4. 이진탐색트리 연산
1. 삽입
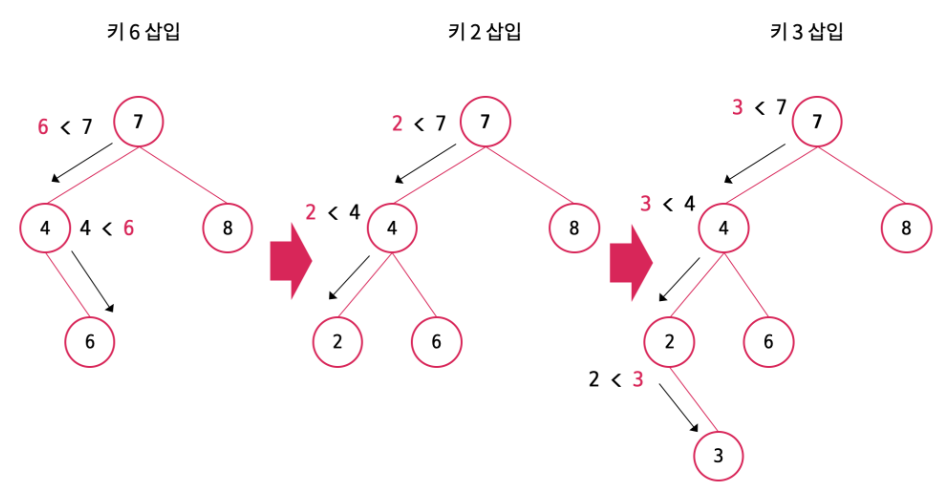
- 루트 노드가 존재하지 않는 처음 삽입인 경우 단순히 해당 노드를 루트 노드로 설정하면 된다.
- 루트 노드가 존재하는 경우 이진 탐색 트리의 규칙인 왼쪽 노드는 자신보다 작고 오른쪽 노드는 자신보다 크다는 특징을 이용하여 루트 노드부터 시작하여 삽입할 노드가 더 작으면 왼쪽 자식 노드로 보내고 더 크면 오른쪽 자식노드로 보낸다. 이를 더 이상의 이동이 필요 없을 때 까지 반복한다.
삽입 연산은 Node를 return하는 재귀적인 구조인데 마지막까지 반복한 경우 삽입할 노드를 return하고 그렇지 않은 경우 삽입할 노드와 비교한 노드를 return한다. 재귀적인 구조라 글로 쓰면 복잡해 보이지만 코드로 보면 그리 복잡하지는 않다.
재귀적인 구조의 장단점
- 장점: 코드 구현이 간단하다는 것이다.
- 단점: 함수를 여러 번 호출하여 스택에 할당되기에 반복문으로 작성한 코드에 비해 성능이 떨어진다.
public void add(int key) {
Node newNode = new Node();
newNode.key = key;
if (root == null) {
root = newNode;
} else {
root = addNode(root, newNode);
}
}
private Node addNode(Node node, Node newNode) {
if (node == null)
return newNode;
else if (node.key > newNode.key)
node.left = addNode(node.left, newNode);
else
node.right = addNode(node.right, newNode);
return node;
}2. 삭제
case 1) Leaf Node 삭제
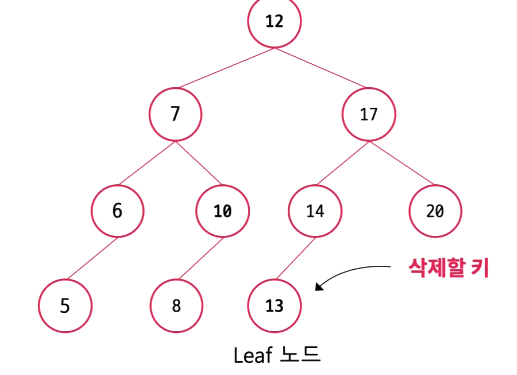
Leaf 노드의 부모 노드가 해당 Leaf 노드와의 연결을 끊어 주면 된다.
