5. 해시 함수
해시 함수는 임의의 길이를 갖는 메시지를 입력받아서 고정된 길이의 해시값을 출력하는 함수다. 해시 함수에서 중요한 것은 고유한 인덱스 값을 설정하는 것이다. 해시 테이블에 사용되는 대표적인 해시 함수로는 아래의 3가지가 있다.
- Division Method: 나눗셈을 이용하는 방법으로 입력값을 테이블의 크기로 나누어 계산한다.( 주소 = 입력값 % 테이블의 크기) 테이블의 크기를 소수로 정하고 2의 제곱수와 먼 값을 사용해야 효과가 좋다고 알려져 있다.
- Digit Folding: 각 Key의 문자열을 ASCII 코드로 바꾸고 값을 합한 데이터를 테이블 내의 주소로 사용하는 방법이다.
- Multiplication Method: 숫자로 된 Key값 K와 0과 1사이의 실수 A, 보통 2의 제곱수인 m을 사용하여 다음과 같은 계산을 해준다. h(k)=(kAmod1) × m
- Univeral Hashing: 다수의 해시함수를 만들어 집합 H에 넣어두고, 무작위로 해시함수를 선택해 해시값을 만드는 기법이다.
6. 해시 값 충돌
해시 값우 충돌하는 경우
해시 충돌이 1도 없는 해시 함수를 만드는 것은 불가능하다. 따라서 해시 충돌에 대해 안전하다는 해시 함수는 '충돌을 찾는 게 거~의 희박하다'라는 뜻이다. 이 해시 충돌이 발생하는 근본적인 원인은 비둘기집 원리다. (비둘기집 원리란 n+1개의 물건을 n개의 상자에 넣을 때 적어도 어느 한 상자에는 두 개 이상의 물건이 들어 있다는 원리를 말한다.) 즉 해시 함수가 무한한 가짓수의 입력값을 받아 유한한 가짓수의 출력값을 생성하는 경우에는 비둘기집 원리에 의해 해시 충돌은 항상 존재한다. 