[kocw 이미정]10. Connectionless transport: UDP, Principles of reliable data transfer, Connection-oriented transport: TCP
네트워크
목록 보기
10/24
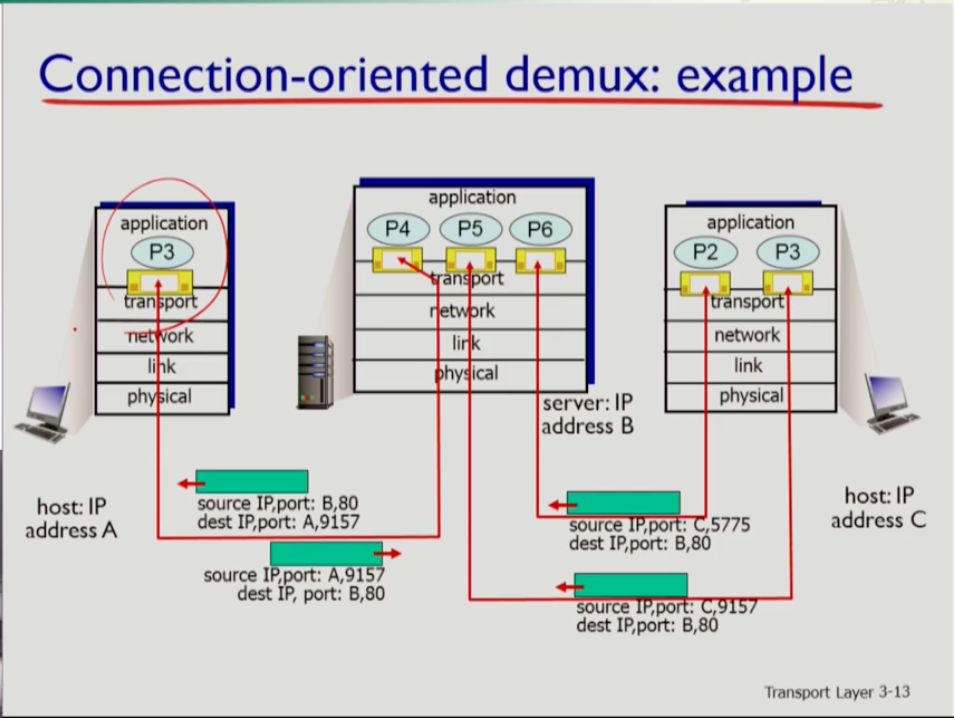
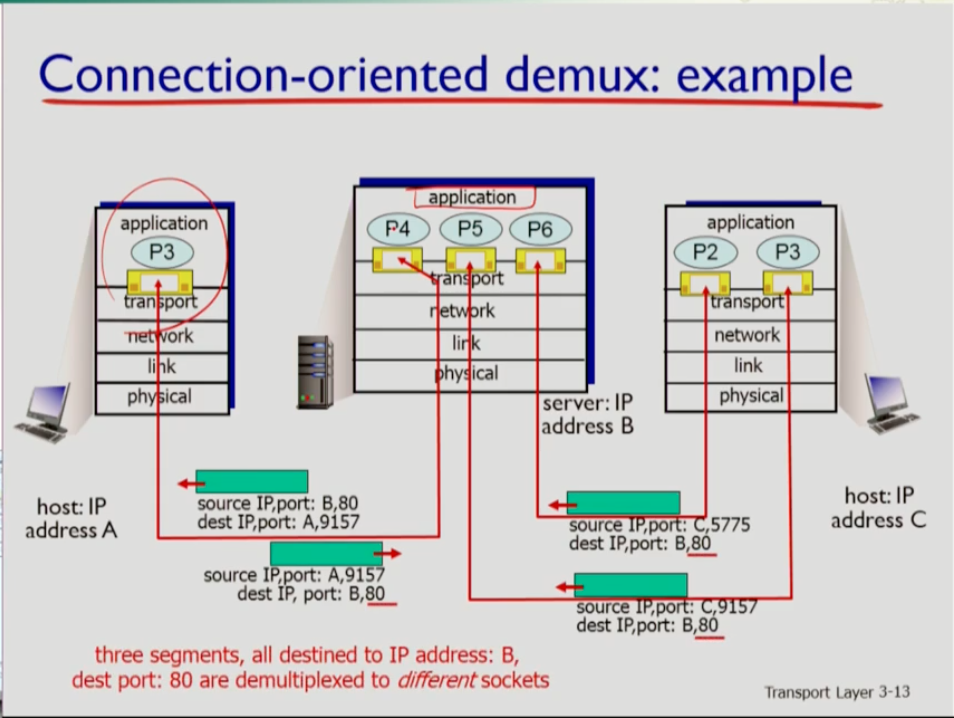
- Connectionless 일 경우 demux는 목적지쪽의 포트번호만 보고 일어난다. 그런데, Connection-oriented일 경우 demux는 어떨까. 이 경우 서버 호스트에 여러 앱이 있고 도어 소켓을 열고 있다. 이때 어떤 클라이언트가 연결을 할 때마다 그 클라이언트만을 위한 소켓을 별도로 열어준다. 이 경우 리시버 쪽에서 demux를 위해 위 네 가지 정보(source IP,source port number, dest ip address,dest port number)가 다 필요하다. dest ip를 보고 나에게 제대로 왔는지를 확인하고 dest port를 보고는 어느 앱인지를 알 수 있다(이는 door 소켓에 할당된 포트번호이므로). 또한 여러 클라이언트 중 해당 클라이언트를 위한 소켓이 어떤 것인지를 파악하기 위해 source ip 주소와 source port번호를 사용한다.
- 위 사진의 애플리케이션 밑에 여러 프로세스가 있는데, 커넥션이 들어오면 소켓을 만들 뿐 아니라 자식 프로세스도 포크를 한다.
- 프로세스가 여러개면 관리 오버헤드가 커지므로 스레딩 기법을 통해 동일한 어플리케이션 밑의 서로 다른 여러 소켓을 활동해 데이터를 주고받는다.
## Chapter 3 outline
Connectionless transport: UDP

