
캐글에 관심사인 "교육" 관련 진행 중인 컴피티션이 있어 공유해요! 틀린 답을 보고 그에 대한 오해를 찾아내는 대회입니다. 학생들이 수학 학습을 개선하도록 돕는 온라인 교육 플랫폼 Eedi(https://eedi.com/) 데이터 셋을 기반으로 제작되었어요.
어떤 대회는?
-
학생들이 수학 문제를 풀 때, 어떤 학생들은 잘못된 방식으로 문제를 풀어서 틀린 답을 낸다.
예를 들어, 문제에서 덧셈과 곱셈이 나왔을 때, 덧셈을 먼저 하고 그다음에 곱셈을 해야 하는데, 왼쪽에서 오른쪽으로 순서대로 계산하는 잘못된 방식으로 풀어서 답을 틀릴 수 있죠. 이걸 오해라고 할 수 있다. -
이 대회에서의 목표는 학생들이 고른 오답이 어떤 오해와 관련이 있는지를 알아내는 것이다. 마치 선생님이 학생들이 왜 틀렸는지 이유를 알고 싶어하는 것과 같죠. 선생님은 학생이 "13"이라는 오답을 골랐을 때, "아, 이 학생은 덧셈과 곱셈의 순서를 헷갈렸구나"라는 걸 알 수 있다.

이 대회에서 해야할 일
- 문제: 각 문제는 정답 하나와 3개의 오답(오답지) 로 구성됨
- 오답과 오해 연결: 오답은 단순히 잘못된 답이 아니라, 학생이 어떤 오해를 했기 때문에 고른 답. 예를 들어, 13이라는 오답은 "왼쪽에서 오른쪽으로 순서대로 계산한다"는 오해로 인해 고른 답일 수 있음
- 문제점: 사람이 이 오답을 하나하나 분석해서 오해와 연결하는 것은 매우 시간이 많이 들고, 사람마다 다르게 분석할 수 있음
- 만들어야할 모델: 오답과 오해를 연결하는 작업. 이미 알려진 오해뿐만 아니라, 새로운 오해도 발견해내서 교사들이 더 쉽게 학생들이 어디서 헷갈렸는지 이해할 수 있게 도와주는 것
예시 문제 설명
예를 들어, 하나의 문제에 대한 데이터는 이렇게 구성될 수 있음
- 문제(QuestionText): 비율 계산 문제
- 정답(CorrectAnswer): D
보기 A: 총합으로 나누지 않고 각각의 비율로 나눔 → 오해 A: 비율 계산의 기본적인 착각
보기 B: 비율의 양쪽을 혼동함 → 오해 B: 비율의 개념을 혼동함
보기 C: 비율의 한 부분만 찾고 필요한 부분을 곱하지 않음 → 오해 C: 비율의 다른 부분을 간과함
평가
- 모델은 각 질문과 그에 대한 오답에 대해 최대 25개의 오해를 예측할 수 있음.
- 이를 통해 오답과 관련된 오해를 얼마나 정확하게 찾아내는지가 모델의 성능 평가 기준임
- 이때 평가 지표로는 MAP@25 (Mean Average Precision @ 25) 라는 것이 사용되는데, 간단히 말하면 올바른 오해를 얼마나 많이 맞췄는지를 측정하는 방법을 사용함 (25씩 예측)
- 순위가 중요하며, 정확한 예측이 상위에 있을수록 더 높은 점수를 받음
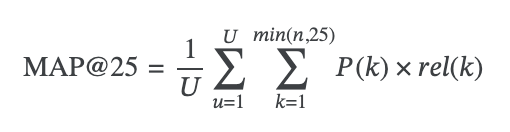
- 최종평가

- MAP@25
- 소요된 시간
- 예측시 CPU만 사용
정확도를 유지하면서 CPU환경에서 빠르게 실행되는 모델을 만들기 위함
데이터셋
- 이 대회의 데이터셋은 학생들이 진단 문제를 푼 결과와 그에 대한 오답과 오해를 연결한 데이터입이다. 각 문제는 4개의 보기(A, B, C, D)가 주어지고, 그 중 하나는 정답이고 나머지 3개는 학생들이 특정 오해로 인해 고를 수 있는 오답이다. 각 오답은 특정한 오해와 연결된다.
