
- 네트워크 계층의 프로토콜은 ip, icmp, 라우팅 프로토콜 3가지가 있다.

- icmp는 호스트와 라우터 간 에러 리포팅 등 서로 살아있는지 확인하기 위한 네트워크 계층 제어 정보를 교환하는 프로토콜이다.
- icmp는 ip보다 상위 계층인데 icmp 메세지를 ip 데이터그램으로 encapsulate하기 때문이다.
- icmp 메세지에는 타입,코드, 문제가 된 ip 데이터그램의 첫 8바이트가 필드로 담긴다. 타입과 코드에 어떤 문제가 발생했는지(오류정보)가 담겨있다. 만약 문제 발생 경우 라우터가 소스에게 전달하지 못하는 데이터그램의 첫 8바이트를 icmp 메세지에 싣고 코드와 타입을 적어 보낸다. 타입 8이고 코드 0 이면 양 네트워크가 살아있다는 메세지(echo request)이다.

- 위는 icmp를 활용해 구현된 네트워크 애플리케이션 프로그램이다. 호스트 1인 gaia~에서 호스트 2인 eure~까지 가는데 거치는 모든 라우터의 리스트와 ip주소, 각 라우터까지의 딜레이를 세 번 측정한 결과가 보여진다. 8번째 부터 딜레이가 확 느는 부분을 볼 수 있다. 대답이 없을 때는 17번처럼 별이 찍힌다.
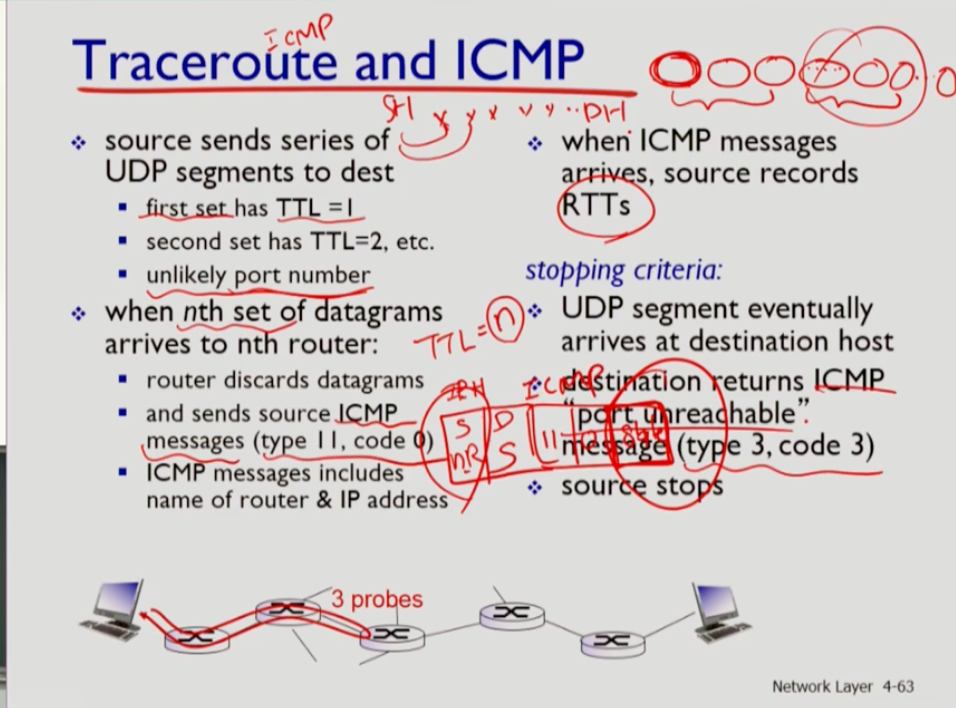
- traceroute는 소스 호스트에서 udp 세그먼트를 계속 내보낸다. 세그먼트 3개가 1세트인데 첫번째로 내보낼때는 헤더에 ttl 필드를 1로 셋팅한다. n번째를 내보낼때는 n으로 셋팅한다. n번째 라우터가 이를 icmp 메세지를 만들고 ip 데이터그램을 보낸 소스로 icmp를 보내며 드랍시킨다. 소스는 이를 확인하며 라우터의 이름과 n번째 라우터의 rtt를 알 수 있다.
- ttl이 충분히 커져 목적지 호스트까지 도착하면, 목적지 호스트는 port unreachable이라는 메세지를 보낸다. 그러면 소스는 경로파악이 끝났음을 알고 종료시킨다.

