TLS/SSL Terminatation with Ingress
SSL은 사용하지 않지만 상징적인 의미로 사용하고있다고 한다.
현재는 TLS를 사용함
https://en.wikipedia.org/wiki/TLS_termination_proxy
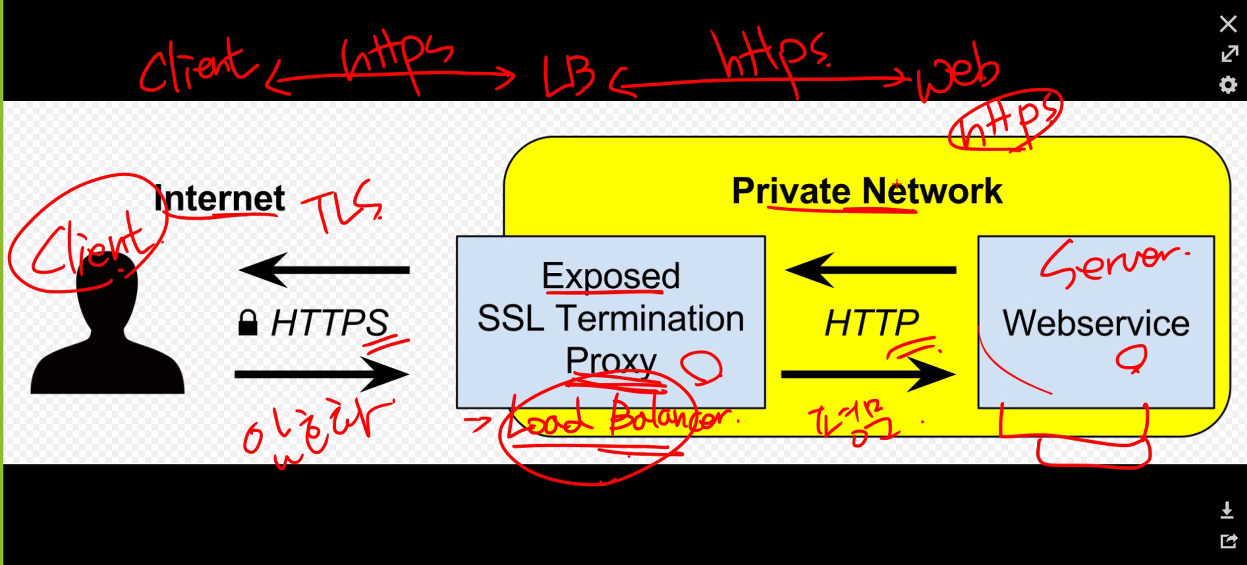
저번에 했던 내용은 https로만 통신을 했지만
이번에는 특정 구간만 https를 사용하게 할 수 있음
기본적으로 Pod를 여러 개 사용하게 되는데 그렇게 되면 각 Pod마다 인증서를 따로 관리를 해주어야한다. 그런 관리 어려움이 존재한다.
그리고 암호화 복호화 과정에서 cpu를 많이 사용하게 된다.
인증서는 LB에서만 관리해주면 된다.
다만 그래서 LB의 성능이 어느정도 중요해질 수 있다.
그리고 물론 내부 네트워크에서도 보안장비를 추가할 수 있다. 그러면 좀 더 안전한 구성이 가능하다.
끄적끄적..
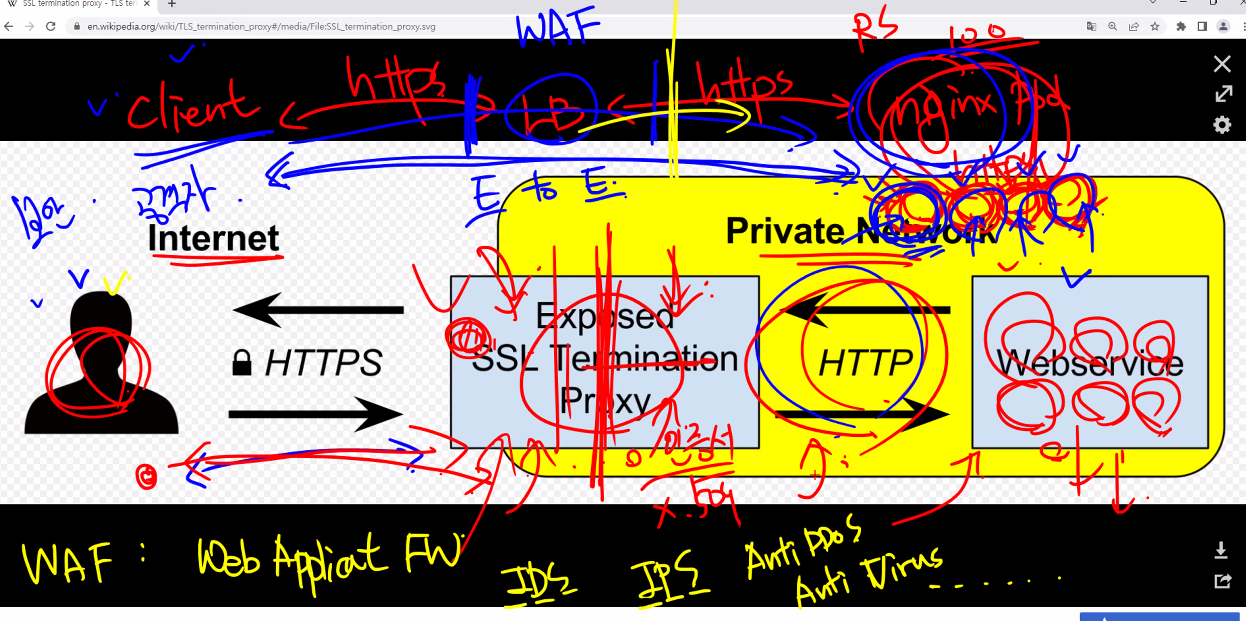
kubectl explain ing.spec
kubectl explain ing.spec.tls
### 보면 tls에 대한 항목이 있다.
### tls를 보면 hosts가 있고 도메인에 대한 내용이다.
### secretName은 인증서가 있는 secret을 참조하는 부분이다.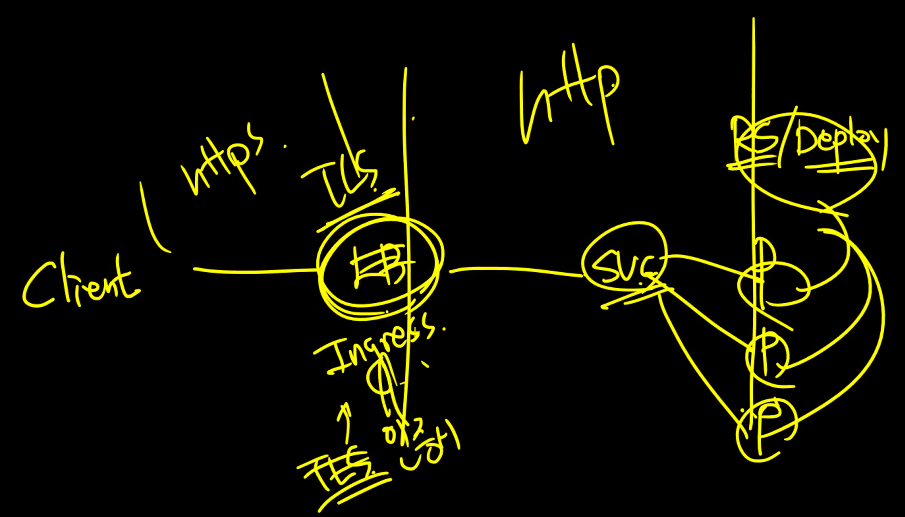

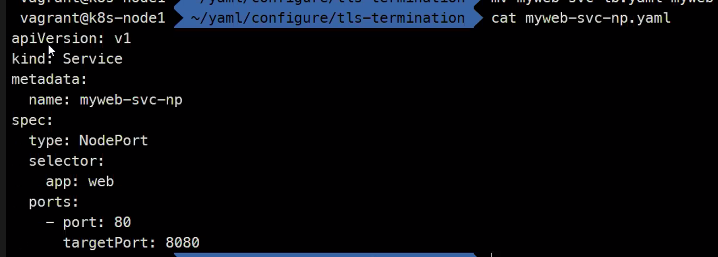
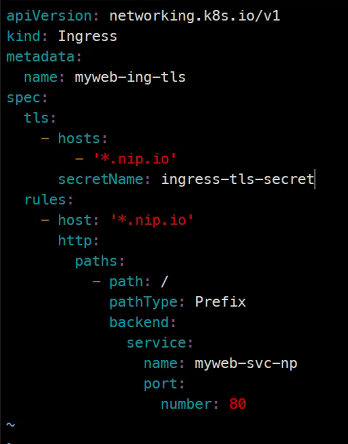

