마이크로미터 소개
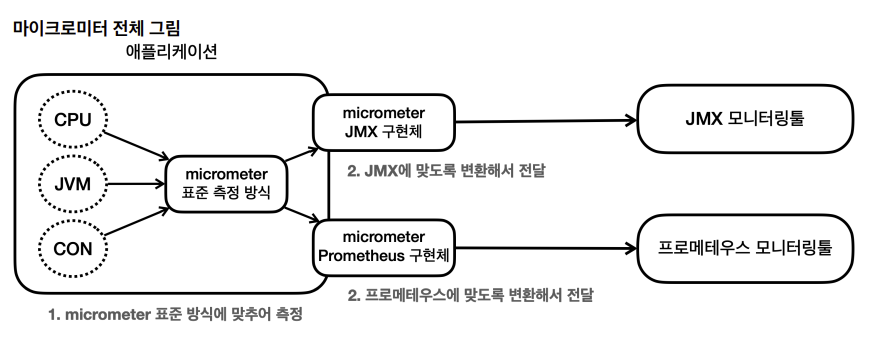
서비스를 운영할 때는 애플리케이션의 CPU, 메모리, 커넥션 사용, 고객 요청수 같은 수 많은 지표들을 확인하는 것이 필요하다. 그래야 문제가 발생하기 전에 미리 대응을 할 수 있고, 문제 발생시 발빠른 대처가 가능해진다.
이러한 모니터링 툴을 작동하려면 다양한 지표들을 각각의 모니터링 툴에 맞도록 보내주어야 한다. 이때 애플리케이션의 메트릭(측정 지표)을 마이크로미터가 정한 표준 방법으로 모아서 제공해준다.
프로메테우스와 그라파나 소개
프로메테우스
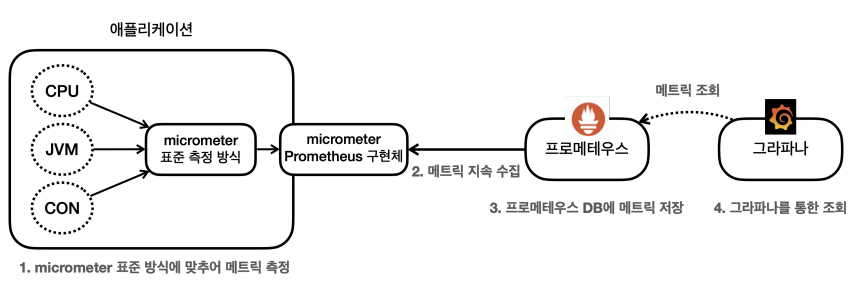
메트릭의 과거 이력까지 함께 확인하기 위해서는 보관할 DB가 필요하다. 프로메테우스는 메트릭을 지속해서 수집하고 DB에 저장하는 역할을 한다.
그라파나
프로메테우스가 DB라고 하면, 그라파나는 수집된 데이터를 보기 편하게 대시보드로 만들어주는 역할을 한다.
프로메테우스 - 애플리케이션 설정
- 애플리케이션 설정: 애플리케이션에서 프로메테우스 포멧에 맞추어 메트릭 만들기
- 프로메테우스 설정: 프로메테우스가 애플리케이션의 메트릭을 주기적으로 수집할 수 있도록 설정하기
포멧 차이
- jvm.info jvminfo : 프로메테우스는 . 대신에 포멧을 사용한다. . 대신에 _ 포멧으로 변환된 것을 확인할 수 있다.
- logback.events logback_events_total : 로그수 처럼 지속해서 숫자가 증가하는 메트릭을 카운터라 한다. 프로메테우스는 카운터 메트릭의 마지막에는 관례상 _total 을 붙인다.