- ipv6는 ipv4의 주소 공간 부족 문제를 해결하기 위한 것이다. ipv6는 주소를 128비트로 표현한다. 이는 영원히 고갈되지 않을 수준의 공간이다. 또 가변적이지 않고 고정된 길이의 주소 필드를 사용하고 fragmentation을 없애므로써 데이터그램의 프로세싱 시간을 단축시킨다.

- 위와 같은 필드들이 ipv6에서 qos로 추가된다.

- ipv6에서는 체크섬이 삭제된다. 헤더에 오류가 없다고 가정하기 때문이다. 옵션 필드도 없어진다.
- icmpv6라는 icmp의 새로운 버전도 만들어졌다.

- ipv4 체계를 하루아침에 ipv6로 모두 바꿀 수는 없고, 중간중간에 ipv6로 바꿔준다. 그러나 ipv4는 ipv6를 이해할 수 없으므로 "터널링"을 활용하여 ipv4 데이터그램 속에 ipv6를 동봉한다.
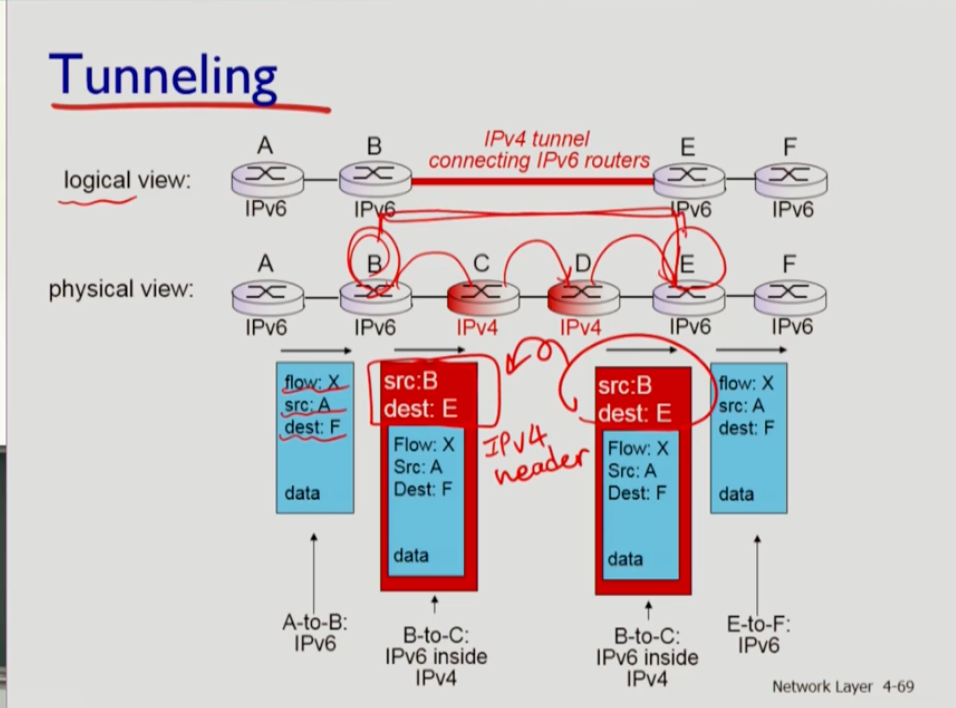
