문제 상황 예시
먼저 이 알고리즘을 알게된 문제부터 소개하겠습니다.
https://www.acmicpc.net/problem/2631
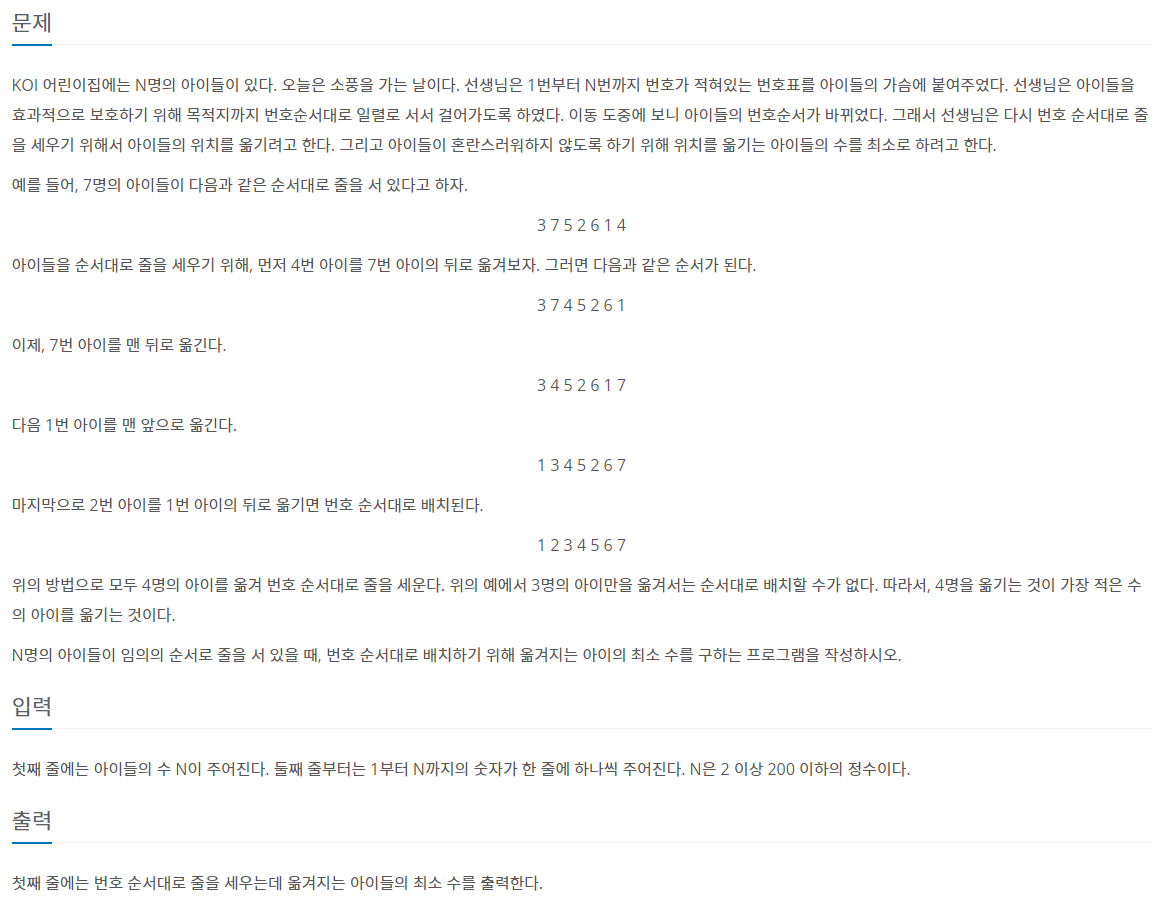
이렇게 생긴 문제인데, DP 문제로 분류되어 있어서 메모이제이션에 집중을 하고 생각해 봤는데, 진짜진짜 도저히 생각이 안나서 힌트만 얻고자 조금의 검색을 해본 결과, 최장 증가 수열이라는 것에 대해 알게 되었습니다.
최장 증가 수열이란
이 최장 증가 수열 (Longest Increasing Subsequence 줄여서 LIS) 이란 주어진 배열 내에서 부분집합을 뽑았을 때, 가능한 모든 오름차순으로 배열되어 있는 부분집합 중에서 길이가 가장 긴 부분집합을 의미합니다.
즉 위 문제에서 주어진 [3, 7, 5, 2, 6, 1, 4] 배열을 기준으로 보면

위 사진과 같이 오름차순 수열을 이루는 부분집합들을 여러개 뽑을 수 있습니다.