- udp는 connectionless 이므로 핸드셰이킹이 없고 각 세그먼트를 독립적으로 주고받는다. 즉 각 세그먼트는 각자의 목적지 주소를 달고 나간다. 따라서 받는 쪽에서 각 세그먼트를 동일한 클라이언트에게 온 것으로 인식하지 않는다.
- 네트워크 계층에서 호스트 딜리버리를 제공하는 서비스에 추가적인 다른 서비스를 하지 않으며, 단순히 최선을 다해 네트워크가 배달해준 세그먼트를 바로 전달한다. 즉 중간에 유실을 파악하지 않고 알려주지도 않는다. 즉 데이터를 잃어버릴 수도 순서가 어긋날 수도 있다. 각 세그먼트를 독립적으로 인식하기 때문이다.
- 스트리밍 서비스는 udp를 좋아한다. 오디오 같은 경우 udp의 손실이 일어나도 별로 민감하지 않기 때문이다. 반면 이 경우 지속적인 플레이가 가능해야 하므로 단위시간당 minimum tolerant를 보장해야 한다. 또 dns의 경우 한 클라이언트가 쿼리를 지속적으로 여러번 보내고 여러번 받는 일이 없다. 한번 보내고 응답받으면 끝이다. 이 경우에도 tcp의 경우 계속해서 커넥션을 맺어야 해서 오버헤드가 발생하므로 udp를 쓴다.snmp의 경우도 네트워크의 여러 엔터키가 로컬 사이트를 관리하는 엔터키에 정기적으로 status 정보를 정기적으로 넘긴다. 따라서 한번 실수해도 조금 후에 최신 정보가 바로 넘어오므로 udp를 사용한다.
- tcp의 최고 장점은 reliable transfer를 한다는 것이다. 그러나 데이터의 무결성이 매우 중요한 경우 udp를 사용하기도 한다. 이 경우 어플리케이션 스스로가 무결성을 체크하고 손실을 회복하는 기능을 갖고 있기 때문에 중간에 손실이 발생해도 체크에서 걸러지거나 회복이 되므로 큰 상관이 없다.