tls를 하면 자동으로 443번이 열림

curl -k https://192-168-100-100.encore.xyz
Headless
mkdir headless
cd headless
### 직전에 사용했던 rs와 svc를 사용함
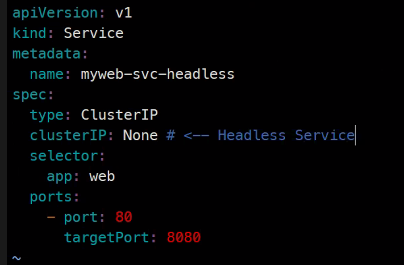
이 설정이 Headless임
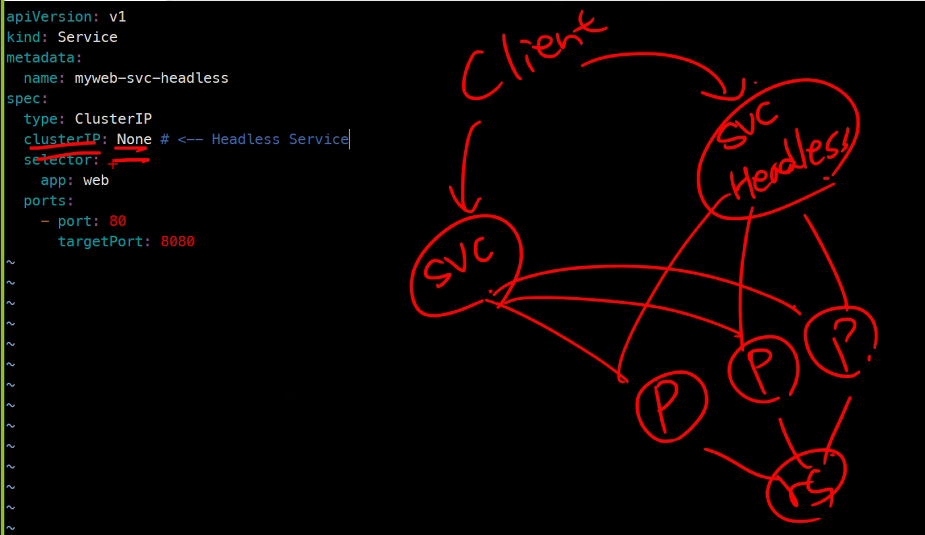
그림으로 그려보면
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: myweb-rs
spec:
replicas: 2
selector:
matchLabels:
app: web
env: dev
template:
metadata:
labels:
app: web
env: dev
spec:
containers:
- name: myweb
image: ghcr.io/c1t1d0s7/go-myweb
ports:
- containerPort: 8080
protocol: TCP
apiVersion: v1
kind: Service
metadata:
name: myweb-svc
spec:
type: ClusterIP
selector:
app: web
ports:
- port: 80
targetPort: 8080
apiVersion: v1
kind: Service
metadata:
name: myweb-svc-headless
spec:
type: ClusterIP
clusterIP: None # <-- Headless Service
selector:
app: web
ports:
- port: 80
targetPort: 8080
kubectl create -f .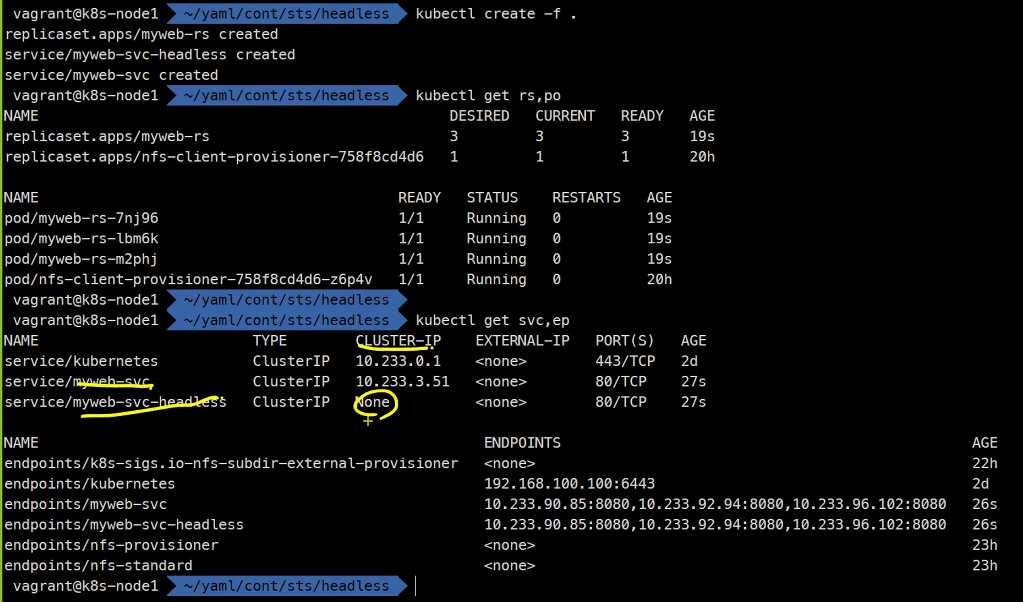
kubectl run nettool -it --image ghcr.io/c1t1d0s7/network-multitool --rm
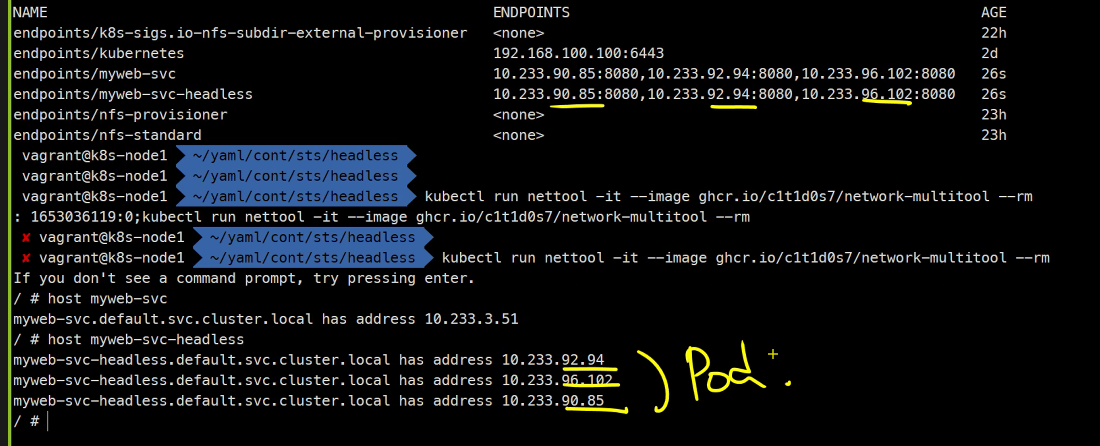
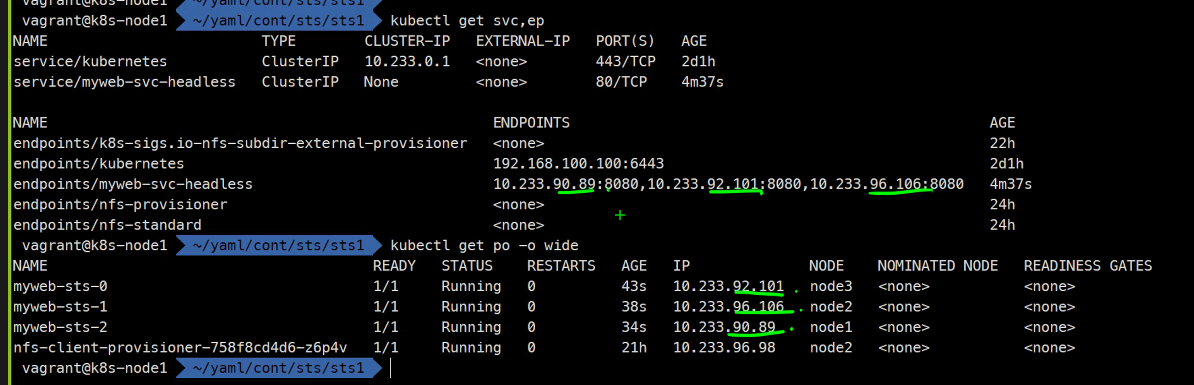
서비스의 IP자체가 없는걸 headlessip라고 하고 이 headless를 쿼리하면 Pod3개가 응답하게됨
kubectl scale rs myweb-rs --replica=5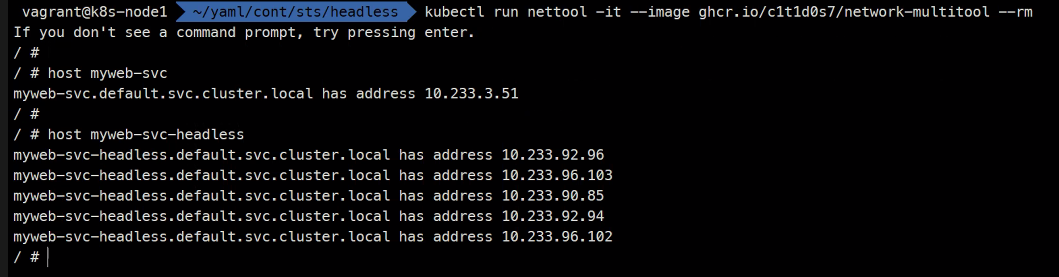
이 상태에서 Statefulset 을 하게되면 FQDN이 다 다르게 된다.
즉, Pod에 고유성을 부여할 수 있다.
Statefulset
https://kubernetes.io/ko/docs/concepts/workloads/controllers/statefulset/
http://cloudscaling.com/blog/cloud-computing/the-history-of-pets-vs-cattle/
애완동물은 고유성이있다. 그래서 교체하기가 어렵다.
가축은 고유성이 없고 교체하기가 쉽다.

이로 인해 반드시 headless서비스가 필요하다.
mkidr sts1
cd sts1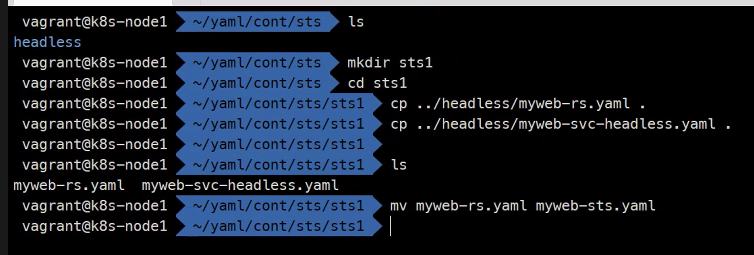
이런식으로 아까꺼를 사용하고
vi apiVersion: apps/v1
kind: StatefulSet
metadata:
name: myweb-sts
spec:
replicas: 3
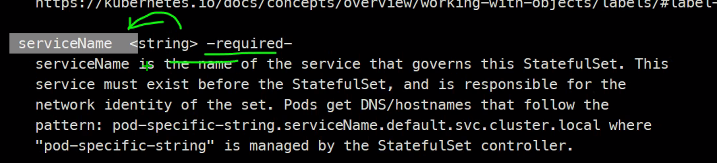
serviceName: myweb-svc-headless
selector:
matchLabels:
app: web
env: dev
template:
metadata:
labels:
app: web
env: dev
spec:
containers:
- name: myweb
image: ghcr.io/c1t1d0s7/go-myweb
ports:
- containerPort: 8080
protocol: TCP
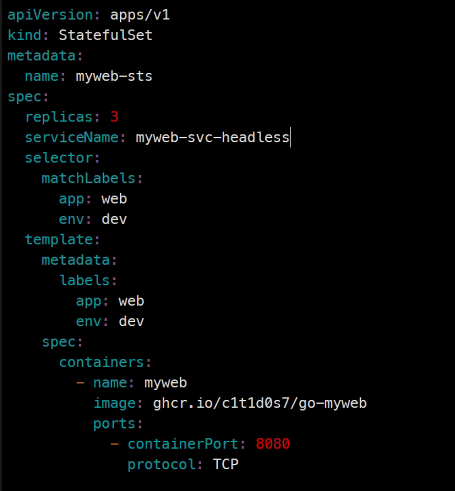
create하고..
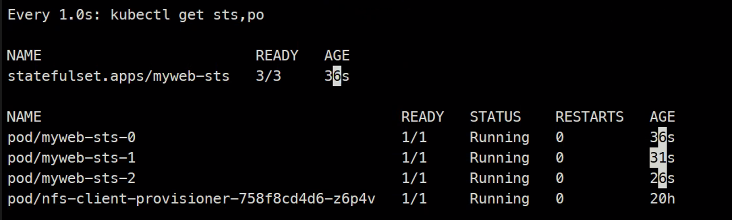
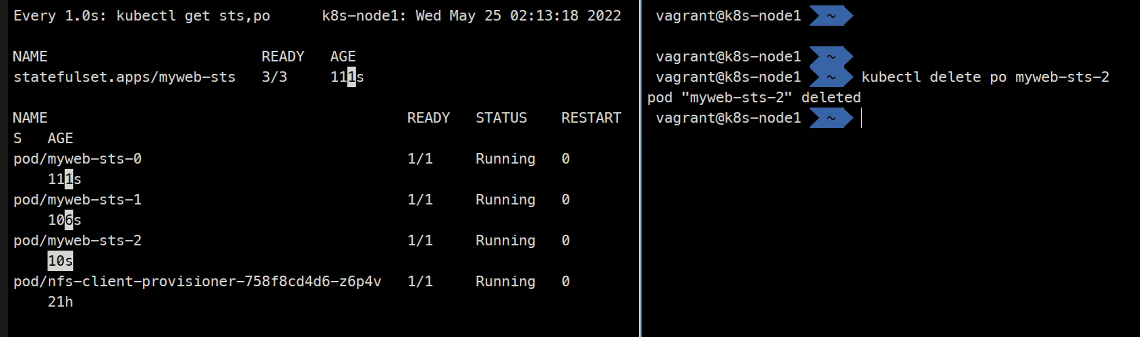
이렇게 삭제를 해도 다시 똑같은 이름의 Pod를 만들게된다
결국 이름을 고정시키게되어 고유값이 생기고 이걸 활용할 수 있게 된다.
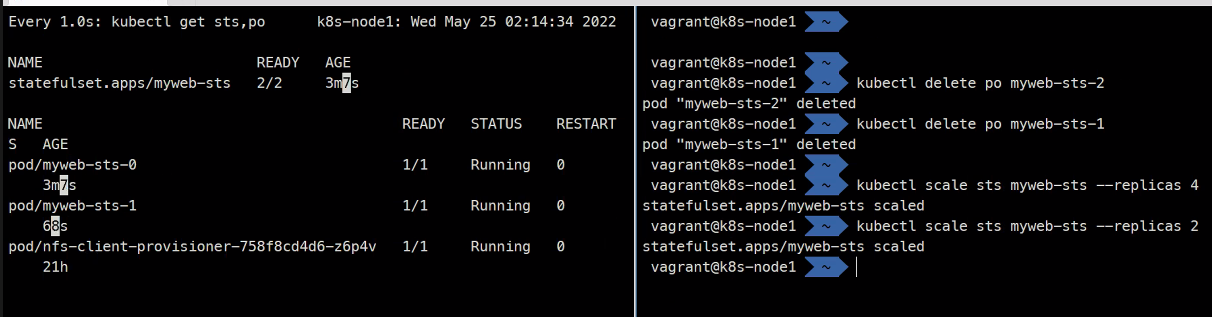
항상 순서를 지키면서 스케일링하게 된다
kubectl run nettool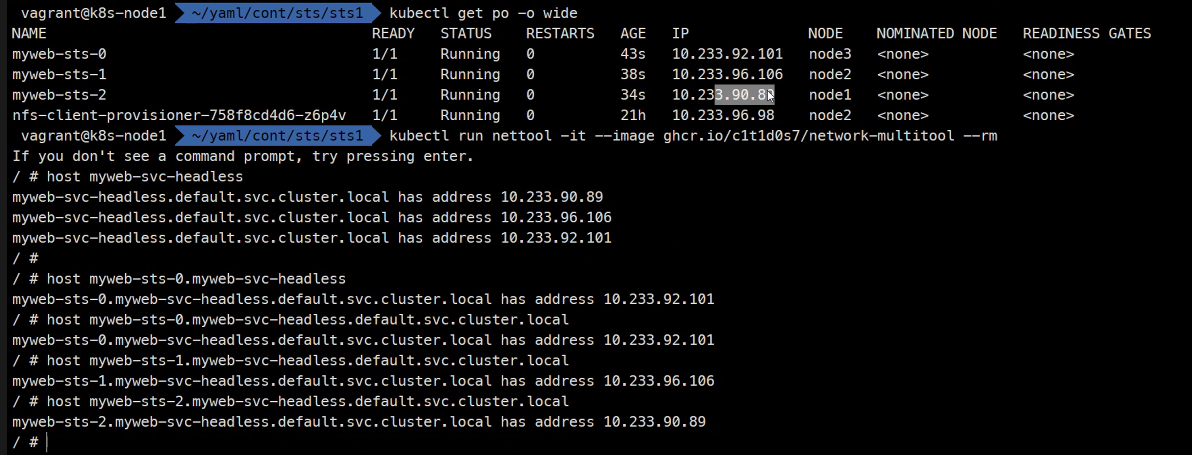
이게 headless 서비스와 stateful 서비스를 활용해서 Pod를 특정할 수 있게 된다.

