공부한 이유
- 우테코 프리코스 미션을 수행하며 다른 참가자 분들의 코드를 열심히 구경하던 중, equals와 hashcode 메소드를 오버라이딩하여 사용하는 코드를 적지 않게 확인할 수 있었다. 그런데 정작 이 방법을 왜 사용하는지, 또 어떻게 사용하는지에 대한 지식이 전무했기에, 본 기회를 통해 인지하고 넘어가고자 하였다.
정의
equals에 대하여 : 동일성과 동등성의 개념
- 일단 이 equals를 이해하기 위해서 동일성과 동등성의 개념을 다시 짚고 넘어가 보도록 하자
동일성
동일성은 말 그대로 객체 A와 객체 B가 완전히 같은 하나의 객체라는 것이다. 즉 메모리에 저장된 주소공간이 완전히 같을 경우, "객체 A와 B는 동일하다" 라고 표현 가능하다.
즉 반대로 표현하면 객체의 상태가 완전히 같아도, 주소공간이 다르면 동일한 객체가 아니다 라고 표현할 수 있는 것이다.
동등성
동등성은 위와 달리, 두 객체의 주소공간이 같아도 단순히 가지고 있는 값만 같다면 "A와 B는 동등하다" 라고 표현한다.
이 동일성과 동등성의 차이를 코드를 통해 보자
class Main {
public static void main(String[] args) {
String Man1 = "lee";
String Man2 = "lee";
System.out.println(Man1 == Man2); //true
System.out.println(Man1.equals(Man2)); //true
}
}그런데 위 코드에서는 Man1과 Man2의 동일성과 동등성이 모두 보장되는 것을 볼 수 있다. 이는 객체에 값이 실제 값을 저장한느 원시 타입(Primitive)으로 저장되었고, 원시 타입은 단순히 값을 비교하여 동일성을 판단하기 때문이다.
class Main {
public static void main(String[] args) {
String Man1 = new String("lee");
String Man2 = new String("lee");
System.out.println(Man1 == Man2); //false
System.out.println(Man1.equals(Man2)); //true
}
}따라서 위 코드 처럼 new String을 통해 참조 타입으로 변수를 생성한 경우, 참조 타입은 주소 공간을 저장하므로 주소 공간이 다른 Man1과 Man2는 동일성이 보장되지 않고 동등성만 보장 된다.
equals & hashcode 사용 이유
equals의 필요성
나는 먼저 근본적으로 equals가 필요한 이유는 객체지향의 "캡슐화" 개념 때문이라고 생각했다. 결국 캡슐화를 보장해 내부 상태 정보를 숨긴 채로 두 객체의 동등성 정보를 파악해야 하는데, 따라서 상태 간 비교가 아닌 더 큰 개념에서 객체와 객체 자체를 비교하기 위해서 equals라는 메소드를 재정의해 동등성을 판단해야 한다고 생각했다.
즉 객체에게 "너 얘랑 같냐?"라고 질문만 던질 수 있도록 하는 것이다.
또 추가적으로 들은 조언은...단순하게 생각해서 동등성 관리 제대로 안해서 같은 클라이언트를 다른 놈으로 인식해버리면 서비스가 어떻게 되겠냐는 말이었다.
따라서 equals를 구현하지 않을 경우
public static void main(String[] args) {
Car car1 = new Car(1,"sonata");
Car car2 = new Car(1,"sonata");
System.out.println(car1.equals(car2)); //false
}다음과 같이 객체 내부 상태가 완전히 같아도 동등성을 보장할 수 없다.
equals 사용 예시 - equals만 재정의
public class Car {
private final int id;
private final String name;
public Car(int id, String name) {
this.id = id;
this.name = name;
}
@Override
public boolean equals(Object o) {
if (this == o) {
return true;
}
if (o == null || getClass() != o.getClass()) {
return false;
}
Car car = (Car) o;
if (id != car.id) {
return false;
}
return Objects.equals(name, car.name);
}
}따라서 equals를 다음과 같이 재정의하면
public static void main(String[] args) {
Car car1 = new Car(1,"sonata");
Car car2 = new Car(1,"sonata");
System.out.println(car1.equals(car2)); //true
}위와 같은 테스트에서 동등성이 보장됨을 확인할 수 있다.