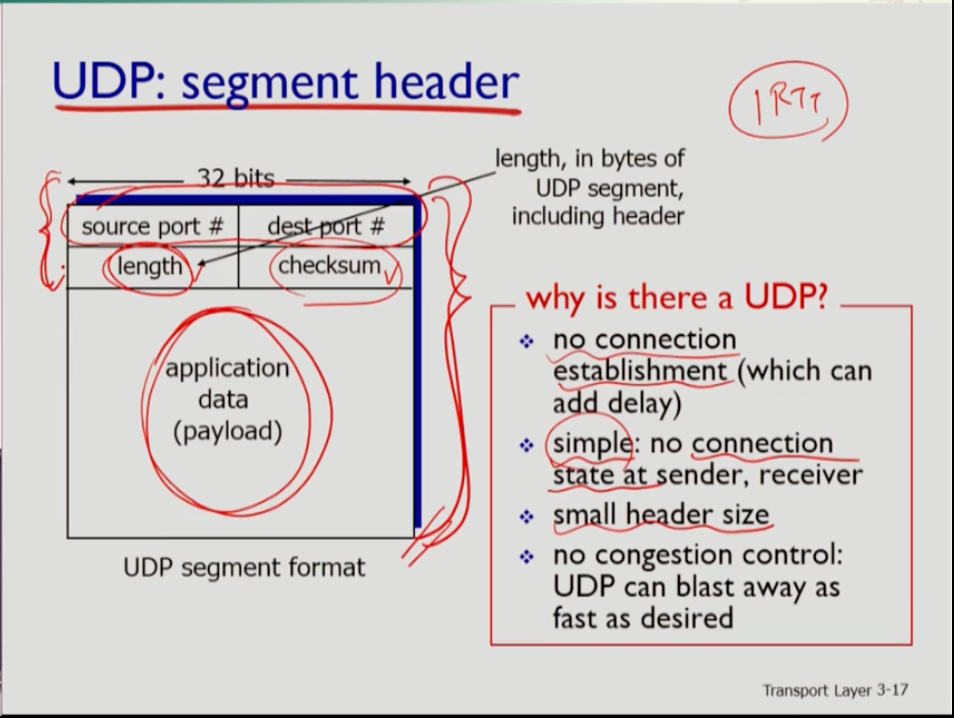
- udp의 장점은 커넥션이 없으므로 오버헤드가 적고 세그먼트를 딜레이 없이 금방 내보낼 수 있다. 따라서 커넥션 상태를 유지할 필요 없어 프로토콜 유지가 간단하다. 또 헤더의 크기가 작아 오버헤드가 적다. 위 사진처럼 udp가 하는일은 mux와 demux 둘이므로 이 두 정보만 필요하다. 그것을 위해 source port와 dest port 두 가지만 필요하고 length(udp 세그먼트 전체 길이 정보)와 checksum은 별로 크지 않으므로 헤더의 사이즈가 작다. 또 congestions control이 없어 애플리케이션이 데이터를 생성하는 속도로 네트워크로 밀어넣을 수 있다.


- UDP checksum에 대한 설명이다 sending udp는 각 세그먼트를 16비트의 연속으로 보고 이들을 모두 더한다. 이 더한 것을 checksum field라 하는데, 보내는 측에서 이를 받는 측에 보내면 받는 측에서는 역시 똑같이 udp 세그먼트를 16비트로 다 더한 다음 보내는 측에서 작성한 체크섬과 일치하는지 확인한다. 여기서 일치하지 않으면 중간에 전송 에러가 발생했다고 가정하는 것이다. 하지만 이는 실제로 발생하는 에러를 모두 발생할 수 없다. 데이터 자체에는 변화가 생겨도 체크섬의 총합이 같으면 감지를 못 하기 때문이다. udp는 오류 발생 여부가 중요하지 않으므로 잘 쓰지 않지만 경우에 따라서 오류 정보를 어플리케이션에 올려 보내줄 수 있다. 오류가 발생할지도 모른다는 뜻을 전달하기만 하는 것이다.
