(이 글은 외로운 우테코 5기 취준생 “김동욱”, “이건회” aka “그레이”, “하마드”가 작성했습니다.)
문제 발생
비동기 처리와 스레드 풀 튜닝을 통해 알림 기능을 개선하며 성능 테스트 하던 중, 문제가 발생했다.
??????????????
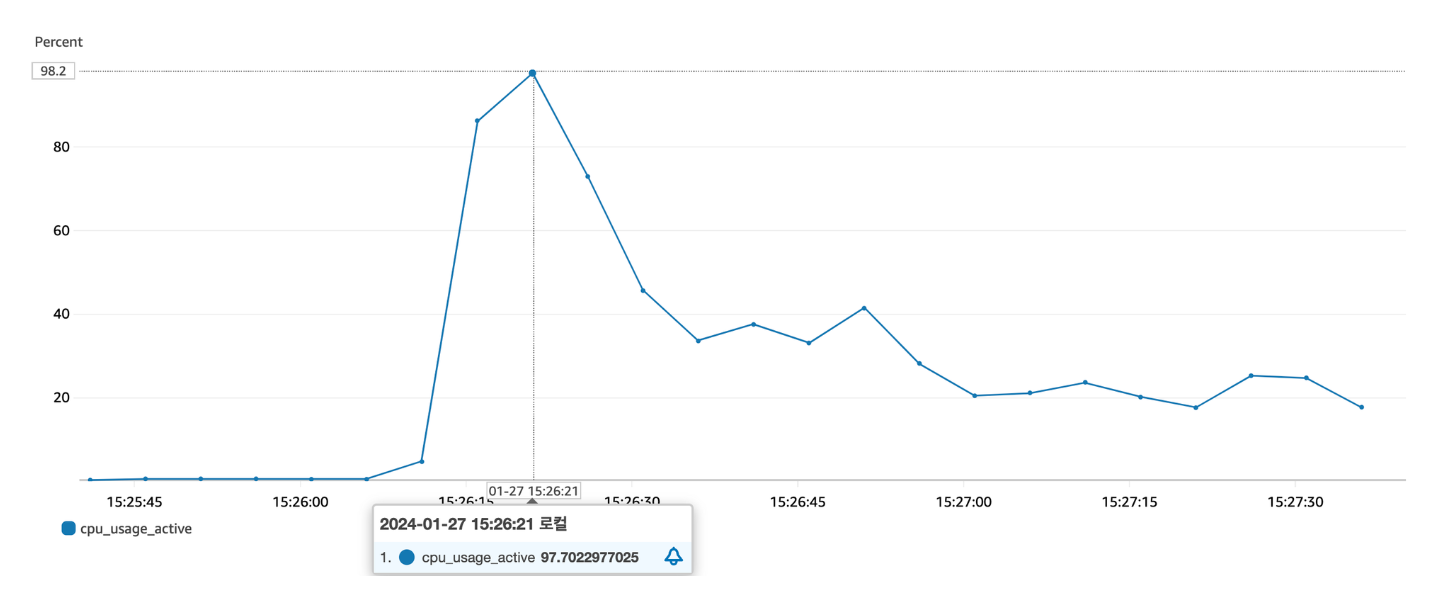
갑자기 CPU 수치가 급등해 99.9%를 찍게 되는 현상을 발견했다.
알림을 처리하는 중 간헐적으로 발생하는 것이 아닌, 배포를 완료한 직후 요청(초반)에만 발생한 후 천천히 내려가는 것을 파악했다. 가용 중인 애플리케이션에서 CPU 수치가 99%를 찍는다는 것은 굉장히 위험한 징후다.
누가 CPU를 좀먹고 있었을까?
해당 현상을 확인하기 위해 다양한 시도를 했다.
- 배포 직후 스레드 덤프 → 총 32개 스레드
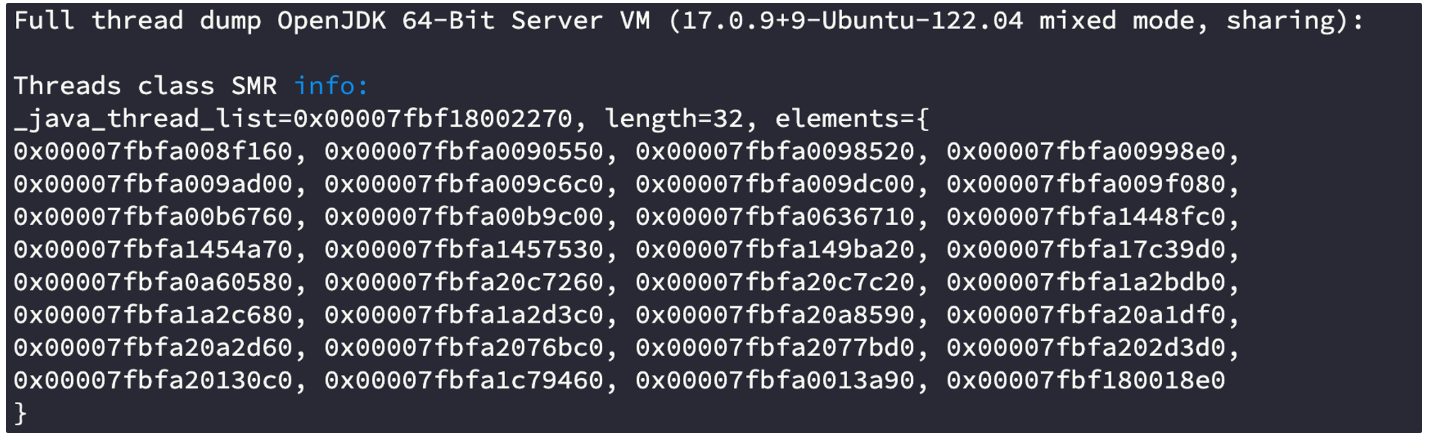
먼저 스레드 덤프를 통해 확인해보니 알림 요청이 오기 전에는 비동기 스레드가 생성되지 않다가, 알림 요청이 온 이후에야 스레드가 생성 후 RUNNABLE 상태가 되는 것을 파악했다.
