
Domain layer 정리
지금까지 1~3편을 통해 아무런 아키텍처도 적용되지 않은 앱에 MVVM을 한스푼 넣어줬는데요, 먼저 UI를 두 가지 클래스로 분리하여 역할을 나눴고 (UI layer), UI가 동작하기 위해 필요한 복잡한 비즈니스 로직을 ViewModel로부터 분리하여 UseCase로 만들었습니다. (DomainLayer)
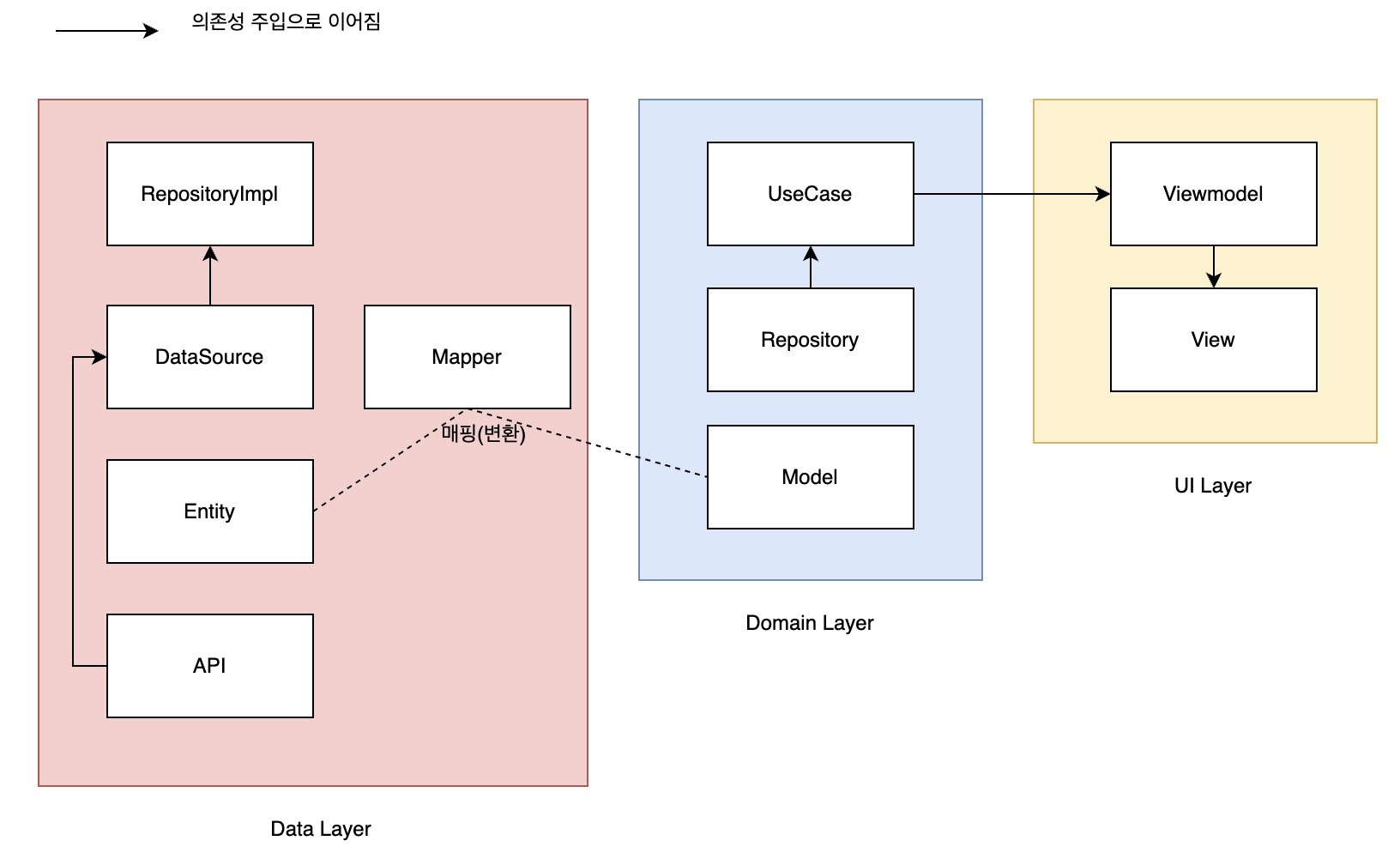
3편의 글을 다 읽고오신 분이라면 UseCase를 설명하면서 Repository에 대해 'Data를 가져오기 위한 로직의 구현부 혹은 인터페이스' 라고 설명했던것을 기억하실 텐데요, 이번 포스팅에서는 이 부분에 대해 다뤄보려고 합니다.