따라서 해시 테이블의 충돌을 완화하는 방향으로 문제를 보완해야 한다. 해시 테이블에서는 충돌에 의한 문제를 분리 연결법(Separate Chaining) 과 개방 주소법(Open Addressing) 크게 2가지로 해결하고 있다.
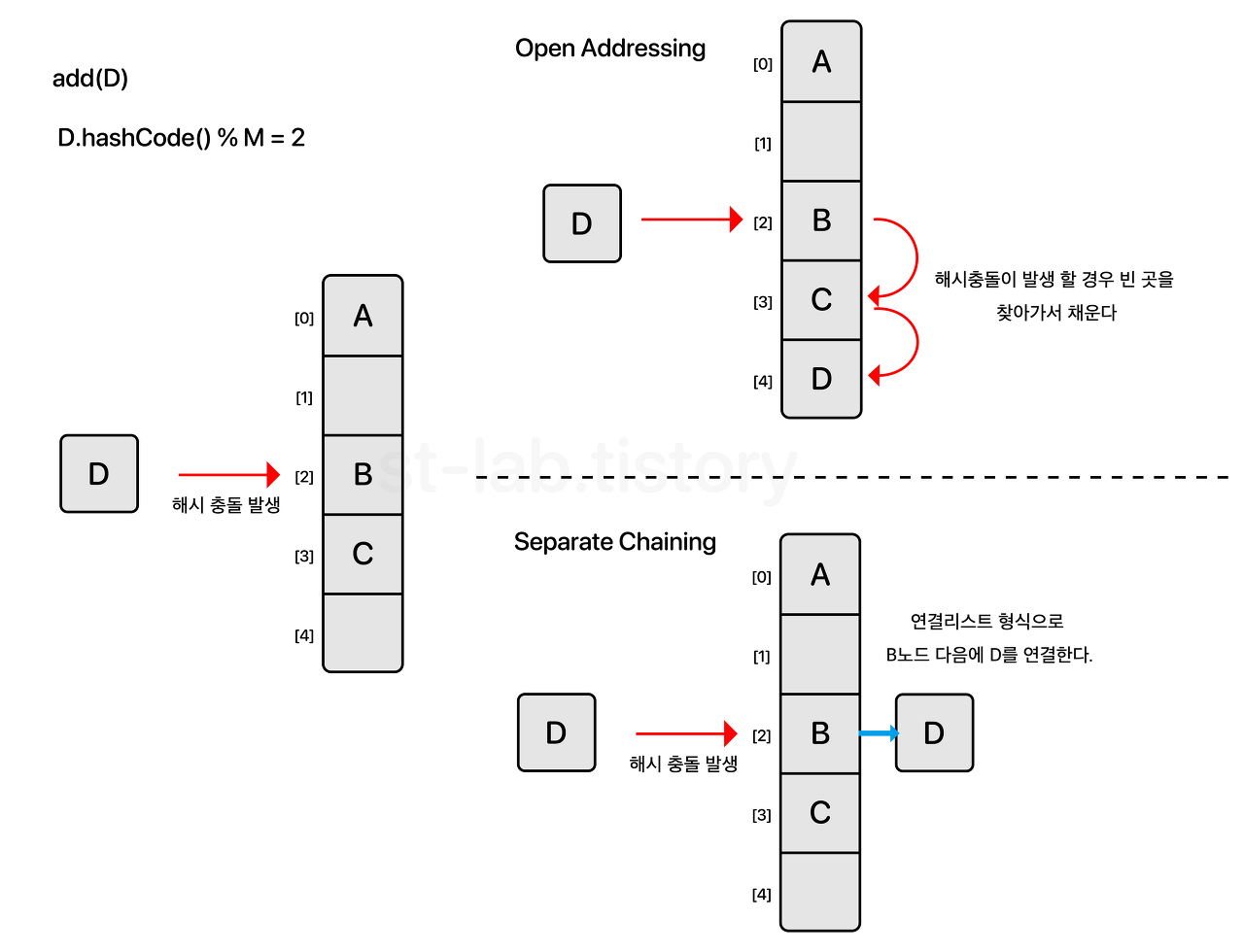
1. 개방 주소법(Open Addressing)
한 버킷 당 들어갈 수 있는 엔트리는 하나이지만 해시 함수로 얻은 주소가 아닌, 다른 주소에 데이터를 저장할 수 있도록 허용하는 방법이다. 하지만 이 방법은 부하율(load factor)이 높을 수록(= 테이블에 저장된 데이터의 밀도가 높을수록) 성능이 급격히 저하된다. 개방 주소법의 주요 목적은 저장할 엔트리를 위한 다음의 slot을 찾는 것인데 이 방법으로 2가지가 널리 쓰인다.
1. 선형 탐사법(Linear Porbing)
말 그대로 가장 간단하게 선형으로 순차적 검색을 하는 방법이다. 해시 함수로 나온 해시 index에 이미 다른 값이 저장되어 있다면, 해당 해시값에서 고정 폭을 옮겨 다음 해시값에 해당하는 버킷에 액세스한다. 여기에 또 다른 데이터가 있다면 또 다시 고정폭으로 이동해 액세스한다.
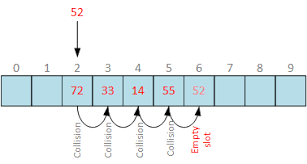
이 경우에는 특정 해시 값의 주변이 모두 채워져 있는 일차 군집화(primary clustering) 문제에 취약하다. 예를 들어 모든 키가 100이라는 해시값으로 매핑이 될 경우 충돌을 100%가 된다.
따라서 해시 충돌이 해시 값 전체에 균등하게 발생할 때 유용한 방법이다.
