SQL = '''
SELECT id
FROM library
WHERE name = %s
'''
cursor.execute(SQL, library_name)
library = cursor.fetchone()
id = library['id']
db_close(connection)
return id
# 작가 이름을 입력하면 author_id를 반환하는 함수
def save_author(author_name):
connection = db_connect()
# cursor를 생성한다.
# cursor에 데이터 딕셔너리 옵션을 준다. (결과를 데이터 딕셔너리로 자동으로 바꿔주는 옵션)
cursor = connection.cursor(pymysql.cursors.DictCursor)
id = 0
# 1. 먼저 이름으로 검색
SQL = '''
SELECT *
FROM author
WHERE name = %s
'''
parameter = author_name
cursor.execute(SQL, parameter)
author = cursor.fetchone()
# 기존에 있던 작가라면 id 바로 반환
if author is not None :
id = author['id']
else :
# 새로 들어온 작가라면
# 1. 작가 새로 생성
SQL = '''
INSERT INTO testdb.author (name, create_date, update_date)
VALUES(%s, CURRENT_TIMESTAMP, CURRENT_TIMESTAMP);
'''
parameter = author_name
cursor.execute(SQL, author_name)
# 데이터가 반영이 안되서 우선 한번 커밋
connection.commit()
# 2. 생성한 작가 id 가져오기
SQL = '''
SELECT id
FROM author
WHERE name = %s
'''
cursor.execute(SQL, author_name)
author = cursor.fetchone()
id = author['id']
db_close(connection)
return id✏️ 4. 데이터 밀어넣기
import csv
#. 파일을 읽습니다.
file = open("../data/경상남도 통영시_꿈이랑도서관보유도서목록현황_20230206.csv",
'r',