- 비동기 스레드 생성 후 스레드 → 총 112개 스레드
- 알림 호출 스레드 40개 + FCM 비동기 호출 스레드 40개
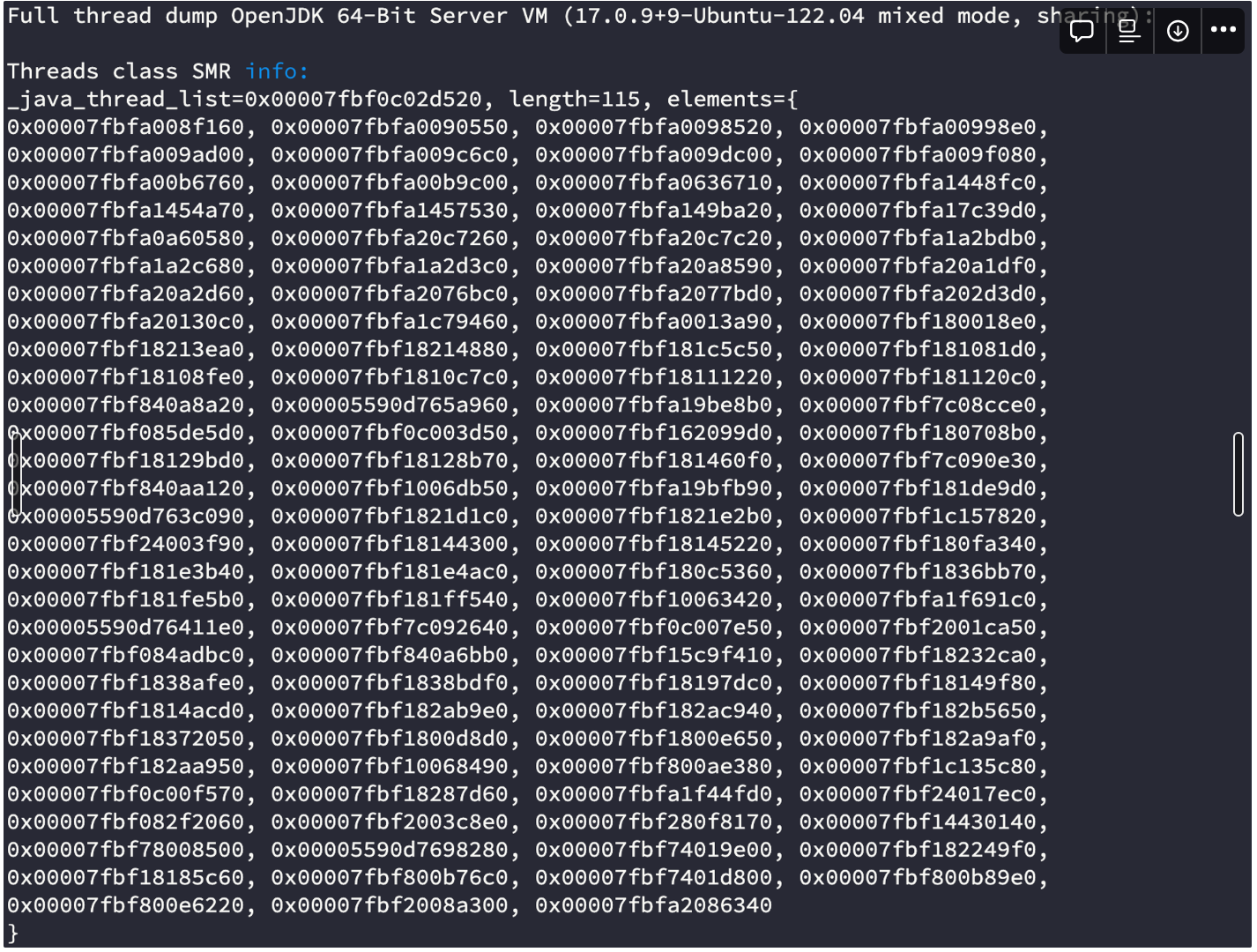
비동기 스레드를 생성하는 과정에서 CPU 스파이크가 일어나지 않을까란 가설을 세웠고, 미리 40개의 스레드를 만들어 놓는 요청을 보낸 뒤 테스트를 해봤다.
하지만, 여전히 CPU 사용량은 초반 99%까지 튀어오르는 것을 볼 수 있었다.
그런데, 우리가 간과했던 부분이 있었다.
“그냥 어떤 스레드가 CPU를 많이 쓰고 있는지 보면 원인파악 되는 거잖아…?”