2. 제곱 탐사법(Quadratic Probing)
선형 탐사법과 동일한데, 고정폭이 아니라 제곱으로 늘어난다. 따라서 2^1, 2^2, 2^3로 이동해서 데이터를 할당한다.
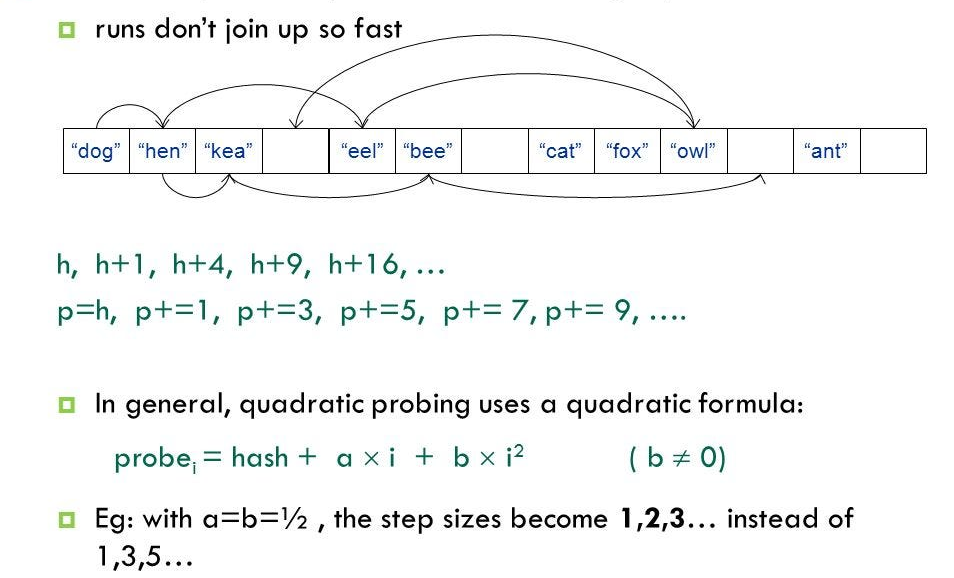
따라서 제곱 탐사법을 이용한 경우 데이터의 밀집도가 선형 탐사법보다 낮기 때문에 다른 해시값까지 영향을 받아서 연쇄적으로 충돌이 발생할 가능성이 적다. 하지만 선형 탐사법보다는 캐시의 성능이 떨어져서 속도의 문제가 발생한다.
3. 이중 해싱(Double Hashing)
이 방법은 탐사할 해시값의 규칙값을 없애서 클러스터링을 방지한다. 즉 해시 함수를 이중으로 사용하는데, 하나는 최초의 해시값을 얻을 때, 다른 하나는 해시 충돌이 일어났을 때 탐사 이동폭을 얻기 위해 사용한다. 이렇게 되면 최초 해시값이 같더라도 탐사 이동폭이 달라지고, 탐사 이동폭이 같더라도 최초 해시값이 달라져 위의 두 방법을 모두 완화할 수 있다.
2. 분리 연결법(Seperate Chaining)
분리 연결법은 개방 주소법과는 달리 한 버킷(슬롯) 당 들어갈 수 있는 엔트리의 수에 제한을 두지 않는다. 이때 버킷에는 링크드 리스트(linked list)나 트리(tree)를 사용한다.