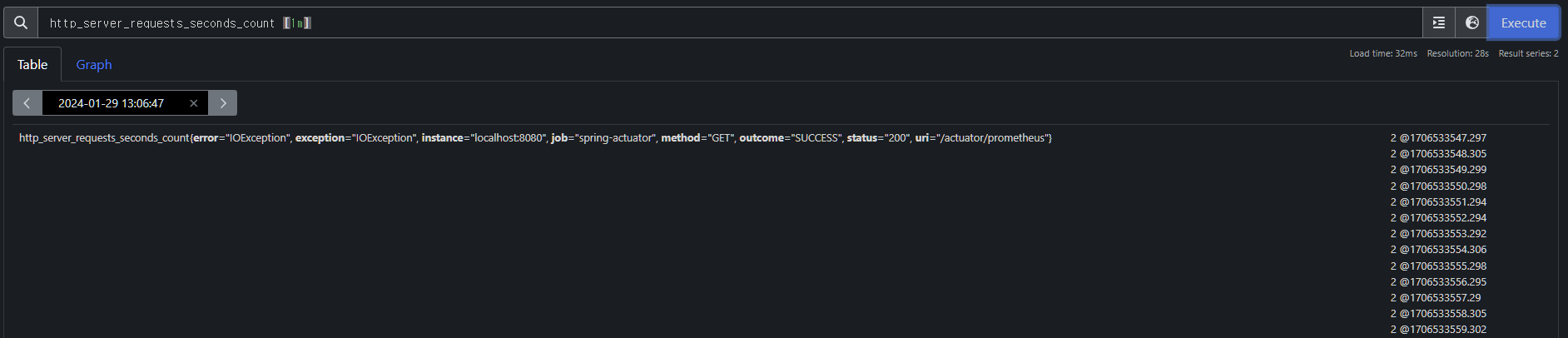
- http.server.requests 이 메트릭은 내부에 요청수, 시간 합, 최대 시간 정보를 가지고 있었다. 프로메테우스에서는 다음 3가지로 분리된다.
- http_server_requests_seconds_count : 요청 수
- http_server_requests_seconds_sum : 시간 합(요청수의 시간을 합함)
- http_server_requests_seconds_max : 최대 시간(가장 오래걸린 요청 수)
프로메테우스 - 수집 설정
prometheus.yml에 추가
#추가
- job_name: "spring-actuator"
metrics_path: '/actuator/prometheus'
scrape_interval: 1s
static_configs:
- targets: ['localhost:8080']- job_name : 수집하는 이름
- metrics_path : 수집할 경로
- scrape_interval : 수집할 주기
- targets : 수집할 서버의 IP, PORT
예제에서는 수집 주기를
1s로 했지만, 기본 값은1m이다. 수집 주기가 너무 짧으면 애플리케이션에 영향을 줄 수 있으므로 운영에서는10s ~ 1m정도를 권장한다.
프로메테우스 - 기본 기능

- 태그, 레이블: error , exception , instance , job , method , outcome , status , uri 는 각각의 메트릭 정보를 구분해서 사용하기 위한 태그이다. 마이크로미터에서는 이것을 태그(Tag)라 하고, 프로메테우스에서는 레이블(Label)이라 한다.
- 숫자: 해당 메트릭의 값
기본기능
- Table -> Evaluation time을 수정하여 과거 시간 조회 가능
- Graph -> 메트릭을 그래프로 조회
필터
중괄호{} 문법을 사용하여 필터를 사용
레이블 일치 연산자
=제공된 문자열과 정확히 동일한 레이블 선택!=제공된 문자열과 같지 않은 레이블 선택=~제공된 문자열과 정규식 일치하는 레이블 선택!~제공된 문자열과 정규식 일치하지 않는 레이블 선택
예)
- method 가 GET , POST 인 경우를 포함해서 필터
- http_server_requests_seconds_count{method=~"GET|POST"}