그중 가장 길이가 긴 최장 증가 수열은 [3, 5, 6] 이 되겠네요.
이 최장 증가수열이라는 것을 알게되면 뒤 문제를 어떻게 해석할 수 있을까요?
결국에는 주어진 배열을 가장 적은 이동횟수로 정렬하는 문제이기 때문에, 이미 정렬되어 있는 부분만 빼고 나머지를 건드려서 정렬시켜주면 됩니다. 즉 '가장 잘 정렬되어 있는 상태를 유지하면서 나머지 부분을 지금 상태에 맞게 맞추어주기만 하면' 된다는 겁니다.
그러려면 가장 길게 정렬되어 있는 최장 증가 수열을 구하고 그 외의 원소를 정렬하면 되는데, 이 문제는 정렬하는데 필요한 이동횟수를 구하는 것이므로 최장 증가 수열의 길이만큼을 총 배열에서 빼면 됩니다. 나머지 원소를 한번씩 움직여서 순서를 맞춰주면 되니까요.
즉 최장 증가 수열의 길이를 구하는 문제와 완벽하게 똑같은 문제입니다.
https://www.acmicpc.net/problem/11053
LIS의 길이를 구해봅시다
그렇다면 최장 증가 수열(LIS)의 길이는 어떻게 구할 수 있을까요?
- Dynamic Programming :
- Binary Search :
두 가지 방법이 존재하는데 위의 예제 배열으로 두 가지 방법을 살펴보겠습니다. (코드는 파이썬 코드입니다.)
DP를 이용한 방법
N = int(sys.stdin.readline())
children = [3, 7, 5, 2, 6, 1, 4]
dp = [1] * N
for i, child in enumerate(children):
for j in range(0, i):
if children[j] < child and dp[i] < dp[j] + 1:
dp[i] = dp[j] + 1
print(children) # [3, 7, 5, 2, 6, 1, 4]
print(dp) # [1, 2, 2, 1, 3, 1, 2]
print(max(dp)) # 4dp 배열에는 해당 인덱스까지 오름차순으로 정렬될 수 있는 가장 긴 길이를 memoization합니다.
- 최장 증가 수열 부분집합을 찾지 못해도 본인 자신의 부분집합은 존재하므로 dp배열을 1로 초기화합니다.
- for문으로 주어진 children 배열을 처음부터 끝까지 돌면서
- 각각의 인덱스에 대해 이전의 모든 값들을 순서대로 검사합니다.
- 만약 현재 인덱스 (i)의 값보다 더 작은 이전의 인덱스(j) 값을 찾았다면 현재 위치 (i)의 증가 수열 길이보다 이전 인덱스 (j)로부터 부분집합을 만들었을 때 증가 수열 길이가 더 크다면 dp를 업데이트합니다.
- 이렇게 하면 최종적으로 dp에는 각 인덱스 까지 부분집합을 구성했을 때 가능한 증가 수열 중 가장 긴 길이가 저장됩니다.
- dp배열의 max값을 출력합니다.

dp 배열이 어떻게 나오는지 시각화 해보면 위 그림과 같습니다.
각각 인덱스에 해당하는 인수를 포함하는 부분집합 중 가장 긴 증가수열의 길이가 dp에 저장되는 방식으로 구현하고 dp에서 가장 긴 길이가 최장 증가 수열의 길이가 되는 아이디어입니다.
for문이 2중으로 구성되므로 의 시간복잡도를 가집니다.
이분탐색을 이용한 방법
def binary_search(array, start, end, tar):
while start <= end:
mid = (start + end) // 2
if array[mid] < tar:
start = mid + 1
elif array[mid] > tar:
end = mid
if start == end:
break
else:
break
return mid
N = int(sys.stdin.readline())
children = [3, 7, 5, 2, 6, 1, 4]
lis = [0] * N
length = 0
for i, child in enumerate(children):
if length == 0:
lis[0] = child
length += 1
else:
idx = binary_search(lis, 0, length, child)
lis[idx] = child
if idx == length:
length += 1
print(lis) # [1, 4, 6, 0, 0, 0, 0]
print(length) # 3LIS의 길이를 구하는데에는 이분탐색을 사용할 수 도 있습니다.
lis배열을 추가로 생성하여 증가수열을 기록해 나가도록 합니다. 이 때 주어진 children 배열의 모든 원소를 순차적으로 탐색하며 lis 배열을 업데이트하게 됩니다.