사용하는 경우를 구분할 줄 알아야함

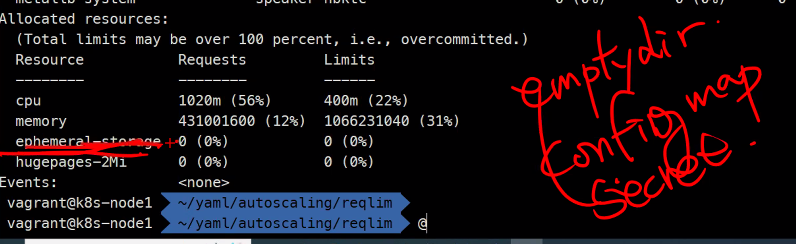
무조건 PVC를 붙여야함
이 때 다이나믹 프로비저닝을 사용함
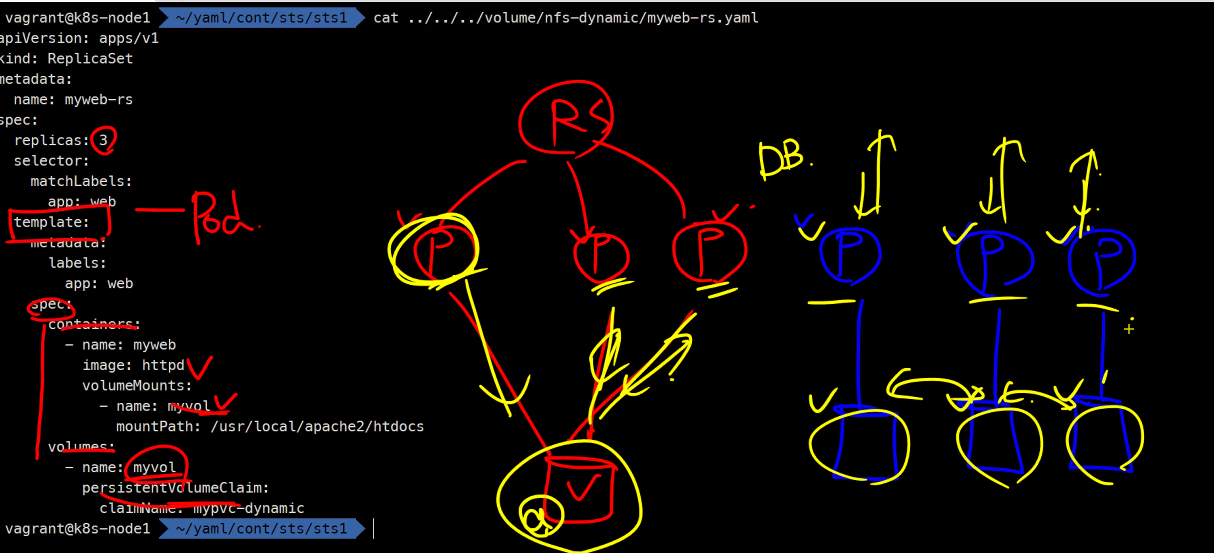

볼륨 데이터를 동기화 할거냐 안할거냐는 그 다음문제임
예제

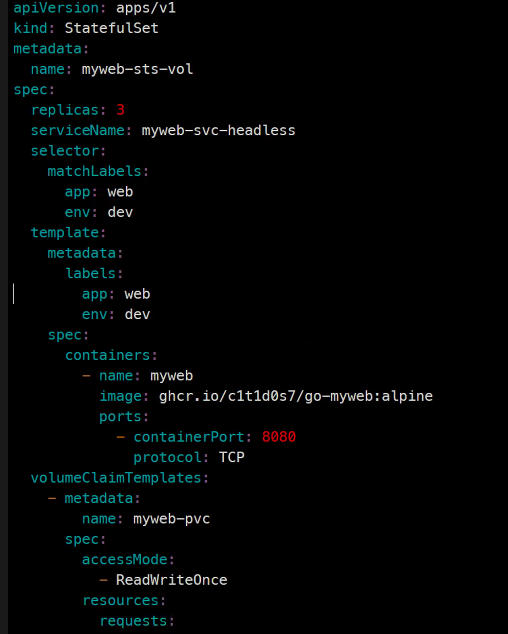
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: myweb-sts-vol
spec:
replicas: 3
serviceName: myweb-svc-headless
selector:
matchLabels:
app: web
env: dev
template:
metadata:
labels:
app: web
env: dev
spec:
containers:
- name: myweb
image: ghcr.io/c1t1d0s7/go-myweb:alpine
ports:
- containerPort: 8080
protocol: TCP
volumeMounts:
- name: myweb-pvc
mountPath: /data
volumeClaimTemplates:
- metadata:
name: myweb-pvc
spec:
accessModes:
- ReadWriteOnce
resources:
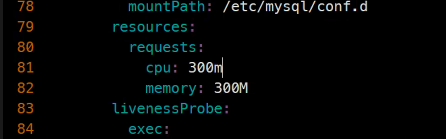
requests:
storage: 1G
storageClassName: nfs-client
kubectl create -f myweb-svc-headless.yaml
kubectl create -f myweb-sts-vol.yaml
kubectl get sts,po,pv,pvc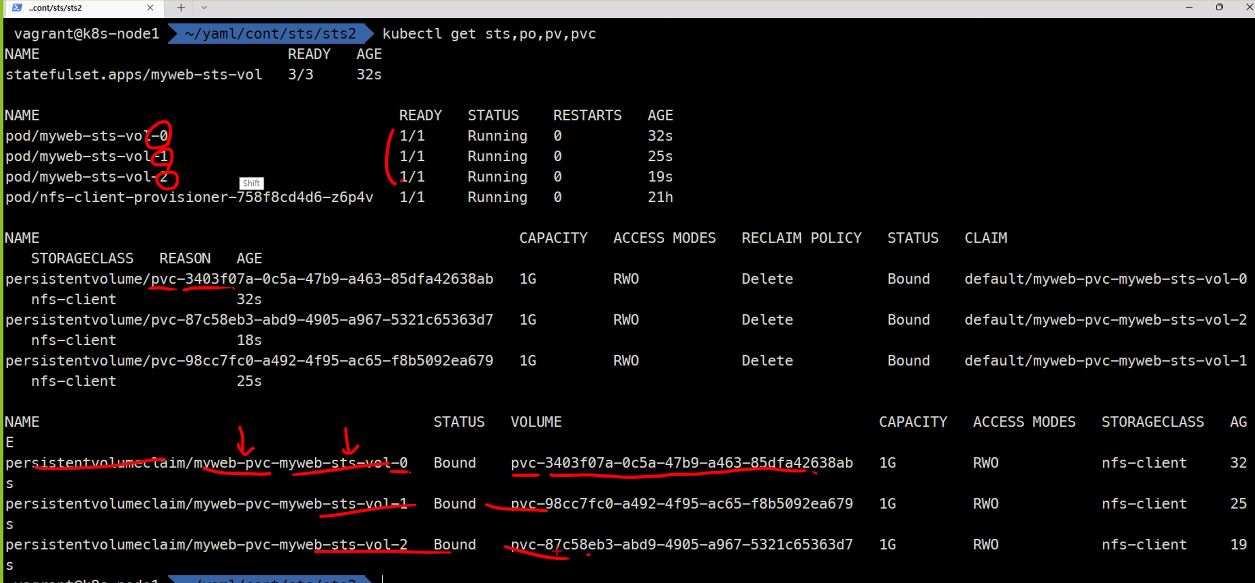
kubectl scale sts myweb-sts-vol --replicas=2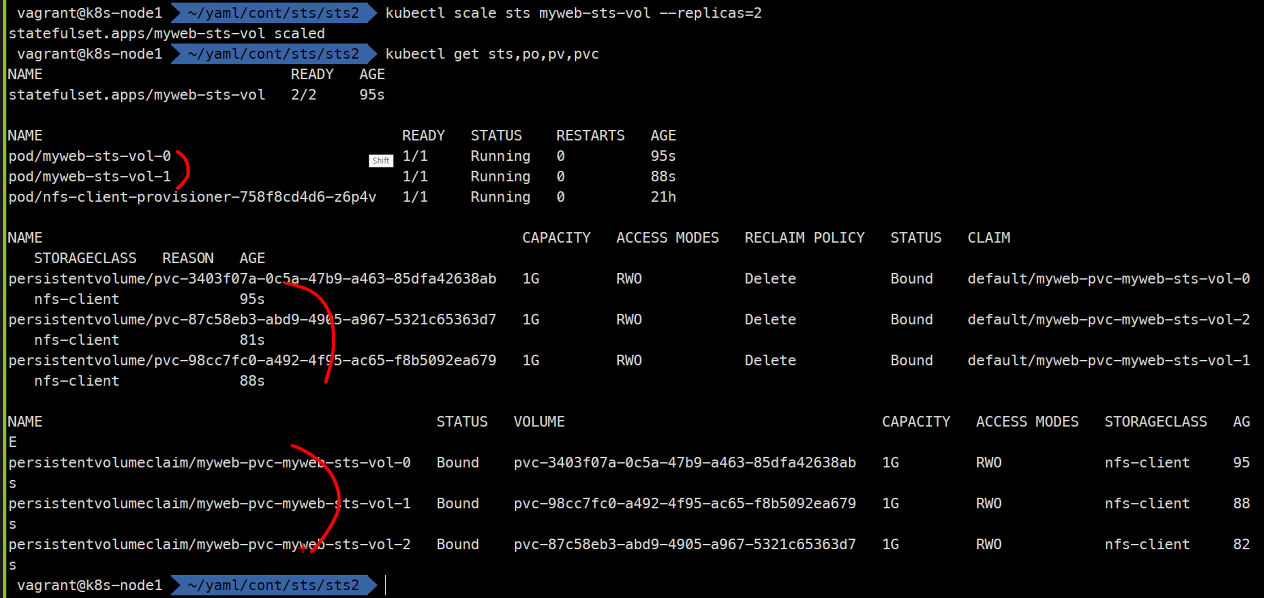
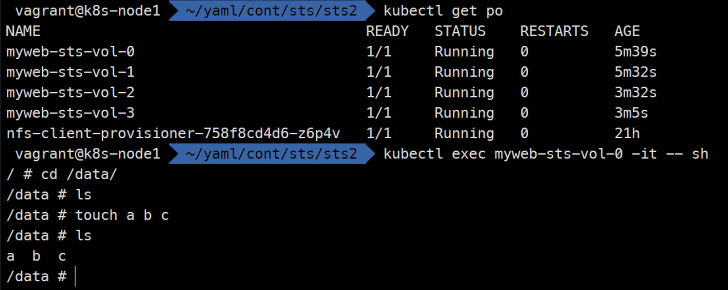

