1. 분할정복(Divide and Conquer)이란?
그대로 해결할 수 없는 문제를 작은 문제로 분할하여 문제를 해결하는 방법이다.
Quick Sort나 Merge Sort로 대표되는 정렬 알고리즘 문제가 대표적이다.
분할 정복 알고리즘은 보통 재귀 함수(recursive function)를 통해 자연스럽게 구현된다. 예를 들면, 아래와 같이 구현할 수 있다.
function F(x):
if F(x)의 문제가 간단 then:
return F(x)을 직접 계산한 값
else:
x를 y1, y2로 분할
F(y1)과 F(y2)를 호출
return F(y1), F(y2)로부터 F(x)를 구한 값또한 여기서 작은 부문제로 분할할 경우에 부문제를 푸는 알고리즘은 임의로 선택할 수 있다. 이러한 재귀호출을 사용한 함수는 함수 호출 오버헤드 때문에 실행 속도가 늦어진다.
빠른 실행이나 부문제 해결 순서 선택을 위해, 재귀호출을 사용하지 않고 스택, 큐(queue) 등의 자료구조를 이용하여 분할 정복법을 구현하는 것도 가능하다.
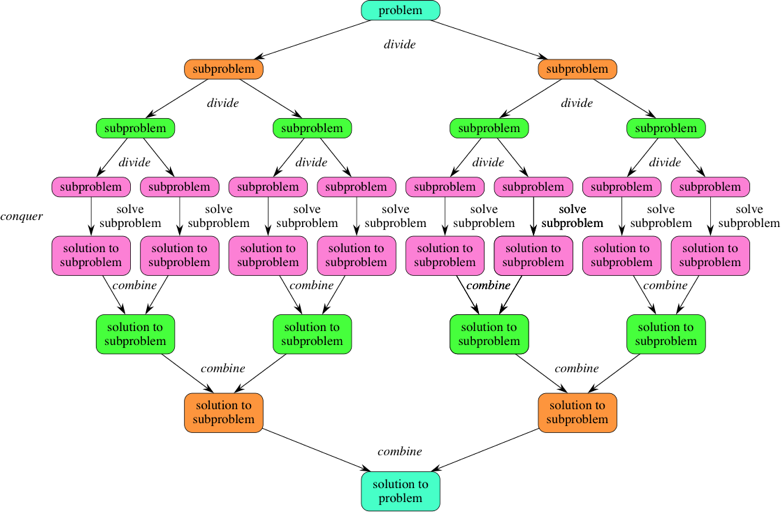
2. 분할정복 과정
- 문제 사례를 하나 이상의 작은 사례로 분할(Divide)한다.
- 작은 사례들을 각각 정복(Conquer)한다. 작은 사례가 충분히 작지 않은 이상 재귀를 사용한다.
- 필요하다면, 작은 사례에 대한 해답을 통한(Combine)하여 원래 사례의 해답을 구한다.
3. 분할정복의 장단점
장점
문제를 나눔으로써 어려운 문제를 해결할 수 있다는 엄청나게 중요한 장점이 있다. 그리고 이 방식이 그대로 사용되는 효율적인 알고리즘들도 여럿 있으며, 문제를 나누어 해결한다는 특징상 병력적으로 문제를 해결하는 데 큰 강점이 있다.
단점
함수를 재귀적으로 호출한다는 점에서 함수 호출로 인한 오버헤드가 발생하며, 스택에 다양한 데이터를 보관하고 있어야 하므로 스택 오버플로우가 발생하거나 과도한 메모리 사용을 하게 되는 단점
4. 예시(1부터 n까지의 합)
int consecutive_sum(start, end){
if(start == end) return start;
mid = (start + end) / 2;
return consecutive_sum(start, mid) + consecutive_sum(mid + 1, end);
}
# 출력
System.out.println(consecutive_sum(1, 100))
# 결과 값
5050- Divide: 1 ~ n까지의 합을 절반 씩 나눈다.
- Conquer: 절반씩 나눈 것들의 합을 구한다.
- Combine: Conquer에서 구한 값들을 모두 합친다.
분할정복을 활용한 알고리즘은 퀵 정렬, 이진 탐색(이분 탐색), 병합 정렬 등이 있다.
