
쿠퍼네티스를 변수로서 어떻게 설치할 것인지가 나와있음
여기에 containerd라고 되어있는데 선택할 수 있는 값이 docker,crio,containerd이다.
https://kubernetes.io/ko/blog/2020/12/02/dont-panic-kubernetes-and-docker/
우리는 더이상 도커를 지원하지 않습니다~ 라는 말의 의미가 오해였는데 왜냐하면 옛날에는 도커라이브러리를 사용했었는데 지금은 containerd라이브러리를 사용해서임
지금은 containerd와 ContainerRuntimeInterface를 선택할 수 있다.
그래서
systemctl status containerd
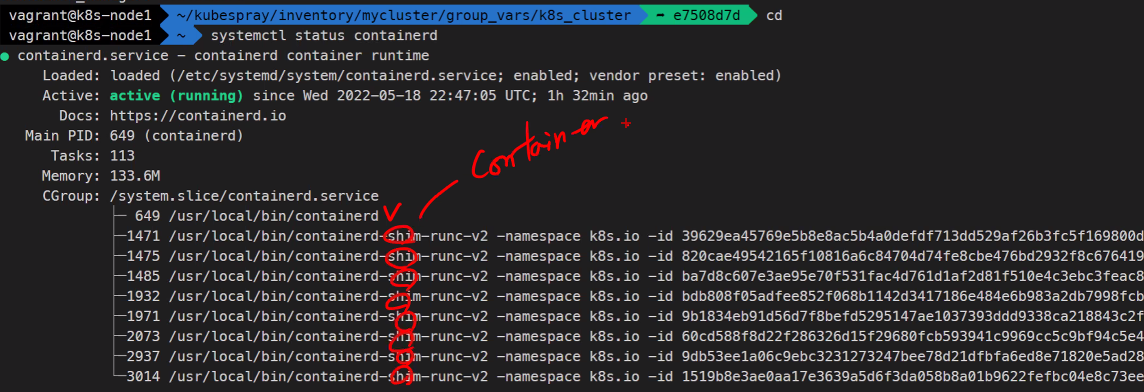
runc라고 되어있는 것들은 container의 c 표준이다.
https://github.com/containerd/containerd
Release들어가보면
에서 ctr이라는 명령어를 설치할 수도 있고.
crictl이라는 명령어가 기본으로 설치되어있고 이 명령어는 관리자 권한이 필요하다.
이 친구는 그냥 sudo -i 로
crictl ps
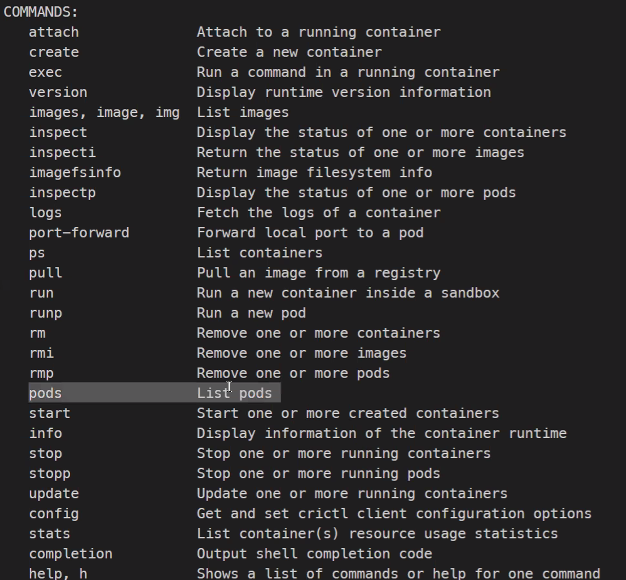
이런 명령어들이 있고
특이하게 pods를 보는 기능이 있다.
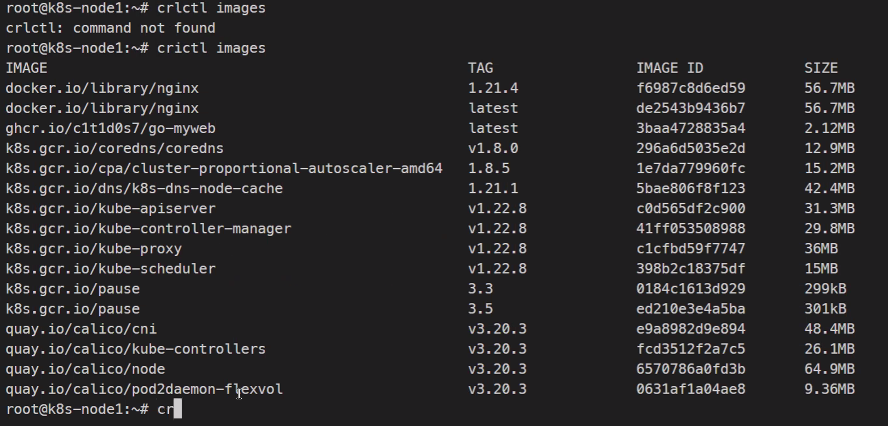
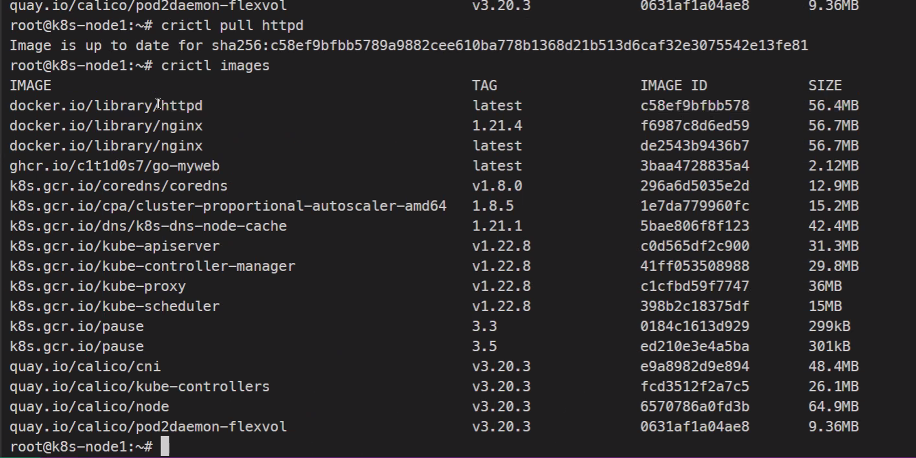
이런식으로 이미지를 불러오는것도 가능하다.
image이름도 docker와 다르게 풀네임이 다 찍힌다.
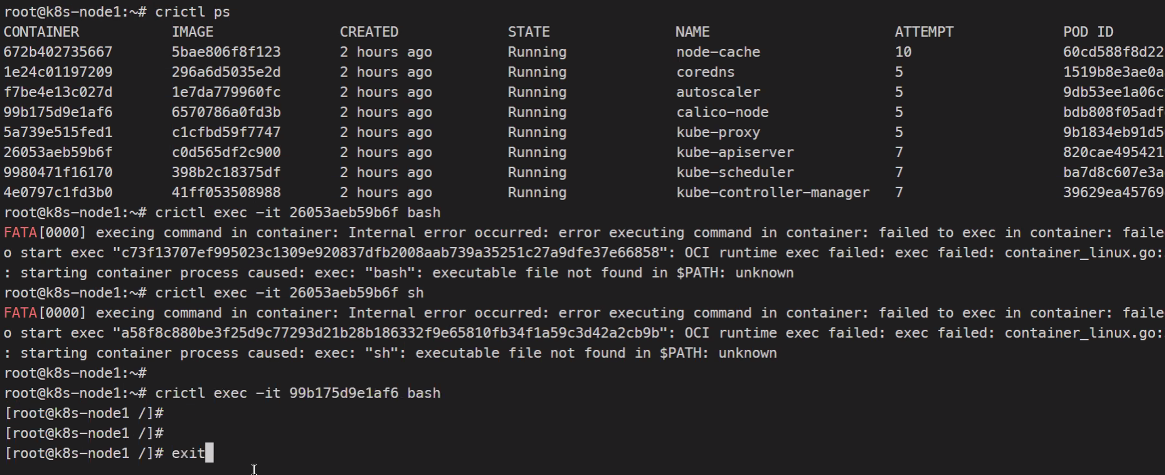
이런식으로 crictl을 사용할 수 있다.
굳이 docker를 설치하지 않아도 되는 방법에 대한 내용이었다.
https://kubernetes.io/docs/reference/tools/map-crictl-dockercli/
https://kubernetes.io/docs/tasks/debug/debug-cluster/crictl/
이런 내용들을 참조 해보길 바란다.......
데몬셋
설명을 읽어보자..

데몬이라고 하면 systemctl에서 관리하는 것들.. 서비스, 데몬, 서비스 데몬 다 같은 의미이고
우리같은 경우에는 systemd라고 하는 녀석에 의해서 제어되는 App이고 이것들은 BG에서 실행되게 되고 이런 계속해서 실행되는 것들을 제어하는 친구가 데몬이다.