자, 위 다이어그램에서 UI layer는 2편에서 다뤘고, Domain layer는 3편에서 다뤘습니다. 이제 거대한 Data layer가 남아있네요. Domain layer에 대해 정리해보면
UseCase의 비즈니스 로직이 추상화된 Repository의 매서드를 통해 Data layer에 있는 구현부에 접근하여 데이터를 서버로부터 가져오고 이를 Model에 있는 표현식으로 만들어 ViewModel에 전달한다! 입니다.
Repository 패턴
지금까지 과정에서 UseCase를 통해 ViewModel에서 UI State를 셋팅하기 위한 비즈니스 로직을 완벽하게 분리했습니다. 그렇다면 비즈니스 로직에서 네트워크 통신이나 내장 DB 데이터 입출력 과정이 필요하다면 어떻게 해야 할까요? 당연히 UseCase 안에 모든 과정을 구현해도 되겠지만 이렇게 하면 생기는 가장 큰 문제점이 있습니다. UseCase의 역할이 너무 많아질 뿐더러 위 클린아키텍처 구조의 Data layer의 존재가 지워집니다.
자 그럼 Repository 패턴에 앞서 본질적인 의문을 먼저 해소하고 가야겠죠?
Data layer는 왜 존재하는가 feat. SoC
Data layer 뿐만 아니라 클린아키텍처 구조에서 왜 data, domain, ui 세 개의 layer로 나누는 것도 모자라 각 layer들조차 여러개의 컴포넌트로 쪼개놓았을까요?
그것은 바로 소프트웨어 엔지니어링의 기본 원칙중 하나인 관심사의 분리 (Separation of Concerns, SoC) 때문입니다.
SoC는 프로그램을 잘 정의된 구분되는 기능적 단위로 나누어 각 단위가 자신의 관심사에만 집중하도록 하는 설계 원칙입니다. 이 원칙은 코드의 유지보수성, 확장성 및 가독성을 향상시키는 데 도움이 되며 주요 특징을 아래와 같이 정리할 수 있습니다.
-
모듈성 향상
각 부분이 특정 기능이나 책임에 집중함으로써, 코드의 모듈성이 향상됩니다. 이는 팀 내에서 작업의 분배를 용이하게 하고, 개발 과정을 보다 효율적으로 만듭니다. -
재사용성 증가
관심사가 잘 분리된 코드는 다른 부분이나 프로젝트에서 재사용하기 더 쉽습니다. 이는 재사용 가능한 코드 라이브러리나 모듈을 만드는 데 기여할 수 있습니다. -
유지보수성 개선
코드의 특정 부분을 변경해야 할 때, 관심사의 분리는 그 변경이 다른 부분에 미치는 영향을 최소화합니다. 이는 유지보수 작업을 보다 예측 가능하고 관리하기 쉽게 만듭니다. -
테스트 용이성
각 부분이 독립적으로 존재하므로, 단위 테스트와 같은 테스트 작업이 더 쉽고 효율적으로 이루어질 수 있습니다. 모의 객체나 가짜 구현을 사용하여 각 부분을 독립적으로 테스트할 수 있습니다. -
가독성 및 이해도 향상
코드가 잘 구조화되고 각 부분이 명확한 책임을 가짐으로써, 코드의 가독성이 향상되고 다른 개발자가 코드를 이해하기 쉬워집니다. -
확장성
애플리케이션의 특정 부분만 변경하거나 확장해야 할 때, SoC는 이러한 변경이나 확장을 보다 용이하게 합니다. 각 부분이 독립적으로 존재하기 때문에, 새로운 기능이나 요구 사항을 쉽게 통합할 수 있습니다.
다시 돌아와서...!
이제 의문이 해소 되셨나요? 즉 클린 아키텍처 구조도에서 나눠놓은 각 layer들과 layer안의 모듈들은 SoC 원칙에 따라 각각의 역할을 수행하기 위해 모듈화된 단위이고 우리는 이에 맞춰 개발을 진행해야 하기에 MVVM 아키텍처를 공부하고 있는 것입니다. 생각해보면 각각이 무슨 역할을 하는지, 그리고 실제로 역할이 잘 분리되어 있다는 것 또한 알 수 있습니다.