train.csv와 test.csv 파일
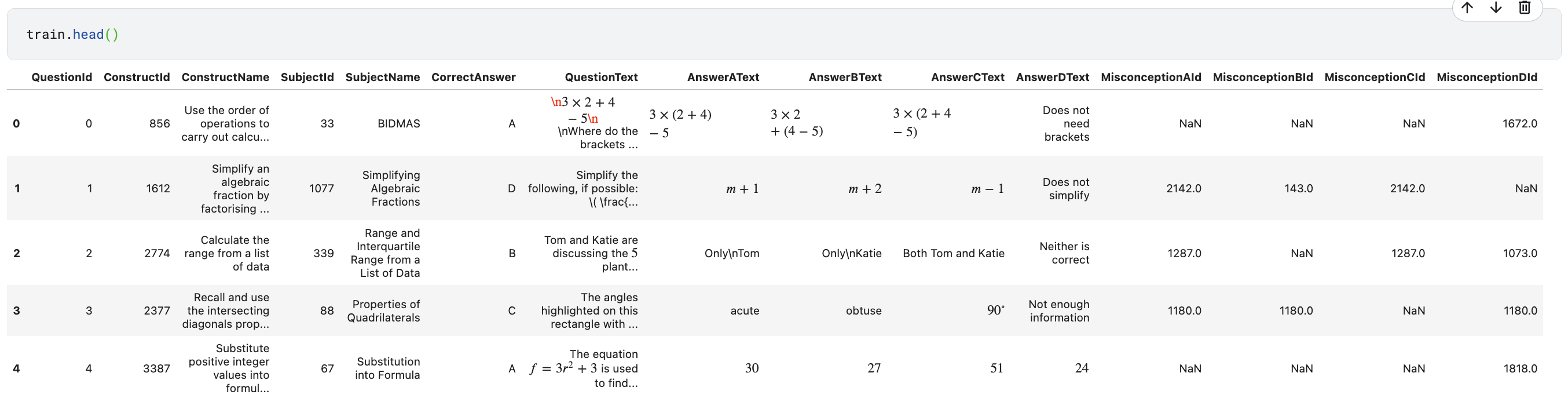
- QuestionId: 각 문제의 고유 식별자. 각 문제마다 고유한 번호
- ConstructId: 문제와 관련된 특정한 지식을 나타내는 고유 식별자. 문제의 핵심 개념을 의미
- ConstructName: ConstructId와 연결된 지식의 이름. 예를 들어, '비율 계산' 같은 문제의 지식 영역을 나타냄
- CorrectAnswer: 이 문제의 정답이 무엇인지(A, B, C, D 중 하나) 표시
- SubjectId: 문제의 더 일반적인 지식 영역을 나타내는 고유 식별자.
- SubjectName: SubjectId와 연결된 과목 이름.
- QuestionText: 문제
- AnswerText: 각 보기(A, B, C, D)
- MisconceptionId: 각 보기가 어떤 오해와 연결되는지 나타내는 고유 식별자. 훈련 데이터에서 이 값들이 제공되고, 이걸 바탕으로 테스트 데이터의 오해를 예측하는 것이 목표
misconception_mapping.csv 파일

- 이 파일은 오해에 대한 정보가 담겨 있음.
- 각 MisconceptionId는 해당 MisconceptionName과 연결됨.
