Spark 기본 아키텍처 및 용어
Spark 애플리케이션은 클러스터의 드라이버 프로그램과 익스큐터 그룹으로 구성됩니다. Driver는 Spark 애플리케이션의 기본 프로그램을 실행하고 작업 실행을 조정하는 SparkContext를 생성하는 프로세스입니다. executor는 드라이버 프로세스가 할당 한 task을 실행하는 클러스터의 worker 노드에서 실행되는 프로세스입니다.
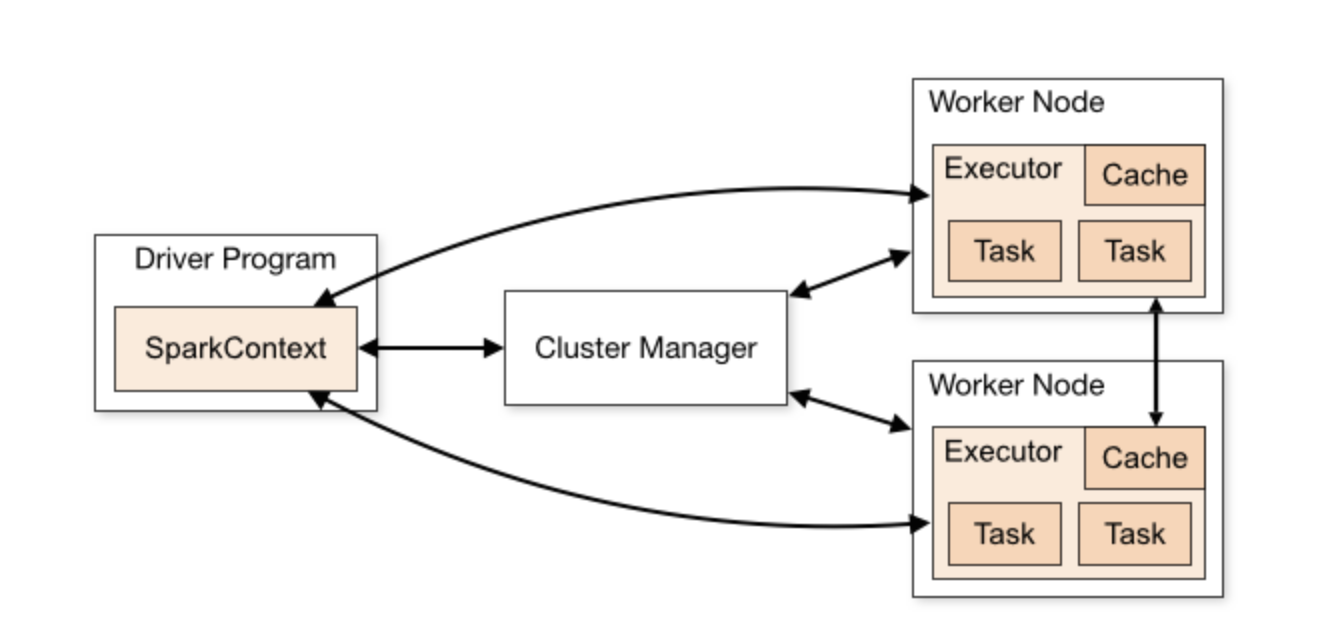
클러스터 관리자(예: Mesos 또는 YARN)는 Spark 애플리케이션에 대한 물리적 리소스 할당을 담당합니다.
spark 진입점
모든 Spark 애플리케이션에는 데이터 소스와 통신하고 데이터 읽기 및 쓰기와 같은 특정 작업을 수행할 수 있는 진입점이 필요합니다. Spark 1.x 에서는 SparkContext , SQLContext 및 HiveContext 의 세 가지 진입점이 도입되었습니다 . Spark 2.x 이후 세 가지 컨텍스트에서 사용할 수 있는 모든 기능을 기본적으로 결합한 SparkSession 이라는 새로운 진입점이 도입되었습니다.
Spark의 초기 릴리스에서는 각각 다른 목적을 가진 이 세 가지 진입점을 사용할 수 있었습니다.
SparkContext
SparkContext는 작업을 조정하고 실행하기 위해 클러스터 및 리소스 관리자와 통신을 설정하기 위해 드라이버 프로세스에서 사용됩니다. SparkContext는 다른 두 컨텍스트, 즉 SQLContext 및 HiveContext에 대한 액세스도 가능하게 합니다
SparkContext를 생성하려면 먼저 아래와 같이 Spark 구성( SparkConf)을 생성해야 합니다.
// Scala
import org.apache.spark.{SparkContext, SparkConf}
val sparkConf = new SparkConf() \
.setAppName("app") \
.setMaster("yarn")
val sc = new SparkContext(sparkConf)
spark-shell을 사용하는 경우 sc 라는 변수를 통해 SparkContext를 이미 사용할 수 있습니다 .
SQLContext
SQLContext는 구조화된 데이터 처리를 위한 Spark 모듈인 SparkSQL 의 진입점 입니다. SQLContext가 초기화되면 사용자는 이를 사용하여 데이터 세트 및 데이터 프레임에 대해 다양한 "sql-like" 작업을 수행할 수 있습니다.
SQLContext를 생성하려면 먼저 아래와 같이 SparkContext를 인스턴스화해야 합니다.
// Scala
import org.apache.spark.{SparkContext, SparkConf}
import org.apache.spark.sql.SQLContext
val sparkConf = new SparkConf() \
.setAppName("app") \
.setMaster("yarn")
val sc = new SparkContext(sparkConf)
val sqlContext = new SQLContext(sc)
HiveContext
Spark 응용 프로그램이 Hive와 통신해야 하고 Spark < 2.0을 사용하는 경우 HiveContext 가 필요할 것입니다. Spark 1.5+의 경우 HiveContext는 window functions를 지원합니다.
// Scala
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.sql.hive.HiveContext
val sparkConf = new SparkConf() \
.setAppName("app") \
.setMaster("yarn")
val sc = new SparkContext(sparkConf)
val hiveContext = new HiveContext(sc)
hiveContext.sql("select * from tableName limit 0")
a) Hive 지원도 제공하는 SparkSession이 도입되었습니다.
b) Native window functions이 릴리스되어 기본적으로 Hive UDAF를 기본 Spark SQL UDAF로 대체했습니다.
SparkSession
Spark 2.0은 본질적으로 SQLContext와 HiveContext를 모두 대체하는 SparkSession 이라는 새로운 진입점을 도입했습니다. 또한 개발자에게 SparkContext에 대한 즉각적인 액세스를 제공합니다. Hive를 지원하는 SparkSession을 생성하려면 다음 작업을 수행하기만 하면 됩니다.
// Scala
import org.apache.spark.sql.SparkSession
val sparkSession = SparkSession \
.builder() \
.appName("myApp") \
.enableHiveSupport() \
.getOrCreate()
// Two ways you can access spark context from spark session
val spark_context = sparkSession._sc
val spark_context = sparkSession.sparkContext