- View : UI를 그리고 유저와 상호작용하며 입력을 받는다
- ViewModel : 유저입력을 받아 UI를 그리기 위한 정보를 hold 하고 업데이트 한다.
- UseCase : ViewModel이 정보를 업데이트하기 위한 비즈니스 로직을 담당한다.
와 같은 내용들 말입니다.
자 그럼 UseCase는 말그대로 비즈니스 로직만을 담당해야 하므로 데이터 입출력 작업에 대해서는 알지 못해야 합니다. 데이터 관련된 내용은 data layer가 담당을 하고 있기에 UseCase는 이 Data layer의 어느 구현부에 접근하여 데이터를 가져와야 하는데 우리는 이를 Repository 패턴을 활용하여 구현합니다.
Repository 패턴에 대해 구구절절 설명하기 전에 먼저 어떻게 구현하는지 다이어그램을 한번 그려볼게요. ... 짠!
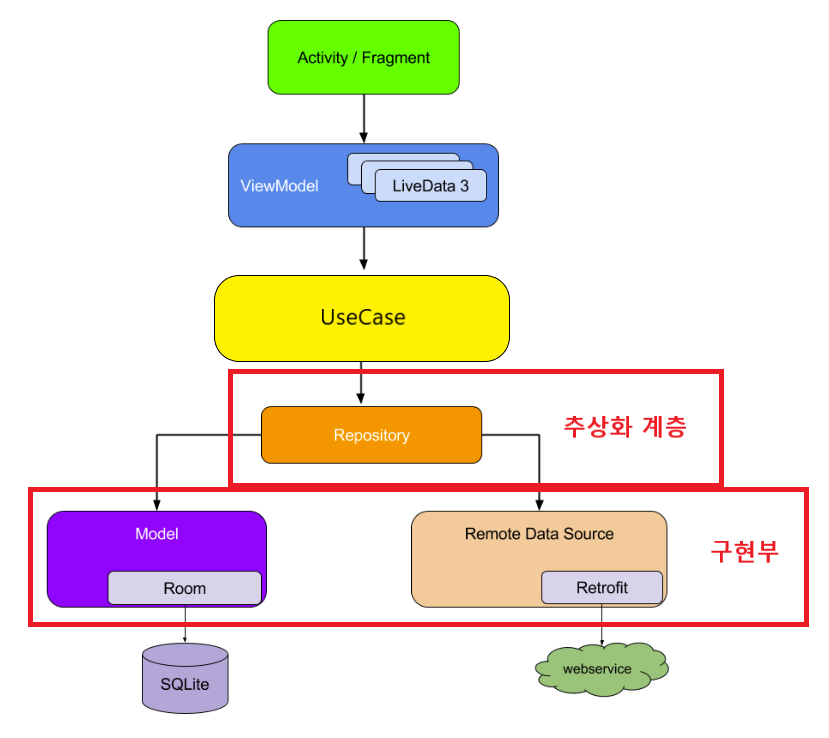
공식문서의 Repository 패턴 그림을 가져와 제가 조금 수정했습니다. 감쪽같죠?
가장 위의 View에서 유저입력을 받아 가장 아래쪽의 data source로부터 data를 가져오기까지 어떤 의존관계를 맺고있는지에 대한 다이어그램입니다. 쭉쭉쭉 내려와서 UseCase쪽에서 추상화된 Repository를 접근하고 있고 이 추상화 계층을 구현한 local / remote 구현체가 실제 데이터를 꺼내오고 있는 모양입니다.
추상화? 이게 왜 필요하고, 굳이 remote, local의 구현부를 따로 만드는 이유가 무엇인지 아래 내용을 통해 차차 알아봅시다.
다시, Repository 패턴이란?
레포지토리 패턴은 애플리케이션의 비즈니스 로직과 데이터 액세스 레이어 사이의 분리를 촉진하는 설계 패턴입니다. 이 패턴의 주요 목적은 데이터 소스와의 상호 작용을 추상화하여 데이터 액세스 로직을 캡슐화하는 것입니다. 레포지토리 패턴을 사용하면 UseCase는 데이터베이스나 외부 서비스와 같은 데이터 소스의 세부 구현 사항에 대해 알지 않고도 데이터를 조작할 수 있습니다.
