📌 고유값
DISTINCT(): 중복 값들을 제외하고 고유한 값만 보는 방법이다.SUBSTRING(): 문자열의 일부 추출한다.
✅ gender 컬럼에서 고유값
SELECT DISTINCT(gender) FROM copang_main.member;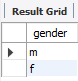
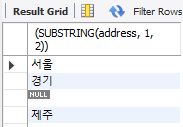
✅ address 컬럼에서 주요 지역들의 고유값
SELECT DISTINCT(SUBSTRING(address, 1, 2)) FROM copang_main.member;SUBSTRING(address, 1, 2)는 address 컬럼에서 가장 첫 번째 문자에서 총 두 개의 문자를 추출하라는 의미이다.
그리고 그 두 문자를 기준으로 DISTINCT() 함수가 작동한다.
📌 고유값 개수
COUNT(): row의 개수를 구하는 함수이다.COUNT(DISTINCT()): 고유값의 개수를 구한다.
SELECT COUNT(DISTINCT(gender)) FROM copang_main.member;SELECT COUNT(DISTINCT(SUBSTRING(address, 1, 2))) FROM copang_main.member;📌 문자열 관련 함수
- LENGTH
문자열 길이
SELECT *, LENGTH(address) FROM copang_main.member;- UPPER, LOWER
UPPER는 문자열을 모두 대문자로 바꿔준다.
LOWER는 문자열을 모두 소문자로 바꿔준다.
SELECT email, UPPER(email) FROM copang_main.member;
SELECT email, LOWER(email) FROM copang_main.member;- LPAD, RPAD
LPAD는 왼쪽을 특정 문자열로 채워준다.
RPAD는 오른쪽을 특정 문자열로 채워준다.
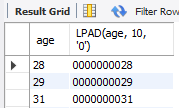
SELECT age, LPAD(age, 10, '0') FROM copang_main.member;age 컬럼의 왼쪽에 문자 '0'을 10개 채워준다.
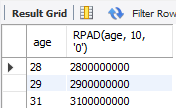
SELECT age, RPAD(age, 10, '0') FROM copang_main.member;age 컬럼의 오른쪽에 문자 '0'을 10개 채워준다.
❗ age 컬럼은 INT형이었다. 그렇더라도 문자열 함수 안에 인자로 넣어주면 그 값이 자동으로 문자열로 형 변환이 된다.
- TRIM, LTRIM, RTRIM
LTRIM은 왼쪽 공백을 삭제한다.
RTRIM은 오른쪽 공백을 삭제한다.
TRIM은 왼쪽, 오른쪽(양쪽) 공백을 삭제한다.
SELECT LTRIM(word) FROM FOR_TEST.trim_test;SELECT RTRIM(word) FROM FOR_TEST.trim_test;SELECT TRIM(word) FROM FOR_TEST.trim_test;📌 그루핑 1
그루핑이란 row들을 여러 개 그룹으로 나누는 것을 말한다.
남성 회원과 여성 회원들이 각각 총 몇 명인지를 알기 위해서 먼저 성별 기준으로 그루핑을 해야 한다.
SELECT gender FROM copang_main.member GROUP BY gender;이 결과는 DISTINCT(gender)의 결과와 겉으로는 같아보이지만, 내부적으로는 전혀 다른 결과이다.
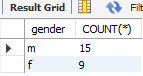
✅ gender 별 row 개수
SELECT gender, COUNT(*) FROM copang_main.member GROUP BY gender;COUNT(*) 는 조회되는 row의 개수를 구해주는 함수이다. 그러나 그루핑된 상태에서는 그룹별로 row의 개수를 구한다.
✅ 남성과 여성의 평균 키
SELECT gender, COUNT(*), AVG(height) FROM copang_main.member GROUP BY gender;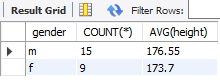
✅ 각 성별에서 몸무게가 가장 가벼운 회원 조회
SELECT
gender,
COUNT(*),
AVG(height),
MIN(weight)
FROM copang_main.member
GROUP BY gender;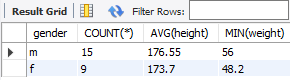
위에서 사용한 COUNT, AVG, MIN 함수들은 집계 함수라고 한다.