그럼 hashcode는 왜 필요할까? - Hash Collection 객체 때문
- 위의 예시만 본다면 equals만 잘 재정의하면 모든 객체의 동등성이 보장될 것 같지만, 아쉽게도 모든 객체가 그렇지는 않다.
- 이 예외는 Hash 값을 사용하는 Hash Collection 자료구조(HashMap, HashSet, HashTable) 때문에 일어난다
public static void main(String[] args) {
Set<Car> cars = new HashSet<>();
cars.add(new Car(1, "sonata"));
cars.add(new Car(1, "sonata"));
System.out.println(cars.size()); // 2 -> HashSet 사이즈가 1이 아닌 2임
}위의 예시를 보자, 만약 컬렉션에 중복되지 않은 객체를 넣으라는 요구사항이 있다고 가정해 보자
중복을 불허하는 Set을 사용하여 완전히 상태가 같은 객체를 두 번 set에 집어넣었다. 이론상으로는 중복이기에 Hashset의 길이가 1이어야 하지만 프로그램을 돌리면 길이가 2가 나온다. 동등성 보장에 실패한 것이다.
보장되지 않는 이유는?
참고한 블로그에 사진으로 이 내용이 명확히 설명되어 인용을 하도록 하겠다
위에서 언급 한 Hash를 사용하는 Collection들(HashMap, HashSet, HashTable)은 객체의 동동성 비교를 다음 과정과 같이 수행한다
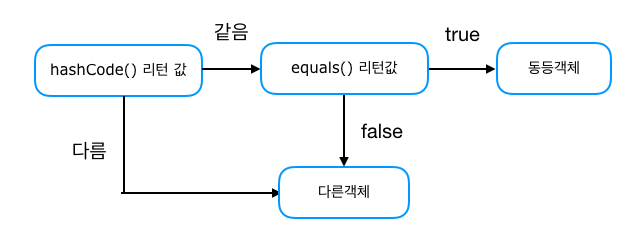
출처 : https://tecoble.techcourse.co.kr/post/2020-07-29-equals-and-hashCode/
즉, 일단 hashcode값이 서로 같아야만 equals 메소드로 객체비교를 수행하는 것이다. Hashcode가 다르면 동등성 비교는 입구컷이라는 뜻
따라서 상태 값이 같을 때, Hashcode 또한 같도록 오버라이딩 해야 한다!
public class Car {
private final int id;
private final String name;
public Car(int id, String name) {
this.id = id;
this.name = name;
}
@Override
public boolean equals(Object o) {
if (this == o) {
return true;
}
if (o == null || getClass() != o.getClass()) {
return false;
}
Car car = (Car) o;
if (id != car.id) {
return false;
}
if (name != null ? !name.equals(car.name) : car.name != null) {
return false;
}
return true;
}
@Override
public int hashCode() {
int result = id;
result = 31 * result + (name != null ? name.hashCode() : 0);
return result;
}
}따라서 다음과 같이 hashCode를 재정의해주는데, 나는 그냥 인텔리제이의 generate를 사용했고, 실제로도 hashcode 재정의를 사람이 직접 수행하는 경우는 많이 없다고 한다.
public static void main(String[] args) {
Set<Car> cars = new HashSet<>();
cars.add(new Car(1, "sonata"));
cars.add(new Car(1, "sonata"));
System.out.println(cars.size(); // 1 -> 동등성 보장
}따라서 테스트를 수행하면 set의 사이즈가 정상적으로 1로 출력된다.
HASHCODE, 항상 재정의해야 하는가
참고한 블로그의 말을 인용하면, 항상 HASH COLLECTION을 사용하는 것은 아니나, 요구사항이 이것을 사용하도록 변경되었을때 코드의 수정을 최소화하려면 미리 정의하는 것이 좋다는 의견을 주셨다. 참고로 내 견해도 이와 일치한다.
참고
https://tecoble.techcourse.co.kr/post/2020-07-29-equals-and-hashCode/
https://mangkyu.tistory.com/101