최종적으로 완성된 lis배열의 길이가 최장 증가 수열이 길이가 되는 원리이며 이 때 증가수열을 기록해 나가는 과정을 최적화하기 위해 이분탐색을 사용하게 됩니다.
lis배열을 업데이트 해나가는 과정은 아래와 같습니다.
- children에서 원소를 하나 꺼냅니다.
- 꺼낸 원소가 lis 배열에 오름차순에 따라 들어갈 수 있는 위치를 이분탐색으로 찾습니다.
- 만약 꺼낸 원소가 가장 큰 수라면 lis 배열의 마지막에 추가합니다.
- 그렇지 않다면 꺼낸 원소보다 바로 다음으로 큰 lis 배열 내의 수를 대체합니다.
- children의 모든 원소를 꺼낼때 까지 반복합니다.
주어진 children = [3, 7, 5, 2, 6, 1, 4] 배열을 가지고 lis 배열이 생성되는 과정을 그림으로 그려보면 아래와 같습니다.
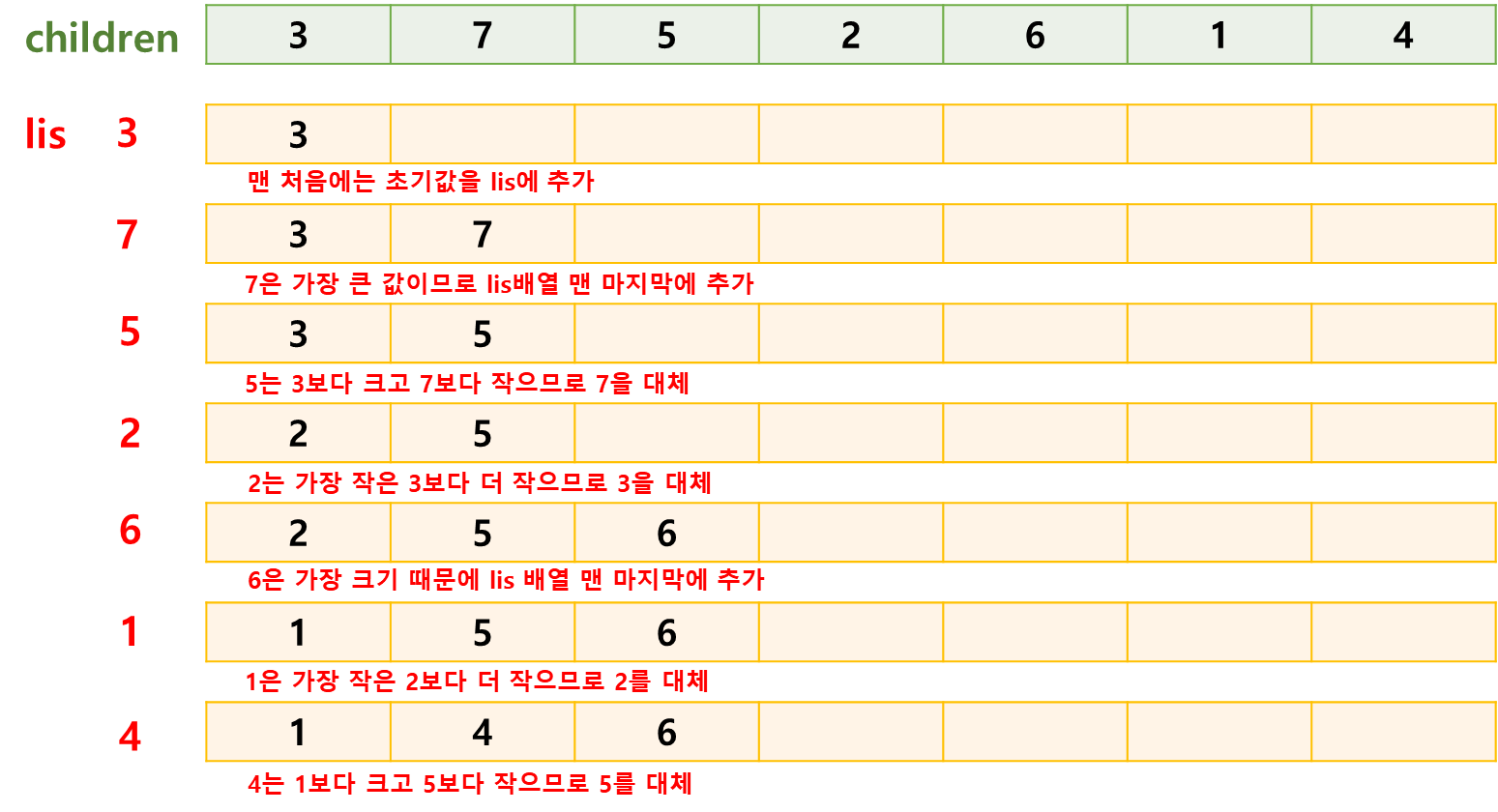
알고 넘어가야할 점은 이 알고리즘은 정확한 lis 배열을 구하기 위한 방법이 아닌 lis의 길이를 구하기 위한 알고리즘 이라는 점입니다. 실제로 children 배열에서 구할 수 있는 최장 증가 수열은 [3, 5, 6] 이지만 위 알고리즘의 결과로 나온 lis 배열은 최종적으로 [1, 4, 6]인 것을 알 수 있습니다.