3.4 Principles of reliable data transfer


- 일반적으로 reliable한 data transfer를 하기 위해서는 어떤 프로토콜 요소가 필요할까? 먼저 리시버가 세그먼트를 받았을 때 오류 여부를 확인하는 체크섬이 필요하다. 그리고 오류가 있는지 없는지를 상대방에게 알려주는 Acknowledgement가 필요하다. 리시버가 센더에게 패킷을 잘 받았는지를 알려주는 것이다. 이 신호는 하나의 패킷에 대한 신호일 수도, 아니면 여태까지 전달되어 축적된 패킷 전체에 대한 신호일 수도 있다. 또 Negatice Acknowledgement도 필요한데 센더에게 어떤 패킷이 잘못 된것을 말한다. 특정 패킷을 집어서 말해야 그 패킷에 대해 다시 재전송을 할 수 있다. 마지막으로 위 과정이 모두 문제가 없더라도 만약 네트워크에서 패킷 자체를 드랍해버리면 리시버 측에 패킷이 도착할 수 없어 애초에 신호를 보낼 수가 없다. 제대로 받았다는 신호가 와야 센더가 다음 패킷을 보내는데 이 경우 센더가 한없이 기다릴 수 있다. 그러므로 타이머가 필요하다. 패킷을 보내놓고 일정 시간동안 신호가 오지 않으면 네트워크가 드랍한 것을 가정하고 재전송을 하는 것이다. 그러나 불필요한 재전송이 발생하기도 한다. 리시버가 패킷을 잘 받고 보낸 신호가 드랍될 수 있기 때문이다. 따라서 시퀀스 넘버가 필요하다. 패킷에 id인 넘버를 부착하는 것이다. 또 센더와 리시버 사이를 넓고 긴 파이프라 가정할때, 파이프가 길고 넓다면 패킷을 빨리 실어나르기 위해 잘 받았다는 신호가 안 와도 패킷을 계속 밀어넣는다. window pipelining은 파이프에서 최대로 집어넣을 수 있는 양이 window를 뜻하고 그 window만큼만 파이프에 패킷을 한꺼번에 집어넣는다는 뜻이다.
3.5 Connection-oriented transport: TCP

- tcp는 reliable하고 순차적인 전송을 하는데, 전송하는 데이터를 byte steam으로 본다. 유저가 메세지를 내려보내면 본인의 버퍼에 받고 그것을 뽑을 때는 congestion/flow 컨트롤에 의해 제어되는 메세지를 뽑는다. 메세지 바운더리는 인식하지 않고 유저가 데이터들을 바이트의 연속으로 본다는 뜻이다. 즉 메세지의 양과 상관없이 원하는 만큼만 뽑아서 보낸다는 것이다. 받는 측 역시 데이터를 버퍼에 먼저 받고 사용자가 원하는 만큼 읽어가게 한다.
- 또 커넥션을 셋업하기 위해 핸드셰이킹을 한다.
- tcp는 센더 한명, 리시버 한명을 두는 point To point transport 방식이다.
- 또 full duplex data connection을 맺는데 이는 클라이언트 프로세스와 서버 프로세스가 tcp 커넥션을 맺으면 클라이언트에서 서버로 혹은 서버에서 클라이언트로, 양방향으로 메세지를 보낼 수 있다는 뜻이다.
- 또 tcp는 파이프라이닝을 하여 여러 세그먼트를 내보내 효율성과 작업량을 높인다.