당연하겠지만 윈도우도 똑같이 서비스가 존재한다.
services.msc
예를들어 백신같은것도 등록이 되어서 항시 실행이 된다.
그리고 시작 유형에서 보게되면 자동이라고 되어있는데 이건 우리가 systemctl enable 한거와 똑같다.

수동 트리거 시작이라고 되어있는 거는 다른 요소에 의해서 자동으로 실행되는 형태이다.
이런 것들을 데몬이라고 하고
데몬셋은 모든 노드의 파드를 실행한다..
여기서 중요한 점은 apache도 데몬이고 다 데몬이 아닙니까 할 수 있는데 (백그라운드에서 실행되기 때문) 데몬에는 다른 의미가 또 있다.
rs은 예를들어 노드가 3개라고하면 복제본이 3개라고 선언을 했을테고 그럼 rs가 각 3개의 노드에 만들어서 고가용성을 만족시킬 수 있을테지만 우선은 기본적으로 rs같은 경우에 1,2,3노드가 있다고 하더라도 하나씩 배치하는게 불가능하다 스케쥴러에 의해서 배치될 뿐이다.
rs입장에서는 3개만 만들면되지 고가용성을 만족시키면서 배치하게 할 기본 사항은 없다고 한다. (스케쥴링을 하면 된다고함)
ds는 반드시 각 노드에 컨테이너를 분산시켜서 실행한다.
이 점이 데몬셋과 레플리카셋의 차이점임
물론 rs의 스케쥴링을 지정해줄 수 있지만 굳이.. 그러지 않고 데몬셋을 사용함
ds는 이럼 노드가 추가되면 무조건 노드 하나에 한개의 컨테이너를 배치시킴
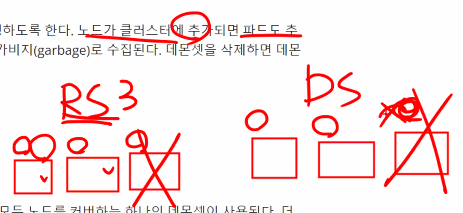
그림으로 표현하면 이렇다
데몬셋의 주 용도는 Agent이다. (web, webApp이 아님!)
즉, 노드와 관련된내용임 어플리케이션들을 보조하거나 인프라 플랫폼을 보조하기 위해 사용됨.
쿠버네티스가 연결할 수 있는 CRI CNI CSI같은 인터페이스를 사용할텐데 (예를들어 Rook Ceph) 노드의 어플리케이션을 관리할 것들 또는 log를 관리할 때 ELK EFK구성을 하는데 이런 도움을 주는것들이 Agent이고 또한 프로메테우스가 모니터링을 지원해주는데 이런것들도 Agent이다.
이런 Agent의 용도를 관리하기 위해 사용할 것이 데몬셋이다.

지금 노드가 3개가 있는데 여기 desired값이 3개인 이유가 바로 그것이다.
그리고 안에 있는 내용들은 모두 네트워크와 관련된 것임 그래서 그와 관련된 어플리케이션이 다 배치가 되는 것이라고 한다.
데몬셋은 기본적으로 노드100개면 파드100개가 만들어짐 물론 스케줄러를 조정하면 조정 가능하다.
%%%%%%%%%%%%%%%
숙제 kubelet은 왜 서비스로 동작하는가?
%%%%%%%%%%%%%%

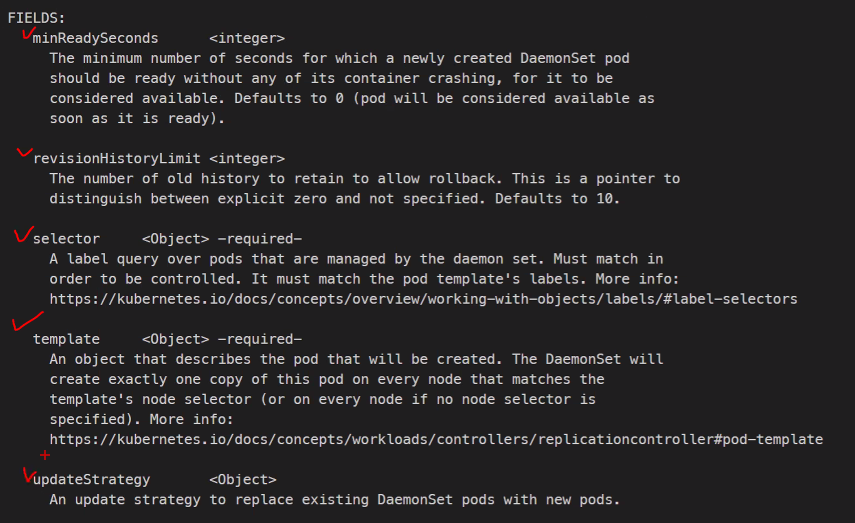
kubectl explain ds.spec.selector
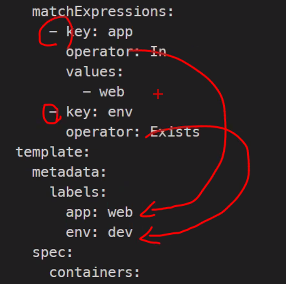
레이블이 여러 개 면 모두가 참이어야 한다는 뜻
vi myweb-ds.yaml
apiVersion: apps/vi
kind: Daeminset
metadata:
name: myweb-ds
spec:
selector:
matchExpressions:
- key: app
operator
values:
- myweb
- key: env
operator: Exists
template:
metadata:
labels:
app: myweb
env: dev
spec:
containers:
- name: myweb
image: ghcr.io/c1t1d0s7/go-myweb
ports:
- containerPort: 8080
protocol: TCP쿠버네티스 시험에서도
쿠버네티스.io 사이트를 보면서 해도 되긴함kubectl create -f myweb-ds.yaml kubectl get ds
node수에 따라 desired수가 결정 됨kubectl get pods -i wide
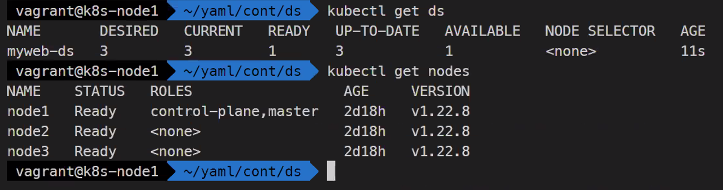
각 노드마다 1개씩 배치된 것을 확인할 수 있음
---
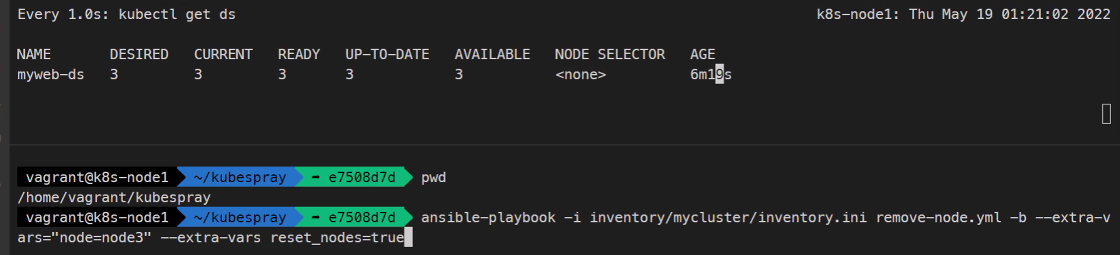
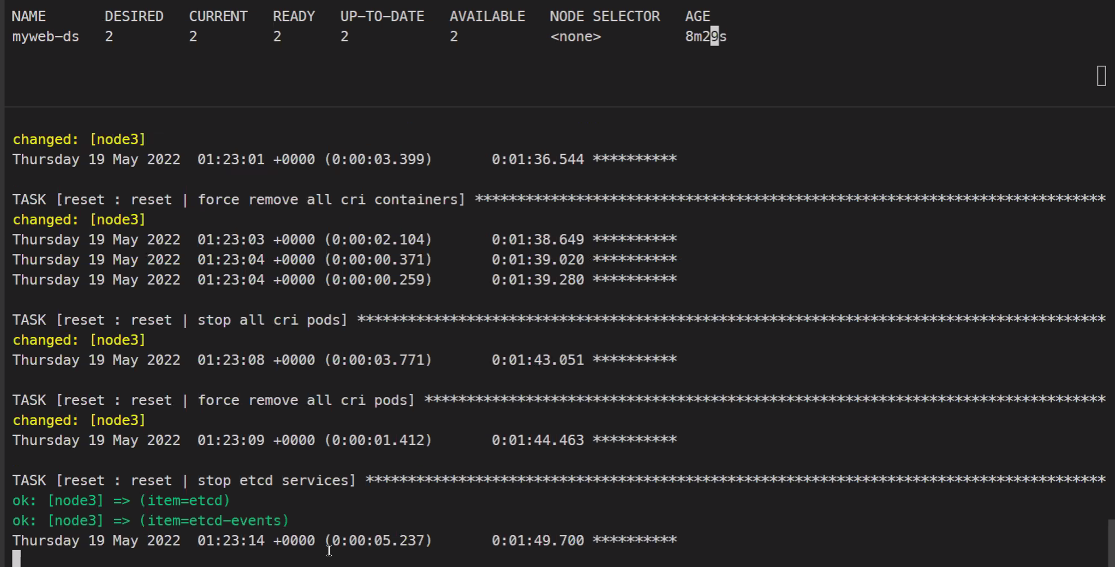
## 노드 제거
https://kubespray.io/#/




---
## 다시 노드 추가

인벤토리파일이 이미 노드3개로 되어있기 때문
```bash
ansible-playbook -i inventory/mycluster/inventory.ini scale.yml -b잡
https://kubernetes.io/ko/docs/concepts/workloads/controllers/job/
잡 그리고 크론잡은 시작이 있고 끝이 있는 어플리케이션이다.