레포지토리 패턴은 대체로 다음과 같은 구성 요소로 이루어집니다:
-
엔티티(Entity): 데이터베이스 테이블을 대표하는 도메인 엔티티입니다.
-
API Service : 원격 데이터소스에 접근하기 위한 메서드를 구현하여 제공합니다.
-
레포지토리 인터페이스(Repository Interface): 데이터 액세스 로직에 대한 추상화를 제공합니다. 이 인터페이스는 데이터를 조회, 추가, 수정, 삭제하는 메소드를 정의합니다.
-
레포지토리 구현 클래스(Repository Implementation Class): 레포지토리 인터페이스를 구현하는 클래스입니다. 이 클래스는 실제 데이터 소스와의 상호 작용을 담당합니다.
즉 위 다이어그램에서 Repository는 레포지토리 인터페이스에 해당하며 데이터의 출처(local/remote)와 상관없이 동일한 인터페이스로 데이터에 접근할 수 있도록 해주는 추상화 계층인 것입니다.
DI는 과연 만능인가
UseCase에서 바로 data source 구현부를 주입받아 사용하면 되는데 왜 굳이 추상화 계층을 통해 접근하게 구현해야 할까요?

제가 이런 그림에 대한 견문은 없지만 소프트웨어 추상화에 대해선 설명해줄 수 있습니다 ㅎㅎ
이전에 3편에서 DI를 통해 의존성을 주입함으로써 결합도를 어느정도 낮추었고 의존성 변경에 대해 어느정도 안정적으로 대응할 수 있도록 했습니다.
그런데 이런생각을 하셨다면 아주 잘 이해한 것입니다. '아무리 DI를 통해 의존성을 외부에서 주입해준다 해도, 해당 객체를 클래스 내에서 사용하는건 동일한데, 주입받는 객체에 변경점이 생기면 클래스 내부에서도 변경이 일어날 수 있는거 아닌가?'
즉 의존성을 가지는 클래스를 직접 생성하는 것에서 주입받는것으로 바꾸었기 때문에 '직접 의존'에서 '간접 의존' 으로 바뀐 것일 뿐 실제로 해당 클래스의 구현에 의존하고 있다는 사실은 바뀌지 않습니다.
구현에 의존한다는 말이 무슨뜻인지 나타내기 위해 시나리오를 한번 들어볼게요.
- 로그인 기능을 담당하는 LoginUseCase를 만들어 로그인을 수행하도록 했습니다.
- 로그인을 위해 네트워크에 접근하여 인가를 받는 AuthService 구현체를 통해 네트워크 로직에 접근하고 있습니다.
- 서버팀에서 갑자기 신기술을 도입하여 보안이 강화된 버전의 API를 릴리즈 하여 안드로이드에서도 앱을 업데이트하며 새로운 AuthTokenService 구현체를 추가하였습니다.
- 기존의 LoginUseCase에서 사용하던 AuthService를 새로 릴리즈된 AuthTokenService로 바꾸면서 UseCase의 전반적인 로직이 수정되었습니다.
class AuthService(){ // <- 기존 사용하던 ApiService
fun validate() : Boolean {
// ...
}
}
class AuthTokenService(){ // <- 새로 기능이 탑재되어 강화된 ApiService
fun validateToken() : String { // <- 매서드 동작방식 변경
// ...
}
}
class LoginUseCase(val childClass : AuthService){ // <- 주입받는 클래스타입과
fun login() : Boolean { // <- 사용하던 매서드 모두 수정이 일어나야 함
return childClass.create()
}
}자, API Service 구현체가 추가되고 매서드 동작방식이 바뀜에 따라 UseCase까지 그 영향이 전파되었습니다. 만약 AuthService를 사용하는 UseCase가 Login 뿐만 아니라 10개, 100개 더 있었다면 너무 끔찍하겠죠?
의존 역전 원칙 (DIP)
이를 해결하기 위한 방법이 객체지향 개발방법론에서 항상 이야기하는 의존역전 원칙 (Dependency Inversion Principle, DIP) 을 지키는 것입니다.