- /actuator 로 시작하는 uri 는 제외한 조건으로 필터
- http_server_requests_seconds_count{uri!~"/actuator.*"}
sum by
sum by(method, status)(http_server_requests_seconds_count)
SQL의 group by 기능과 유사
count
count(http_server_requests_seconds_count)
메트릭 자체의 수 카운트
topk
topk(3, http_server_requests_seconds_count)
상위 3개 메트릭 조회
오프셋 수정자
http_server_requests_seconds_count offset 10m
현재를 기준으로 특정 과거 시점의 데이터를 반환

범위 벡터 선택기
http_server_requests_seconds_count[1m]
마지막에 [1m] , [60s] 와 같이 표현한다. 지난 [시간]의 모든 기록값을 반환
프로메테우스 - 게이지와 카운터
게이지(Gauge)
- 임의로 오르내일 수 있는 값, 현재 상태를 나타내는 값
- 예) CPU 사용량, 메모리 샤용량, 사용중인 커넥션
카운터(Counter)
- 단순하게 증가하는 단일 누적 값
- 예) HTTP 요청 수, 로그 발생 수
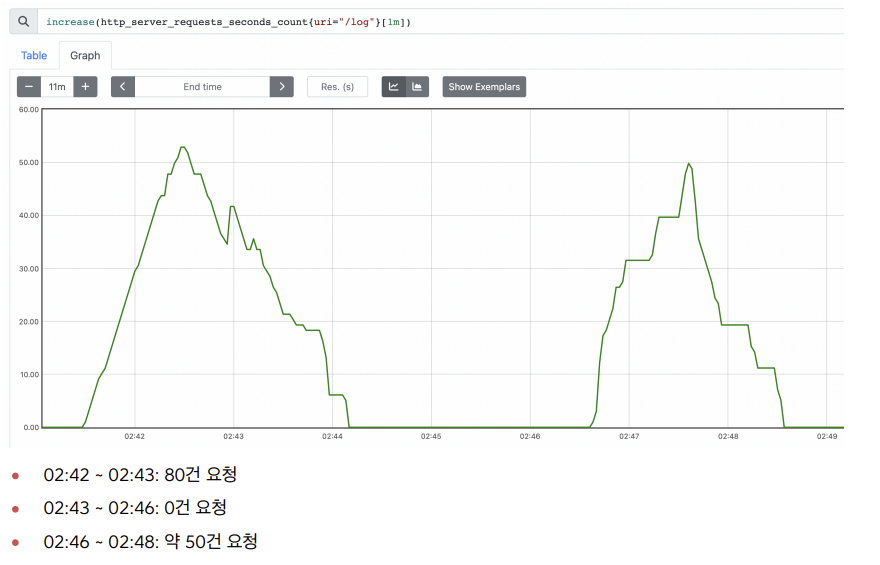
increase()
지정한 시간 단위별로 증가를 확인할 수 있다.
마지막에 [시간] 을 사용해서 범위 벡터를 선택해야 한다.
예) increase(http_server_requests_seconds_count{uri="/log"}[1m])
rate()
범위 백터에서 초당 평균 증가율을 계산한다.
increase() 가 숫자를 직접 카운트 한다면, rate() 는 여기에 초당 평균을 나누어서 계산한다.
예) rate(http_server_requests_seconds_count{uri="/log"}[1m])에서 [1m] 이라고 하면 60초가 기준이 되므로 60을 나눈 수이다.
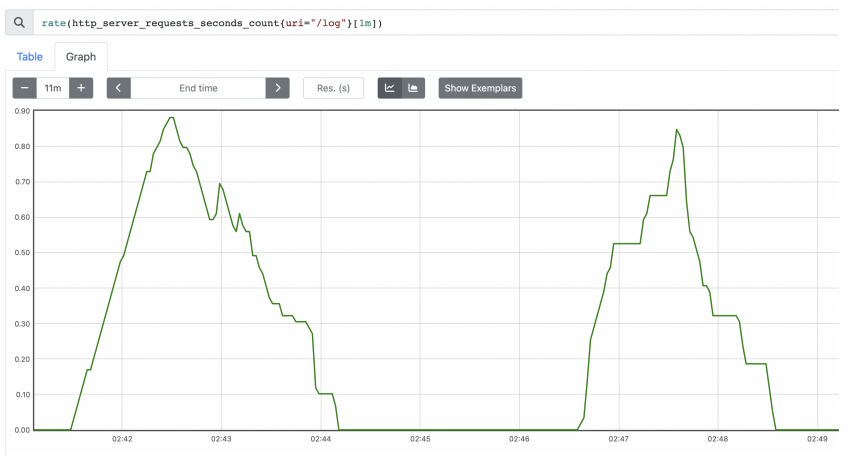
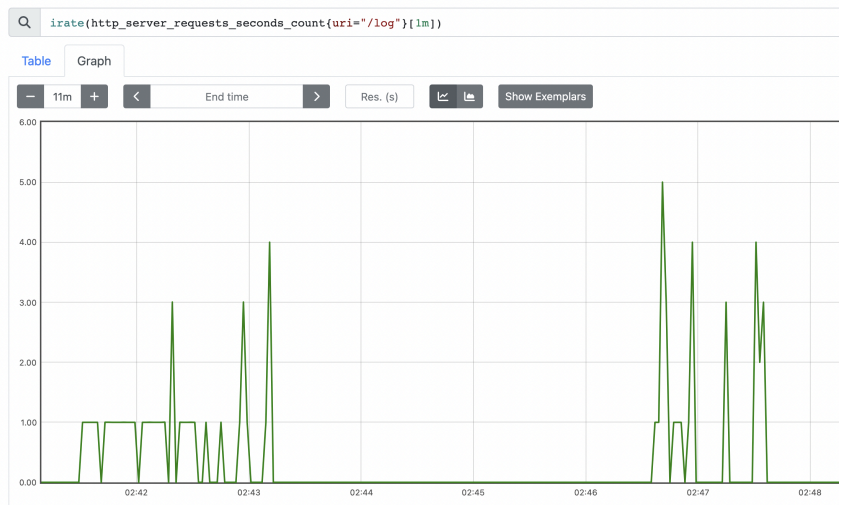
irate()
rate 와 유사한데, 범위 벡터에서 초당 순간 증가율을 계산한다. 급격하게 증가한 내용을 확인하기 좋다.