종료를 보장한다는 점이 특징이다.
사용 예시로는
명세서
ML
DL
MLOPs
mkdir job
cd job
systemctl status containerd
systemctl start
kubectl api-resources | grep batch배치작업은 대량은 어떤 순서가 있는 작업을 말함
kubectl explain job.spec
template이 필수임
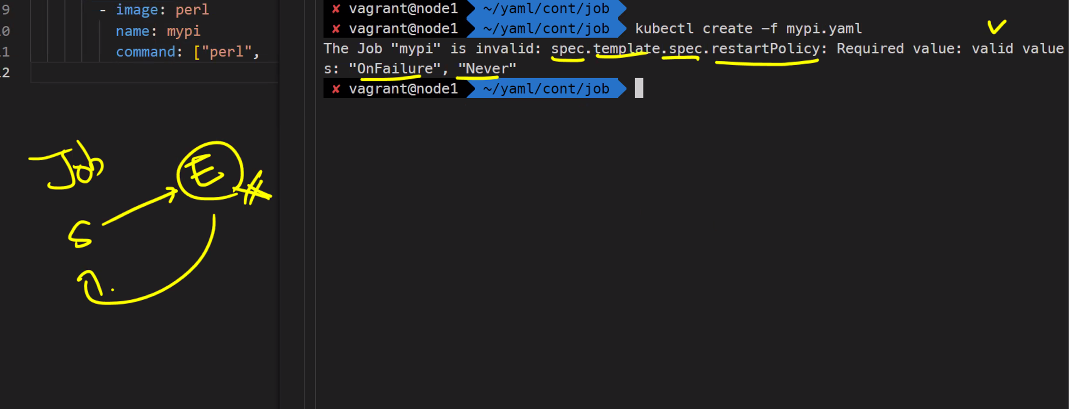
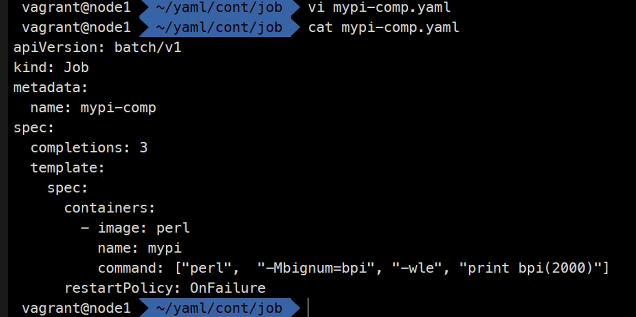
vi mypi.yaml
apiVersion: batch/v1
kind: Job
metadata:
name: mypi
sepc:
template:
spec:
containers:
- image: perl
name: mypi
command: ["perl", "-Mbignum=bpi", "-wle", "print bpi(2000)"]
restartPolicy: OnFailure
### print bpi 2000은 pi값을 2000자리까지 계산하는 것임여담
데몬셋에도 레이블을 붙이는 관습이 있음
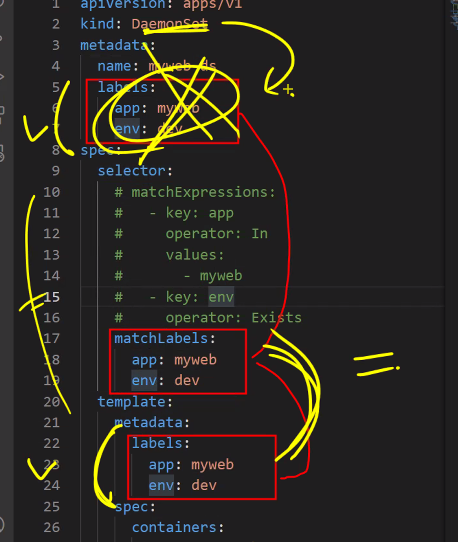
kubectl explain pod.spec.containers.command
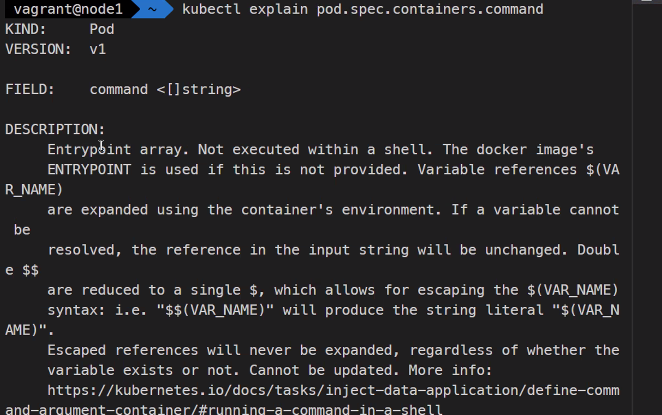
kubectl explain pod.spec.container.args
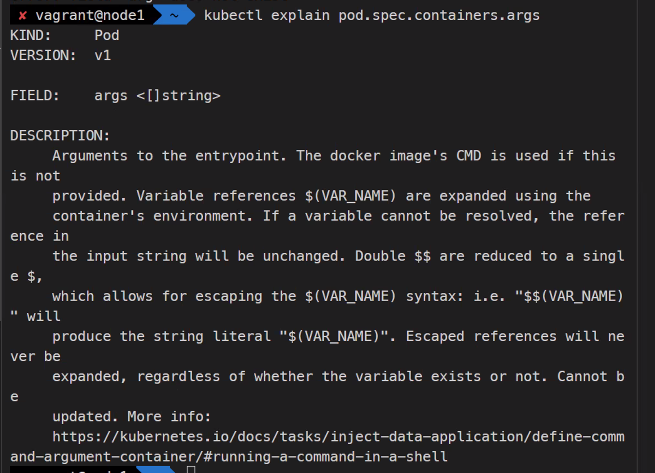
watch -n1 -d kubectl get job,pokubectl logs mypi--1-wmncc
### 계산 값을 볼 수 있음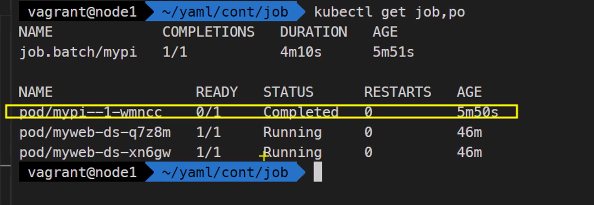
해외 사례중에 클러스터가 죽었는데 그 이유로 job이 쌓이고 쌓여서 나중에는 꽉 차버려서 데이터베이스에 공간이 부족해서 죽어버린 경우가 있다고 한다.
kubelet이 서비스로 동작하는 이유..
부팅과정에 힌트가 있다고 한다.
Job에서 셀렉터를 지정하지 않는 이유
잡이나 크론잡에서는 시작을 하면 끝나는 것을 보장하기 때문에
잡이나 크론잡에서 셀렉터를 사용하게 되면 혹시나 기존에 다른 레이블을 지정해서 해당되는 파드를 꺼버리게 될 수도 있음
잡을 자동으로 지우지 않는 이유
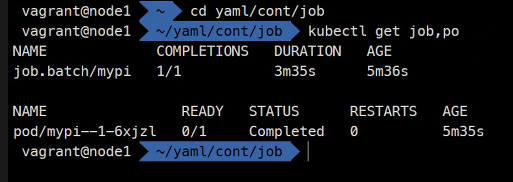
언제 계산을 다 할 줄 알고 지웠을 때 결과가 log에 남는데 log가 지워지면 안되는걸 원칙으로 한다.
