(이 글은 외로운 우테코 5기 취준생 “김동욱”, “이건회” aka “그레이”, “하마드”가 작성했습니다.)
알림이 항상 성공한다는 보장이 있을까?
알림이 실패한다면 어떻게 될까?
만약…FCM 서버 측의 오류로 알림 요청이 에러가 터지면서 실패한다면 어떻게 해야 할까??
물론 비동기 처리로 전환했기에 한 명에게 전송하는 알림의 에러가 다른 사용자로 전파되지는 않으나, 해당 사용자에게는 정말 억울한 상황이 아닐 수 없다. 남들 다 받는데 나만 안 받으면…
그래서 알림이 실패했을 경우, 어떻게 재시도하도록 할 것인가? 에 대해 논의 및 적용해봤다.
FCM 서버에서는 어떤 에러가 발생할까??
알림 서버의 에러에 대응하기 위해서는, 먼저 알림 서버에서 어떤 에러를 응답하는지 확인해야 할 것이다. araboza.
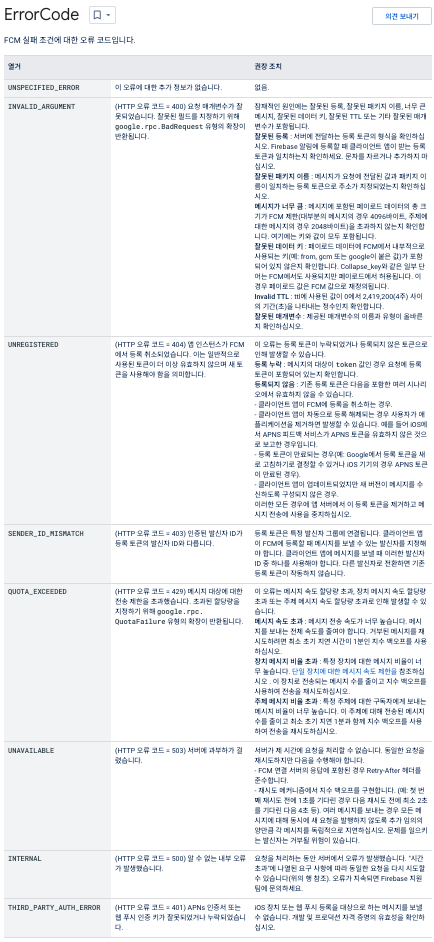
딱 봐도 수많은 에러가 존재하고 있는데…찬찬히 하나씩 확인해 보자
MessagingErrorCode.INTERNAL
Internal server error.
→ FCM 자체 서버에서 발생하는 에러다
MessagingErrorCode.INVALID_ARGUMENT
One or more arguments specified in the request were invalid.
→ 알림을 전송하는 메소드에 잘못된 인자를 넣은 경우다
MessagingErrorCode.QUOTA_EXCEEDED
Sending limit exceeded for the message target.
→ 프로젝트로부터 너무 많은 요청이 빠르게 들어와 서버가 이를 처리할 리소스가 부족한 경우다
MessagingErrorCode.SENDER_ID_MISMATCH
The authenticated sender ID is different from the sender ID for the registration token.
→ 프로젝트 ID값을 잘못 지정한 경우다
MessagingErrorCode.THIRD_PARTY_AUTH_ERROR
APNs certificate or web push auth key was invalid or missing.
→ 설정 오류이다
MessagingErrorCode.UNAVAILABLE
Cloud Messaging service is temporarily unavailable.
→ 일시적으로 서버가 이용 불가능한 경우다
MessagingErrorCode.UNREGISTERED
App instance was unregistered from FCM. This usually means that the token used is no longer valid and a new one must be used.
→ 미등록 혹은 만료 토큰에 메세지를 전송한 경우다
어떤 에러를 재전송처리해야 할까?
모든 에러가 발생할 때 마다 재전송을 해야할까? 만약 토큰이 만료된 경우, FCM 서버의 리소스가 부족한 경우, 혹은 메타 데이터를 잘못 넣은 경우 등등…재전송을 아무리 해도 계속 실패할 것이다. 따라서 수많은 에러 중 어떤 에러를 재전송 해야 할지 지정해야 한다.
MessagingErrorCode.INTERNAL
→ FCM 자체 서버 에러므로 재전송에 적합
MessagingErrorCode.UNAVAILABLE
→ 일시적 오류이므로 재전송 적합
MessagingErrorCode.INVALID_ARGUMENT
→ 애초에 로직자체를 잘못 짠 경우므로 재전송 부적합
MessagingErrorCode.QUOTA_EXCEEDED
→ 메세지를 계속 보내도 이미 한도초과이므로 부적합
MessagingErrorCode.SENDER_ID_MISMATCH
→ 프로젝트 ID값이 잘못된 경우므로 부적합
MessagingErrorCode.THIRD_PARTY_AUTH_ERROR
→ 이 부분도 설정 오류이므로 부적합
MessagingErrorCode.UNREGISTERED
→ 미등록 혹은 만료토큰 발생시 재전송보다는 토큰 삭제처리가 적합
최종적으로 메세지를 재전송했을때 성공 확률이 높다고 판단되는 INTERNAL, UNAVAILABLE 에러에 대해 재전송 처리를 하기로 결정했다.