의존성 역전 원칙은 다음과 같이 정의될 수 있습니다
- 고수준 모듈은 저수준 모듈에 의존해서는 안 된다. 둘 다 추상화에 의존해야 한다.
- 추상화는 세부 사항에 의존해서는 안 된다. 세부 사항은 추상화에 의존해야 한다.
- 쉽게말해 '구현체 말고 추상화에 의존해라'

추상화? 는 interface를 말하는거 같은데 어떻게 빈 껍데기에 의존을 할 수 있을까요? 그리고 왜 그렇게 하라는 걸까요?
먼저 DI를 할 때 추상화 interface를 상속받은 구현체를 주입해줌으로써 interface에 대한 의존을 해결할 수 있습니다.
그리고 그 이유는 위에서 이야기 했던것처럼 두 모듈간 의존이 맺어진 관계에서 한 모듈의 변경점이 본인에게 의존하고 있는 다른 모듈에게도 전파되는 문제점을 해결하기 위함입니다.
즉 서로 다른 모듈에 직접 접근하는 것이 아니라 가운데 허브(추상화 계층)를 하나 두고 허브를 통해 접근하도록 구현하라는 것입니다.
해외여행 갈 때 나에게 만능 어댑터가 하나 있다면 해당 나라의 정격전압이 220V 인지 110V인지 알 필요 없이 그냥 만능 어댑터에 냅다 꽂으면 되는것과 같은 원리입니다.
A 클래스가 B 클래스에 의존성을 가지고 있을 때 B 클래스를 직접 참조하지 않고 B 클래스의 추상화 버전만 참조한다면 B의 실제 구현부가 어떻게 바뀌었든 참조 관계에는 영향을 받지 않게 된다는 것입니다.
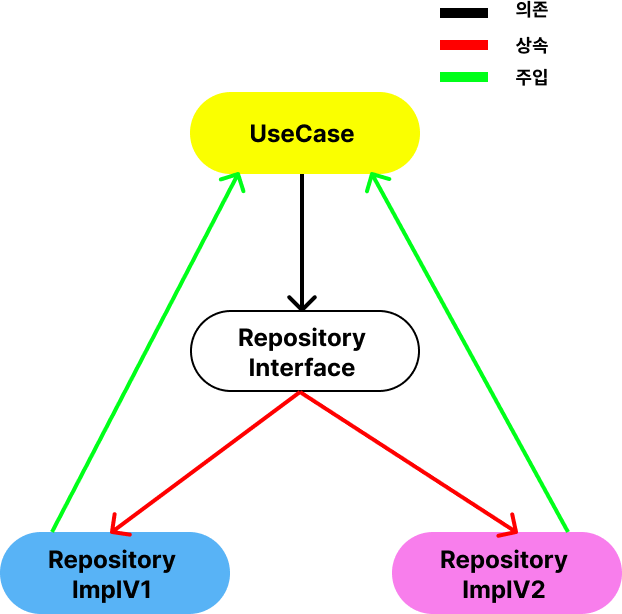
시각화를 한번 해보았는데요, UseCase에서 DB관련 작업을 하기위해 필요한 매서드는 모두 Interface에 정의되어있습니다. 따라서 내부 구현사항이 어떻게 바뀌었든 UseCase는 알 필요 없고 Interface를 통해 메소드를 호출만 하면 됩니다.
만약 내부 구현사항은 RepositoryImpl 이라는 구현체에서 직접 구현이 되어 있는데 버전이 올라가면서 구현부가 바뀐다면 동일한 Repository를 상속한 다른 구현체를 새로 만들어 주입해주면 됩니다.
초록색으로 표시된 의존성 주입의 경우 DI를 담당하는 클래스가 어떤 구현체를 주입해줄지 결정하기 때문에 UseCase입장에서는 Repository의 구현체에 대해 아무것도 몰라도 역할을 잘 수행할 수 있겠죠?
정리해보면
UseCase에서 DB나 네트워크 작업을 할 경우 비즈니스 로직과 데이터엑세스에 대한 역할을 분리하기 위해 레포지토리 패턴을 사용합니다.
레포지토리 패턴은 각 데이터 엑세스에 필요한 ApiService, Entity 와 이를 이용하여 접근 로직을 구현한 RepositoryImpl, UseCase가 데이터엑세스 로직에 접근하기 위한 매서드를 정의해둔 Repository 추상화 계층 네 가지로 구성됩니다.