잡 ttl설정
activeDeadlineSeconds
Start를 하고난 이후에 너무 오랫동안 동작하는것을 방지하기위해서 데드라인을 지정할 수 있다.
backofflimit
실패를 몇 번 하는것인지
ttlSecondsAfterFinished
자동으로 시간이 지나면 삭제되게 하는 것
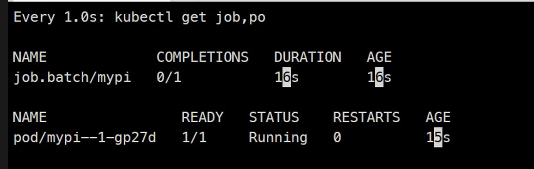
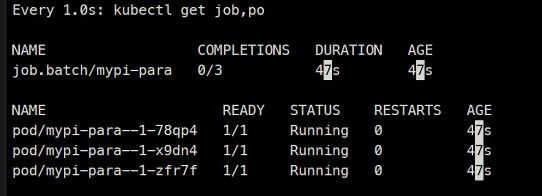
completeions, parallelism
parallelism 병렬
completeions 완료
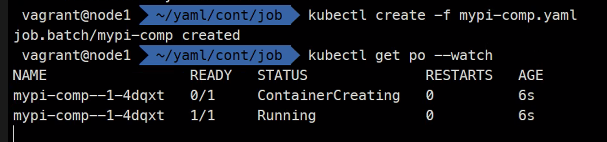
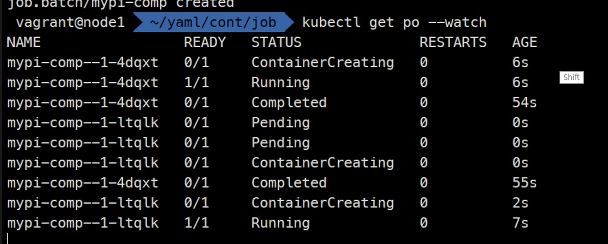
이거를 3번 한다는 의미
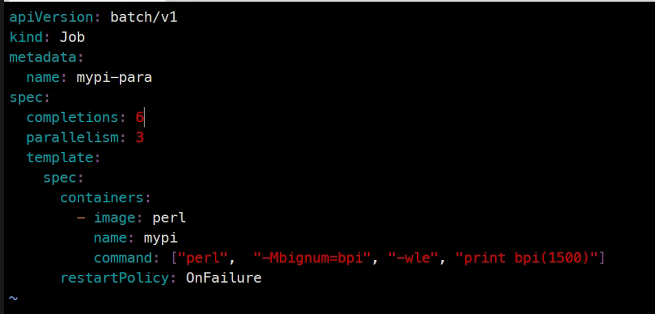
apiVersion: batch/v1
kind: Job
metadata:
name: mypi-comp
spec:
completions: 3
template:
spec:
containers:
- image: perl
name: mypi
command: ["perl", "-Mbignum=bpi", "-wle", "print bpi(2000)"]
restartPolicy: OnFailure병렬처리의 경우..
사용하는 이유는 뭔가 데이터를 가공을 해야하는데 시간이 너무 오래 걸리면 이렇게 병렬처리가 가능하다.
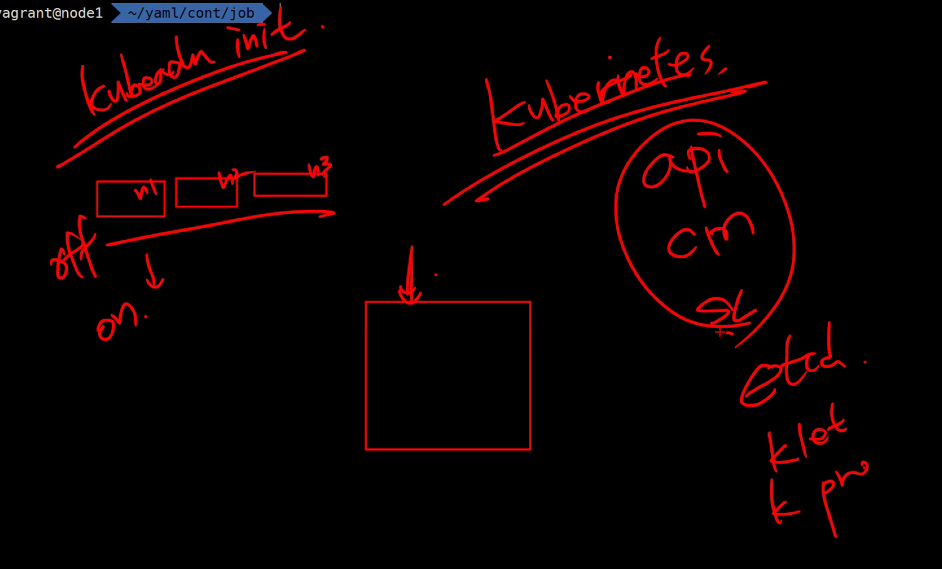
Kubelet은 왜 서비스로 동작하는가?
kubeadm init할 때
pre-flight = 설치가 될지 안될지 검증하는 것.
건호님
-쿠버네티스 클러스터가 운영체제랑 비슷한데, kubeadm init이 클러스터를 생성하는 과정이 운영체제의 부트 과정과 비슷하다고 생각해서 따라서 init 시 kubelet 호출하여 실행되기 때문에 kubelet이 서비스라고 생각합니다
효주님
-건호 생각에 좀 더해서 kubeadm init 명령을 진행하고 나면 etcd pod가 local etcd로부터 정보를 가지고 오는 순서가 kubeadm이 클러스터를 생성하고 kubelet 컴포넌트가 업로드 되는 순서보다 먼저였고 그렇다면 etcd에서 가져온 정보로 kubelet이 시스템처럼 동작해서 부팅을 하는 것이 아닌가.. 라고 생각을 더 해봤습니다!
https://kubernetes.io/docs/reference/setup-tools/kubeadm/kubeadm-init/#synopsis
https://kubernetes.io/ko/docs/concepts/workloads/pods/#%EC%A0%95%EC%A0%81-%ED%8C%8C%EB%93%9C
자기자신(쿠버네티스)는 누가 띄워주어야하느냐
pod로 띄운다.
service는 enable되어있으면 스타트가 되어지니까
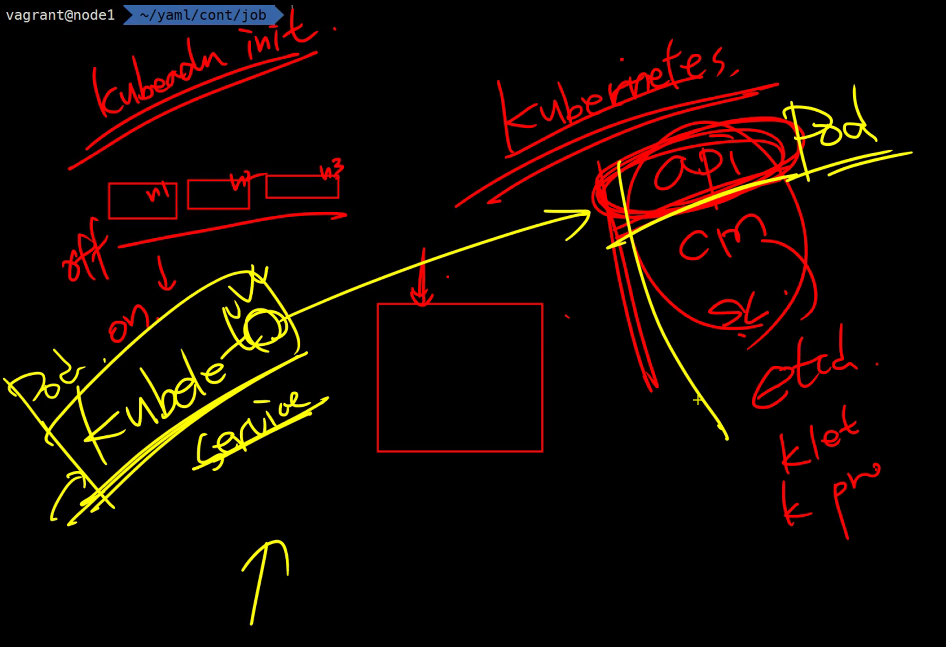

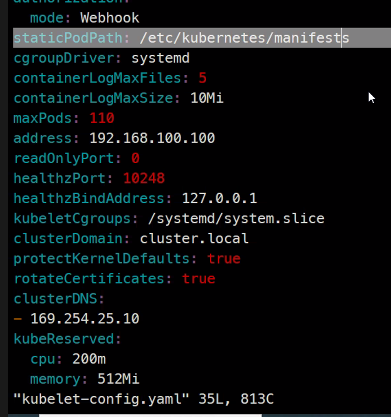
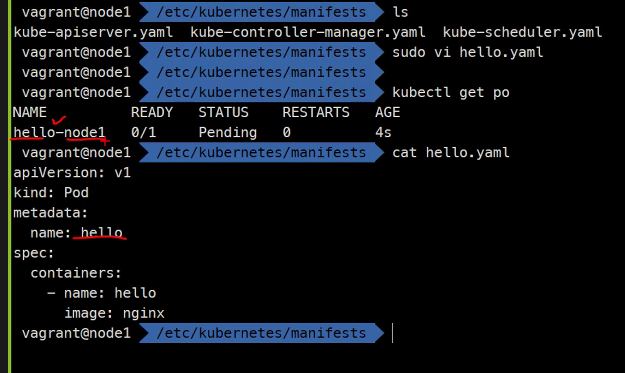
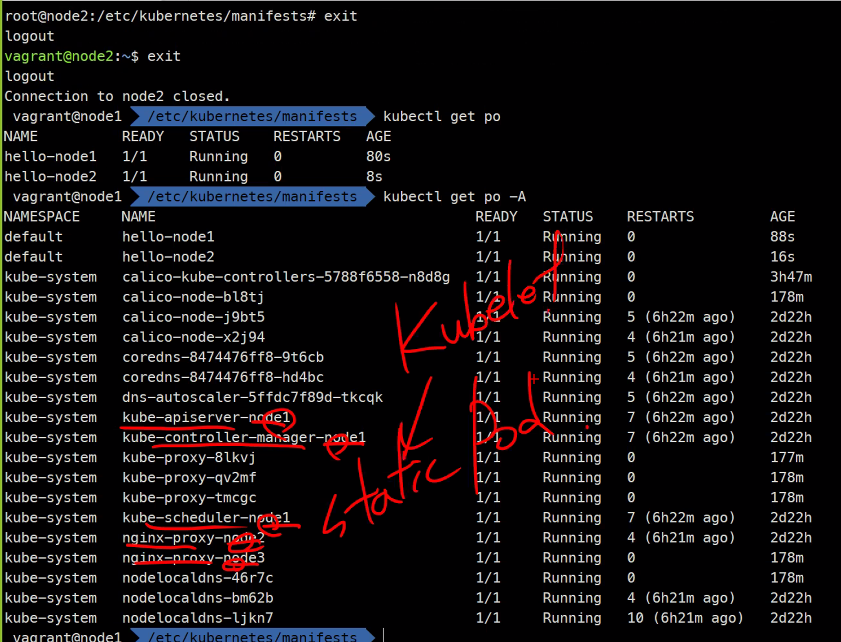
static Pod들은 kubelet이 관리한다.