그라파나 - 연동
그라파나는 프로메테우스를 통해 데이터를 조회하고 보여주는 대시보드의 역할을 한다.
공유 대시보드 활용
https://grafana.com/grafana/dashboards
그라파나 - 메트릭을 통한 문제 확인
실무에서 주로 발생하는 다음 4가지 대표적인 예시를 확인해보자.
- CPU 사용량 초과
- JVM 메모리 사용량 초과
- 커넥션 풀 고갈
- 에러 로그 급증
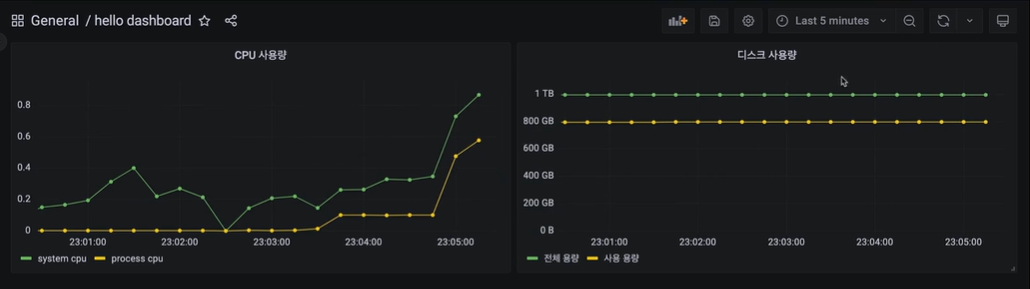
CPU 사용량 초과
@Slf4j
@RestController
public class TrafficController {
@GetMapping("/cpu")
public String cpu() {
log.info("cpu");
long value =0;
for (long i = 0; i < 100000000000L; i++) {
value++;
}
return "ok value=" + value;
}
}
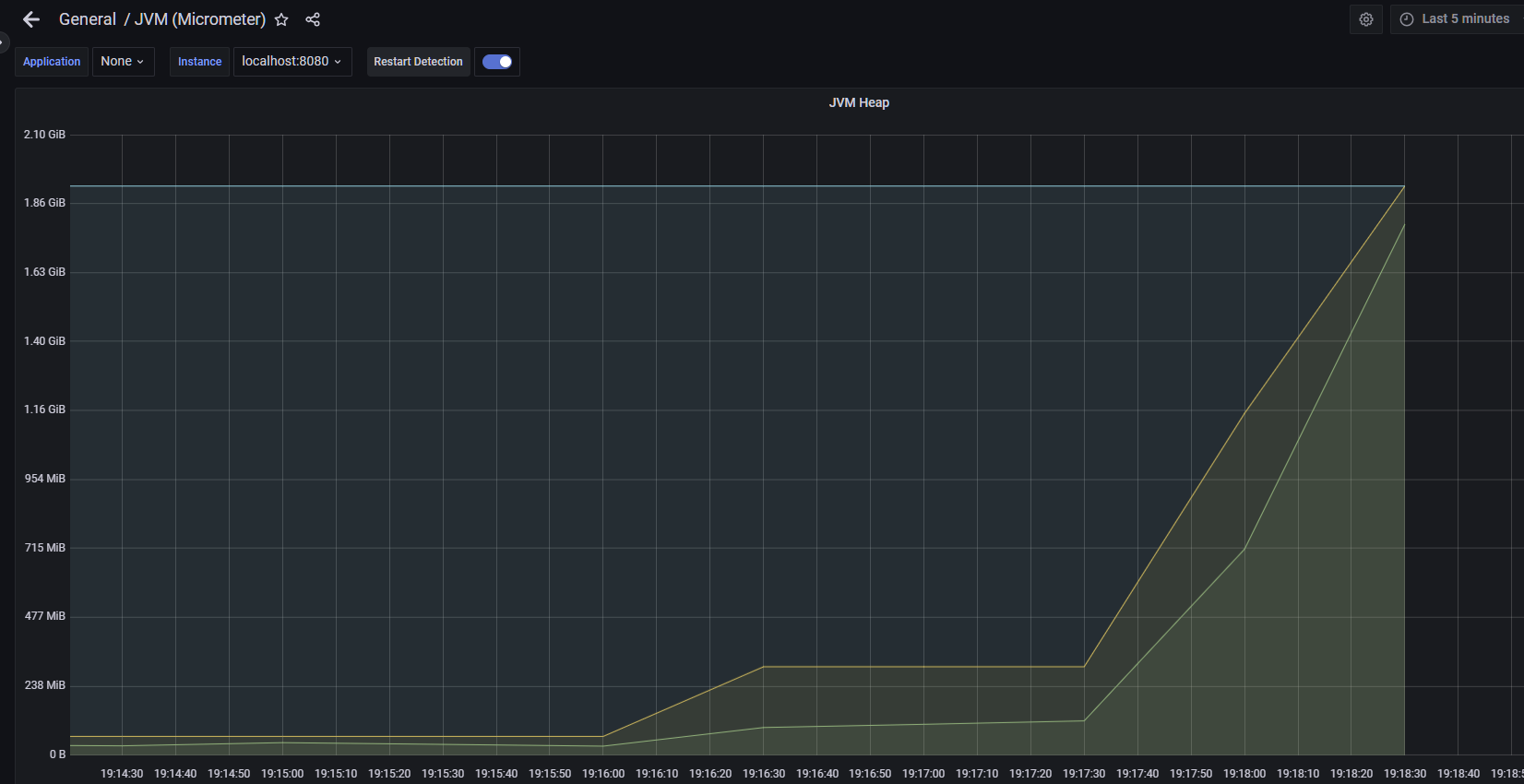
JVM 메모리 사용량 초과
private List<String> list = new ArrayList<>();