case2) 중간 Node 삭제
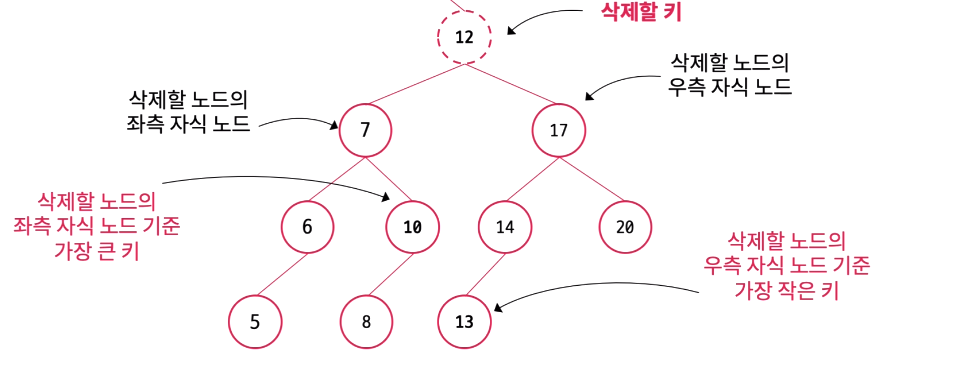
중간 노드를 삭제한다면 전체적인 이진 탐색 트리의 구조가 무너지기 때문에 삭제할 노드를 대체할 노드를 찾아 이진 탐색 트리의 구조에 맞게 해당 위치로 옮겨야 한다. 실제 구현시에는 노드를 정말 옮기는 것은 아니고 단지 두 노드의 key값을 바꾼다.
key 값을 대체할 노드는 삭제한 노드의 키 기준 왼쪽 서브트리의 가장 오른쪽에 있는 노드 또는 오른쪽 서브트리의 가장 왼쪽에 있는 노드이다. 서브트리가 하나만 있으면 해당 서브트리에서 대체 노드를 찾으면 되며 두 개의 서브트리가 있다면 어느 쪽의 서브트리에서 대체 노드를 찾아도 무방하다.
왼쪽 서브트리의 가장 오른쪽에 있는 노드 = 해당 서브트리에서 가장 큰 값
오른쪽 서브트리의 가장 왼쪽에 있는 노드 = 해당 서브트리에서 가장 작은 값
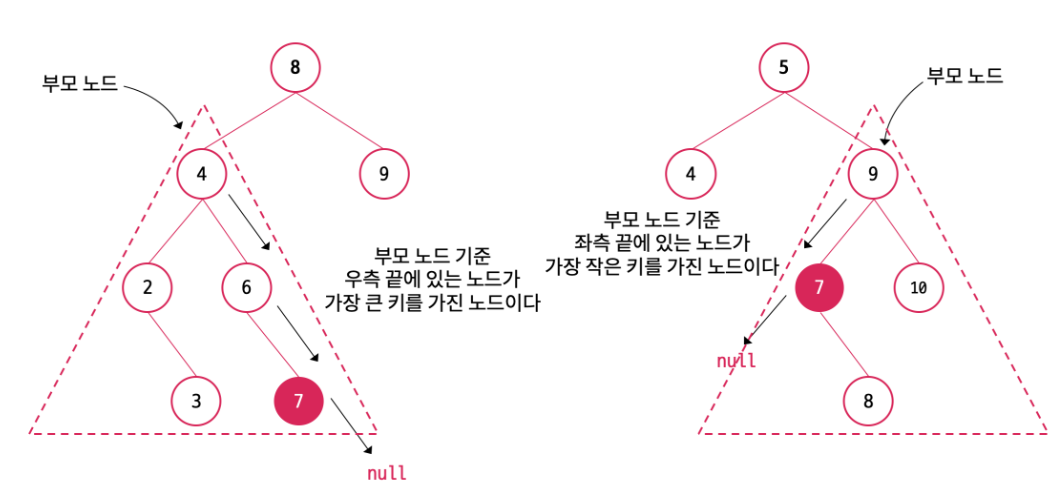
결국 삭제한 노드 기준 가장 가까운 값을 키로 갖는 노드를 대체함으로써 노드의 이동을 최소화하면서 전체 이진 탐색 트리의 구조를 유지하는 것이다.