크론잡
버전을 잘 생각해야한다..
github에 보면 로그인을 하고 Notification을 누르면 새로운 버전이 나올 때 마다 메일로 알림이 오기 때문에 이런것들의 정보를 확인할 수 있다.
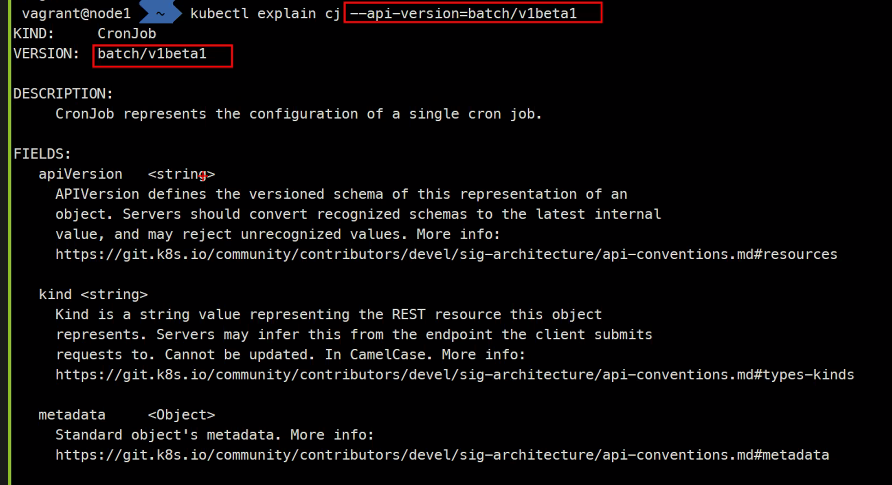
이렇게 하면 다른 버전을 볼 수 있다.
kubectl api-versions | grep autoscaling
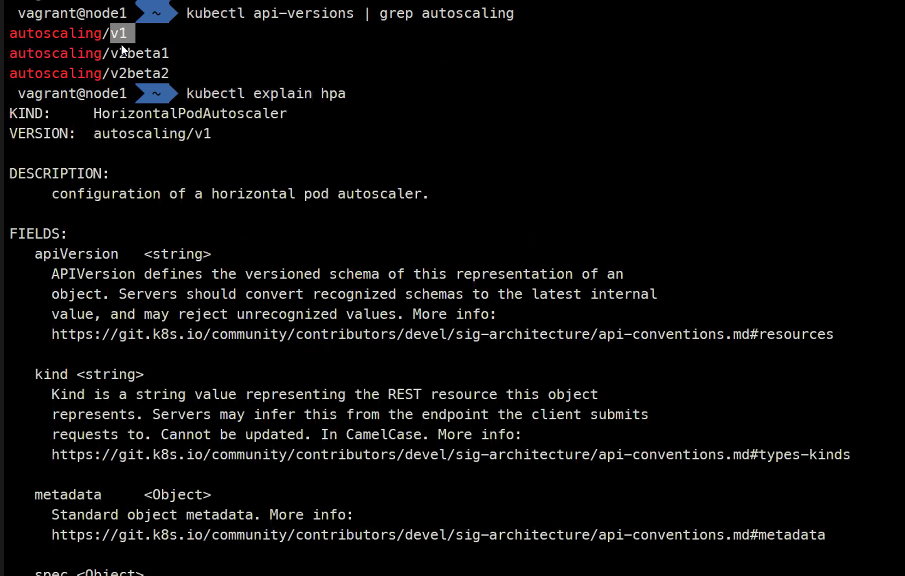
그래서 kubectl explain hpa --api-version=autoscaling ...해주어야함
kubectl
crontab.guru
사이트에 schedule을 선언하는데 도움이 되는것이 있음
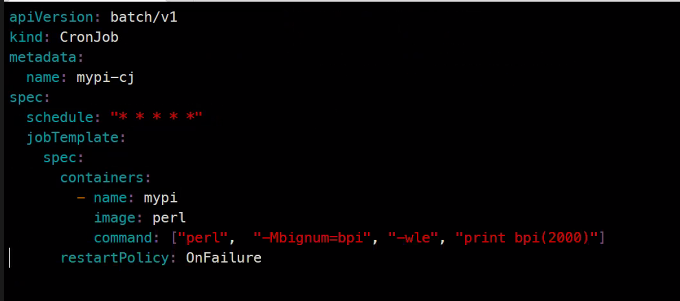
apiVersion: batch/v1
kind: CronJob
metadata:
name: mypi-cj
spec:
schedule: "* * * * *"
jobTemplate:
spec:
template:
spec:
containers:
- name: mypi
image: perl
command: ["perl", "-Mbignum=bpi", "-wle", "print bpi(2000)"]
restartPolicy: OnFailure
### 매 분마다 실행을 할것임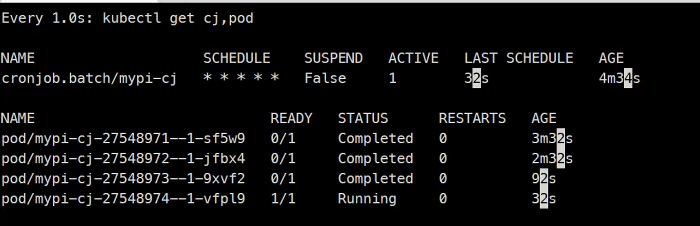
크론잡은 기본적으로 4개까지만 생성됨
설정값은 아래
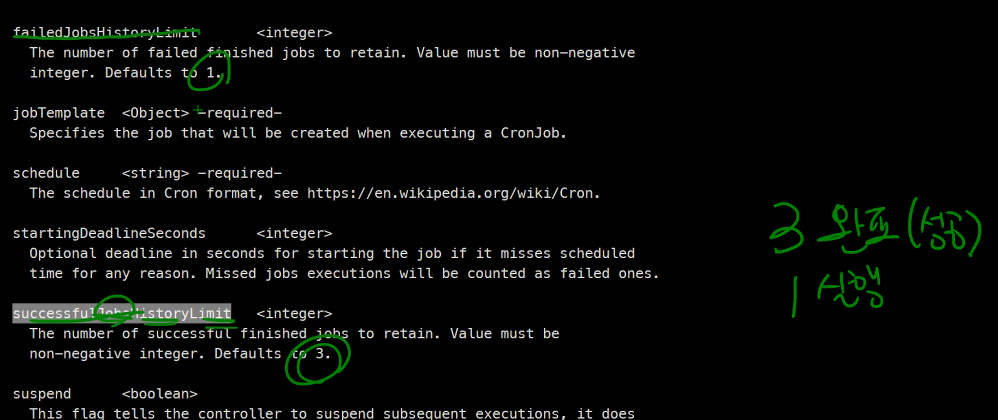
실패는 1개가 기본값
동시에 실행되어도 상관이 없으면 괜찮은데 그게 아니라면...