따라서 리눅스의 top-H 명령어를 통해 각 스레드의 CPU 사용량을 체크해 보았다.
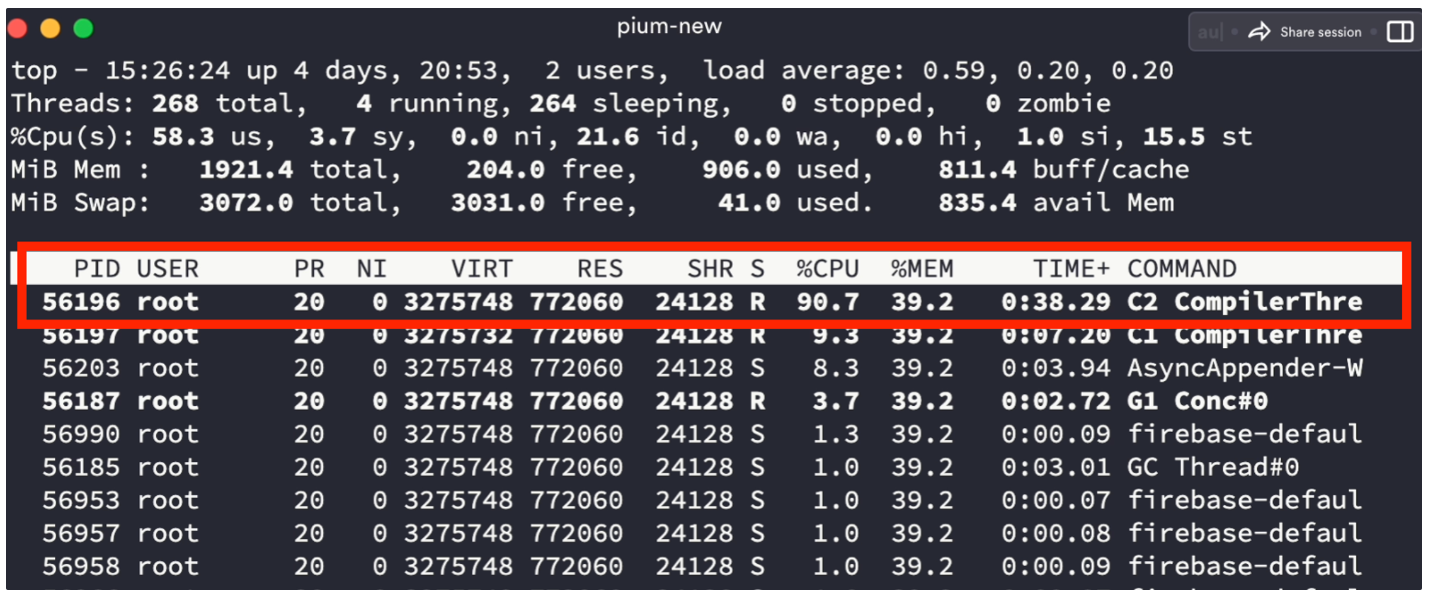
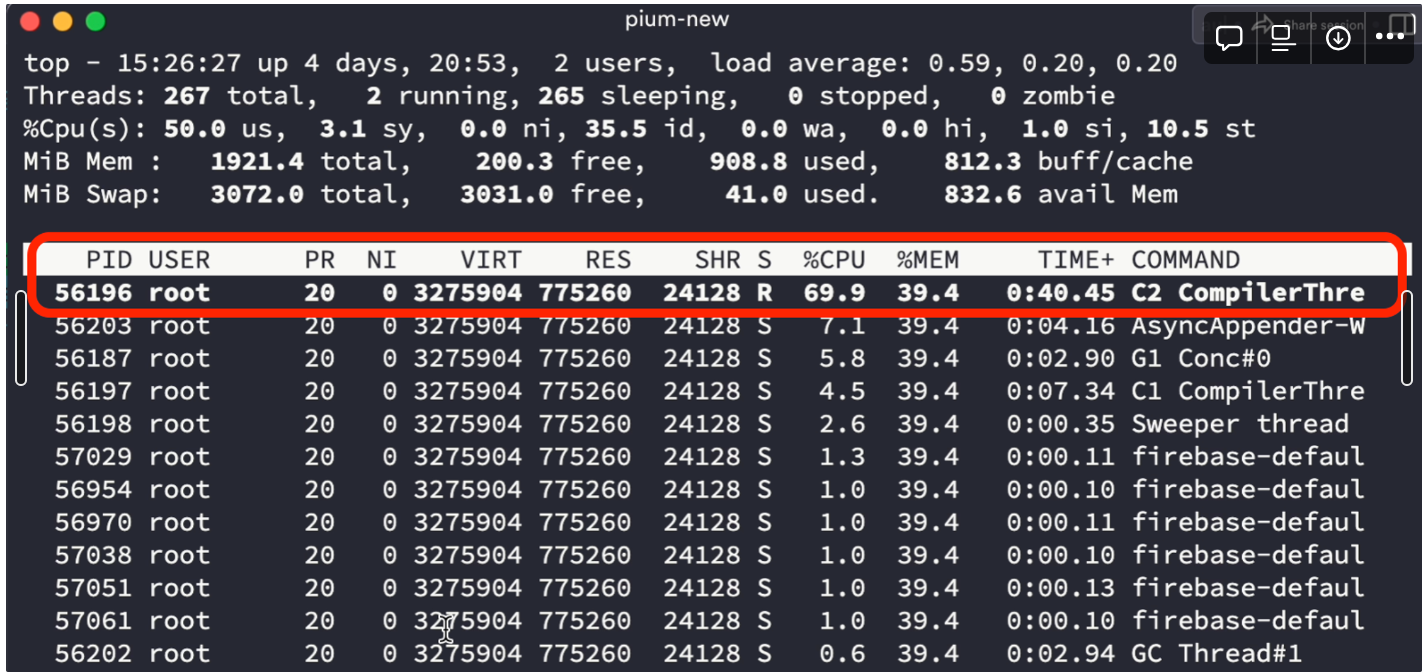
알림 비동기 처리를 담당하는 담당하는 40개의 스레드는 각각 1~3%의 CPU 사용량을 보이지만,
갑자기 웬 C2 Complier라는 놈이 튀어나와 스레드를 혼자 50~60%에 가장 많게는 90%까지 먹어치워버린다.