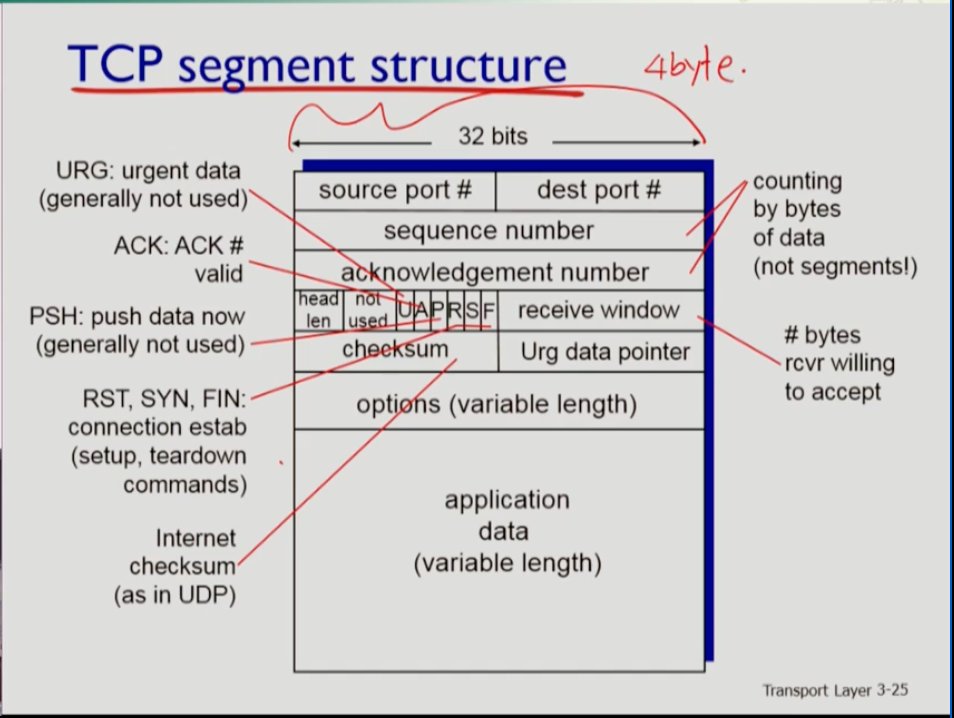
- 다음은 tcp 세그먼트의 구조다. udp와 마찬가지로 헤더와 페이로드로 나뉘어진다. 그러나 tcp가 훨씬 복잡하다. tcp가 udp보다 하는일이 훨씬 많기 때문이다. tcp 헤더에는 udp 헤더와 달리 고정파트와 가변파트가 있어 헤더의 길이는 가변적이므로 header length field가 있어 이를 통해 어디까지 헤더인지 파악하도록 해야 한다.
- 가로의 길이는 32비트=4바이트다. 4바이트 짜리가 고정 헤더에 5줄이 있다. 따라서 고정 헤더 길이는 20바이트다. tcp 헤더의 디폴트 값이라는 것이다. 먼저 소스 포트번호 목적지 포트번호가 있다. 그 다음에는 시퀀스 번호가 있다. 이를 통해 앱 데이터 필드에 포함된 데이터 바이트가 몇 번째 데이터 바이트인지 바이트 넘버를 표시해 준다. 커넥션이 시작되고 클라이언트가 서버에 데이터를 보낼 때 클라이언트가 몇 바이트번호를 보낼 것인지 미리 말해준다. 그 다음 acknowledgement field에는 상대방이 나에게 보낸 데이터에 대한 ack넘버가 들어간다. 그 다음 receive window 는 flow control을 위한 필드다. 상대방으로부터 오는 데이터를 받을 버퍼 사이즈를 결정하는 것이다. 또 체크섬이 있으며, U,A,P,R,S,F 의 플래그가 있으며 의미는 그림과 같다. URG(Urgent) data pointer는 소켓을 통해 어플리케이션이 내려보낼 때 URG플래그가 세팅되어 있으면 바로 애플리케이션으로 올려 보내는데, 애플리케이션에게 어느 위치에 URG한 데이터가 박혀있는지 표시해주는 것이다.