@GetMapping("/jvm")
public String jvm() {
log.info("jvm");
for (int i = 0; i < 1000000; i++) {
list.add("hello jvm!" + i);
}
return "ok";
}
커넥션 풀 고갈
@Autowired DataSource dataSource;
@GetMapping("/jdbc")
public String jdbc() throws SQLException {
log.info("jdbc");
Connection conn = dataSource.getConnection();
log.info("connection info={}", conn);
//conn.close(); //커넥션을 닫지 않는다.
return "ok";
}
에러 로그 급증
@GetMapping("/error-log")
public String errorLog() {
log.error("error log");
return "error";
}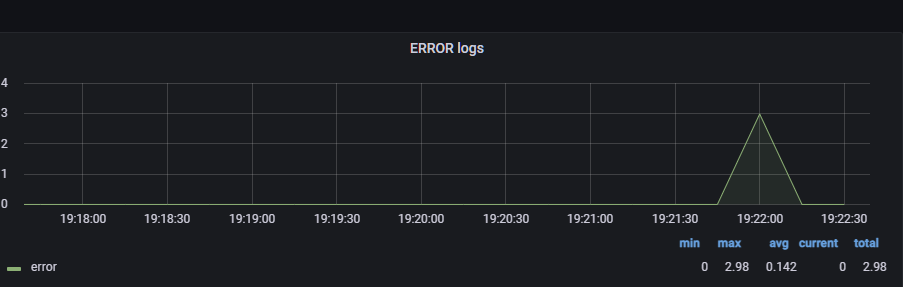
메트릭을 보는 것의 목적은 정확한 값을 보는 것이 아닌, 추세를 확인하는 것이 주 목적이다.
