문제 링크 : 뉴스 클러스터링
문제 설명
자카드 유사도는 집합 간의 유사도를 검사하는 여러 방법 중의 하나로 알려져 있다. 두 집합 A, B 사이의 자카드 유사도 J(A, B)는 두 집합의 교집합 크기를 두 집합의 합집합 크기로 나눈 값으로 정의된다.
예를 들어 집합 A = {1, 2, 3}, 집합 B = {2, 3, 4}라고 할 때, 교집합 A ∩ B = {2, 3}, 합집합 A ∪ B = {1, 2, 3, 4}이 되므로, 집합 A, B 사이의 자카드 유사도 J(A, B) = 2/4 = 0.5가 된다. 집합 A와 집합 B가 모두 공집합일 경우에는 나눗셈이 정의되지 않으니 따로 J(A, B) = 1로 정의한다.
자카드 유사도는 원소의 중복을 허용하는 다중집합에 대해서 확장할 수 있다. 다중집합 A는 원소 "1"을 3개 가지고 있고, 다중집합 B는 원소 "1"을 5개 가지고 있다고 하자. 이 다중집합의 교집합 A ∩ B는 원소 "1"을 min(3, 5)인 3개, 합집합 A ∪ B는 원소 "1"을 max(3, 5)인 5개 가지게 된다. 다중집합 A = {1, 1, 2, 2, 3}, 다중집합 B = {1, 2, 2, 4, 5}라고 하면, 교집합 A ∩ B = {1, 2, 2}, 합집합 A ∪ B = {1, 1, 2, 2, 3, 4, 5}가 되므로, 자카드 유사도 J(A, B) = 3/7, 약 0.42가 된다.
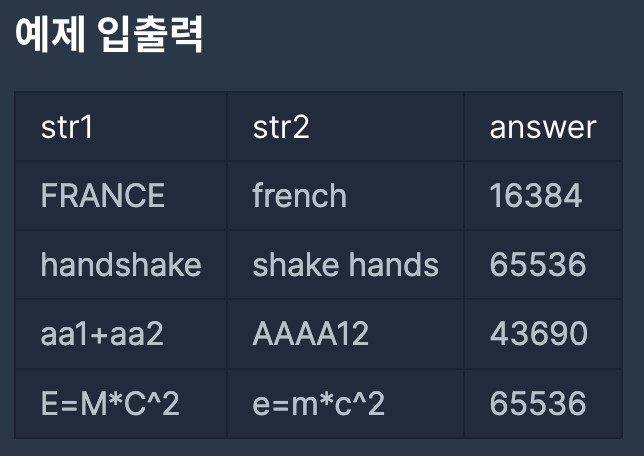
이를 이용하여 문자열 사이의 유사도를 계산하는데 이용할 수 있다. 문자열 "FRANCE"와 "FRENCH"가 주어졌을 때, 이를 두 글자씩 끊어서 다중집합을 만들 수 있다. 각각 {FR, RA, AN, NC, CE}, {FR, RE, EN, NC, CH}가 되며, 교집합은 {FR, NC}, 합집합은 {FR, RA, AN, NC, CE, RE, EN, CH}가 되므로, 두 문자열 사이의 자카드 유사도 J("FRANCE", "FRENCH") = 2/8 = 0.25가 된다.
입력 형식
- 입력으로는 str1과 str2의 두 문자열이 들어온다. 각 문자열의 길이는 2 이상, 1,000 이하이다.
- 입력으로 들어온 문자열은 두 글자씩 끊어서 다중집합의 원소로 만든다. 이때 영문자로 된 글자 쌍만 유효하고, 기타 공백이나 숫자, 특수 문자가 들어있는 경우는 그 글자 쌍을 버린다. 예를 들어 "ab+"가 입력으로 들어오면, "ab"만 다중집합의 원소로 삼고, "b+"는 버린다.
- 다중집합 원소 사이를 비교할 때, 대문자와 소문자의 차이는 무시한다. "AB"와 "Ab", "ab"는 같은 원소로 취급한다.
출력 형식
- 입력으로 들어온 두 문자열의 자카드 유사도를 출력한다. 유사도 값은 0에서 1 사이의 실수이므로, 이를 다루기 쉽도록 65536을 곱한 후에 소수점 아래를 버리고 정수부만 출력한다.
이 문제를 풀면서 사실 코딩 기법을 찾아봤다기보다는 교집합, 합집합을 만드는 법에 대해서 찾아보았다.
교집합/합집합 만드는 법
- 집합 A의 원소가 집합 B에 포함되었는지 확인한 후, 포함되었으면 교집합에 원소를 추가하고, 그 원소를 집합 B에서 삭제한다.
- 그 후 앞의 결과에 상관 없이 집합 A의 원소를 합집합에 포함한다.
- 집합 B에 남아있는 원소를 합집합에 포함한다.
내 풀이
public int solution(String str1, String str2) {
str1 = str1.toLowerCase();
str2 = str2.toLowerCase();
ArrayList<String> str1List = new ArrayList<>();
ArrayList<String> str2List = new ArrayList<>();
ArrayList<String> union = new ArrayList<>();
ArrayList<String>intersection = new ArrayList<>();
for(int i = 0; i < str1.length() - 1; i++){
char char1 = str1.charAt(i);
char char2 = str1.charAt(i + 1);
if(Character.isLetter(char1) && Character.isLetter(char2)) {
str1List.add(Character.toString(char1) + char2);
}
}
for(int i = 0; i < str2.length() - 1; i++){
char char1 = str2.charAt(i);
char char2 = str2.charAt(i + 1);
if(Character.isLetter(char1) && Character.isLetter(char2)) {
str2List.add(Character.toString(char1) + char2);
}
}
for(String str: str1List) {
if(str2List.remove(str)) {
intersection.add(str);
}
union.add(str);
}
for(String s : str2List) {
union.add(s);
}
double answer = 0;
if(union.size() == 0)
answer = 1; // 공집합일 경우 1
else
answer = (double) intersection.size() / (double) union.size();
return (int) (answer * 65536);
}위 방법대로 교집합, 합집합을 만들면서 문제를 풀어보았다.
먼저 문자열 두개를 모두 소문자로 만든 후, 두 글자씩 끊어서 만든 문자열을 저장할 List 두개와, 합집합, 교집합을 저장할 List를 만든다.
그 후 각각의 문자열을 반복하면서 알파벳일때만 strList에 저장한다.
그 후 str1List에 저장된 원소들을 순회하면서, str2List에 포함되어 있으면 제거 후 교집합에 추가하고, 위의 결과와 상관없이 합집합에 추가했다.
그 후 남은 str2List의 원소들을 합집합에 포함시켰다.
남은 유사도를 구하는 과정은 문제에서 제시된 대로 처음에는 소수부까지 모두 필요하므로 실수형인 double 자료형을 사용한 후, 정수형으로 반환했다.