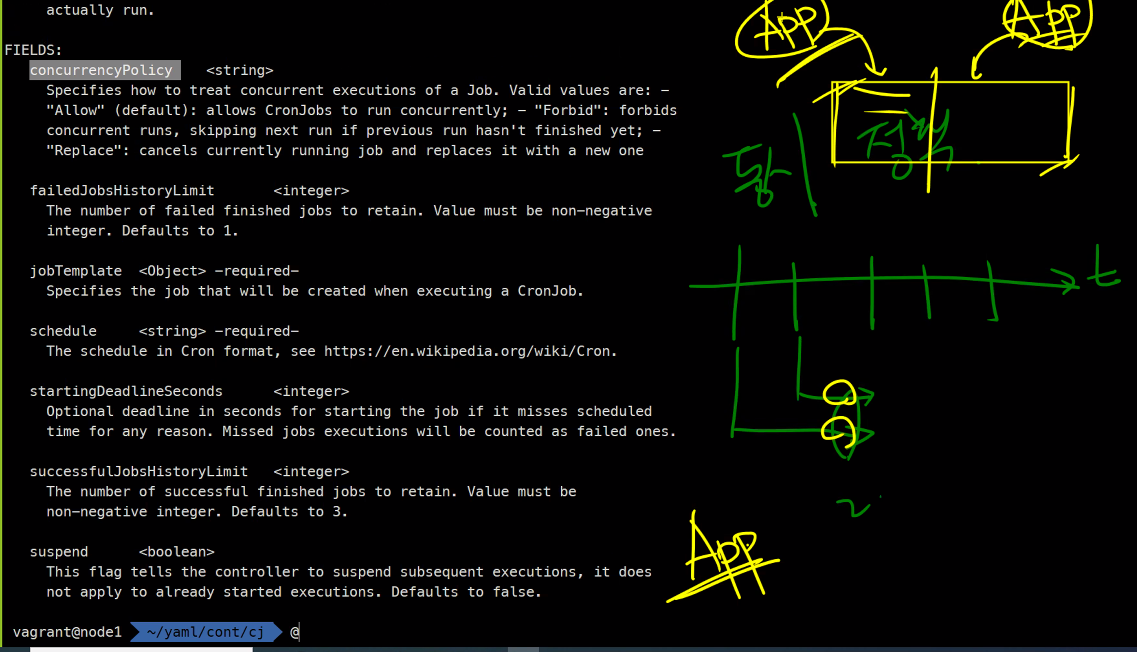
기본값은 allow임 금지하려면 Forbid임
그럼 Forbid를 그림으로 설명하면
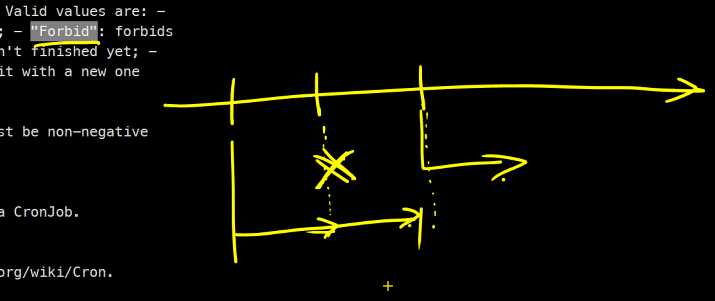
Replace를 그림으로 설명하면..
실습해보면..
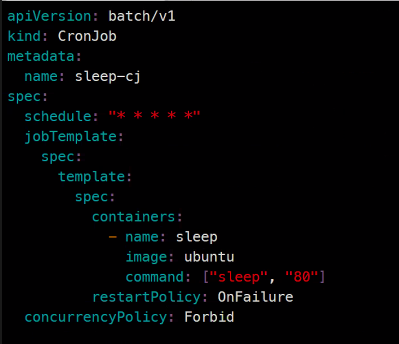
apiVersion: batch/v1
kind: CronJob
metadata:
name: sleep-cj
spec:
schedule: "* * * * *"
jobTemplate:
spec:
template:
spec:
containers:
- name: sleep
image: ubuntu
command: ["sleep", "80"]
restartPolicy: OnFailure
concurrencyPolicy: Forbid
### 다음 번에는 Forbid를 Replace로 바꾸어서...kubectl create -f sleep-cj.yaml크론잡이 100회 일정이 누락되면 중단이 된다.
Forbid에서 실행되지 못하고 지나가면 한 번의 실패라고 간주한다.
Replace의 경우 이렇게 된다.
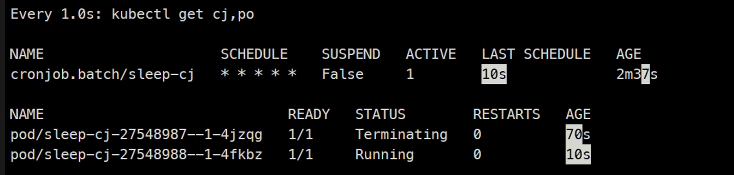
Deadlineseconse 는 ...100초동안 실패한 작업이 있는지 체크한다.
cronjob을 사용하는 예시는 택배 운송 현황을 API로 불러와서 batchjob을 돌리는식으로 한다. 10분 또는 몇 분에 맞게 작업을 하게 된다.
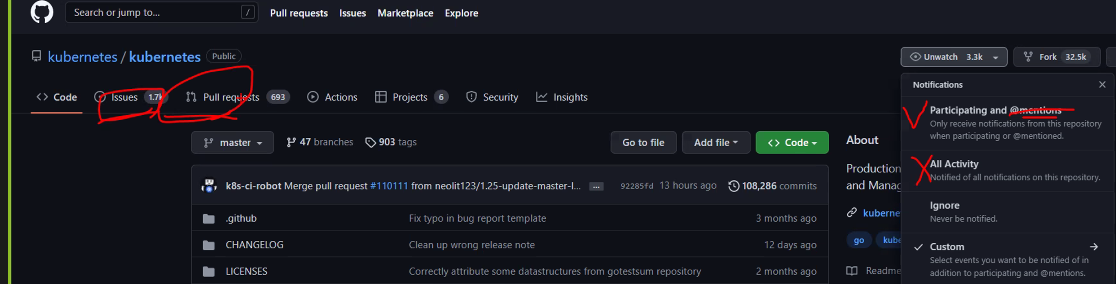
github
계정에 Notifications
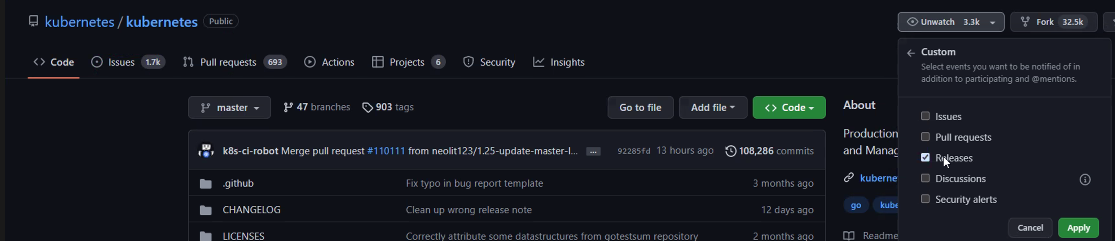
이렇게 하면 새로운 버전이 나왔을 때 알림을 받을 수 있다.
테라폼 1.2버전이 나왔더라
Pod 노출
서비스에 대해서..
https://kubernetes.io/ko/docs/concepts/services-networking/
서비스라는 리소스 자체는 쉽다
https://kubernetes.io/ko/docs/concepts/services-networking/service/
서비스는 파드집합에서 실행중인 어플리케이션을 네트워크 서비스로 노출하는 방법이다.
kubectl expose에 관련된 내용이 될것이다.
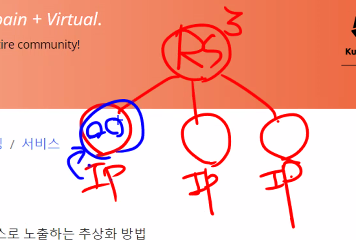
pod1개에 ip1개를 부여받는다.
이때 서비스라는 아이에는 selsector가 있고 pod는 label이 있어서 찾게된다 그리고 svc는 dns이름을 부여받고 이러기 위해서는 kube-dns가 설치가 되어야하고 이를 위해 coredns를 사용하게 된다.
중요한것은 kube-dns는 클러스터 내에서 사용되는것이다.