알림 기능 동작 시 최대 40개 스레드를 할당하도록 했고 각 스레드가 1~3% 내외로 CPU를 사용하는데, C2 Complier가 혼자 절반 이상을 먹어버리니 CPU 스파이크 현상이 발생했던 것이다.
(포켓몬 오박사 톤으로) 근데, 대체 C2 Compiler가 뭘~까요?
자바 컴파일 과정
이를 이해하기 위해서는, 먼저 자바의 컴파일 과정을 이해해야 한다.
자바는 C, C++, GoLang과 같은 컴파일 언어와는 다르게 소스 코드를 중간 언어로 불리는 바이트 코드로 컴파일 해야 한다. 쉽게 말해 바이트 코드는 JAR, WAR 파일이다. 이 JAR, WAR 파일을 실행하면 JVM은 바이트 코드를 읽어 기계어로 만든다.
자바의 컴파일 과정을 더 자세히 설명하면 아래와 같다.
- 개발자가 작성한 코드를 자바 컴파일러(javac)가 읽어 바이트 코드로 변환
- 변환된 바이트 코드를 클래스 로더가 읽어 프로그램 실행에 필요한 부분을 메모리에 적재
- JVM 실행 엔진은 메모리에 올라온 바이트 코드를 읽어서 실행
빌드된 바이트 코드는 별도의 추가 빌드 없이, 자바가 실행 가능한 CPU 아키텍쳐에서 언제든지 실행할 수 있다는 점이 자바의 장점이다. JVM 실행 엔진이 메모리에 올라온 바이트 코드를 읽어서 프로그램을 실행하는데 이 때 실행 엔진은 두 가지 방식으로 사용된다.
첫 번째 방식은 인터프리터 방식이다. 바이트 코드를 하나씩 읽어서 실행한다. 그러므로 전체적인 실행 속도가 느리다.
두 번째 방식은 JIT이다. 바이트 코드를 하나씩 읽는 것이 아닌, 전체 바이트 코드를 한번에 컴파일 해 바이너리 코드로 변환한다. 이후에 해당 코드를 다시 접근할 때는 이미 변환된 바이너리 코드를 이용해 실행한다.
JIT 컴파일러
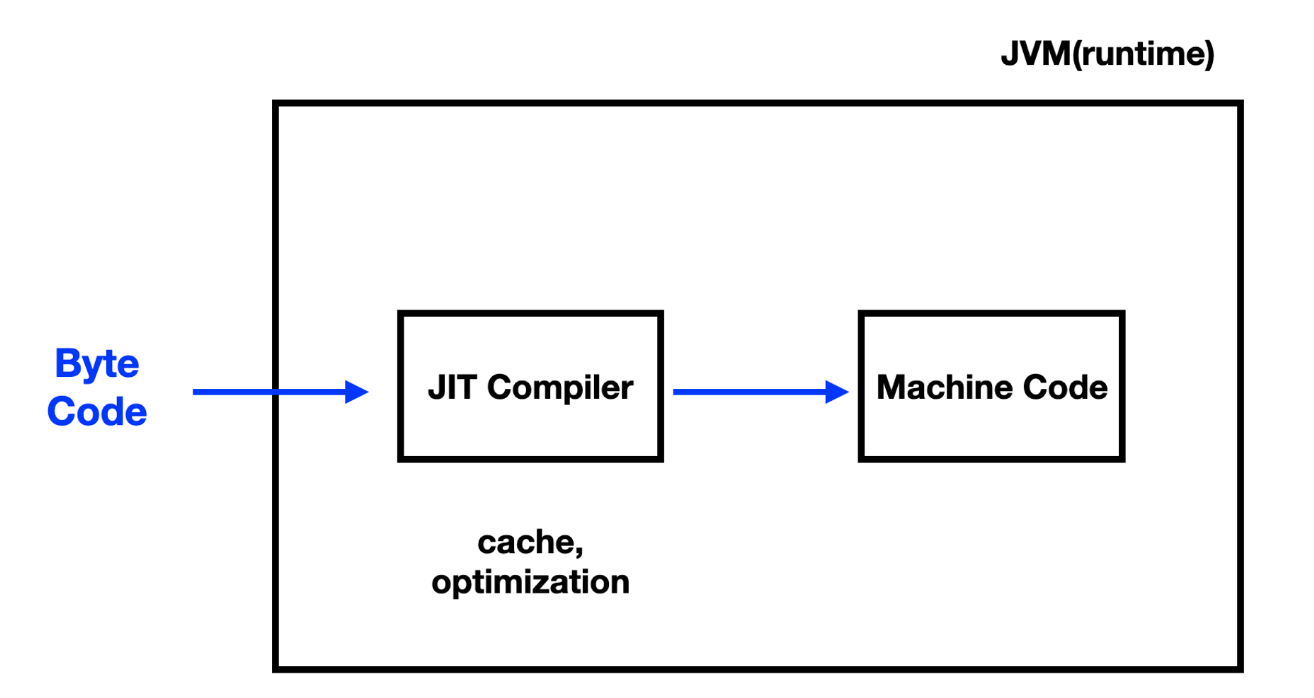
모니터링 중에 발견한 C2 Compiler는 JIT 컴파일러의 스레드 중 하나이다.