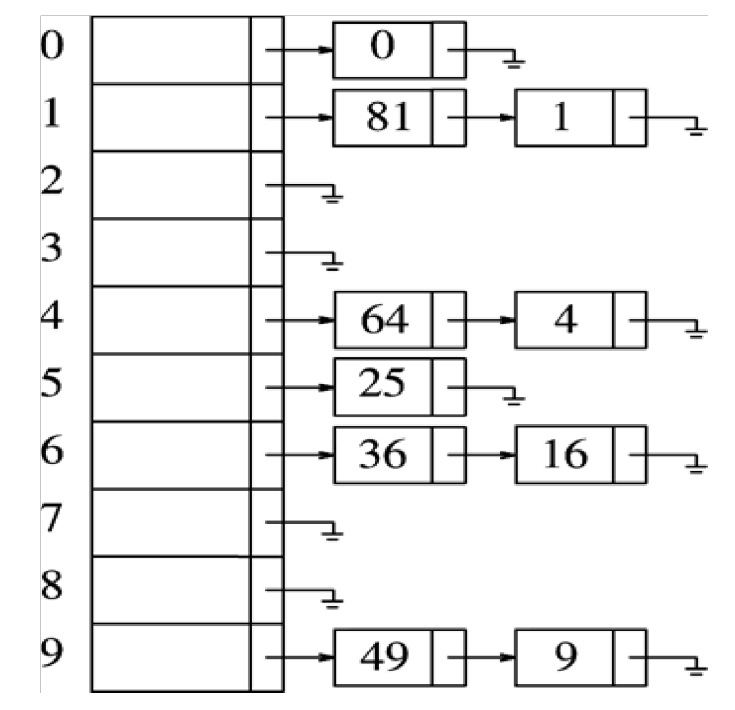
해시 충돌이 일어나더라도 linked list로 노드가 연결되기 때문에 index가 변하지 않고 데이터 개수의 제약이 없다는 장점이 있다. 하지만 메모리 문제를 야기할 수 있으며, 테이블의 부하율에 따라 선형적으로 성능이 저하된다. 따라서 부하율이 작을 경우에는 open addressing 방식이 빠르다.
7. 해시 테이블 사용
해시 맵을 사용하고 싶으면 'Hashtable' 대신 'HashMap'을 쓰면 된다.
1. 해시 테이블 선언
import java.util.Hashtable;
public class HashTableDemo {
public static void main(String[] args) {
Hashtable ht = new Hashtable(); // 타입 설정x Object 설정
Hashtable<Integer, Integer> i = new Hashtable<Integer, Integer>(); // Integer, Integer 타입 선언
Hashtable<Integer, Integer> i2 = new Hashtable<>(); // new는 타입 생략 가능
Hashtable<Integer, Integer> i3 = new Hashtable<Integer, Integer>(i); // i의 Hashtable을 i3으로 값 이전
Hashtable<Integer, Integer> i4 = new Hashtable<Integer, Integer>(10); // 초기용량 지정
Hashtable<Integer, Integer> i5 = new Hashtable<Integer, Integer>() {{ // 변수 선언 + 초기값 지정
put(1, 100);
put(2, 200);
}};
Hashtable<String, String> str = new Hashtable<String, String>(); // String, String 타입 선언
Hashtable<Character, Character> ch = new Hashtable<Character, Character>(); // Char, Char 타입 선언
}
}2. 해시 테이블 값 추가
import java.util.Hashtable;
public class HashTableDemo {
public static void main(String[] args) {
Hashtable<String, String> ht = new Hashtable<String, String>(); // Hashtable 선언
// 값 추가
ht.put("1", "Hello1");
ht.put("2", "World2");
ht.put("3", "Hello3");
ht.put("4", "World4");
ht.put("2", "WorldWorld2");
System.out.println(ht); // 결과출력
}
}
put() 메서드를 사용하여 Key가 같고 Value가 다른 값을 중복해서 넣으면 나중에 넣은 Value값으로 변경된다.
3. 해시 테이블 값 삭제
import java.util.Hashtable;
public class HashTableDemo {
public static void main(String[] args) {
Hashtable<String, String> ht = new Hashtable<String, String>(); // Hashtable 선언
// 값 추가
ht.put("1", "Hello1");
ht.put("2", "World2");
ht.put("3", "Hello3");
ht.put("4", "World4");
System.out.println(ht); // 결과출력
ht.remove("2");
System.out.println(ht); // 결과출력
ht.clear();
System.out.println(ht); // 결과출력
}
}
remove(Key값) 메서드는 Key값에 해당하는 값을 하나 삭제, clear() 메서드는 HashTable의 모든 값을 삭제할 때 사용한다.