- 물리적으로는 중간에 ipv4가 껴있지만 논리적으로는 B다음의 ipv6인 E쪽으로 연결된다. A가 보낸 메세지를 B는 ipv6이므로 이해한다. 그러나 다음 홉인 C는 ipv4이므로 이해하지 못한다. 다음 ipv6는 E이므로 그 쪽까지 터널링하기 위해 목적지를 E로 설정한 ipv6데이터그램을 ipv4에 동봉한다. 즉 ipv4헤더가 붙는 것이다. 목적지인 E에 도착하면 헤더를 뜯어내므로 헤더가 없어지고 나면 ipv6 데이터그램이 되고, E는 똑같이 ipv6을 다음 홉으로 전달한다. 즉 터널링은 ipv6에 ipv4헤더를 붙이는 것이다.
4.5 라우팅 알고리즘
- 라우팅 프로토콜은 라우팅 알고리즘이 필요로 하는 정보를 수집하는 것이다.
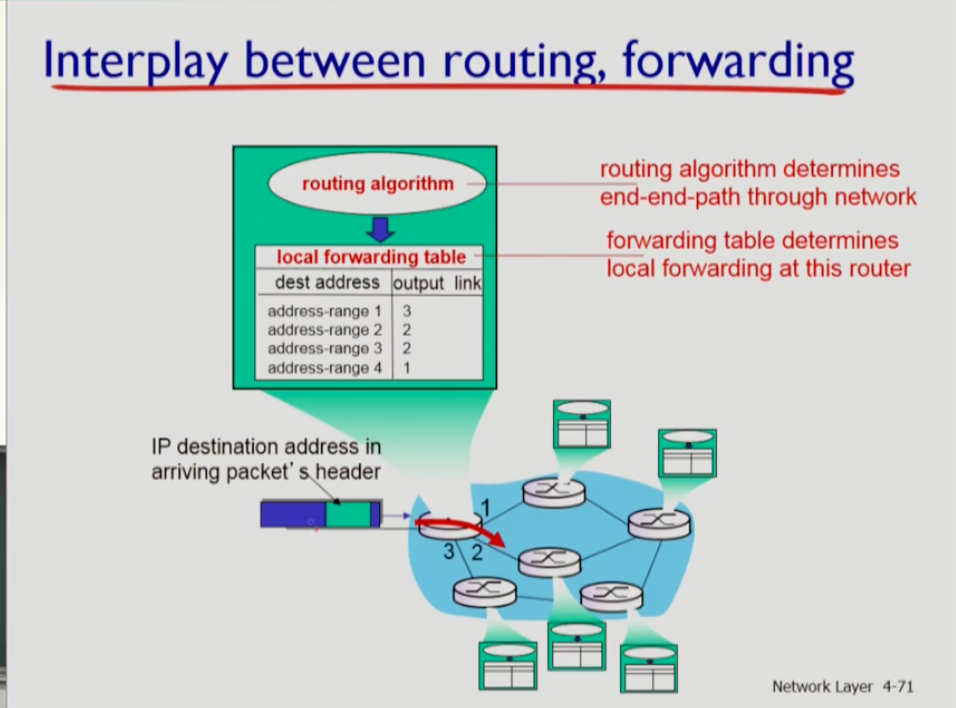
- 라우팅 프로토콜의 목적은 포워딩 테이블을 만들어 패킷이 들어올 때 포워딩 테이블을 룩업해 패킷이 포워딩 될 수 있도록 하는 것이다.