key값을 바꿔 삭제할 노드가 옮겨진 위치의 서브트리에 대해 삭제할 노드가 단말 노드가 될 때까지 재귀적으로 반복한다. 어떻게 보면 분할 정복(Divide and Conquer)에 해당되는데 위에서 살펴본 경우1. leaf node 삭제의 연산은 간단했다. 따라서 복잡한 경우2. 중간 노드를 삭제를 간단한 경우1.로 만들어 해결하는 것이다.
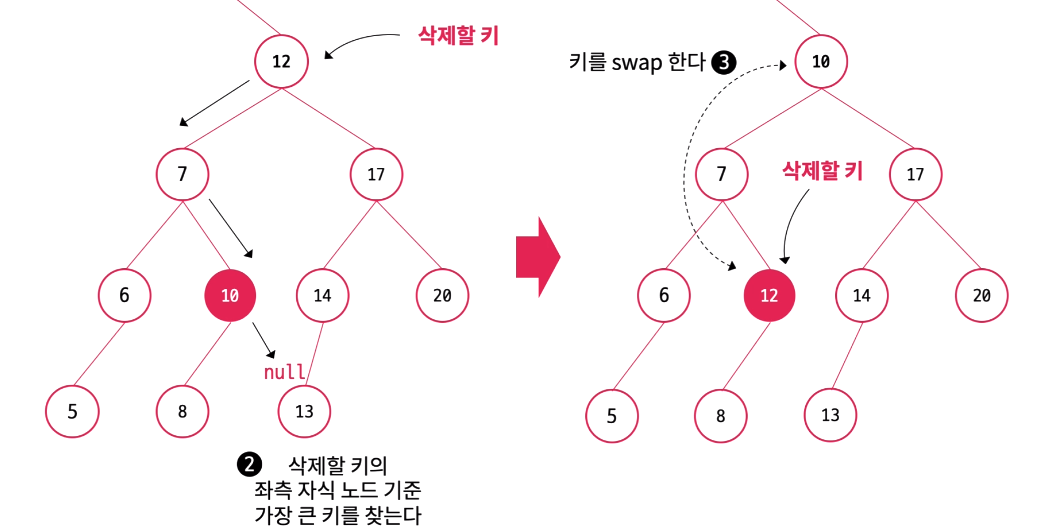
구체적인 삭제 방법은 다음과 같다. 그림은 왼쪽 서브트리의 가장 오른쪽에 있는 노드로 삭제할 노드를 대체하고 있다.
구체적인 구현 방법은 다음과 같다
- 삭제할 노드를 찾는다
- 삭제할 노드 기준 왼쪽(or 오른쪽) 서브트리의 가장 오른쪽에 있는 노드(=해당 서브트리에서 가장 큰 노드)를 찾는다.
