문제풀이(이중 반복문)
입력된 문자열 리스트 중 가장 짧은 문자열의 길이를 구한 뒤, 이를 기준으로 각 문자열의 같은 인덱스 위치에 있는 문자들을 비교하여 공통 prefix를 찾습니다. 이 때, 모든 문자열에 대해 해당 인덱스 위치에 문자가 있는 경우에만 공통 prefix에 추가하고, 아니면 해당 위치부터 뒤의 문자열들은 검사할 필요가 없으므로 바로 반환함.
- 문자열이 1개 이하인 경우, 해당 문자열을 반환
- 입력된 문자열들 중 가장 짧은 문자열의 길이를 찾음
- 가장 짧은 문자열의 길이만큼 "-" 문자를 가진 새로운 문자열을 만들어 입력된 문자열 리스트에 추가함.
- 각 문자열의 같은 인덱스 위치에 있는 문자들을 비교하여 가장 긴 공통 prefix를 찾음.
class Solution:
def longestCommonPrefix(self, strs: List[str]) -> str:
# 문자열이 1개 이하인 경우, 해당 문자열을 반환합니다.
if len(strs) <=1:
return strs[0]
ans = ""
num_str = len(strs)
# 입력된 문자열들 중 가장 짧은 문자열의 길이를 찾습니다.
min_len = len(min(strs,key=len))
# 가장 짧은 문자열의 길이만큼 "-" 문자를 가진 새로운 문자열을 만들어
# 입력된 문자열 리스트에 추가합니다.
strs.append(["-" for _ in range(min_len)])
# 각 문자열의 같은 인덱스 위치에 있는 문자들을 비교하여
# 가장 긴 공통 prefix를 찾습니다.
for i in range(min_len):
flag = False
for j in range(num_str):
if strs[j+1][i] == strs[j][i]:
flag = True
else:
flag = False
if strs[j+1][i] != "-":
return ans
if strs[j+1][i] == "-":
ans += strs[j][i]
return ans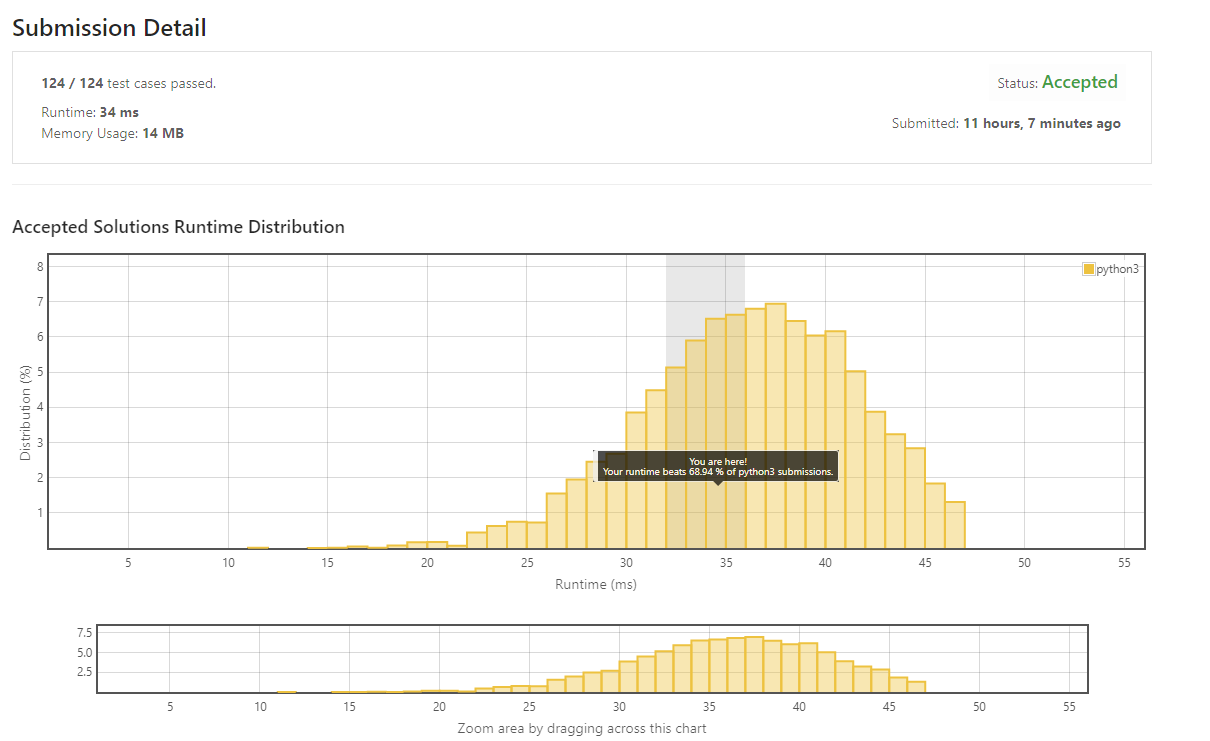
ChatGPT를 통한 개선 소스
class Solution:
def longestCommonPrefix(self, strs: List[str]) -> str:
if len(strs) <= 1:
return strs[0] if strs else ""
min_len = min(len(s) for s in strs)
ans = ""
for i in range(min_len):
c = strs[0][i]
if all(s[i] == c for s in strs):
ans += c
else:
break
return ans문제풀이(반복문 1회)
- strs라는 파이선 방법을 통해 한번의 반복문을 통해 해결함
zip(strs)는 리스트 하나를 인자로 받아들이며, 리스트의 각 요소들을 묶어주는 함수입니다. 반면, zip(strs)는 리스트 strs의 각 요소들을 분리하여 함수의 인자로 받아들이며, 각 요소들의 같은 인덱스 위치에 있는 값들을 묶어주는 함수입
strs=["hello", "world"]
zip(strs) 사용시 ("hello",), ("world",)
zip(strs)는 사용시 zip(*strs)는 ("h", "w"), ("e", "o"), ("l", "r"), ("l", "l"), ("o", "d")와 같은 결과를 반환
class Solution:
def longestCommonPrefix(self, strs: List[str]) -> str:
ans = ''
for char in zip(*strs):
if len(set(char)) > 1:
return ans
else:
ans += char[0]
return ans- 주어진 문자열들에 대해 정렬을 한 후 Min,Max 값만 비교하여 답안 도출
class Solution(object):
def longestCommonPrefix(self, strs):
ans =''
min_len = len(min(strs,key=len))
strs.sort()
s1,s2 = strs[0],strs[-1]
for i in range(min_len):
if s1[i]==s2[i]:
ans+=s1[i]
else :
return ans
return ansLookback
- 소스 코드를 개발하다보면 너무 장황하게 소스 개발이 되는 부분이 있다. 이번 문제도 풀긴 했지만 너무 장황한 부분(if for가 너무 많음)이 있어 ChatGpt 가 개선한 소스 내용을 필사하여 Pythonic하게 풀 수 있도록 해야 겠다.(all 연산자 등)
- 나의 소스는 2번의 반복문을 통해 수행하였는데 위 작성한 두가지 방식을 통해 한번의 반목문을 통해 해결 가능함을 확인하였다. 특히 *strs와 같이 각 요소를 분리하는 방식은 익숙해질 필요가 있을 것 같다. 또한 prefix라는 특성을 이용하여 sorting을 통해 여러 문자열을 2가지 문자열 비교하는 문제로 축소시킨 부분은 기발한 방식으로 보인다.

하루를 성실하게