JIT 컴파일러는 C1 Compiler와 C2 Compiler로 이루어져 있다. 바이트 코드를 머신 코드로 변환하는 과정에서 자주 사용되는 머신 코드를 캐시에 저장한다. C1 Complier는 실행(컴파일 및 최적화) 속도가 빠르지만 덜 최적화된 코드를 생성하도록 설계된 반면, C2 Complier는 컴파일 및 최적화하는 데 시간이 조금 더 걸리지만 더 최적화된 코드를 생성한다.
C2 Complier는 (사소한 부분을 제외한)메소드의 전체를 최적화하기 때문에 최적화가 일어나는 순간에 CPU 사용량이 급증하게 된다.
이를 통해 반복되는 기계어 변환 과정을 줄이게 되어 성능이 향상된다. 하지만 애플리케이션을 시작하는 단계에서는 캐시된 내역이 없기 때문에 자연스럽게 성능 이슈가 발생할 수 있다.
JIT가 내부적으로 어떻게 동작하는지 파악하는 것이 중요하다. JIT은 바이트 코드를 하나씩 컴파일하는 인터프리터와 다르게 메서드 전체 단위로 컴파일한다.
- Method
- 메서드 내 모든 바이트 코드는 한꺼번에 네이티브 코드로 컴파일
- Profiling
- 실행 시간, 메소드 호출 횟수, 메모리 사용량 등을 고려해 최적화할 부분을 결정
- Tiered compilation
- JIT은 단계별 컴파일을 통해 코드를 최적화한다. 이 때 C1, C2 컴파일러가 등장하는데 C1은 간략한 최적화, C2는 최대 최적화.
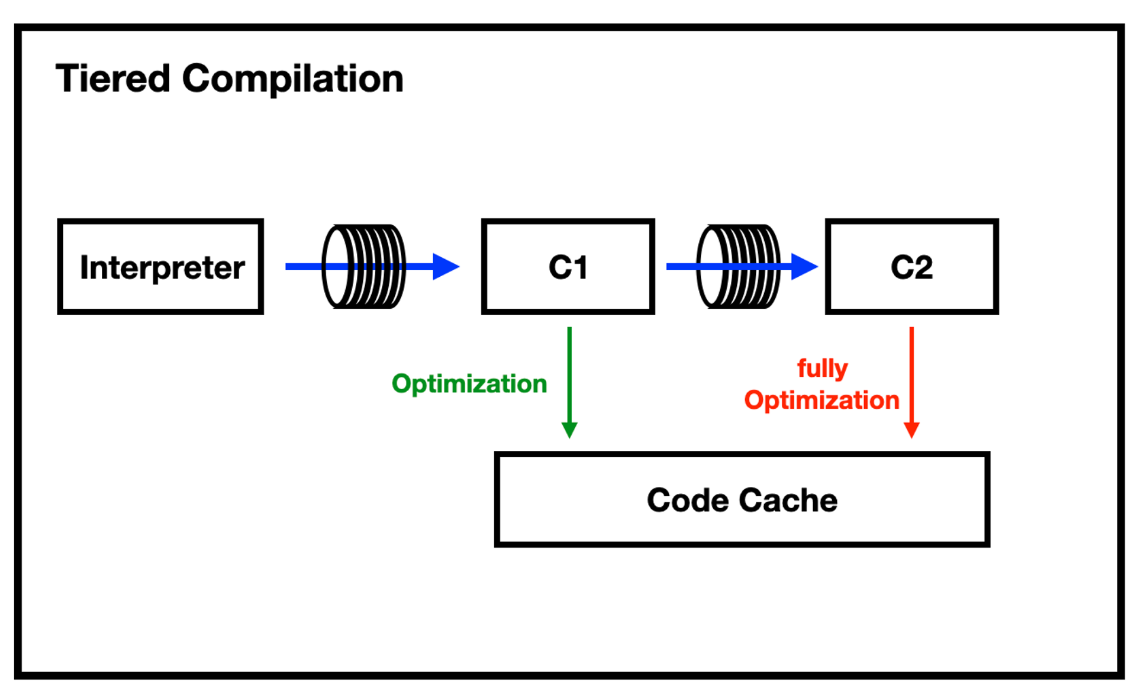
인터프리터를 통해 바이트 코드가 기계어로 번역된다. 해당 메서드가 정해진 임계치 만큼 호출되면 C1 컴파일러를 통해 간략한 최적화를 진행한다. 이후 C2 컴파일러의 임계치 만큼 호출되면 최대 최적화를 진행한다.