- 삭제할 노드와 대체할 노드의 위치를 변경한다(key 값만 바꾼다. 그래야 두 노드와 연결된 다른 노드들과의 관계를 유지하기 때문)
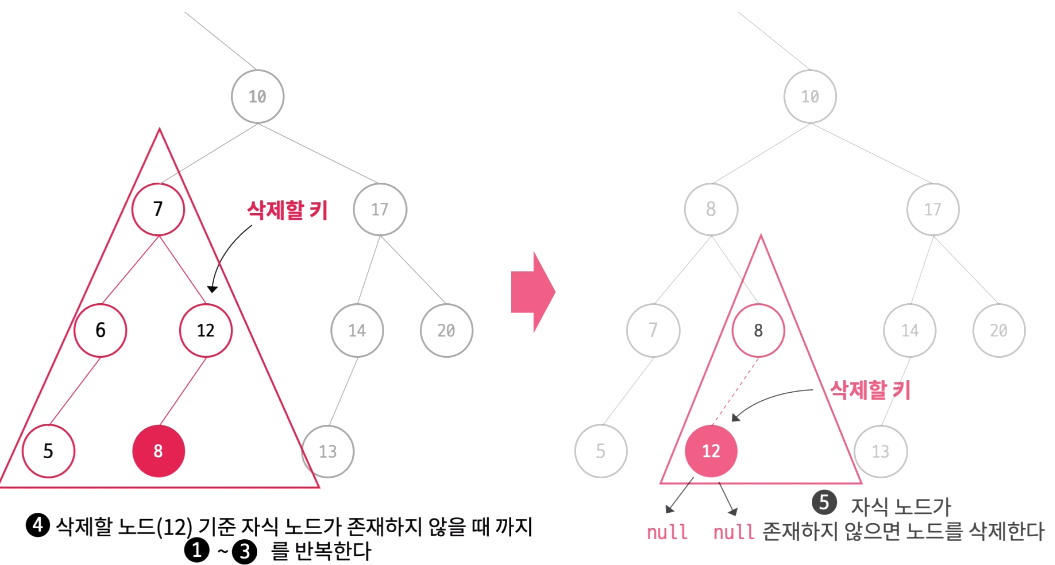
- 위치가 변경된 삭제할 노드를 기준으로 삭제할 노드가 leaf node가 될 때까지 1~3을 반복한다.
- 삭제할 노드가 단말 노드(leaf node)가 되었다면 삭제할 노드의 부모 노드는 삭제할 노드와의 연결을 끊는다. (Java의 Garbage Collector가 더 이상 참조되니 않는 삭제할 노드의 메모리를 해제한다.)
public void remove(int key) {
root = removeNode(root, key);
}
private Node removeNode(Node node, int key) {
if (node == null)
throw new RuntimeException("해당 값을 가진 노드를 찾을 수 없습니다.");
if (node.key > key)
node.left = removeNode(node.left, key);
else if (node.key < key) {
node.right = removeNode(node.right, key);
} else {
//삭제할 노드를 찾은 경우
if (node.left != null) {
//왼쪽 서브트리에서 가장 오른쪽에 있는 값 찾아 대체하기
Node child = findMaxNode(node.left);
int removedKey = node.key;
node.key = child.key;
child.key = removedKey;
//다시 옮겨진 위치에서 서브트리에 대해 재귀적으로 실행
node.left = removeNode(node.left, key);
} else if (node.right != null) {
//오른족 서브트리에서 가장 왼쪽에 있는 값 찾아 대체하기
Node child = findMinNode(node.right);
int removedKey = node.key;
node.key = child.key;
child.key = removedKey;
//다시 옮겨진 위치에서 서브트리에 대해 재귀적으로 실행
node.right = removeNode(node.right, key);
} else {
//삭제할 노드가 단말 노드인 경우 부모 노드와의 연결 종료
return null;
}
}
return node;
}
private Node findMaxNode(Node node) {
if (node.right == null)
return node;
else
return findMaxNode(node.right);
}
private Node findMinNode(Node node) {
if (node.left == null)
return node;
else
return findMinNode(node.left);
}3. 순회 및 탐색
순회는 처음부터 끝까지 전체 노드에 접근하는 것이고 탐색은 순회를 하다 특정 값을 찾으면 순회를 멈추는 것이기에 결국 순회와 탐색은 동일한 논리 구조를 갖는다. 따라서 순회와 탐색을 별도로 구분하지 않고 같이 알아본다.
중위 순회를 쓰는 이유
이진 트리 순회에는 크게는 3가지 방법이 있으며 3가지 방법 모두 재귀적인 방법으로 구현된다.