그리고 위 다이어그램과 같은 의존성 구조를 통하여 DIP를 달성하고 Repository 패턴을 구현할 수 있습니다.
구현 방법
class SignupUseCase {
suspend operator fun invoke(username, password){
// TODO : 실제 회원가입 요청 API 호출
}
suspend fun checkId(id : String){
// TODO : 아이디 중복체크 API 호출
}
suspend fun checkNickname(name : String){
// TODO : 닉네임 중복체크 API 호출
}
// 비즈니스 로직
}
위 코드처럼 UseCase에서 데이터 엑세스 로직이 필요한 경우가 생겼다고 가정해 봅시다.
위에서 설명한 내용 대로라면 UseCase는 Repository interface에 의존해야 하므로 아래와 같이 구성해볼 수 있습니다.
interface UserRepository {
suspend fun requestCheckId(id) : ApiResult<Boolean>
suspend fun requestCheckNickname(name) : ApiResult<Boolean>
suspend fun requestSignUp(username, password) : ApiResult<Unit>
}
class SignupUseCase(private val repository: UserRepository) {
suspend operator fun invoke(username, password) : ApiResult<Unit>{
return repository.requestSignUp(username, password)
}
suspend fun checkId(id : String) : ApiResult<Boolean>{
return repository.requestCheckId(id)
}
suspend fun checkNickname(name : String) : ApiResult<Boolean>{
return repository.requestCheckNickname(name)
}
// 비즈니스 로직
}
UseCase가 interface에 의존하도록 구성을 해봤고 UseCase가 하는건 그저 interface의 매서드를 호출해서 그대로 반환하는거밖에 없습니다. (만약 데이터엑세스 후에 추가적인 데이터 가공이나 전처리가 필요하다면 적절한 비즈니스 로직을 추가해줄 수 는 있겠죠.)
이제 위에서 설명한 대로라면 DI를 담당하는 부분에서 Repository 구현체를 직접 주입해주는 과정이 남아있습니다. DI를 담당하는 부분은 어디일까요? ViewModelFactory입니다.
class JoinViewModel(signupUsecase : SignupUseCase) : ViewModel() {
// ...
// ViewModel 로직
// ...
// 뷰모델 의존성 주입을 위한 Factory
// 여기서 ViewModel에 관련된 모든 의존성 주입이 일어남
companion object {
@Suppress("UNCHECKED_CAST")
val Factory: ViewModelProvider.Factory = object : ViewModelProvider.Factory {
override fun <T : ViewModel> create(
modelClass: Class<T>,
): T {
// 원래 이 코드였는데 Repository 의존성이 추가되었으므로 변경점이 생깁니다.
// val signupUseCase = SignupUseCase()
val userDataSource = BeeringApplication.retrofit.create(UserApi::class.java)
val signupUseCase = SignupUseCase(UserRepositoryImpl(userDataSource))
return JoinViewModel(
signupUseCase
) as T
}
}
}
}3편에서 다뤘던 내용과 유일한 차이점은 UseCase에 의존성을 추가로 주입해주기 위해 data source를 생성하는 부분이 추가되었다는 점입니다. userDataSource가 뭔지는 레트로핏을 사용해보셨다면 아실거라 믿습니다.
어? UseCase가 의존하고 있는 클래스는 UserRepository interface인데 실제로 ViewModelFactory에서 주입해주고 있는 클래스는 UserRepositoryImpl 클래스네요?
이 구현체 클래스는 어떻게 생겼을까요?
class UserRepositoryImpl(
private val userApi: UserApi
) : UserRepository {
override suspend fun requestCheckId(id: String): ApiResult<Boolean> {
val response = userApi.checkUserId(id)
if (response.isSuccessful) {
response.body()?.let { it ->
return ApiResult.Success(it.result)
}
}
return ApiResult.Fail(response.code(), response.message())
}
override suspend fun requestCheckNickname(name: String): ApiResult<Boolean> {
val response = userApi.checkNickname(name)
if (response.isSuccessful) {
response.body()?.let { it ->
return ApiResult.Success(it)
}
}
return ApiResult.Fail(response.code(), response.message())
}
override suspend fun requestSignUp(username: String,
password: String): ApiResult<Unit> {
val apiRequest = JoinRequest(username, password)
val response = userApi.signUp(apiRequest)
if (response.isSuccessful) {
response.body()?.let { it ->
return ApiResult.Success(it)
}
}
return ApiResult.Fail(response.code(), response.message())
}
뭐 대충 이렇게 생겼습니다. 별거 없지 않나요? 그냥 Retrofit API 객체 받아서 통신하고 response 결과 따라서 성공, 실패 객체로 패키징해서 반환하는 뭐 그런 로직입니다.