이렇게 서로의 볼륨이 구분지어진다.
그리고 삭제하더라도 똑같은 Pod가 똑같은 볼륨에 고유하게 유지한다.
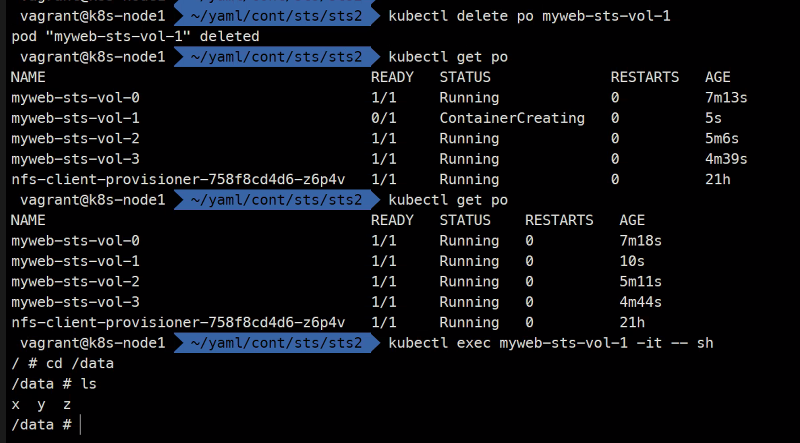
다음시간에는 mysql을 구현해볼 예정임
지우고..

mysql 예제
https://kubernetes.io/docs/tasks/run-application/run-replicated-stateful-application/

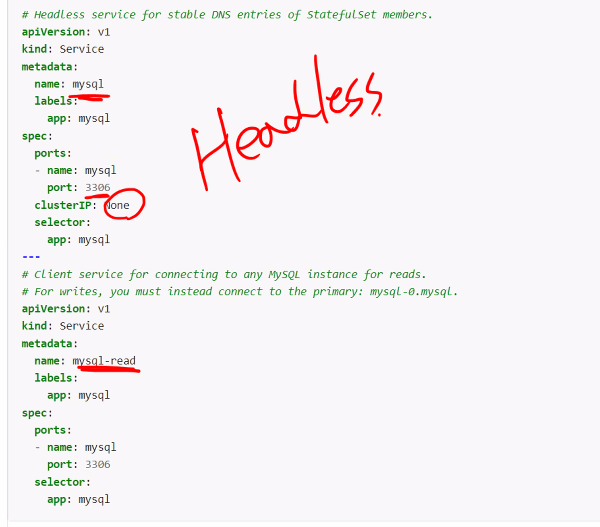
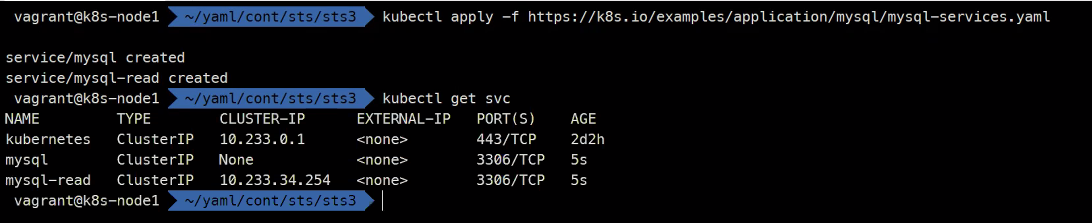

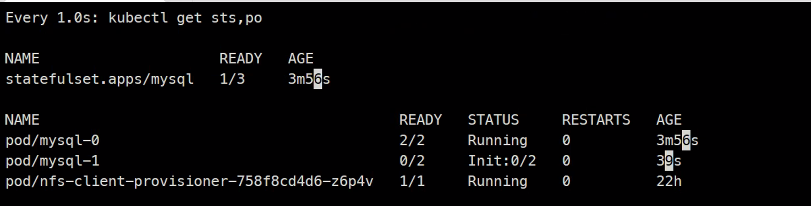
문제발생
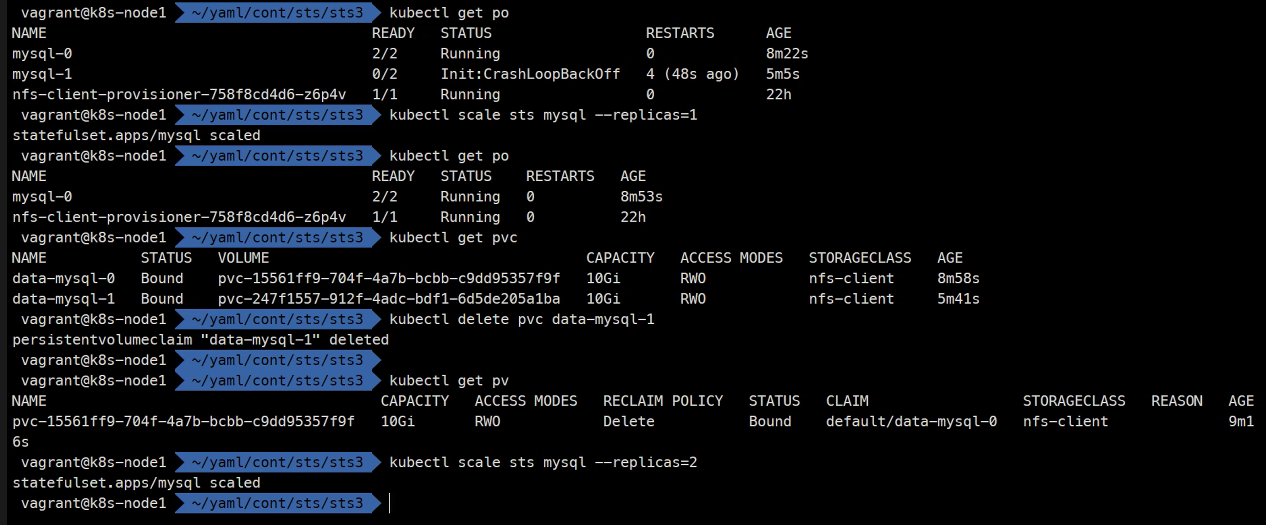

다시 다 지우고

wget https://k8s.io/examples/application/mysql/mysql-statefulset.yamlreplica는 2개로수정
initcontainers가 2개 있고..


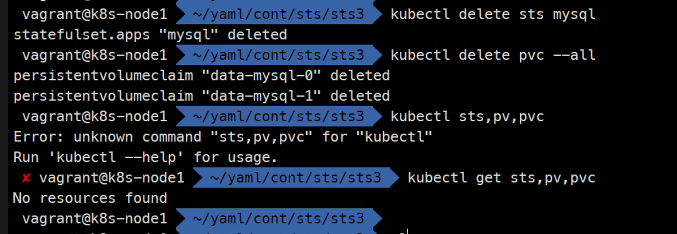
svc 빼고 다 지우고

wget https://k8s.io/examples/application/mysql/mysql-configmap.yaml
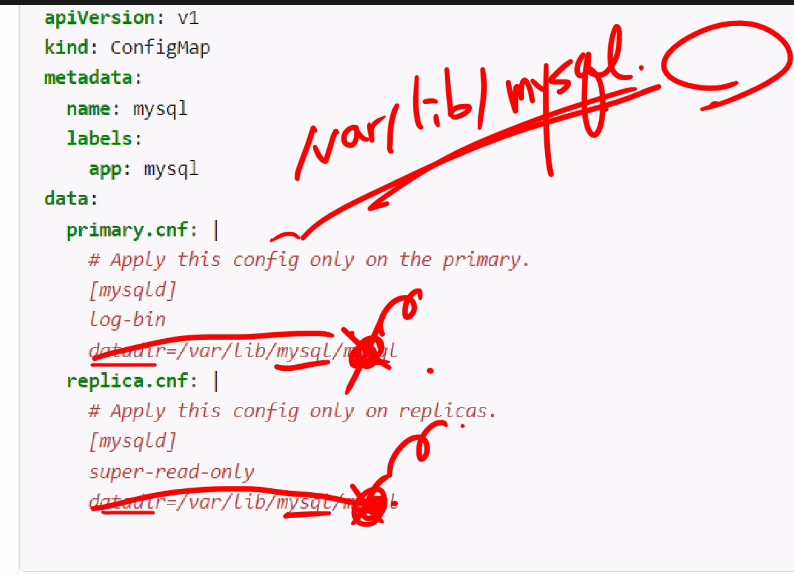