여기서, 임계치란 무엇일까?

JVM 내에서 컴파일 레벨이 설정되어 있는데 레벨 0부터 레벨 4까지 설정되어 있다.
- 레벨 0 : 초기에는(보통 배포 직후를 의미) JVM이 모든 자바코드(정확히는 바이트코드)를 인터프리팅해 기계어로 번역. 하지만 코드를 실행시킨 직후 JVM이 런타임에 핫코드(실행 빈도가 높은 코드)를 컴파일해 프로파일링 정보 수집.
- 레벨 1 : 복잡성이 낮은 메소드에 대해 C1 Complier가 동작하는 단계. 이 메소드에 대해서는 프로파일링 정보를 수집하지 않음. 복잡성이 매우 낮아 C2 Complier를 사용해도 성능이 크게 향상되지 않기 때문.
- 레벨 2 : 만약 C2 Complier로 가기 위한 큐가 꽉 찼다면, JVM은 해당 메소드를 이 레벨에서 가벼운 프로파일링을 사용하는 C1 Complier를 통해 컴파일한다. 이후에 JVM은 이 코드를 전체 프로파일링을 사용하는 레벨 3에서 다시 컴파일하고, C2 컴파일러 큐의 공간이 났을 때 해당 큐로 코드를 보낸다.
- 레벨 3 : 메소드 사용량이 정해진 임계치를 넘었을 때, 메소드가 복잡성이 낮지 않거나, C2 컴파일러 큐가 꽉 차서 레벨 1이나 레벨 2로 가는 경우를 제외하고는 모두 이 레벨에서 컴파일링을 실행한다. 전체 프로파일링을 사용하는 C1 Complier를 사용하며, 일반적으로 레벨 0에서 바로 레벨 3으로 넘어오게 된다.
- 레벨 4 : 장기적인 성능 극대화를 위해 C2 Complier를 이용해 코드를 컴파일한다. 사소한 메소드를 제외한 모든 메소드를 컴파일링하며, 프로파일링 정보 수집을 중단한다. 하지만 JVM이 역최적화(실제 코드를 수행하는 최적 경로와 최적화 결과가 다를 때 수행)를 진행하면 레벨 0으로 다시 강등된다.
바이트 코드가 레벨 0을 통해 기계어로 번역 후 C1 임계치 보다 많이 실행되면 큐로 전달된다. C1에서는 세 가지 레벨에 따라 최적화를 진행한 후 코드 캐시에 저장한다. 최적화 레벨을 변경하는 기준이 임계치이다.
- 총 3가지 임계치
- InvocationThreshold: 메서드 호출 수
- BackEdgeThreshold: 메서드 내 반복문 횟수
- CompileThreshold: 메서드 호출 수 + 메서드 내 반복문 횟수
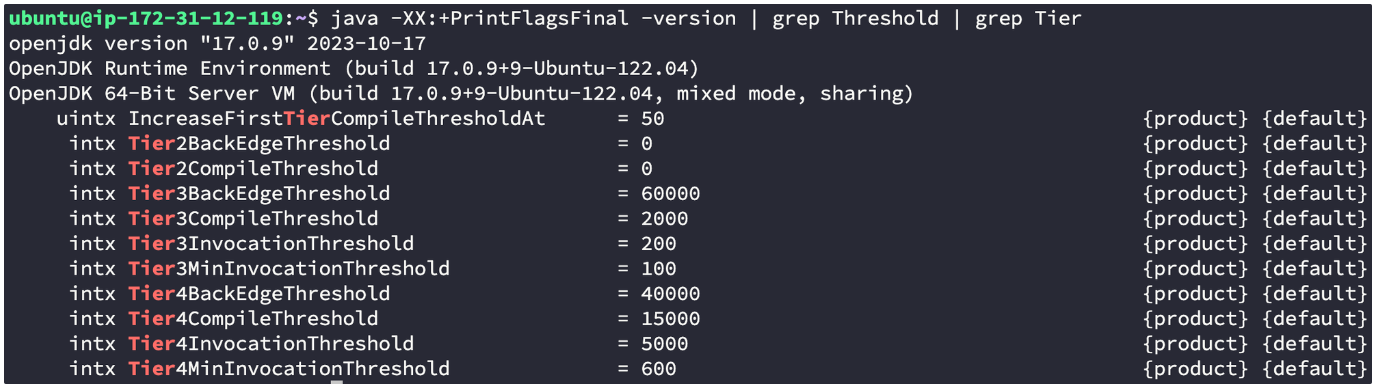
우리 서버의 임계치는 얼마일까? 아래 명령어를 통해 확인해 보자
java -XX:+PrintFlagsFinal -version | grep Threshold | grep Tier아래와 같이 현재 서버의 임계치를 찾을 수 있다.
JVM WarmUp을 통해 CPU 스파이크를 해결해보자
다시 본론으로 돌아가서 배포 후 CPU 스파이크가 발생했던 원인인 C2 Compiler 스레드가 동작하는 것을 해결해보자.
C2 Compiler는 레벨 4 최적화를 진행하고, 이 때의 임계치는 인보케이션 5000, 백엣지 40000, 컴파일 15000이다.