- 예를 들어, MisconceptionId가 "1"인 오해는 "왼쪽에서 오른쪽으로 계산" 같은 구체적인 오해를 나타낼 수 있음
test.csv 파일

- 샘플 3개만 존재함
sample_submission.csv 파일
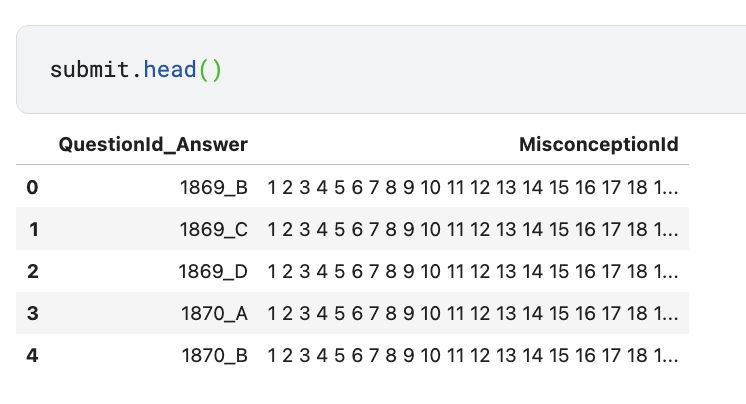
- 1869문제의 정답이 A라면
- 1669문제의 오답 B, C, D에 대해 각각 25개씩 오해의 ID 값 제출
디스커션에 공유된 방법
BGE 모델
- Bai General Embedding(BGE) 모델을 주로 사용하고 있음
- 텍스트 데이터를 저차원의 벡터로 변환하여 문장의 의미를 효율적으로 표현하는 데 사용됩니다. 주로 검색(retrieval) 및 추천 시스템에서 많이 활용되며, 텍스트 간의 유사성을 계산하거나 문장 간의 관계를 평가하는 데 유용함
- https://github.com/FlagOpen/FlagEmbedding
from transformers import AutoModel, AutoTokenizer
# 사전 훈련된 BGE 모델 로드
model_name = "BAAI/bge-large-en"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModel.from_pretrained(model_name)
# 임베딩 생성
text = "What is the capital of France?"
inputs = tokenizer(text, return_tensors="pt")
outputs = model(**inputs)
# 임베딩 벡터 추출
embedding = outputs.last_hidden_state.mean(dim=1)
외부 API를 사용할 수 있을까?
- 대회 제출 시에는 외부 API 호출이나 인터넷 연결이 허용 않음
- ChatGPT, GPT-3, Llama 등)를 호출할 수 없음
- 일한 조건에서 경쟁할 수 있도록 보장하기 위한 규정
- API를 사용하여 훈련 데이터를 미리 생성하거나, 사전 처리된 데이터를 준비해두는 것은 가능
관련 논문
Novice Learner and Expert Tutor: Evaluating Math Reasoning Abilities of Large Language Models with Misconceptions
링크
https://arxiv.org/pdf/2310.02439
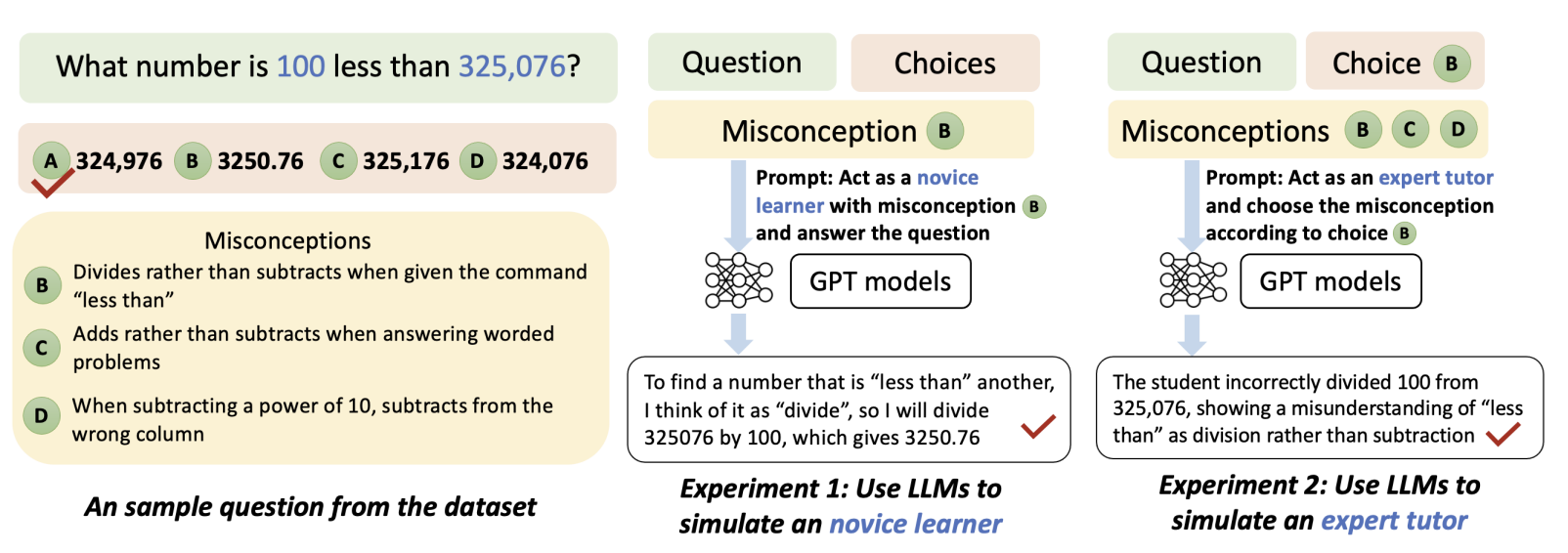