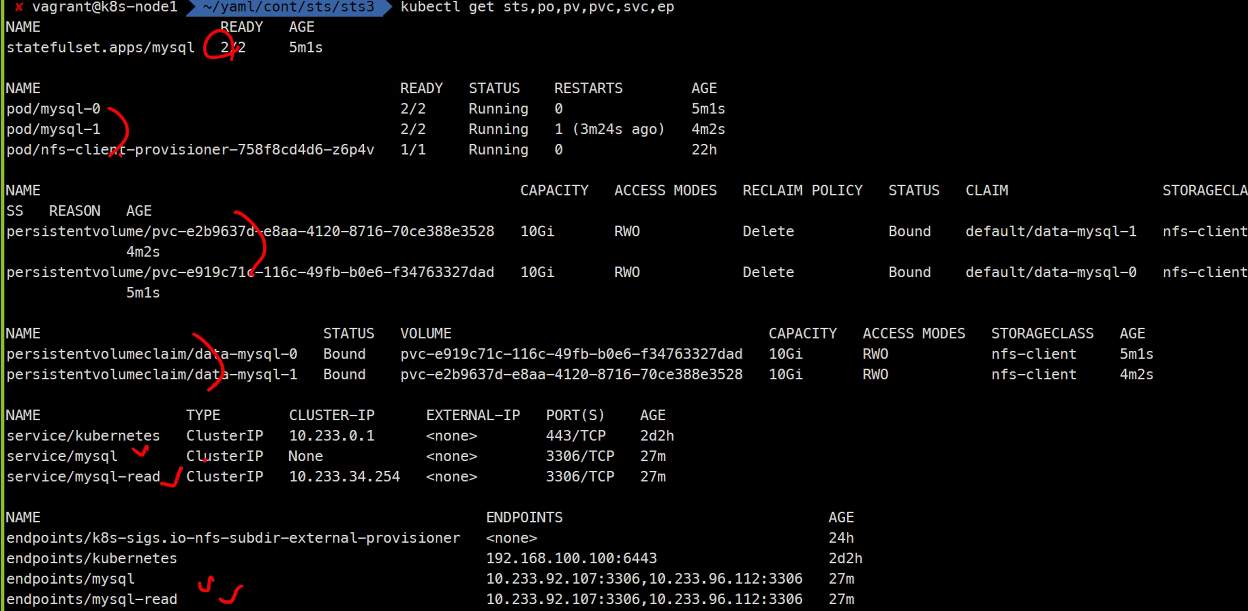
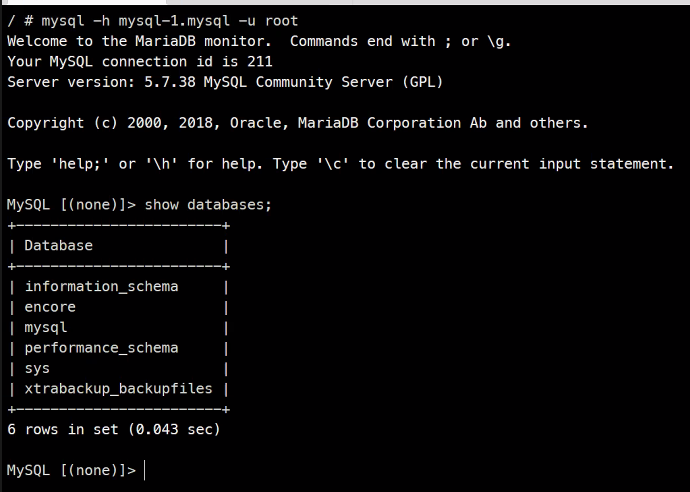
2개씩 잘 만들어진거 확인

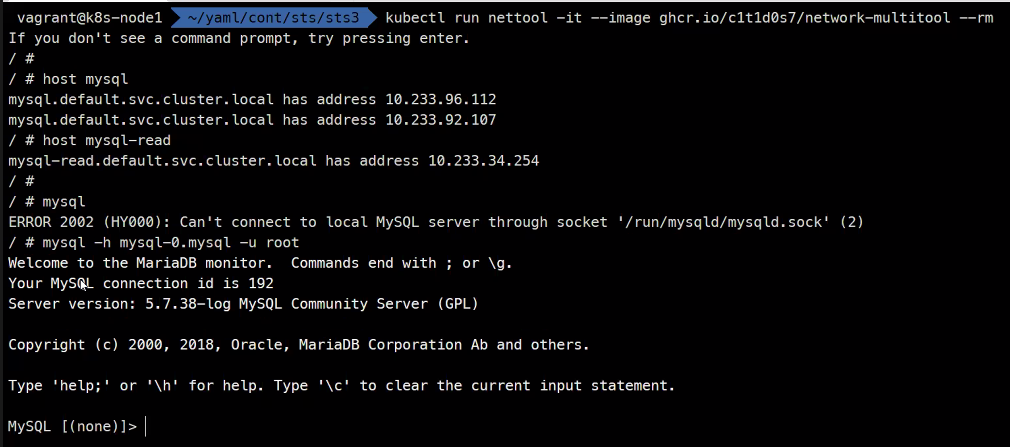
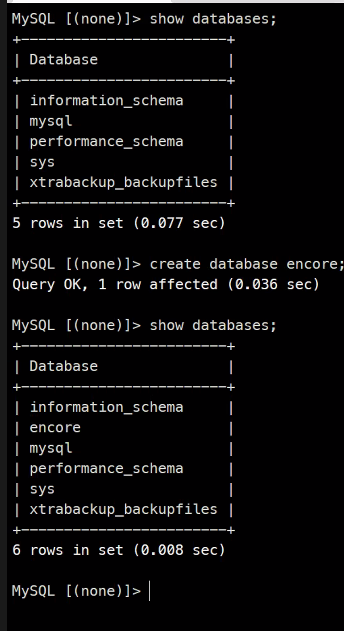
exit

ro이라 안됨
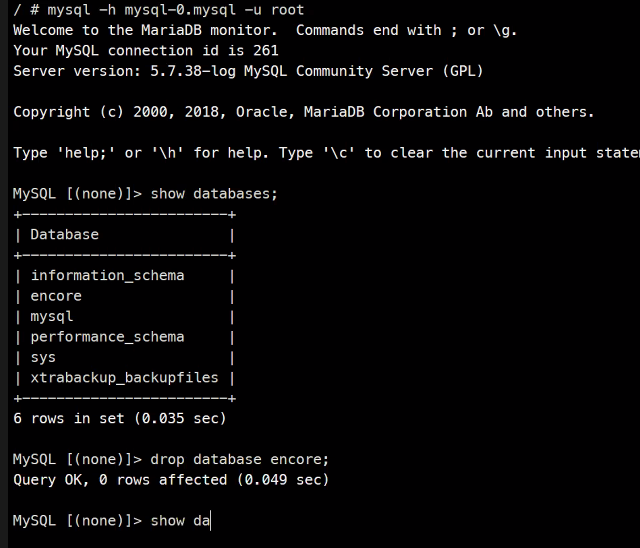
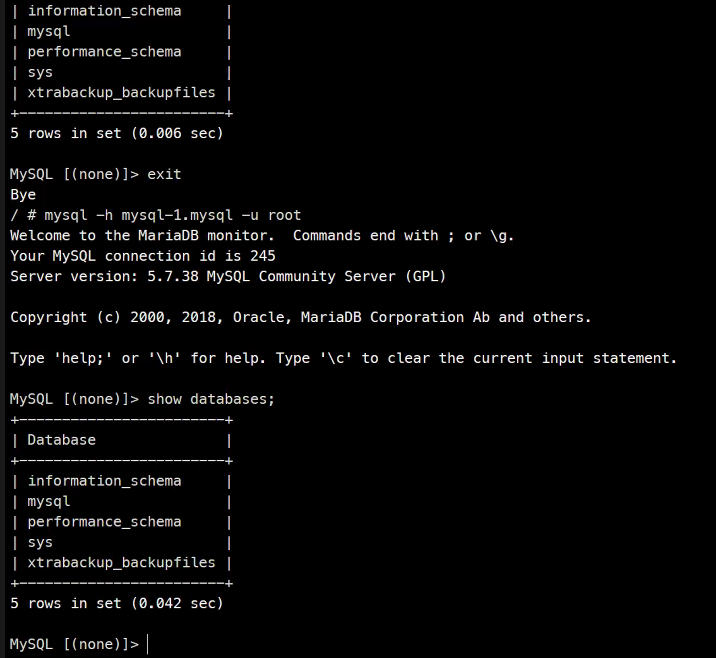
이런식으로 둘은 동기화가 되고 있다.
record를 생성해보면..
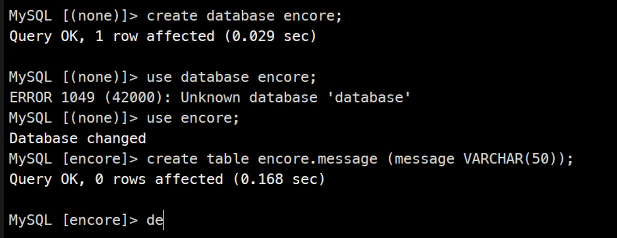
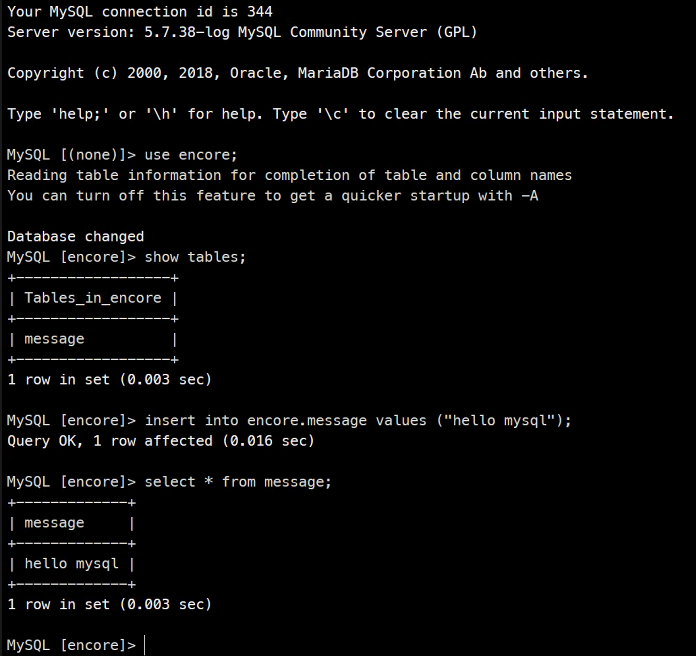
나가서 2번째로 접속을 하면..
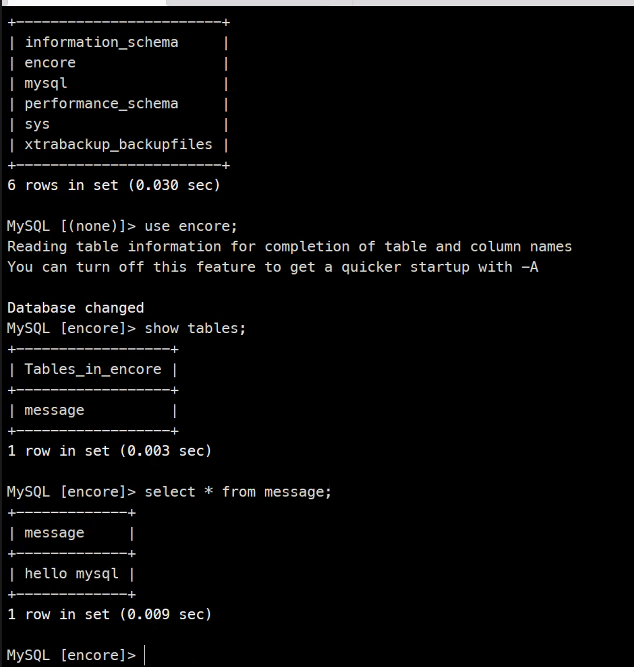
kubectl get po
kubectl scale sts mysql --replicas 3
kubectl get po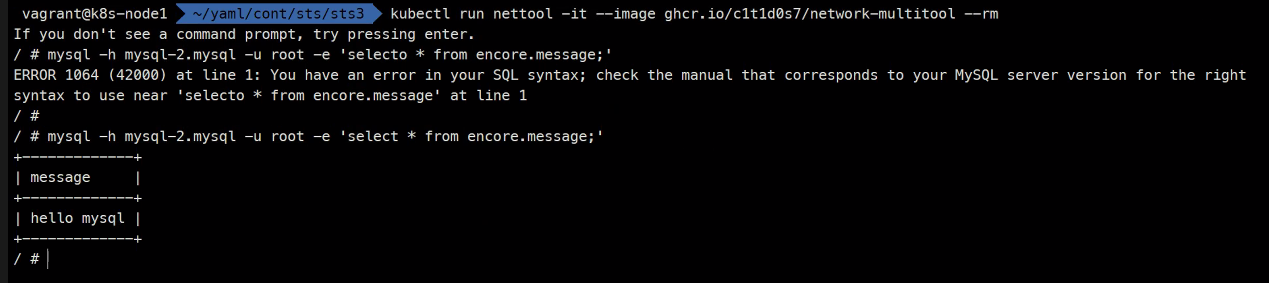
이렇게 방금 생성한 레코드를 바로 확인할 수 있다
기본적으로 어떤구조로 구성이 되어있는지 어떻게 상호작용되는지
볼륨은 어떻게 잡혀있는건지 분석을 해보시길 바란다..
숙제임 ..
복제본을 하나로 rs이나 deployment로 설정해주는것이 포인트
Auto Scaling
cpu제한둔것과 Horizontal Pod Autoscaler을 공부해볼 예정.
https://kubernetes.io/ko/docs/concepts/configuration/manage-resources-containers/