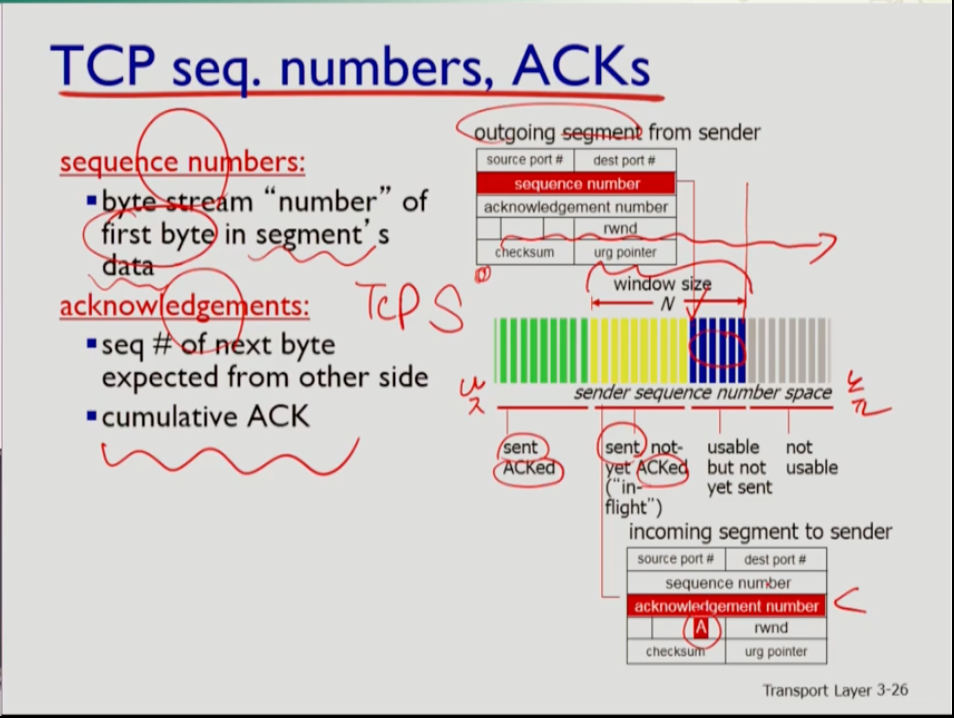
- tcp 시퀀스 번호는 세그먼트의 페이로드에 있는 데이터의 첫 번째 바이트에 있는 번호다. acknowledgements 번호는 상대방에게 상대방이 몇 번째 데이터를 보낼 것인지 기대한다는 뜻. 즉 이전 데이터까지 잘 받았다는 cumulative한 신호다.
- 사진에서 왼쪽(초록)이 시퀀스 번호가 더 낮은 쪽이다. 새로운 세그먼트를 만들어 내보낼 때, 시퀀스 넘버에 실리는 번호는 파란색, 즉 아직 사용하지 않은 번호가 실려 보내진다. 반면 센더가 ack을 받았을 때 ack 받은 넘버는 노란색(보내졌는데 확인되지 않음)에 해당하는데. 그 노란색은 연두색(ack이 와서 확인 됨)으로 변한다.
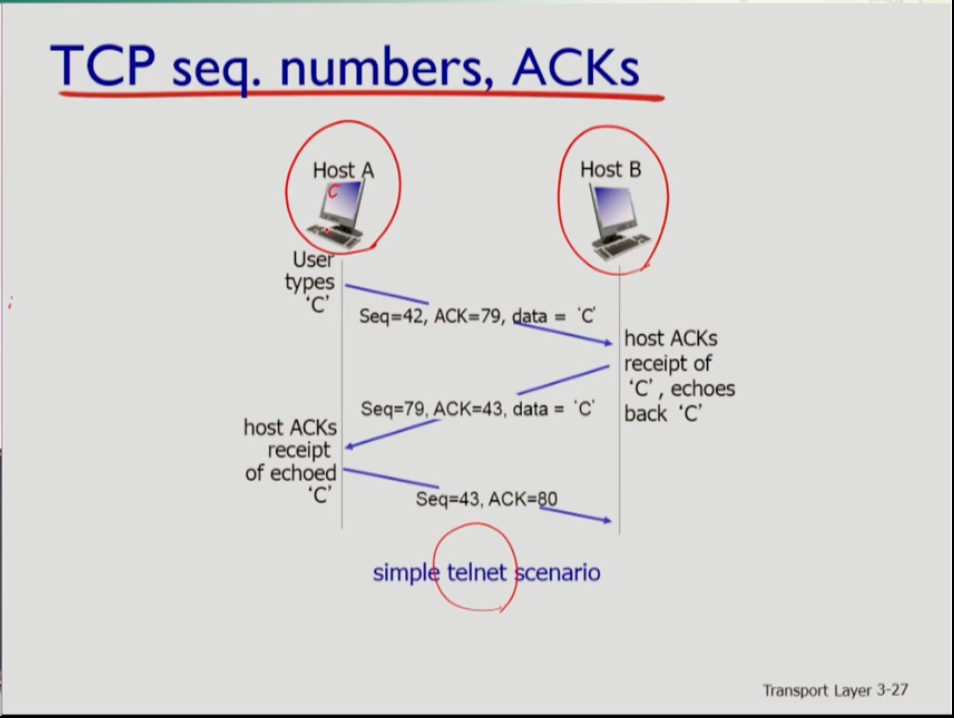
- 시퀀스 번호와 ack번호의 telnet 시나리오 예시다. 호스트A에서 키보드로 가령 "C"를 타이핑하면 호스트 B로 전달되고 B에서 에코로 Ack를 해주면 호스트A가 Ack신호를 받고 브라우저에 띄운다.