성능 테스트를 진행하던 알림 수가 100000개였고 100000번의 알림 이벤트, 알림 전송 메서드가 실행된다. 그러므로 C2 컴파일러가 동작하는 기준이 충족되었고 코드 캐시가 충분히 갖춰지지 않은 배포 직후에 CPU 스파이크가 발생했던 것이다.
해당 코드가 적절히 코드 캐시에 미리 배치되도록 JVM을 WarmUp하는 작업이 필요했다.
여기서 WarmUp이란, 미리 한번 JVM을 달궈주는 것을 의미한다. 마치 우리가 수영장에 들어가기 전에 몸에 찬물을 미리 끼얹어주는 것과 같다.
여기서는 갑작스런 대량의 처리를 대비해 CPU가 적은 비용으로 작업을 처리할 수 있도록, 배포 직후 미리 해당 메소드를 사용하는 요청을 몇 번 보내 주면서 C2 Complier로 코드를 최적화해 캐싱해두는 것이다.
그렇다면 어느 정도의 요청을 미리 보내주어야 할까? 한번 직접 보내보면서 테스트를 진행해봤다. 한 번에 5000개의 테스트 알림을 보내면서, 각 회차별 최대 전체 CPU 사용량과 C2 Complier의 최대 CPU 사용량을 체크해봤다.
우리는 이전 포스팅에서 비동기 스레드 갯수를 40개를 쓸지, 50개를 쓸지 고민했었다. 따라서 두 경우 모두 테스트를 실행하며 JVM WarmUp을 충분히 달군 상태에서 최대 CPU 사용량을 체크하기로 했다.
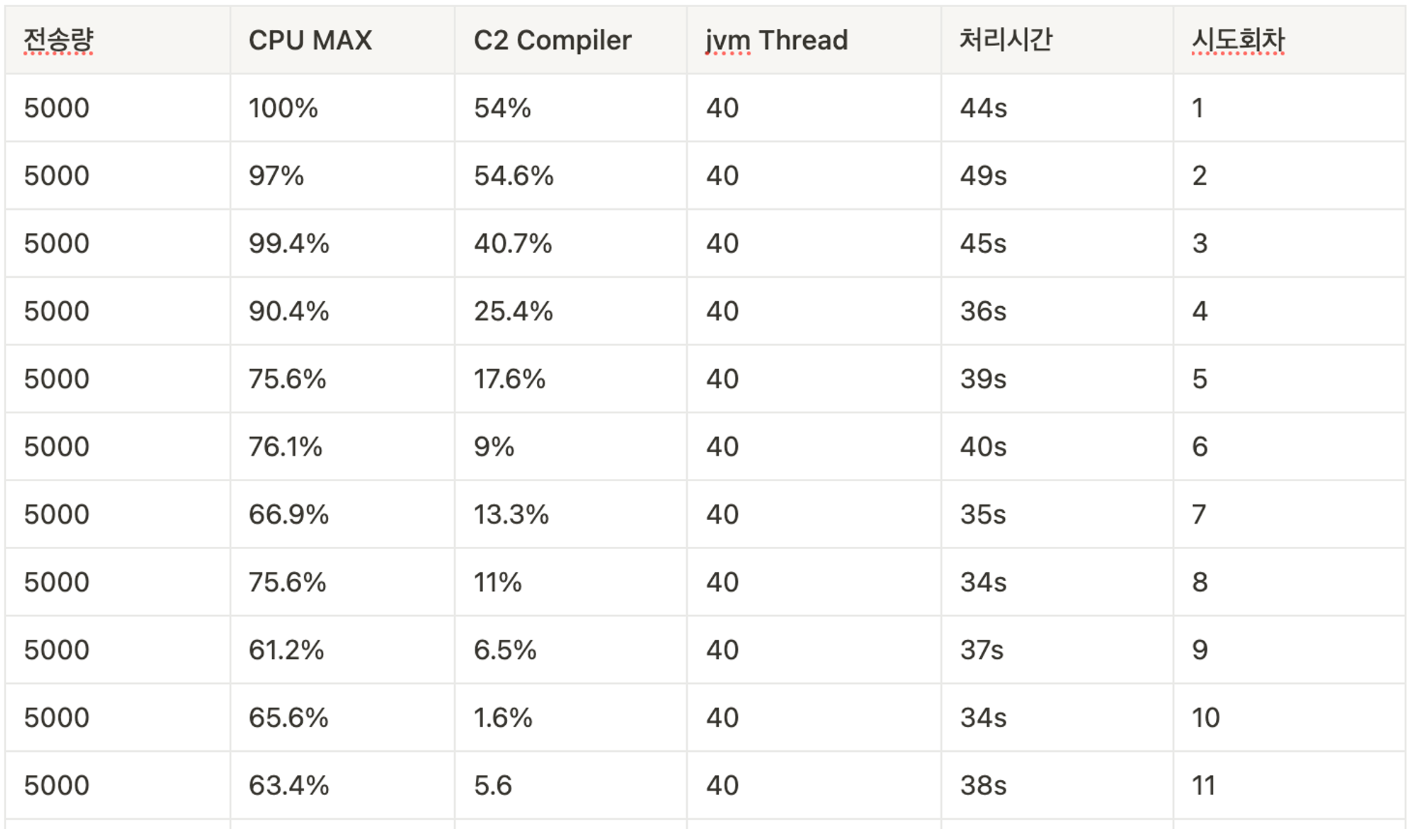
위는 40개의 스레드로 테스트한 결과다. 7~8회 정도 jvm warm up을 진행한 시점에 C2 Complier의 CPU 사용량이 줄어드는 것을 확인할 수 있었고, CPU의 최대 사용량도 65% 이하(평균적으로는 30%~40% 사용)를 유지했다. 또 최적화가 진행되기 이전에는 1~3%의 CPU 사용량을 기록하던 비동기 스레드가 WarmUP 이후 평균 1% 미만의 사용량을 보이고 있었다.
