CNN part 1
CNN 소개
CNN은 Convolutional Neural Network로 합성곱 인공신경망을 뜻한다. 왜 합성곱 인공신경망이냐면 합성곱(Convolution) 연산을 통해 이미지로부터 특징(feature)들을 뽑아오기 때문이다. 무수히 많은 특징(feature)들을 추출하고 fc layer에서 분석하여 라벨을 예측한다.
우선 구조부터 설명하겠다. 예시는 2012년 ImageNet을 우승하여 전세계에 AI 열풍을 불게한 Alex-Net을 예시로 들겠다. AlexNet을 최초의 CNN이라고 얘기해도 될 것 같다. (물론 인공신경망, 인공지능 개념들은 과거 부터 존재했지만 성공적으로 실행에 욺긴 최초의 모델은 AlexNet이라고 알고 있다) AlexNet은 ImageNet 이미지 분류 대회에서 압도적인 스코어로 우승을 차지한 모델이다.
모델 구조(Architecture)
(사실 AlexNet 논문에서 사용한 모델은 3GB GPU2개를 한번에 사용해서 실제 구조는 조금 다르다. 하지만 이후에 나온 GPU들은 성능이 좋아 GPU 1로 돌리는게 가능해졌고 이에 맞는 모델 구조를 베이스로 설명하겠다. 사실 GPU에 대한 깊이가 아직까지는 많이 부족해서 설명을 못한다.)
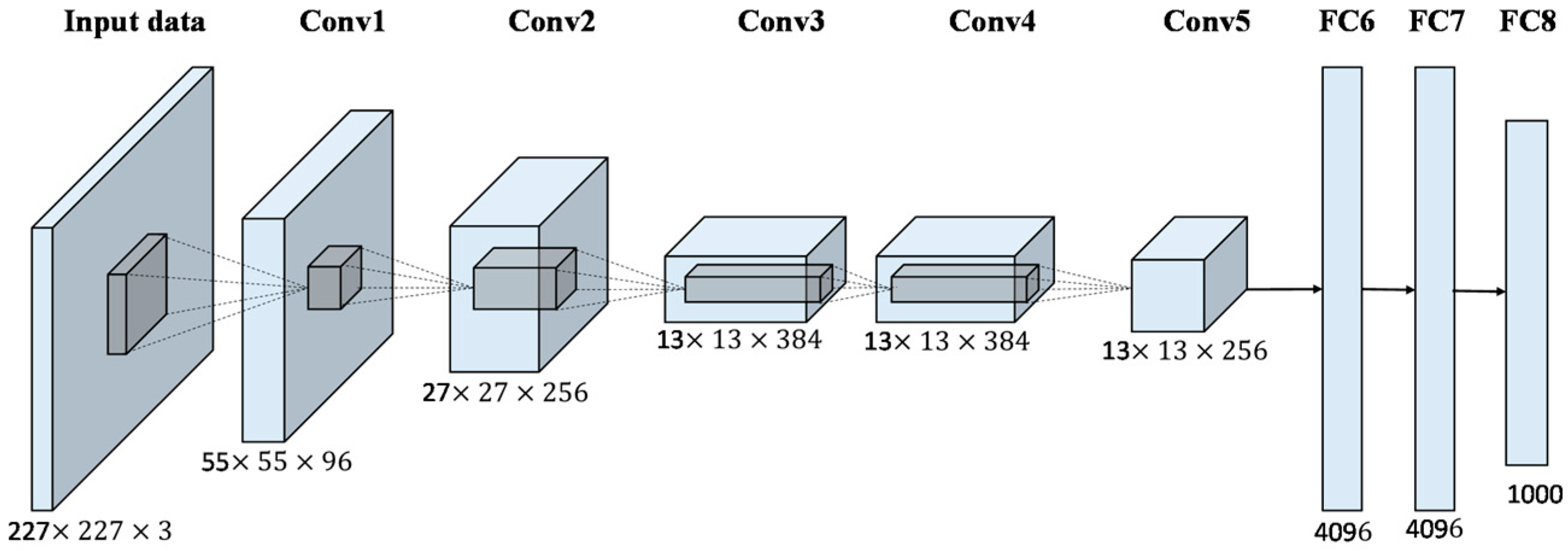
구조는 이렇다. 5 개의 Convolutional Layer, 3 개의 FC Layer 중 최종 1000-way softmax layer. 하나의 Layer는 하나의 층이라 표현하고 이 모든 층들은 순차적으로 쌓여있다고 보면 된다. 모델이 하나의 인풋값을 받으면 차량이 자동세차장에 들어가는 과정과 같이 데이터를 순차적으로 처리한다고 이해하면 될 것 같다.
그렇다면 인풋이 어떻게 처리되는 지 설명하겠다. 간 - 단 - 하 - 게 -
시작지점에서 하나의 Input Image를 받는다. 데이터셋이 100장의 이미지로 구성되어 있다면 모델은 한장 한장씩 처리한다. 이미지를 받으면 해당 이미지를 5개의 Convolutional Layer(합성곱층)로 통과시켜 마지막 3개의 FC Layer에서 인풋값들을 분석/정리하여 최종 1000-way Softmax Layer에서 예측을 한다. 해당 내용을 사진 내 구조와 같이 보면서 이해하고 넘어가면 좋을 것 같다.