4. 해시 테이블 크기 구하기
import java.util.Hashtable;
public class HashTableDemo {
public static void main(String[] args) {
Hashtable<String, String> ht = new Hashtable<String, String>(); // Hashtable 선언
// 값 추가
ht.put("1", "Hello1");
ht.put("2", "World2");
ht.put("3", "Hello3");
ht.put("4", "World4");
System.out.println(ht); // 결과출력
System.out.println("Size : " + ht.size());
}
}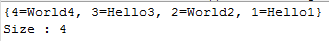
5. 해시 테이블 값 출력
HashTable의 값을 출력하는 방법은 여러가지가 있다. 그 중에서 두 가지 방법을 설명하자면 향상된 for문과 Iterator클래스를 사용한 방법이 있다.
1. 향상된 for 문
import java.util.Hashtable;
import java.util.Map;
public class HashTableDemo {
public static void main(String[] args) {
Hashtable<String, String> ht = new Hashtable<String, String>(); // Hashtable 선언
// 값 추가
ht.put("1", "Hello1");
ht.put("2", "World2");
ht.put("3", "Hello3");
ht.put("4", "World4");
/* 향상된for문을 사용하여 HashTable의 값을 출력 */
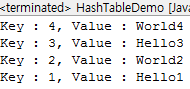
for(Map.Entry<String, String> e : ht.entrySet())
System.out.println("Key : " + e.getKey() + ", Value : " + e.getValue());
}
}
entrySet을 사용하여 HashTable을 Map클래스의 Entry타입으로 변경을 해준다.
Entry의 메서드 getKey()와 getValue()를 사용하여 Key값과 Value값을 가져와 반복해서 출력한다.
2. Iterator 방식 사용
import java.util.Hashtable;
import java.util.Iterator;
import java.util.Map;
import java.util.Map.Entry;
public class HashTableDemo {
public static void main(String[] args) {
Hashtable<String, String> ht = new Hashtable<String, String>(); // Hashtable 선언
// 값 추가
ht.put("1", "Hello1");
ht.put("2", "World2");
ht.put("3", "Hello3");
ht.put("4", "World4");
Iterator<Entry<String, String>> iter = ht.entrySet().iterator();
while(iter.hasNext())
{
Map.Entry<String, String> entry = iter.next();
System.out.println("Key : " + entry.getKey() + ", Value : " + entry.getValue());
}
System.out.println("-----------------------------");
Iterator<String> iter2 = ht.keySet().iterator();
while(iter2.hasNext())
{
String key = iter2.next();
System.out.println("Key : " + key + ", Value : " + ht.get(key));
}
}
}
Iterator를 Entry로 선언하여 위의 향상된 for문처럼 entrySet()의 iterator() 방식으로 가져온다.
예제의 두 번째 방법은 Iterator를 String타입으로 선언하여 HashTable의 키 값을 iterator형태로 집어넣는다.
String을 반복하여 String의 Key값에 해당하는 Value를 반복해서 출력한다.
6. 해시 테이블 key 존재 여부
public boolean containsKey(Object key)를 통해 해당 key가 존재하는지 알 수 있다. 있으면 true, 없으면 false를 반환한다.
import java.util.HashMap;
import java.util.Map;
public class CheckExistHashMap {
public static void main(String[] args) {
// HashMap 준비
Map<Integer, String> map = new HashMap<Integer, String>();
map.put(1, "Apple");
map.put(2, "Banana");
map.put(3, "Orange");
map.put(null, "Tomato");
// 특정 key값 존재여부 체크 (containsKey())
System.out.println(map.containsKey(1)); // true
System.out.println(map.containsKey(5)); // false
System.out.println(map.containsKey(null)); // true
}
}