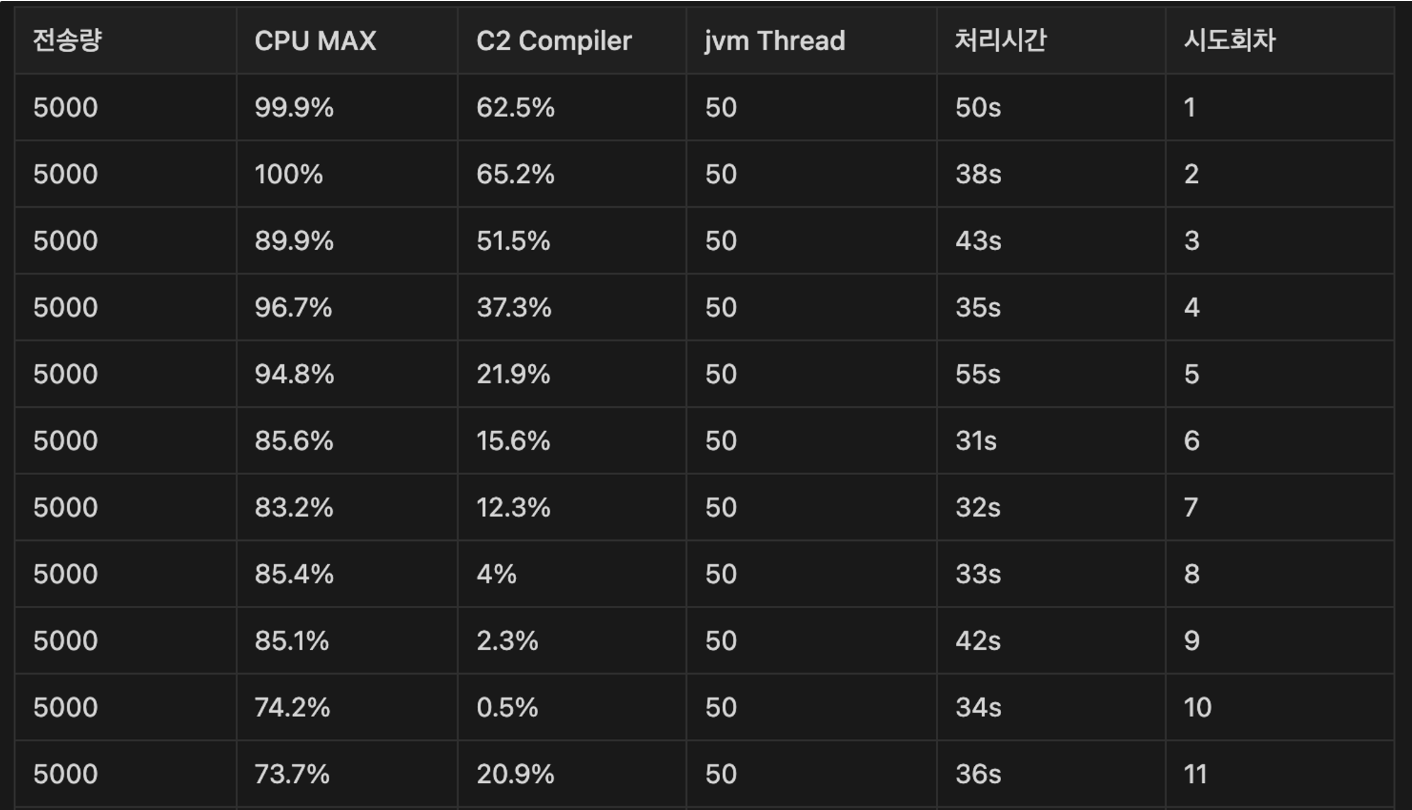
위는 50개의 스레드로 테스트한 결과다. 역시 C2 Complier의 사용량이 줄어드는 시점이 비슷하다. 하지만 11번의 WarmUp을 진행해도, 애초에 스레드 양이 많기에 최대 사용량 70% 이상을 매 테스트마다 기록한다(물론 평균은 저 수준보다 낮다).
따라서 더 안정적으로 JVM을 WarmUp하기 위해, 7~8회보다 살짝 높은 수치인 10회 정도 미리 WarmUp용 알림(실제 사용자가 아닌 다른 곳에 전송)을 보내는 조치를 취하기로 했으며, 비동기 스레드를 40개 사용하는 것으로 결론 지었다.
정리
- 10만개 알림 전송 테스트를 진행하던 중 초반 일시적으로 CPU가 99%까지 튀어오르는 현상 발생
- 배포 직후 JIT C2 Complier의 최적화 작업으로 인한 무거운 CPU 소모가 원인
- JVM WarmUp 통해 배포 직후 5000개의 테스트 알림을 10회 미리 보내 최적화를 미리 진행하여 해결
- CPU 임계치 65% 이하인 비동기 스레드 40개를 사용하기로 결정