어떻게 재전송해야 할까?
그렇다면 재시도는 언제 다시 수행해야 할까? 이는 분명 서비스의 특성과 서버 상황에 따라 다르겠지만, 우리는 FCM 공식 문서에서 권장한 예시를 레퍼런스로 삼았다.

FCM 공식문서에서는 예시로 3회 재시도를 시도하며, 첫 번째 재시도는 적어도 1초 대기, 두 번째는 2초 대기, 세 번째는 4초 대기를 권장하고 있다.
재시도, 구현해보자
public void sendMessageTo(String targetToken, String title, String body) {
Notification notification = Notification.builder()
.setTitle(title)
.setBody(body)
.build();
Message message = Message.builder()
.setToken(targetToken)
.setNotification(notification)
.build();
ApiFuture<String> apiFuture = FirebaseMessaging.getInstance().sendAsync(message);
Runnable task = () -> {
try {
String response = apiFuture.get();
log.info("알림 전송 성공 : " + response);
log.info("현재 스레드 NAME: " + Thread.currentThread().getName());
} catch (InterruptedException e) {
log.error("FCM 알림 스레드에서 문제가 발생했습니다.", e);
} catch (ExecutionException e) {
if (e.getCause() instanceof FirebaseMessagingException exception) {
MessagingErrorCode errorCode = exception.getMessagingErrorCode();
if (isRetryErrorCode(errorCode)) {
retryWithInThreeTimes(message);
}
}
}
};
apiFuture.addListener(task, callBackTaskExecutor);
}수정한 재시도 로직을 천천히 설명하도록 하겠다. 일단 메시지 응답을 처리하는 Runnable의 try-catch 문에서 ExecutionException 이 발생한 경우 해당 에러가 FirebaseMessagingException 의 하위 타입인지 검사하고, 해당 에러가 하위타입이자 재전송해야할 에러라면 재전송을 시도한다.
private static final int MAX_RETRY_COUNT = 3;
private static final int[] LOOP_BACK_TIMES = new int[]{1000, 2000, 4000};
private void retryWithInThreeTimes(Message message) {
int count = 0;
while (count < MAX_RETRY_COUNT) {
try {
Thread.sleep(LOOP_BACK_TIMES[count]);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
boolean isRetrySuccess = retry(message);
if (isRetrySuccess) {
break;
}
count++;
log.info(count + "번째 재시도 입니다.");
}
if (count == MAX_RETRY_COUNT) {
// 재전송에 실패한 알림은 직접 핸들링 하는 로직이 필요할 것
log.info("알림 재전송에 실패했습니다.");
}
}3회 재전송을 수행하는 로직이다. 각각 재전송 횟수마다 대기 시간이 각각 다르다. 1회 재전송시 1초, 2회 재전송시 2초, 3회 재전송시 4초간 스레드를 대기시킨 후, 재전송을 시도한다.
재전송이 성공했다면 반복문을 빠져나가고, 실패했다면 3회까지 재전송한 후, 3회 재전송에 실패하면 최종 실패로 간주한다.
이후 최종실패 알림 처리는 영속화를 하여 배치 작업을 통해 재시도 하는 등의 추가 조치가 필요할 것이다. 이번 포스팅에서는 따로 다루지 않겠다.
private boolean retry(Message message) {
try {
String response = FirebaseMessaging.getInstance().sendAsync(message).get();
log.info("알림 재시도 성공 " + response);
} catch (Exception e) {
if (e.getCause() instanceof FirebaseMessagingException exception) {
MessagingErrorCode errorCode = exception.getMessagingErrorCode();
if (isRetryErrorCode(errorCode)) {
log.info("알림 재시도 실패... 다시 시도합니다.");
return false;
}
}
}
return true;
}
private boolean isRetryErrorCode(MessagingErrorCode errorCode) {
return MessagingErrorCode.INTERNAL.equals(errorCode) ||
MessagingErrorCode.UNAVAILABLE.equals(errorCode);
}실제 재전송을 하는 로직이다. 해당 로직에서는 get() 을 통해 재전송 처리 스레드를 블로킹 방식으로 동작하게 했다. 일반적으로 재전송이 필요한 알림이 실패하는 경우가 적기도 하고, 재전송시 스레드를 대기시키는 시간도 필요하기 때문에 재전송 과정에서의 논블로킹 처리는 효과가 거의 없는 수준이라고 판단했다.

일부러 에러가 발생하도록 하는 테스트를 수행하니 정상적으로 3회 재전송 후 실패 처리를 하는 것을 로그를 통해 확인할 수 있다.
Spring의 Retry를 이용해 좀 더 간결하게 코드를 작성할 수 있지만, 이번 포스팅에서는 직관적이고 간단하게 표현했다. 추가적으로 FCM 서버의 에러가 아닌 네트워크 에러나 백엔드 서버 내부 에러에 대해서는 추가적인 재시도 논의가 필요할 것이다.