중요한건 클래스가 UserRepository를 상속하고 있는 부분입니다. 그렇기 때문에 UserRepository에 선언되어 있는 모든 매서드를 구현해주어야 하고 이 클래스가 구현부가 되는것이죠.
뭐 레포지토리 패턴이니 DI니 DIP니 어려운 말을 주구장창 늘어놓긴 했는데 위 개념들에 대해 이해하고나서 각각의 객체가 무슨역할을 하는지 뜯어보니 막상 역할의 분리가 확실하게 일어나서 별로 안어렵지 않나요?
- UseCase는 ViewModel에서 데이터 관리에 필요한 비즈니스 로직을 담당합니다.
- Repository는 UseCase가 데이터엑세스 시 필요한 매서드들을 추상화하여 UseCase가 해당 로직에 접근할 수 있는 방법을 제공합니다.
- RepositoryImpl은 Repository를 상속하여 직접 네트워크에 연결하여 데이터를 가져오고, 적절히 가공하여 반환하는 역할을 합니다.
- ViewModel Factory는 모든 의존성 주입을 담당하여 RepositoryImpl을 생성하고 이를 UseCase에 주입해주며, 이렇게 생성한 UseCase를 다시 ViewModel에 주입하여 ViewModel을 생성할 수 있도록 합니다.
이것이 CleanArchitecture가 강조하는 장점이라고 볼 수 있습니다.
이쯤에서 Architecture 구조도 복습
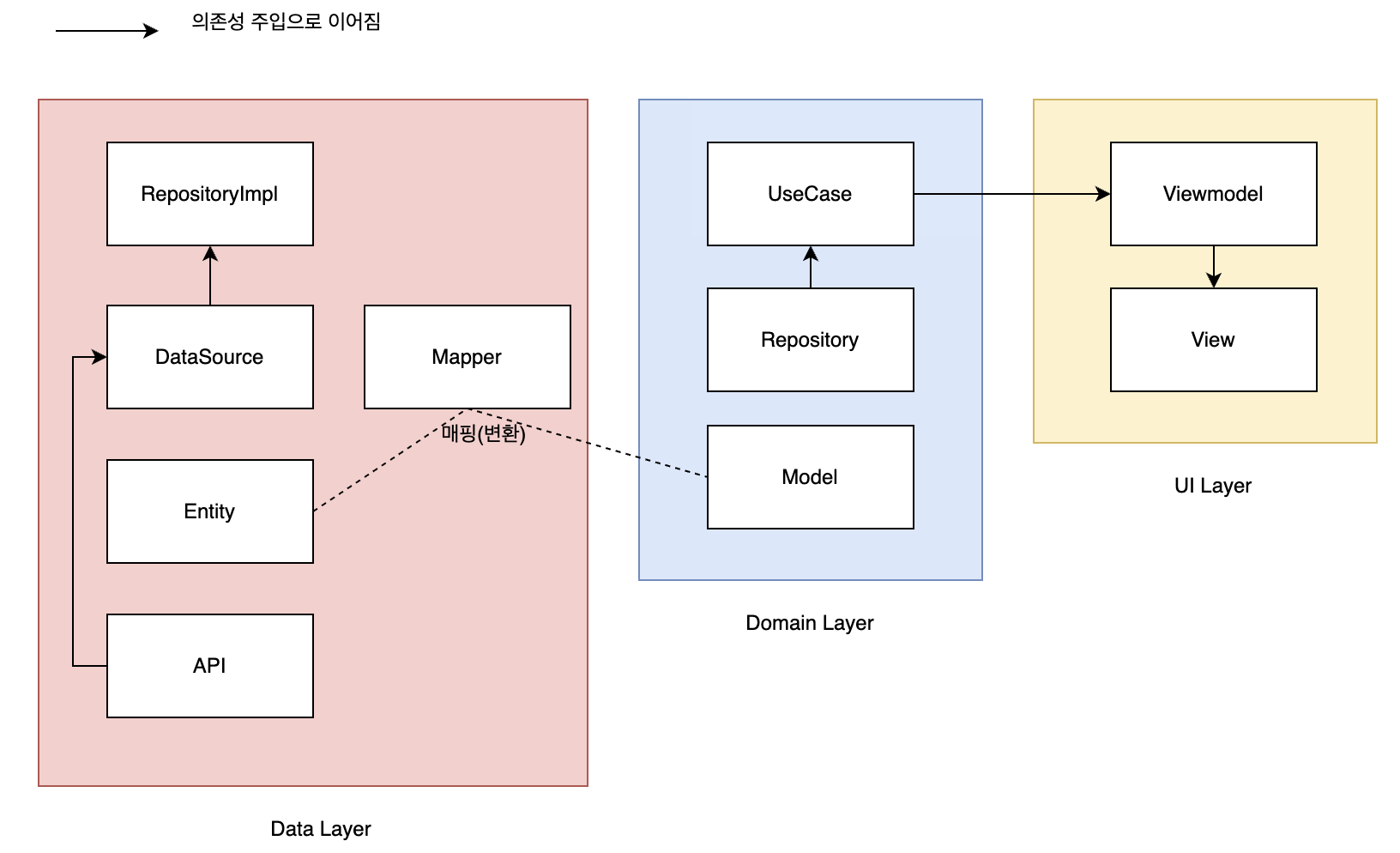
네.. 또 등장했습니다 ㅎㅎ
이 그림을 처음 마주했을 때 겁나 어려워 보이고 뭐 프로젝트 하나 만드는데 이렇게 많은 컴포넌트가 필요해 싶기도 하고 눈에 들어오지도 않았을 겁니다.
그런데 이제 다 아는내용 아닌가요?
- ViewModel과 View 컴포넌트는 UI화면을 UI 데이터와 UI 로직의 구성요소로 분리하였습니다.
- UseCase는 ViewModel에서 필요한 비즈니스 로직을 제공하고 있습니다.