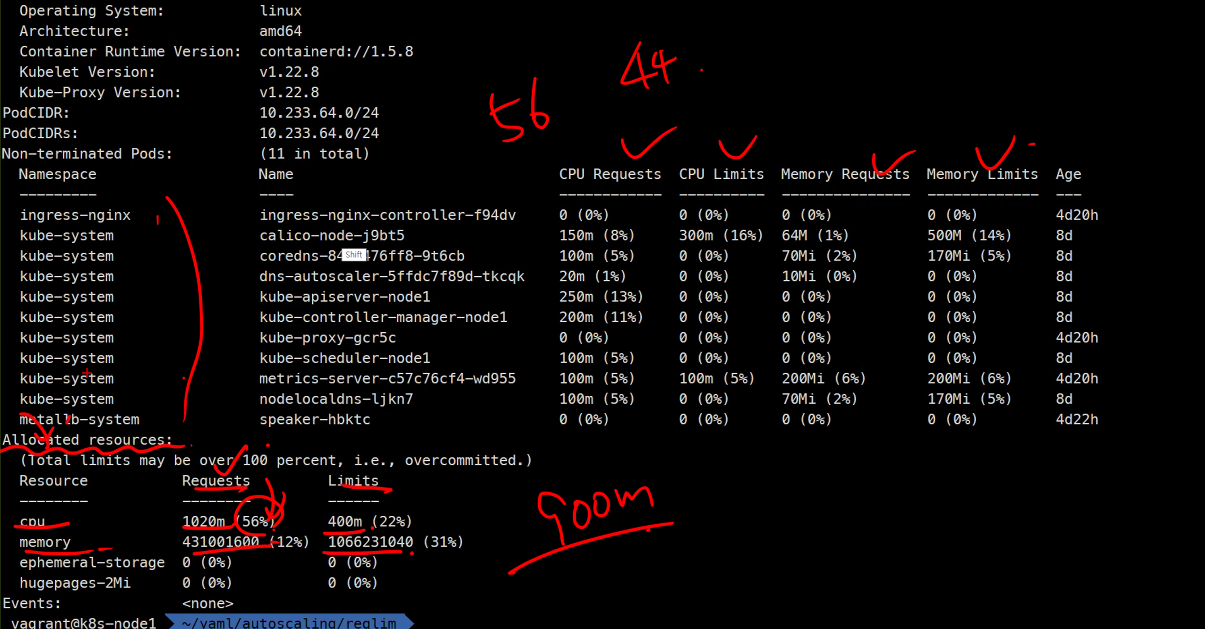
request와 limit의 차이를 알아야한다.
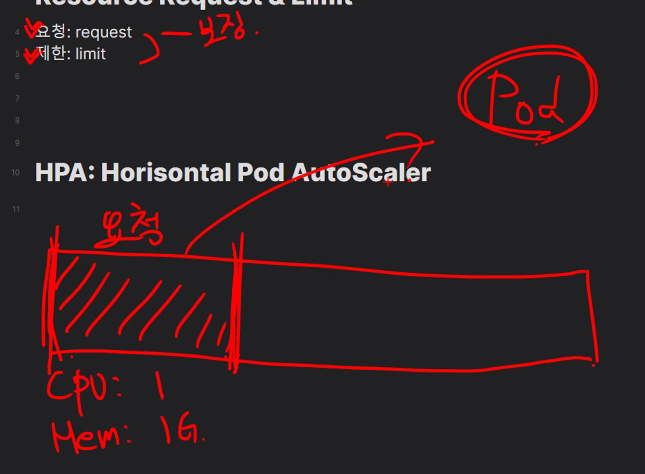
요청은 그만큼을 미리 할당해놓고 보장해주는 것.
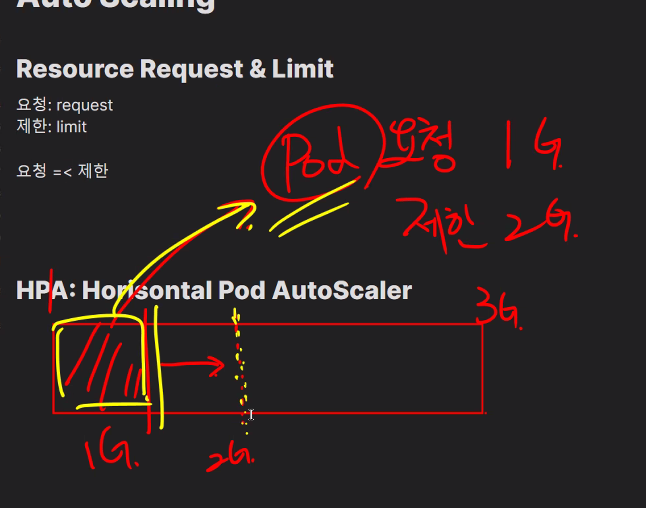

QoS는 Quality of Service임
- BestEffort: 가장 나쁨 #기본값
- Burstable #요청 < 제한
- Guaranteed: 가장 좋음 #요청 = 제한

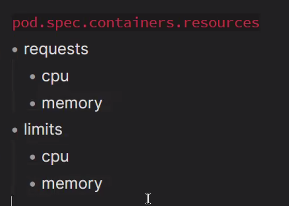

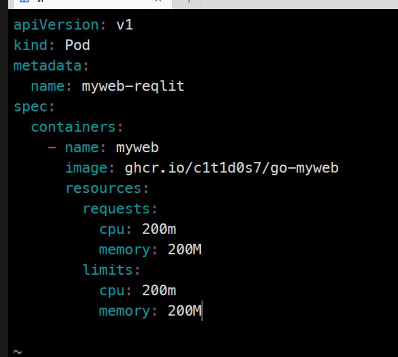
apiVersion: v1
kind: Pod
metadata:
name: myweb-reqlit
spec:
containers:
- name: myweb
image: ghcr.io/c1t1d0s7/go-myweb
resources:
requests:
cpu: 200m
memory: 200M
limits:
cpu: 200m
memory: 200M
create
describe
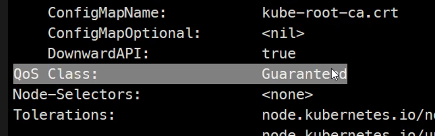


수정이 안되므로 --force를 해주면 삭제했다가 다시만듬


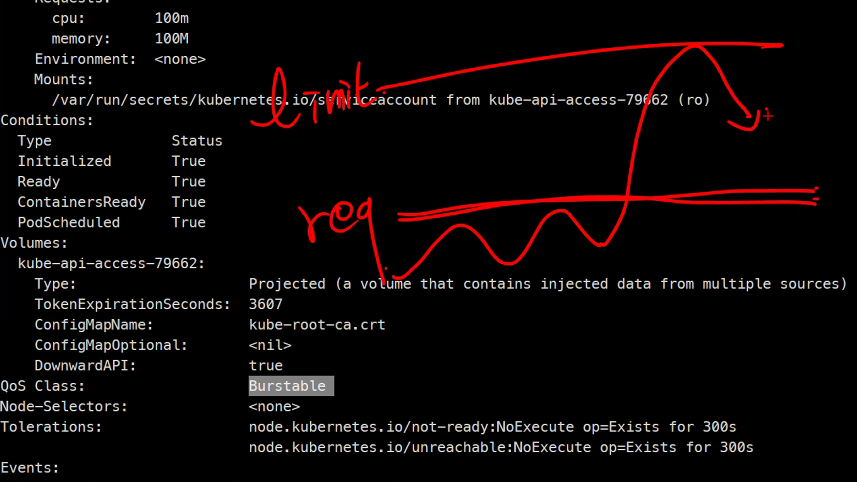
이게 Burst이다
그리고 CPU만 삭제를 하고나더라도 같은 상태가 모드가 유지됨