외에서 dns를 사용하려면 AWSRoutr53
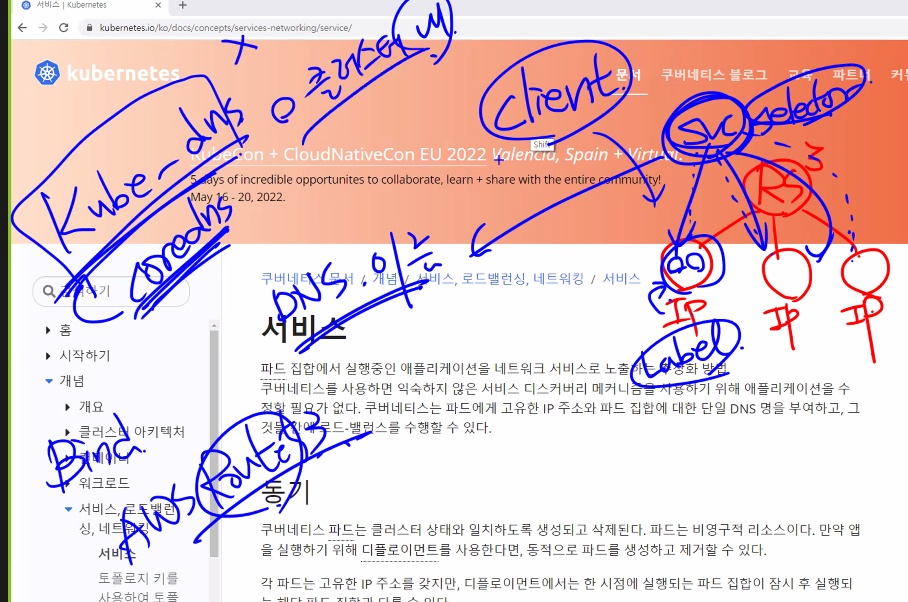
실습환경
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: myweb-rs
spec:
replicas: 3
selector:
matchLabels:
app: web
env: dev
template:
metadata:
labels:
app: web
env: dev
spec:
containers:
- name: myweb
image: ghcr.io/c1t1d0s7/go-myweb
ports:
- containerPort: 8080
protocol: TCP
```bash
kubectl api-resources | grep services
kubectl explain service.spec
### clusterIP는 특정 IP를 부여할 수는 있지만 굳이 사용하지는 않는다.
### ports는 서비스의 포트이다. AWS할 때 LB에 접속할 포트번호가 있고
### LB의 BG에 접속할 VM의 port가 따로 있는걸 생각해보자
### 그래서 여기의 ports는 서비스의 포트이다.
### selector는 서비스할 Pod의 label
### loadPort와 LoadBalancer는 클러스터 외부 ClusterIP는 클러스터 내부 이런식으로 나누어짐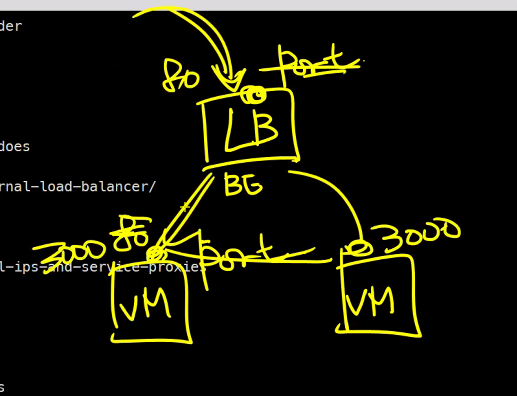
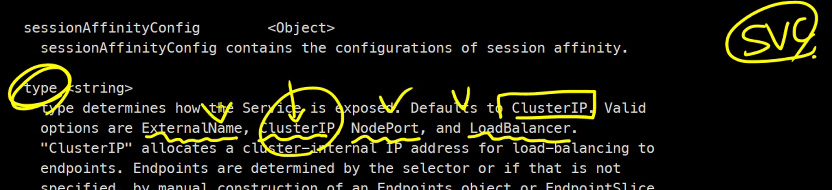
kubectl explain service.spec.ports
### 이름, 프로토콜, 타겟포트
### 타겟포트는 컨테이너의 포트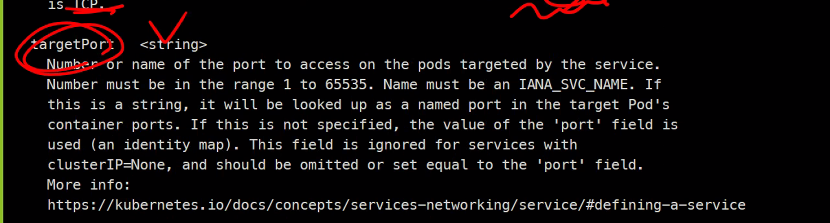
실습파일
apiVersion: v1
kind: Service
metadata:
name: myweb-svc
spec:
selector:
app: web
ports:
- port: 80
targetPort: 8080
kubectl create -f myweb-rs.yaml -f myweb-svc.yaml