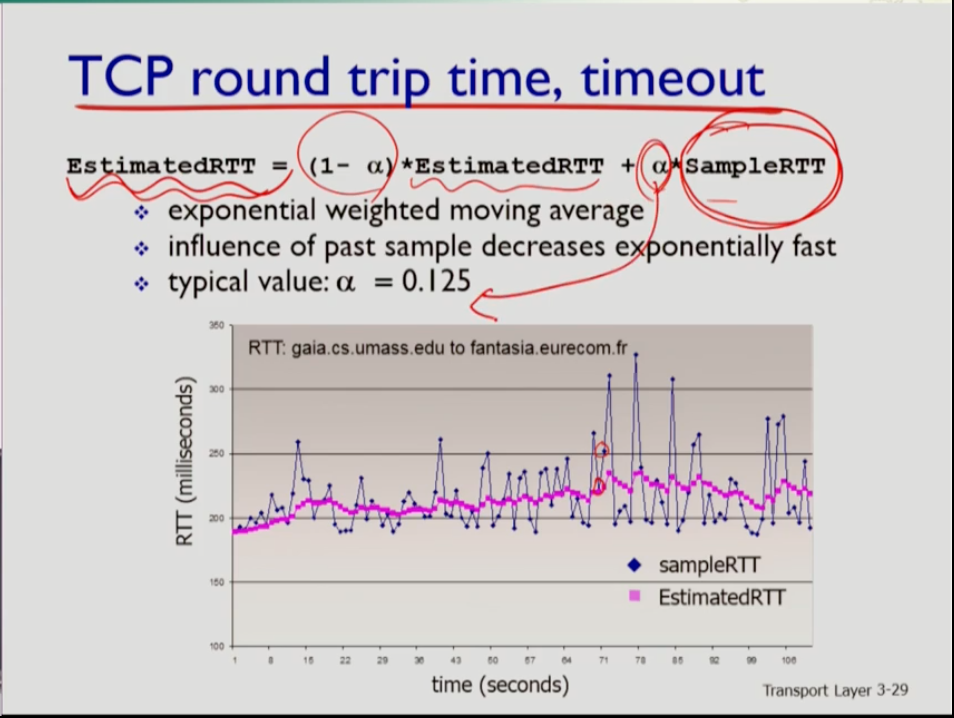
- 타이머는 round trip 시간과 관련성이 깊다. 세그먼트가 가고 ack이 와야 하기 때문이다. RTT만큼 기달렸는데도 ack이 안오면 문제가 생긴거다. RTT를 정확히 예측해야 하는데 너무 짧게 예측하면 불필요한 재전송을 하고, 너무 길게 예측하면 실제로 세그먼트가 드랍되고 늦게 인지해 리액션이 늦는 문제가 생긴다. 따라서 세그먼트에 대해 ack들어올 때마다 rtt 샘플을 구하고 여러 샘플을 모아 평균으로 다음 rtt를 예측한다. 이 때 유의할 점은 재전송된 rtt에 대해서는 샘플링하지 않는다. 오리지널 세그먼트에 대한 rtt인지 재전송된 세그먼트에 대한 rtt인지 파악이 불가능하기 때문이다. 따라서 RTT추정은 전 RTT를 1-알파만큼 + 현재 RTT를 알파만큼 반영해서 RTT를 추정한다.

- 그러나 여전히 실제 rtt와 추정값간의 차이가 있으므로 safety margin을 더하는데 이는 샘플rtt와 추정 rtt간 차이를 베타만큼 반영하고 그 전 rtt의 차이를 1-베타만큼 반영한다. 이때 rtt차이가 크면 safety margin을 크게 두고 rtt차이가 적으면 적게 둔다. 결국 타임아웃 인터벌을 추정 rtt에 rtt차이(safety margin)를 4 곱한 값을 더해 지정한다.

하마드