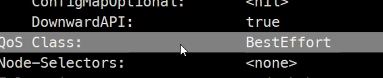
전부 삭제를 하면
BestEffort
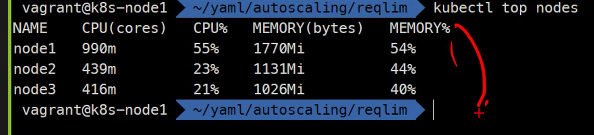
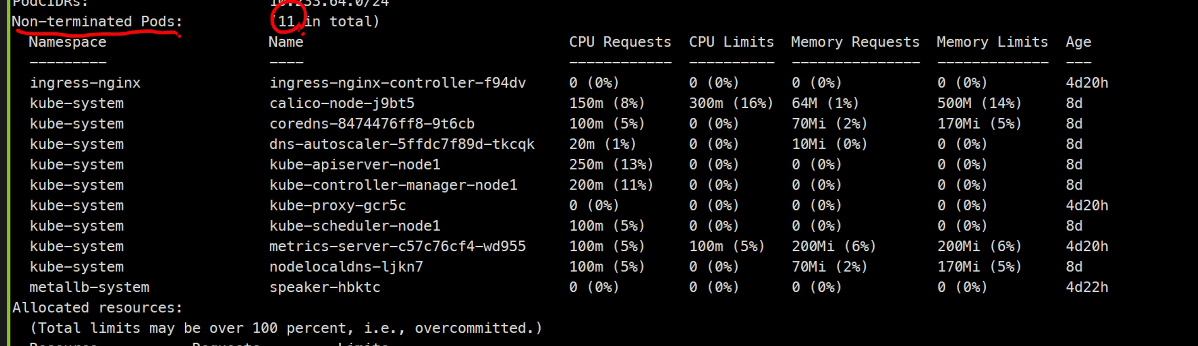
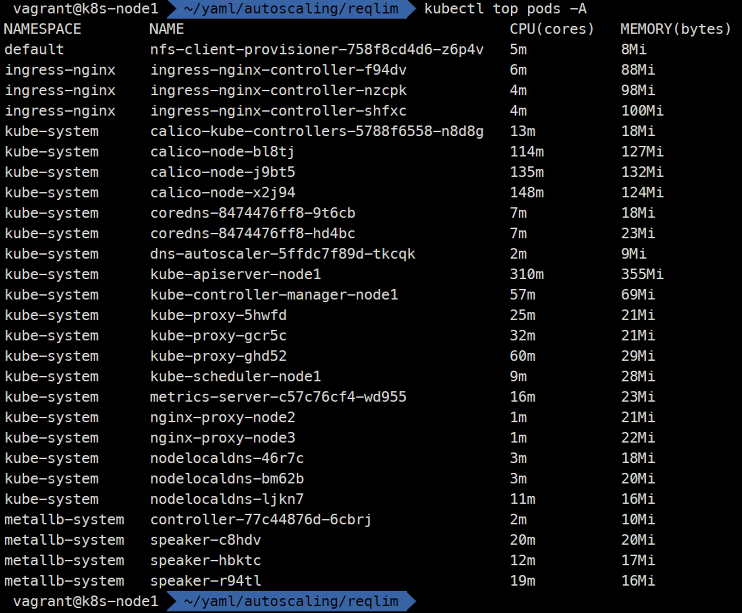
현재 사용량을 볼 수 있음
55%인 이유는 커널도 사용하고 있기 때문
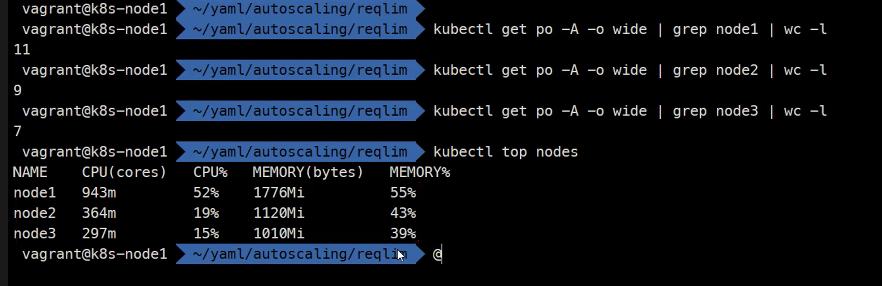
이렇게 현재 사용하고있는 양을 확인할 수 있다.
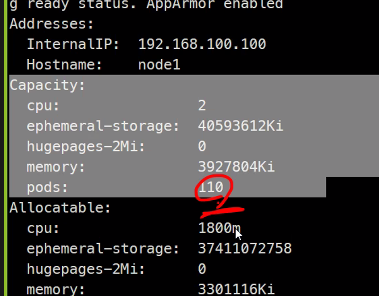
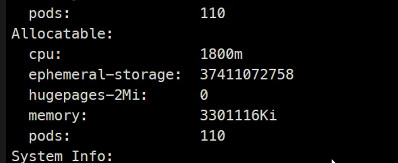
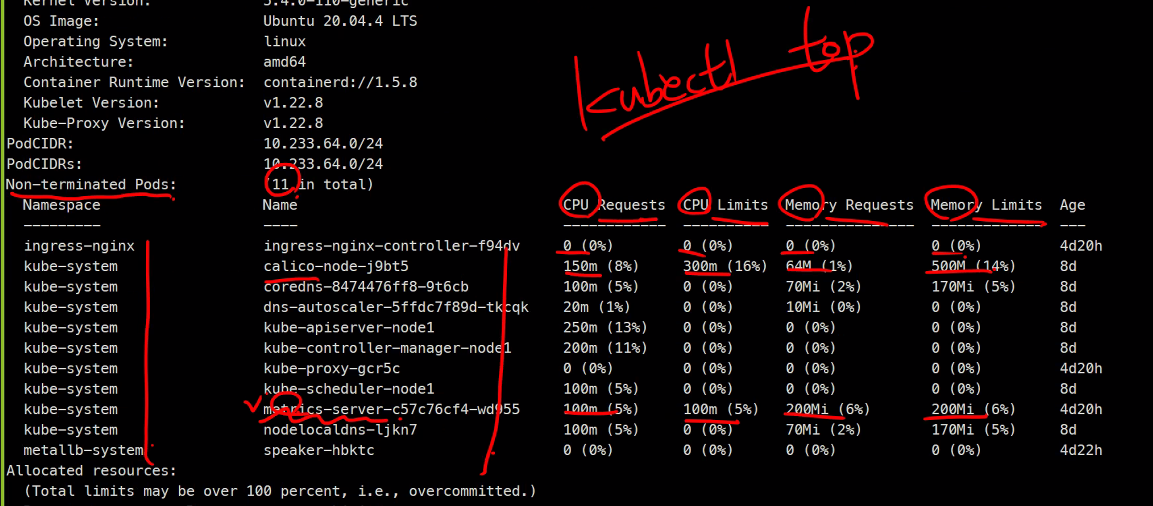
https://github.com/kubernetes-sigs/metrics-server
Metrics Server가 계속해서 모니터링함
원래는 힙스터를 사용했었음
https://github.com/kubernetes-retired/heapster
Retired되었음
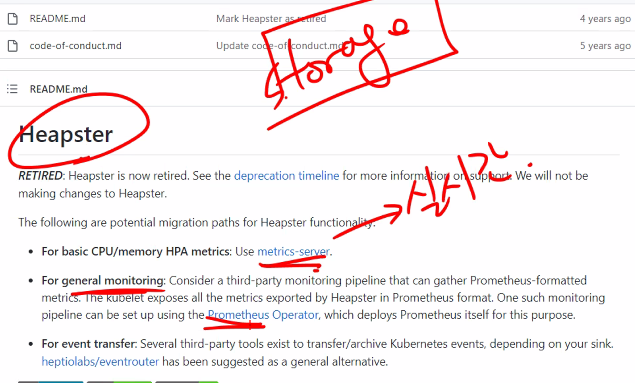
힙스터는 스토리지가 있었고
메트릭 서버는 실시간모니터링만 해주고
프로메테우스는 실시간/이전cpu/memeory/network/disk 등등 모니터링을 한다.
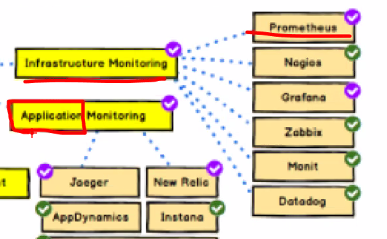
둘의 모니터링 차이를 생각해보고
지금은 인프라 모니터링임

리미트만 설정
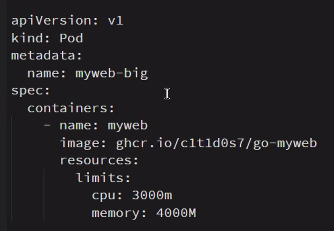

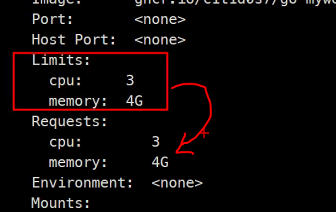

이렇게 할당된거보다 크면 아무것도 되지 않음
이미지, 볼륨, 스케쥴링 중에 하나가 Pending이다.
Horizontal Pod Autoscaling
https://kubernetes.io/ko/docs/tasks/run-application/horizontal-pod-autoscale/

HPA는 파드를 더 만드는것임
VPA는 요청이나 제한을 늘리는것임
ClusterAutoScaler는 Worker Node를 더 할당하시큰것 #AWS에서 AKS로 실습할 수 있다.
AWS의 vm 오토스케일링같은것임
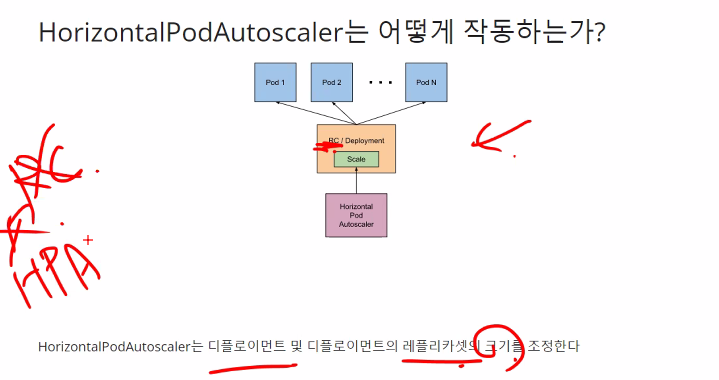
이렇게 세 종류가 사용 가능함
spec:
replicas: ?? 이거를 조정함



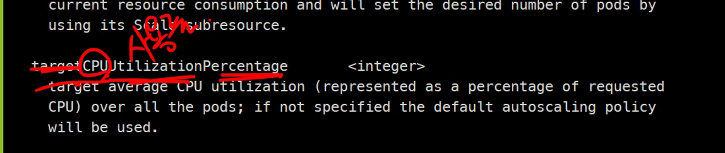
CPU사용량에 따라서..

Ceil은 올림을 뜻함
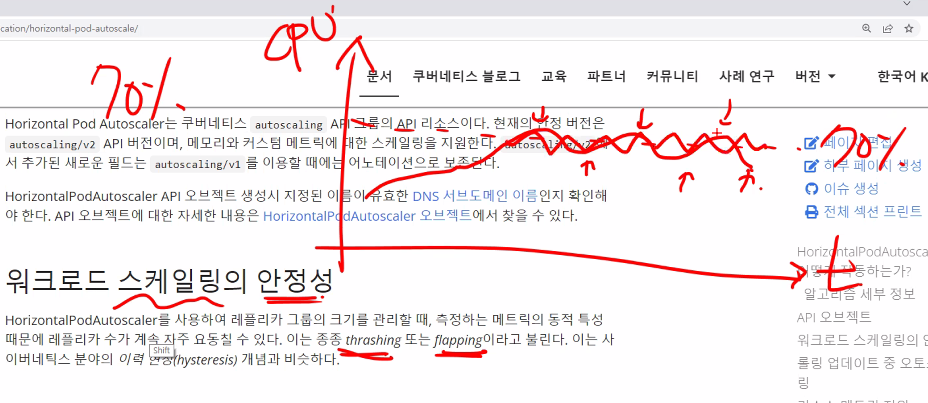
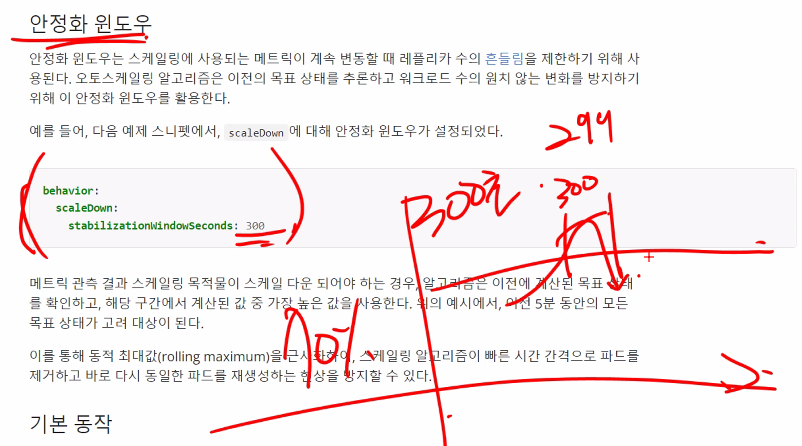
요동치고 바로 스케일링하면 오히려 리소스를 많이 쓰기 때문에
실습해보자
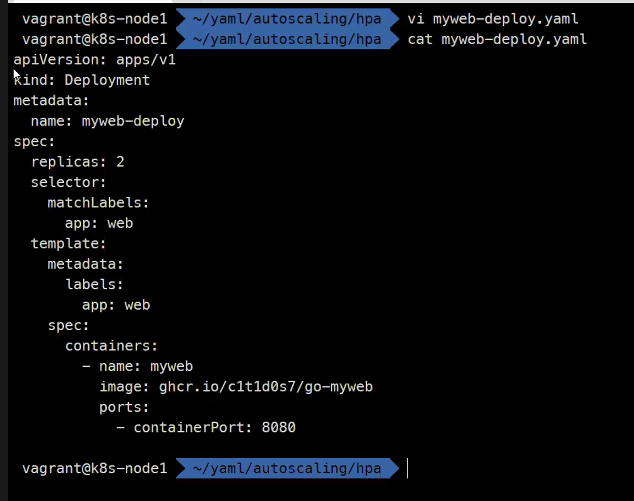
apiVersion: apps/v1
kind: Deployment
metadata:
name: myweb-deploy
spec:
replicas: 2
selector:
matchLabels:
app: web
template:
metadata:
labels:
app: web
spec:
containers:
- name: myweb
image: ghcr.io/c1t1d0s7/go-myweb
ports:
- containerPort: 8080
vi myweb...
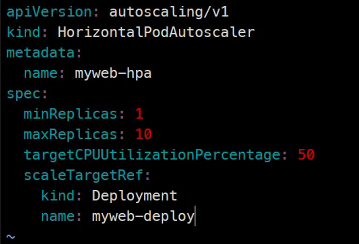
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
name: myweb-hpa
spec:
minReplicas: 1
maxReplicas: 10
targetCPUUtilizationPercentage: 50
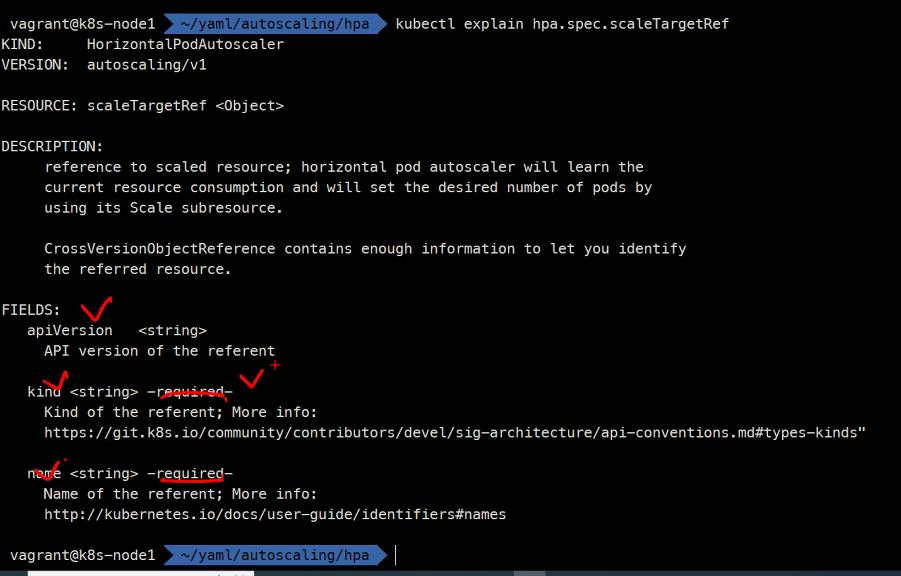
scaleTargetRef:
kind: Deployment
name: myweb-deploy
Pod는 kubelet이 관리함
cadvisor이