이런식으로 가능
kubectl get rs,po,svc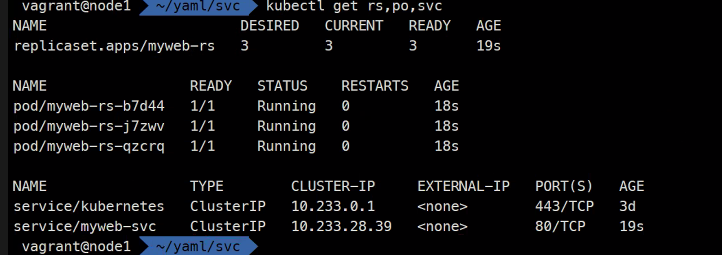
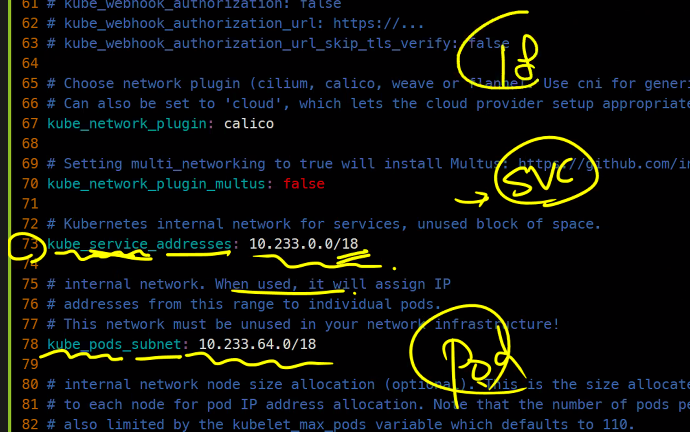
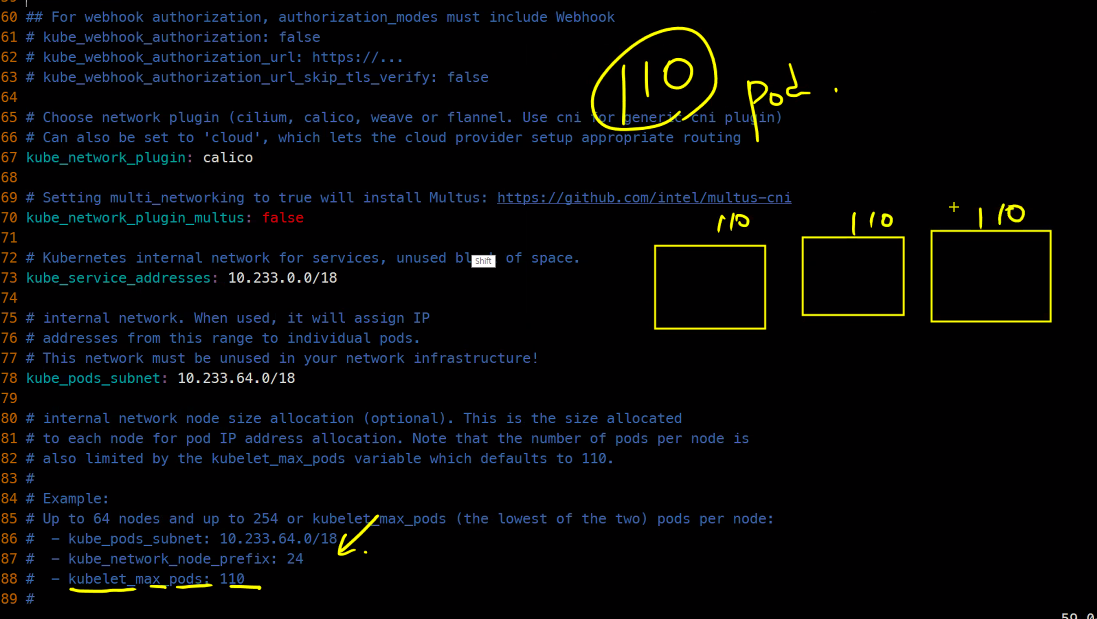
한 노드당 110개가 최대라고 함
이렇게 나와 있음
Pod가 110개면 적어보이지만 아주 많은 양이라고 함
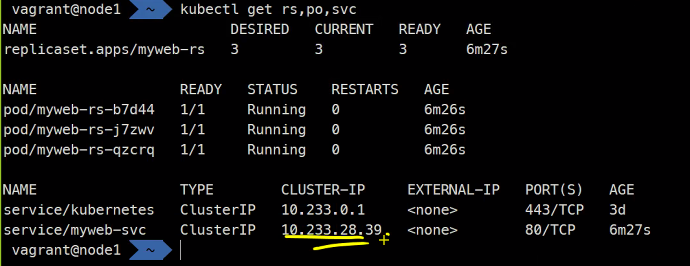
이 IP가 이 대역에서 할당이 된것임
kubectl get svc myweb-svc
kubectl describe svc myweb-svc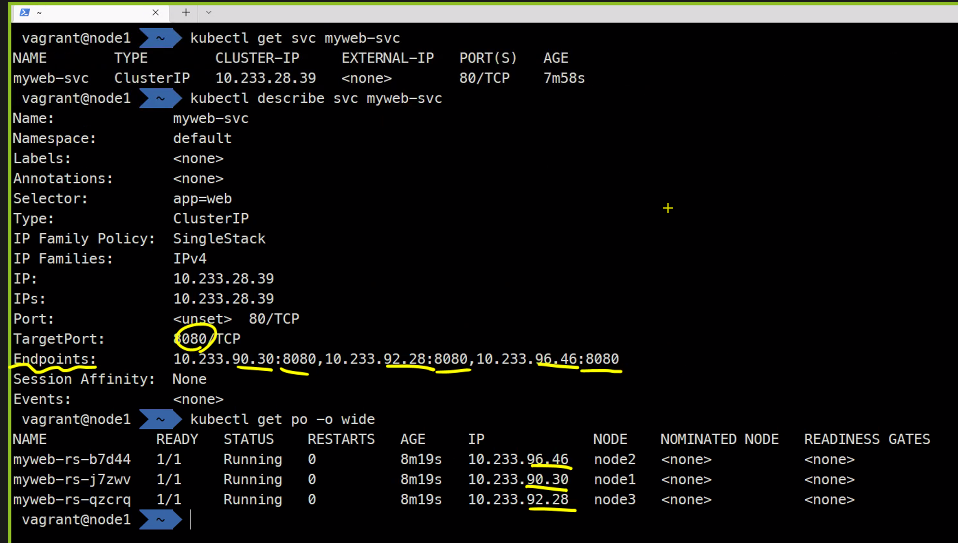
kubectl run client -it --image ubuntu bash
curl
apt update; apt install curl
curl 10.233.28.39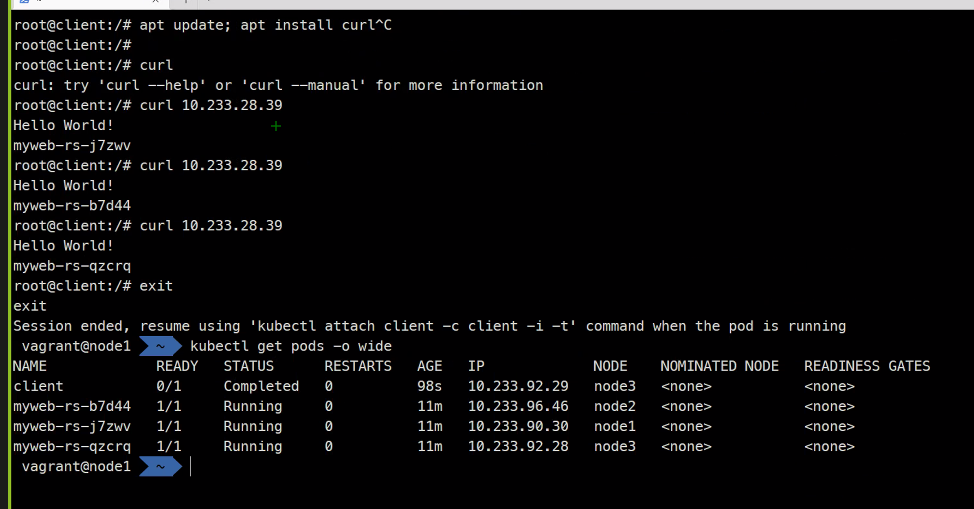
라운드로빈 로드밸런싱이 잘 되는것 까지 확인 가능하다.
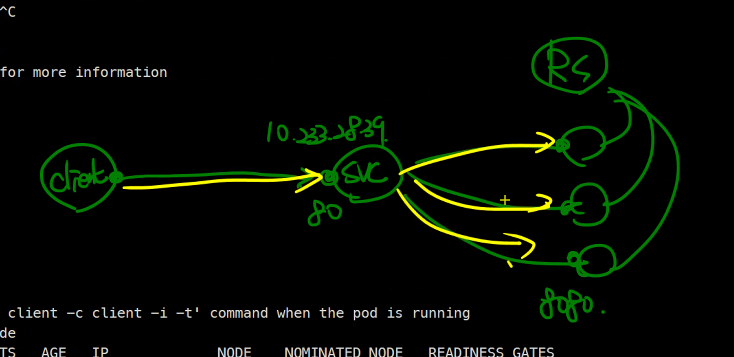
엔드포인트가 같은 이름으로 자동으로 만들어진다.
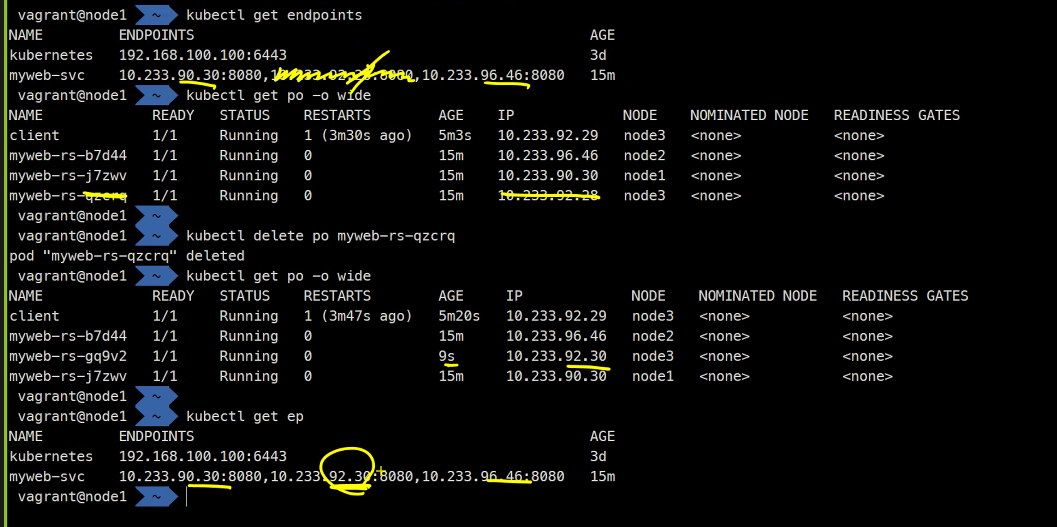
해당 정보들이 엔드포인트가 가지고 있다고 한다.
VM으로 작업할 때는 이런 자동화가 안되는데 이건 됨..

kubectl run nettool -it --image ghcr.io/c1t1d0s7/network-multitool
### 네트워크 확인위한 패키지들 설치한거임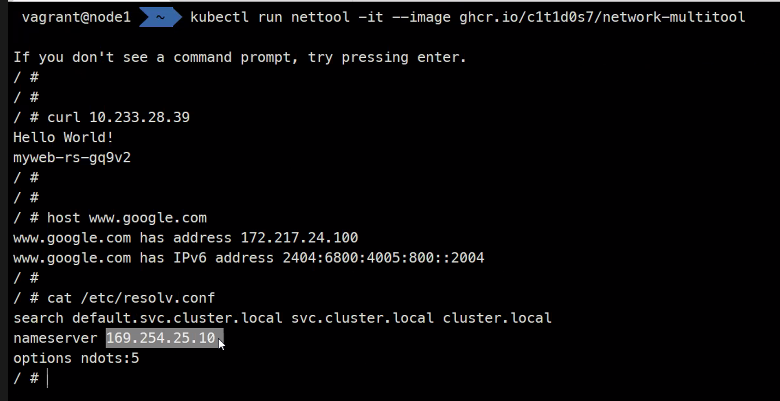
코어 DNS IP주소...

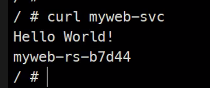
이런식으로 서비스 이름만으로 접속이 잘 됨
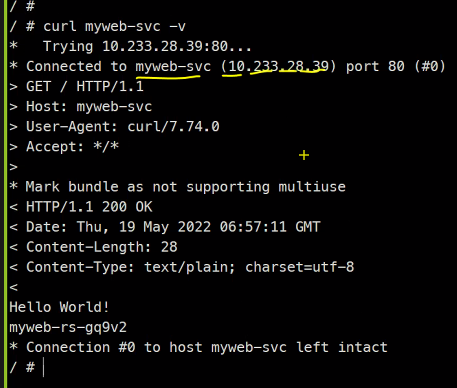
여기에서는 내부용 로드밸런서만 다루었다고 함 !.
최종 프로젝트에 대한 공지사항