lis 배열을 업데이트하는 과정 즉 3, 7, 5 ... 들의 각 원소를 뽑아 lis 배열을 업데이트하는 각각의 스텝이 의미하는 바는 해당 원소의 위치에서 최장증가수열의 길이가 업데이트가 일어나는지를 체크하는 과정입니다. 즉 실제 최장증가수열 [3, 5, 6]에서 가장 마지막 원소는 6이므로 위 알고리즘의 진행과정에서도 6일 때 마지막 업데이트(lis배열의 가장 뒤에 원소가 추가되는 사건)가 일어나고 종료되는 것입니다.
그 과정에서 업데이트가 일어나지 않는 경우에는 lis 배열 중간의 값들이 계속해서 대체되기 때문에 정확한 최장증가수열을 구할 수 없습니다.
정확한 LIS배열을 구하는 방법
정확한 최장증가수열 부분집합을 구하려면 추가적인 memoization을 거쳐야 합니다.
간단히 설명을 위해 DP 구현코드를 다시 살펴보겠습니다.
N = int(sys.stdin.readline())
children = [3, 7, 5, 2, 6, 1, 4]
dp = [1] * N
for i, child in enumerate(children):
for j in range(0, i):
if children[j] < child and dp[i] < dp[j] + 1:
dp[i] = dp[j] + 1
print(children) # [3, 7, 5, 2, 6, 1, 4]
print(dp) # [1, 2, 2, 1, 3, 1, 2]
print(max(dp)) # 4위 코드에서 dp 배열에는 각각의 원소가 증가수열의 마지막 원소인 경우 해당 증가수열의 최대 길이를 나타내고 있습니다.
이 때 증가수열의 길이 뿐만 아니라 이전의 숫자가 어떤 숫자인지 추가적으로 기록해두면 연쇄적으로 역추적하여 정확한 LIS 배열을 구할 수 있습니다.
N = int(sys.stdin.readline())
children = [3, 7, 5, 2, 6, 1, 4]
prev_ids = [-1] * N
dp = [1] * N
for i, child in enumerate(children):
for j in range(0, i):
if children[j] < child and dp[i] < dp[j] + 1:
dp[i] = dp[j] + 1
prev_ids[i] = j
print(children) # [3, 7, 5, 2, 6, 1, 4]
print(dp) # [1, 2, 2, 1, 3, 1, 2]
print(prev_ids) # [-1, 0, 0, -1, 2, -1, 5]
cur_idx = max(range(len(dp)), key=lambda i: dp[i]) # 최장증가수열의 가장마지막 숫자에 해당하는 children의 인덱스
real_lis = list()
while True:
real_lis.append(children[cur_idx])
cur_idx = prev_ids[cur_idx]
if cur_idx < 0:
break
print(real_lis) # [6, 5, 3]
print(max(dp)) # 4lis의 길이만 구했을때와 달라진 점은 prev_ids 배열이 추가로 활용된다는 점입니다.
prev_ids배열에는 dp값이 업데이트 될 때 마다 해당 숫자로 넘어오기 이전의 인덱스를 저장하여 해당 부분집합을 이룰 때 어떤 숫자를 포함하고 있었는지 추적할 수 있도록 합니다.
최종적으로 람다식을 활용하여 가장 긴 길이의 증가수열을 이루는 인덱스를 구하고, while문에서 prev_ids 배열을 통해 해당 증가수열을 이루는 구성요소들을 연쇄적으로 역추적하여 real_lis 배열에 저장합니다.
결과적으로 real_lis 배열에는 최장증가수열에 해당하는 부분집합이 저장되게 되는데, 역추적과정을 거쳤으므로 내림차순 순으로 정렬되어 저장이 되게 됩니다.