이 논문은 대형 언어 모델(LLM), 예를 들어 GPT-3.5와 GPT-4가 수학 문제에서 어떻게 오해(잘못된 개념)를 다루는지 평가하는 연구입니다. 여기서 LLM을 두 가지 역할로 나눠서 테스트
-
초보 학습자 역할: LLM이 수학 문제를 일부러 틀리게 푸는 시나리오입니다. 그런데 그냥 틀리는 게 아니라, 특정 오해에 기반한 잘못된 답을 선택해야 해요. 예를 들어, 소수점 처리에서 흔히 하는 오해 때문에 답을 틀리게 선택하는 겁니다. 이 과정을 통해 LLM이 얼마나 학생처럼 실수를 할 수 있는지 테스트합니다.
-
전문 튜터 역할: LLM이 학생이 틀린 답을 보고, 그 답이 어떤 오해 때문에 나왔는지 맞추는 역할입니다. 예를 들어, 학생이 '덧셈과 곱셈의 순서를 헷갈려서' 답을 틀렸다면, 그 오해를 LLM이 찾아내야 합니다. 이를 통해 LLM이 교사처럼 학생의 실수를 정확히 분석할 수 있는지 평가합니다.
연구에서 확인된 것
LLM은 수학 문제를 푸는 것 자체는 잘합니다. 즉, 정답을 맞히는 건 문제가 없어요.
하지만 학생처럼 실수를 시뮬레이션하는 것과, 학생의 오해를 정확히 찾아내는 것은 어려워합니다. 특히 여러 가지 오해가 섞여 있을 때는 더 힘들어합니다.
실험 방법
Eedi(https://eedi.com/home)라는 수학 문제 데이터셋을 사용. 이 데이터셋은 초등학교 수학 문제와 그 문제를 틀린 이유인 오해가 잘 정리되어 있어요.
실험에서는 LLM에게 문제를 주고, 틀린 답을 내게 하거나(초보 학습자 역할), 틀린 답을 보고 왜 틀렸는지 오해를 찾아내게 했습니다(전문 튜터 역할).
실험 결과
초보 학습자 역할: GPT-4는 정확하게 오해에 기반한 틀린 답을 선택하는데 61.7% 의 정확도를 보였습니다. 이는 무작위 선택보다 훨씬 높은 결과이지만, GPT-4가 정답을 맞추는 성능(94.8%)과 비교하면 상대적으로 낮습니다.
전문 튜터 역할: GPT-4는 제한된 수의 오해가 주어졌을 때 91.9% 의 정확도로 학생의 오해를 찾아냈습니다. 그러나 오해의 수가 증가할수록 성능은 감소하여, 오해가 100개일 때는 39.8% 의 정확도를 기록했습니다.
결론:
LLM은 교사처럼 완벽한 역할을 하기엔 아직 부족해요. 특히, 학생이 왜 틀렸는지 오해를 찾아내는 데는 한계가 있습니다.
하지만 수학 교육에서 LLM을 더 발전시키면 학생들이 틀린 이유를 분석하고, 더 나은 학습 경험을 제공할 수 있는 가능성이 있습니다.
이 연구는 인공지능을 활용한 교육 도구를 개발하는 데 큰 기여를 할 수 있어요. 앞으로 LLM이 어떻게 학생의 오해를 더 잘 이해하고 도와줄 수 있을지에 대한 연구가 계속될 것으로 보입니다.