encoding = 'UTF-8')
#. csv 라이브러리가 csv 파일을 읽을 수 있도록 변환합니다.
reader = csv.reader(file)
# csv 파일의 한 라인(줄)씩 읽어 들이는 과정입니다.
connection = db_connect()
cursor = connection.cursor(pymysql.cursors.DictCursor)
SQL = '''
INSERT INTO book(
book_id, name, publisher, publish_yeard, Agency_name, library_id, author_id
) VALUES (
%s, %s, %s, %s, %s, %s, %s
)
'''
for i, line in enumerate(reader) :
if line[0] == '도서관명':
print('여기는 헤더입니다.')
continue
try:
# 도서관명, 등록번호, 자료명, 저자명, 발행처, 발행연도, 관리기관명, 데이터기준일자
library_name = line[0]
author_name = line[3]
# 도서관 정보, 작가 정보를 가져온다.
library_id = save_library(library_name)
author_id = save_author(author_name)
parameter = (line[1], line[2], line[4], line[5], line[6], library_id, author_id)
cursor.execute(SQL, parameter)
connection.commit()
except Exception as e:
print(f'{line[1]} 데이터 입력 중 오류가 발생했습니다. ==> ', e)
continue
print('데이터를 모두 입력하였습니다.')<실행결과> 총 소요시간 25분 51초...ㄷㄷ

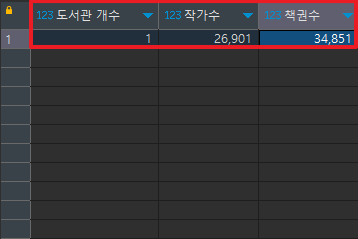
<실행결과> 테이블 별 데이터 개수
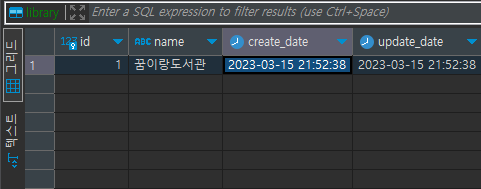
<실행결과> library TABLE
<실행결과> author TABLE
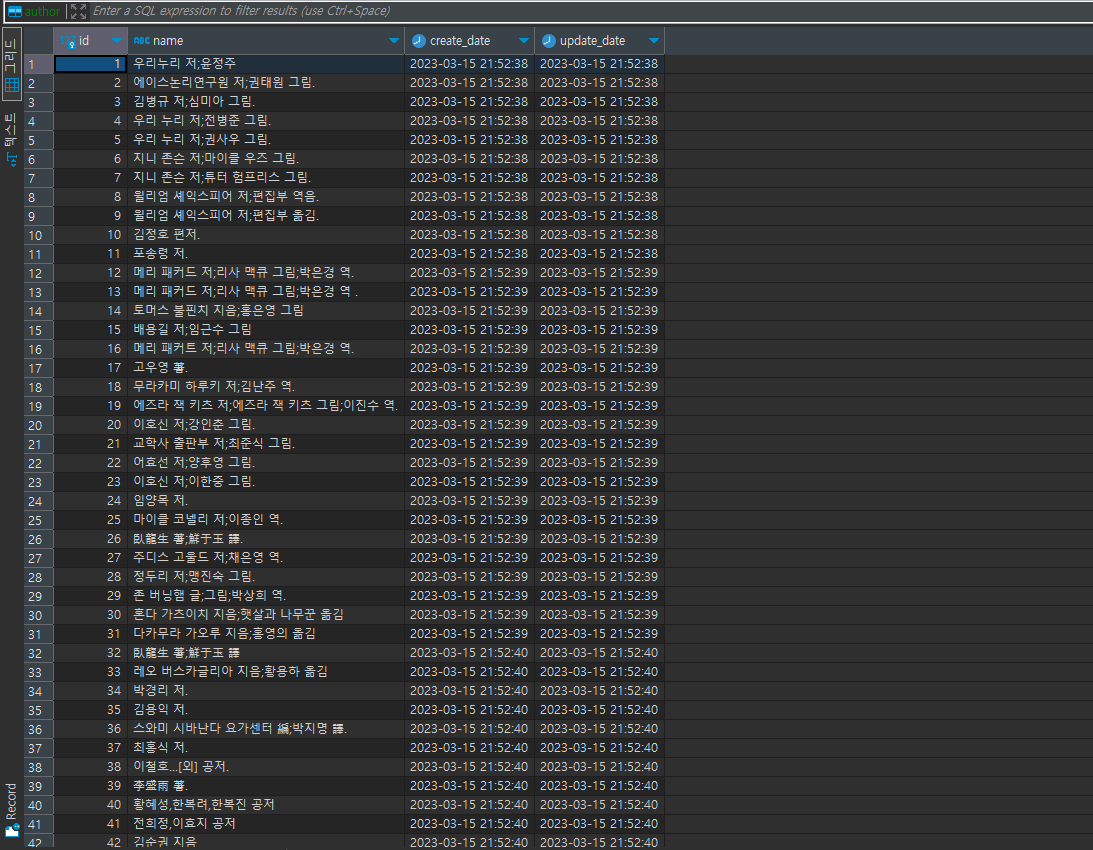
<실행결과> book TABLE
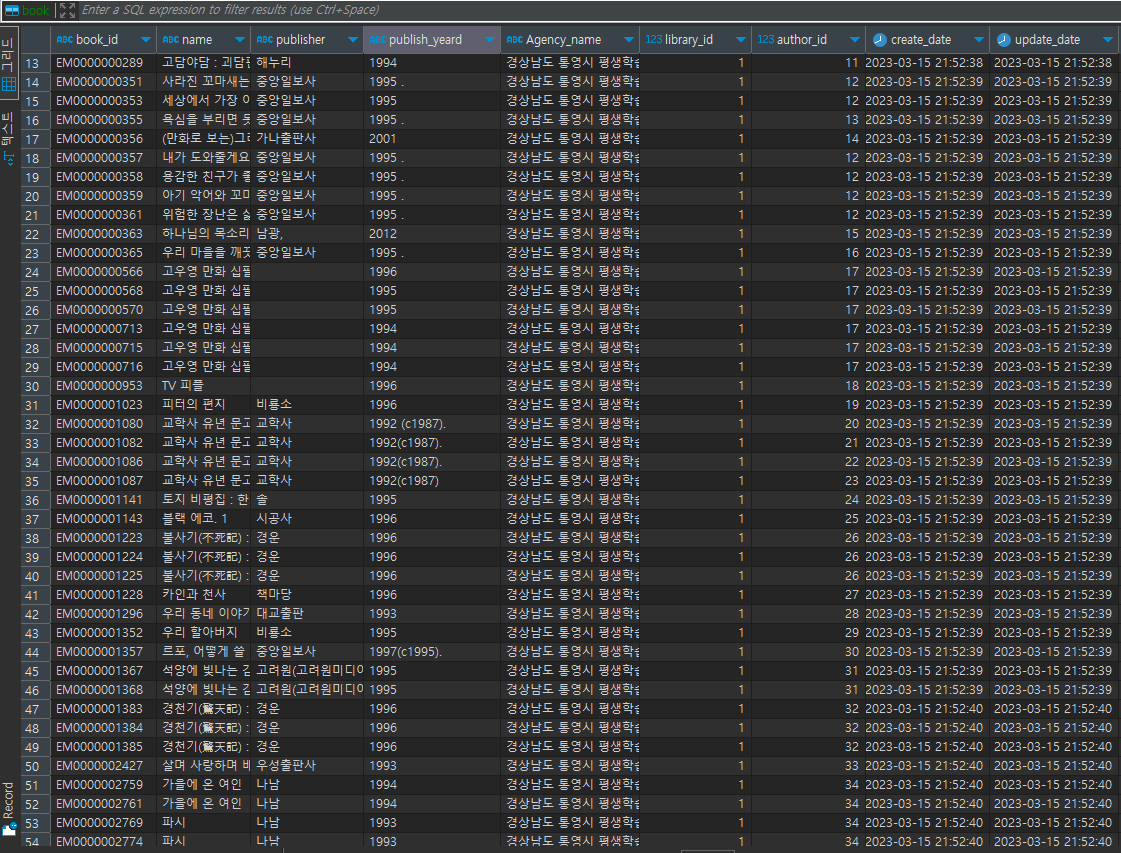

1.01^365