집계 함수란 그루핑을 통해 생성된 각 그룹의 수치적인 특성을 구하는 함수이다.
📌 그루핑 2
SELECT
SUBSTRING(address, 1, 2) AS region,
COUNT(*)
FROM copang_main.member
GROUP BY SUBSTRING(address, 1, 2);address 컬럼은 주소 하나하나가 고유한 값이기 때문에 GROUP BY address로 사용해선 안 된다.
앞서 배운 SUBSTRING 함수를 통해 두 글자를 기준으로 그루핑을 한다.
그리고 각 그루핑(지역)별로 row의 개수를 확인한다.
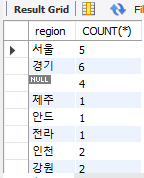
그루핑은 여러 개의 컬럼 사용이 가능하다.
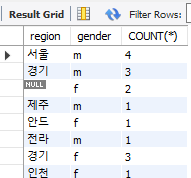
SELECT
SUBSTRING(address, 1, 2) AS region,
gender,
COUNT(*)
FROM copang_main.member
GROUP BY
SUBSTRING(address, 1, 2),
gender;서울이면서 남자인 그룹의 row 개수와 서울이면서 여자인 그룹의 row 개수 등으로 나뉜다.
📌 그루핑 3
GROUP BY를 사용하여 그루핑을 하면 모든 그룹들의 row가 출력된다.
만약 그 중에서도 특정 그룹들만 보고 싶다면 어떻게 할까 ❓
HAVING : 여러 그룹들 중 보고 싶은 그룹만 조회하는 함수
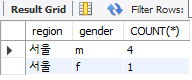
✅ 주요 지역이 서울인 그룹만 조회
SELECT
SUBSTRING(address, 1, 2) AS region,
gender,
COUNT(*)
FROM copang_main.member
GROUP BY
SUBSTRING(address, 1, 2),
gender
HAVING region = '서울';HAVING region = '서울'은 여러 그룹들 중에서도 region 컬럼인 값이 서울이 그룹만 조회한다.
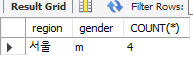
SELECT
SUBSTRING(address, 1, 2) AS region,
gender,
COUNT(*)
FROM copang_main.member
GROUP BY
SUBSTRING(address, 1, 2),
gender
HAVING
region = '서울'
AND gender = 'm';HAVING에는 여러 조건이 입력 가능하다.
HAVING 대신 WHERE를 입력하면 오류가 난다. 둘은 비슷해 보이지만 엄연히 다르다.
WHERE는 테이블에서 맨 처음 row들을 조회할 때 조건 설정한다.HAVING은 이미 조회된 row들을 그루핑했을 때, 그 그룹들 중에서 다시 필터링한다.
✅ region 컬럼이 NULL인 row 제외
SELECT
SUBSTRING(address, 1, 2) AS region,
gender,
COUNT(*)
FROM copang_main.member
GROUP BY
SUBSTRING(address, 1, 2),
gender
HAVING region IS NOT NULL;✅ 그루핑 정렬
SELECT
SUBSTRING(address, 1, 2) AS region,
gender,
COUNT(*)
FROM copang_main.member
GROUP BY
SUBSTRING(address, 1, 2),
gender
HAVING region IS NOT NULL
ORDER BY
region ASC,
gender DESC;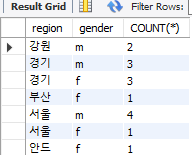
📌 GROUP BY 규칙
GROUP BY를 사용할 때 SELECT 절에는
GROUP BY뒤에서 사용한 컬럼들COUNT,MAX등집계 함수
위 두 가지만 사용할 수 있다는 규칙이 있다.