일단 예측값들을 내어주는 Softmax Layer에 대해 얘기하려 한다.
Convolutional Layer에서의 합성곱 과정은 따로 다루겠다.
Softmax Layer (예측 단계)
AlexNet의 마지막 출력층은 Softmax Layer이다. 앞에서 분석한 파라미터/feature들을 이용하여 최종 예측을 해주는 층인데 Softmax는 각 분류/라벨 별로 확률을 부여한다. 예를 들면 데이터셋 내 0~9의 숫자 이미지들이 있다면 인풋사진이 0일 확률 10%(.1), 1일 확률 60%(.6), 2일 확률 5%(.05) 식으로 각 라벨/클래스/분류 마다 확률을 하나씩 출력해준다. 그리고 그중 가장 높은 확률이 부여된 클래스를 최종 예측 클래스로 한다. 중요한 것은 Softmax 함수는 다중분류에 사용되는 함수이다. 이중 분류에는 Sigmoid과 같은 함수가 있으며 모델이 해결하고자 하는 문제에 따라 사용되는 함수가 다르다.
(Softmax에 관한 자세한 내용은 따로 작성했다)
머신 러닝에서는 크게 분류와 회귀 문제가 있다.
분류 문제는 주어진 인풋 값을 특정 분류에 매핑하는 것이 목적입니다. 위에 다중분류 하는 것을 예시로 들 수 있다. 인풋 사진이 0~9 중 어떤 분류에 속하는 것을 맞추는 등 범주형 값을 예측한다. 회귀 문제는 주로 연속적인 값들을 다루는 문제로써 특정 값을 예측하는 것입니다. 예를 들자면 날씨 예측할때 과거에 쌓인 연속적인 값들을 분석한다. 또한 특정 한 날의 날씨를 보면 이 값은 고정된 값이 아니라 연속적인 값일 가능성이 크다. 이어서 날씨를 결정짓는데 있어서 존재하는 독립변인들과 종속변인들간의 관계를 분석하여 최종 예측을 낸다.
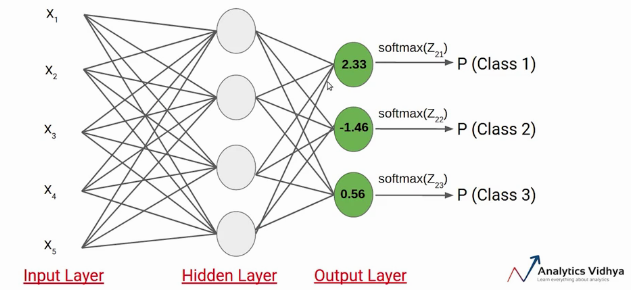
Loss & Cost function(예측값과 정답값간의 거리/차이)
모델이 softmax를 통해 예측을 하는 것 까지 얘기했다. 그런데 처음 부터 모델이 알맞는 예측을 할까? 그렇지 않다. 보통 처음에 예측을 거의 무작위로 한다고 보면 된다. 대충 예측을 해보고 그 다음에 해당 예측값이 정답(실제값)과 얼마나 떨어져 있는 지를 측정한다. 예측값과 실제값의 격차를 구하는 함수를 Loss(손실) 또는 Cost(비용) function(함수)라 얘기하고 예측값과 실제값의 차이를 Loss 또는 Cost라 한다. 원리는 간다하고 이해하기 쉽다.
그렇다면 Loss 와 Cost의 차이는 무엇일까? 매우 간단하다. 수 많은 코스트들을 합해서 평균을 내면 그것이 Loss다. Loss는 cost들의 요약이라고 이해하면 편하다. 그리고 수 많은 코스트들이 모여 하나의 Loss라는 값을 형성한다. 앞에 convolution 부분을 모르면 이 부분이 이해가 안될 것이다. 당장 이해할 필요 없다. 후에 convolution 과정을 설명하면서 다시 cost와 loss를 언급하겠다.
Alex-Net 모델은 cost와 loss를 구하는데 둘다 cross-entropy를 사용했다. Cross entropy에서 ("새년) Entropy는 정보이론(Information Theory)에서 나온 기본 개념인데 이 부분에 대해 조금 더 설명한 글이 있다. 찾아서 보면 도움이 될 것 같다.
Cross entropy loss란?
다양한 Loss 함수들이 존재한다. 다르게 말해서 Loss를 구하는 방법이 여러가지가 있고 이 또한 머신러닝이 다루는 문제에 따라 달라진다. 일단 AlexNet에서 사용된 Cross Entropy Loss는 분류 문제에 주로 사용이 된다.
간단하게 설명하자면 Cross Entropy Loss는 예측 및 관측된 데이터의 각 확률 분포의 차이를 구한다. 각 확률분포의 차이를 구하여 모델의 성능을 평가한다.
이어서 CNN part 2에서는 합성곱을 이용한 특징 추출, 이미지 데이터의 형태를 다루고
CNN part 3에서는 CNN의 핵심인 backpropogation과 최적화 기법 gradient descent, stochastic gradient descent를 다루려고 한다.