1. 전위 순회(preorder traversal)
2. 중위 순회(inorder traversal)
3. 후위 순회(postorder traversal)
- 전위 순회 : 부모 노드 => 왼쪽 서브트리 => 오른쪽 서브트리
- 중위 순회 : 왼쪽 서브트리 => 부모 노드 => 오른쪽 서브트리
- 후위 순회 : 왼쪽 서브트리 => 오른족 서브트리 => 부모 노드
3가지 순회 방법중 이진 탐색 트리의 순차적 탐색을 위한 순회에는 중위 순회가 가장 적절하다. 이는 이진 탐색 트리가 부모 노드 기준 왼쪽 자식 노드는 값이 작고 오른쪽 자식 노드는 값이 크다는 성질을 갖고 있기 때문이다.
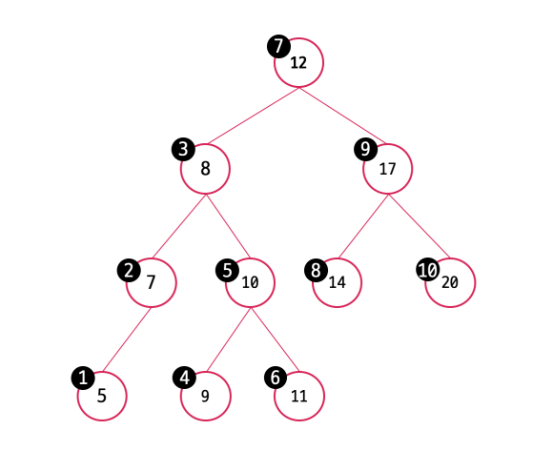
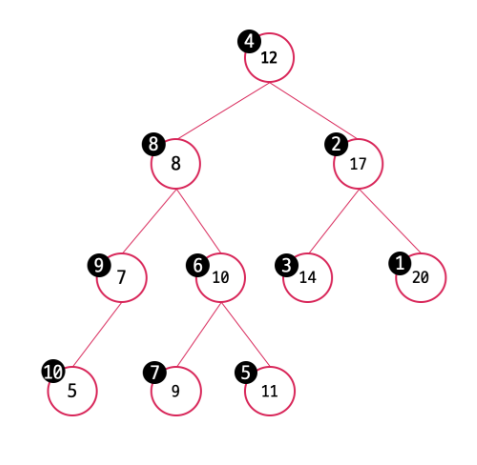
중위 순회도 왼쪽 서브트리, 오른쪽 서브트리 중 어떤 트리를 먼저 순회할 것인가에 따라 좌측 중위 순회, 우측 중위 순회로 나뉜다. 좌측 중위 순회는 왼쪽 서브트리를 먼저, 우측 중위 순회는 오른쪽 서브트리를 먼저 탐색하는 중위 순회이다. 단순히 서브트리의 탐색 순서를 바꾼 것 같지만 이 탐색순서로 내림차순 탐색 혹은 오름차순 탐색이 결정된다.
-
좌측 중위 순회 => 오름차순 순회
-
우측 중위 순회 => 내림차순 순회
public void search(int key) {
searchNode(root, key);
}
private Node searchNode(Node node, int key) {
if (node == null)
throw new RuntimeException("해당 값을 가진 노드를 찾을 수 없습니다.");
if (node.key > key)
node.right = searchNode(node.right, key);
else if (node.key < key)
node.left = searchNode(node.left, key);
else
System.out.println("해당 값을 가진 노드를 찾았습니다.");
return node;
}
public void descendingTraversal() {
//내림차순 순회
System.out.print("내림차순 순회: ");
rightInorderTraversal(root);
System.out.println();
}
private void rightInorderTraversal(Node node){
//우측 중위 순회
if(node == null)
return;
rightInorderTraversal(node.right);
System.out.printf("%d ", node.key);
rightInorderTraversal(node.left);
}
public void ascendingTraversal() {
//오름차순 순회
System.out.print("오름차순 순회: ");
leftInorderTraversal(root);
System.out.println();
}
private void leftInorderTraversal(Node node) {
//좌측 중위 순회
if(node == null)
return;
leftInorderTraversal(node.left);
System.out.printf("%d ", node.key);
leftInorderTraversal(node.right);
}