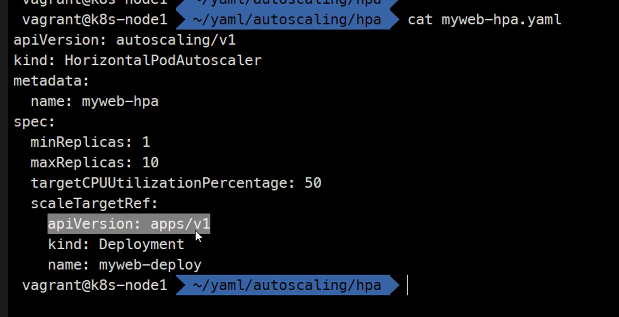
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
name: myweb-hpa
spec:
minReplicas: 1
maxReplicas: 10
targetCPUUtilizationPercentage: 50
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: myweb-deploy
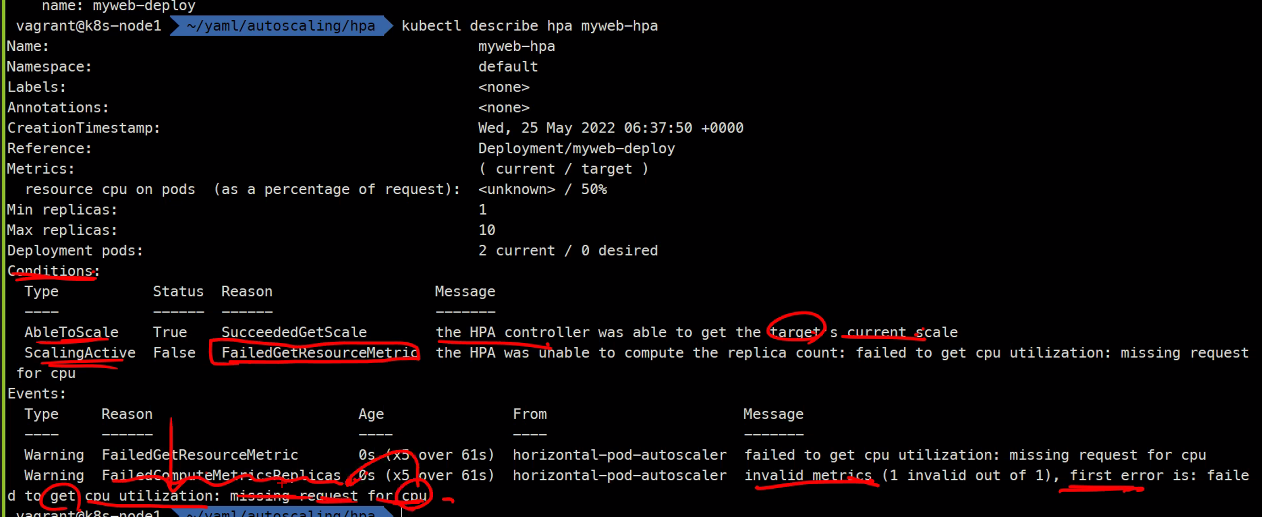
자주 올라오는 질문임
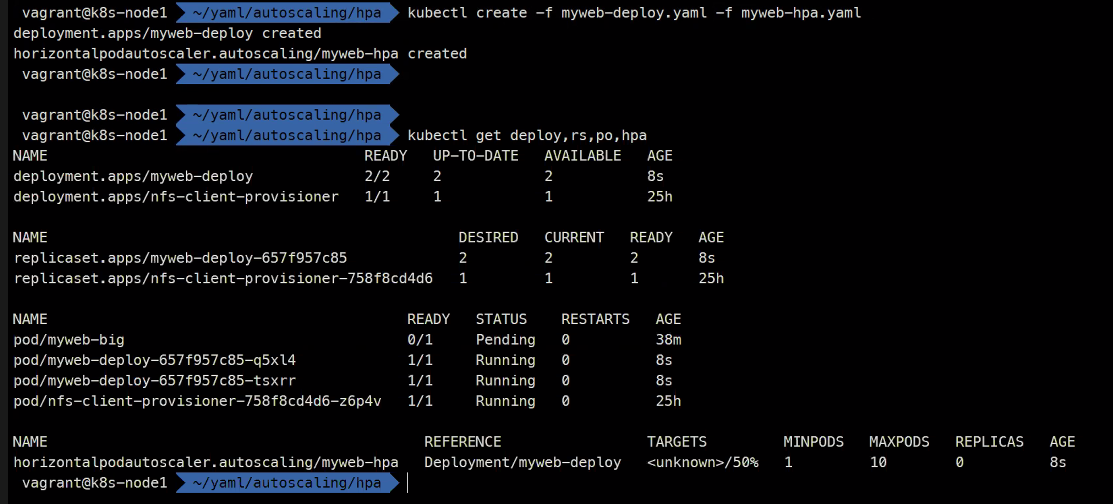
unkown상태에서 측정이 안된다..
그래서 해야하는것은

리퀘스트를 설정해주라는 것이다
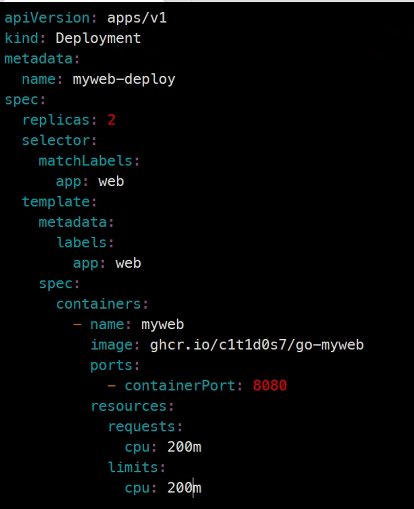
apiVersion: apps/v1
kind: Deployment
metadata:
name: myweb-deploy
spec:
replicas: 2
selector:
matchLabels:
app: web
template:
metadata:
labels:
app: web
spec:
containers:
- name: myweb
image: ghcr.io/c1t1d0s7/go-myweb
ports:
- containerPort: 8080
resources:
requests:
cpu: 200m
limits:
cpu: 200m

부하를 걸어보자

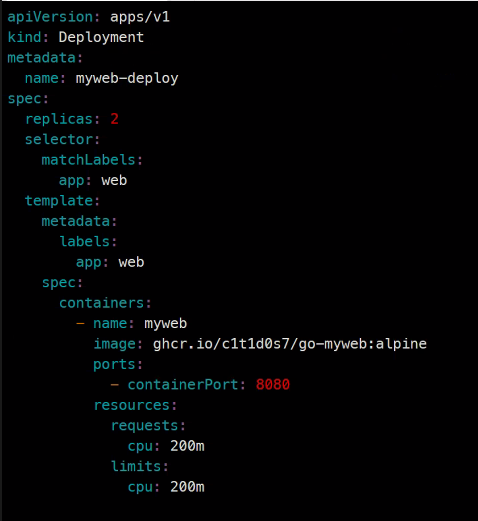
apiVersion: apps/v1
kind: Deployment
metadata:
name: myweb-deploy
spec:
replicas: 2
selector:
matchLabels:
app: web
template:
metadata:
labels:
app: web
spec:
containers:
- name: myweb
image: ghcr.io/c1t1d0s7/go-myweb:alpine
ports:
- containerPort: 8080
resources:
requests:
cpu: 200m
limits:
cpu: 200m

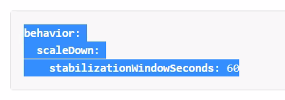
이 기능은 v2beta2를 사용해야함
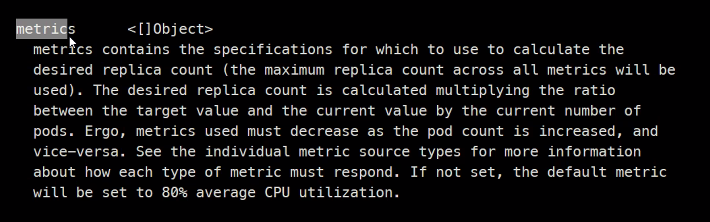
그리고 다양한 metric을 참조해서 오토스케일링할 수 있다고 함
다만 대부분 cpu를 참조하긴함
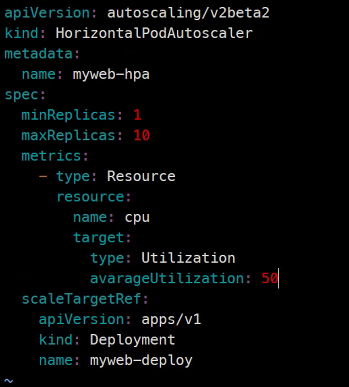
다른 예제임
https://kubernetes.io/ko/docs/tasks/run-application/horizontal-pod-autoscale-walkthrough/
%%%%%%%%%%%%%%%%%%%%%%%%%%%%
추가 숙제
스케일 인이 되었는지 확인해보기
%%%%%%%%%%%%%%%%%%%%%%%%