- Model은 DomainLayer와 UILayer 등에서 사용할 수 있는 데이터 표현식들을 의미합니다. (쉽게말하면 그냥 코틀린의 data class들입니다.)
- Repository는 UseCase가 데이터에 엑세스 할 수 있는 방법을 제공하고 있습니다.
- RepositoryImpl은 Repository의 매서드가 어떻게 동작해야하는지 그 동작 방식을 구현하고 있습니다.
- API는 서버와 통신하기위해 만든 RetrofitInterface를 말합니다.
- DataSource는 Retrofit 라이브러리를 활용하여 RetrofitInterface를 빌드한 객체를 말합니다. RepositoryImpl에서 이 객체를 활용하여 서버와 통신하게 되죠.
이렇게 각자의 역할에 맞게 컴포넌트를 분리하여 설계하는 방식을 CleanArchitecture라고 부르며 우리는 이를 ViewModel을 활용하면서 MVVM 아키텍처로 설계하였습니다.
Entity, Mapper에 대해 설명을 생략했는데 이는 내부 저장소 접근에 관련된 컴포넌트들입니다. Entity는 RoomDB라이브러리를 사용했다면 아실것이고, 이 라이브러리를 통해 가져온 데이터를 Model의 표현식으로 변환해주는 객체가 Mapper입니다.
네트워크 통신과 크게 다른 부분이 없으므로 자세한 코드 설명은 생략하도록 하겠습니다.
자 지금까지의 여정에 걸쳐서 CleanArchitecture가 뭔지 어느정도 알게 되었습니다.
그런데 의문점이 하나 남았죠? 제목은 Hilt 들고 MVVM 정복하기 인데 왜 CleanArchitecture만 지금까지 주구장창 설명했을까? 입니다 :D
그 이유는 Hilt 라이브러리는 MVVM과 CleanArchitecture를 구성하는데 있어 도움을 주는 라이브러리일 뿐 필수적인 라이브러리가 아니기 때문에 이 부분을 빼고 모든 것을 직접 구현하는데 초점을 맞춰 진행해보았기 때문입니다.
다음편부터는 Hilt라이브러리가 무엇이고, 이를 어떻게 사용하며, 사용하면 뭐가 달라지고 편해지는지 에 대한 내용을 다뤄보겠습니다.