- 라우팅 알고리즘에서는 네트워크를 그래프로 추출한다. 그래프를 통해 네트워크의 라우터(N)와 그들 사이의 링크(E)를 모델링할 수 있다.

- 인터넷은 모든 링크의 코스트를 1로 하는데 경우에 따라 다를 수도 있다. 밴드위드 혹은 컨제스쳔, 딜레이, 링크 사용 비용에 따라 코스트를 다르게 할 수도 있다.
- 라우팅 알고리즘의 목적은 목적지까지 최소 비용의 경로를 발견하는 것이다.

- 라우팅 알고리즘은 여러가지로 분류된다.
- 먼저 글로벌과 decentralized로 구분 가능하다. 글로벌 알고리즘은 링크 스테이트라고 부르며, 각 라우터가 네트워크의 전체 상태 정보를 가진다. 문제는 이 정보는 항상 연속적으로 가지고 있어야 한다.
- decentralized 알고리즘인 distance vector 알고리즘은 아주 지엽적인 정보만 알고 있다. 이웃은 누구고 이웃까지의 링크 코스트의 얼마인지만 안다. 이 라우터는 이웃에게 어떤 목적지 서브넷까지 가는 비용이 얼만지 물어보고, 그 이웃은 또 그 옆의 이웃에게 질문을 하여, distance vector를 교환하는 방식이다. 이 정보가 점점 커지며 라우터가 모든 네트웤에 대한 정보를 알 수 있다.
- 혹은 static 혹은 dynamic으로 분류할 수 있다. static은 링크 코스트를 고정적으로 사용한다. 링크 코스트가 변할 일이 없는 인터넷과 같은 경우 사용한다. 이런 알고리즘은 자주 실행될 이유가 없다. 반면 dynamic은 링크 코스트가 가변적이다. 특정 링크에 트래픽이 생겨 밴드위드가 변하면 라우팅을 효율적으로 하기 위해 큰 밴드위드의 링크로 보낼 때 이런 링크 코스트를 사용한다.
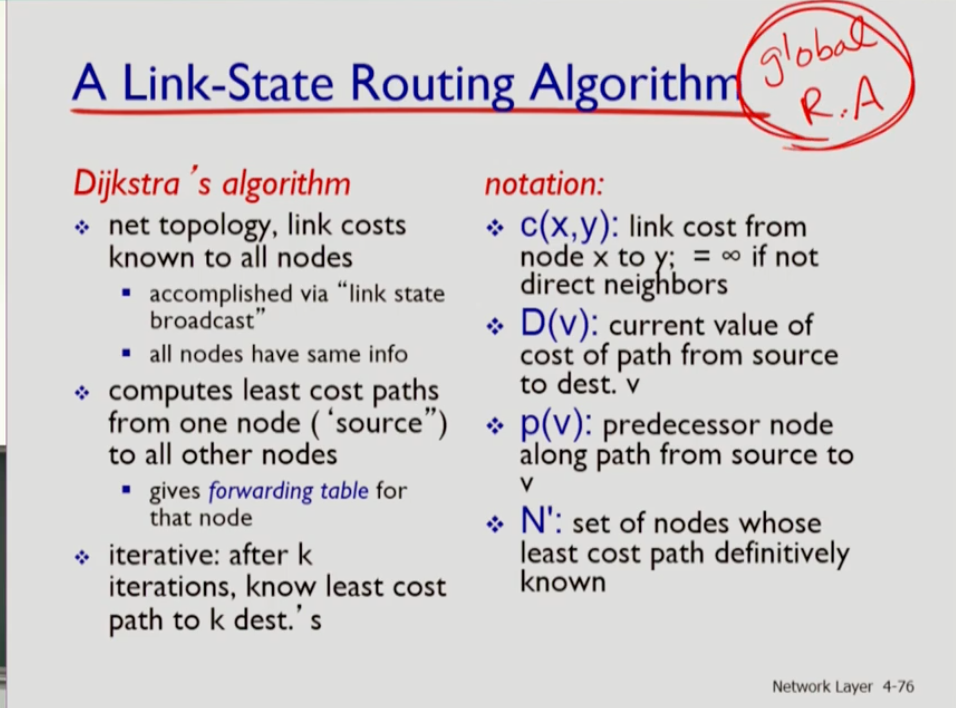
- 글로벌 알고리즘을 알아보겠다. 다익스트라가 대표적인 링크 스테이트 알고리즘이다. 하나의 소스 노드로부터 네트워크의 모든 목적지에 대해 최단 경로를 발견한다. 네트워크에 호스트가 n개 있다면 가장 가까운 목적지로부터 n번의 iteration을 수행한다.
- c(x,y)는 x부터 y로까지 가는 비용를 의미한다. D(v)는 i번째 iterations까지 즉 현재까지 수행한 것 중 최솟값을 말한다. p(v)는 그 최단 경로에서 바로 직전의 노드다. N'는 최단 경로가 확정된 노드의 집합이다.

- 다익스트라 알고리즘의 예시다. 위치 및 연결 정보를 입력 받고 루프가 시작되면 가장 가까운 노드를 N'로 옮겨 현재 최단 경로 정보와 비교하고 최단 경로가 더 짧은 거리가 그 노드로부터 있으면 정보를 갱신한다. 궁극적으로 모든 노드가 N'로 옮겨지고 최단 경로가 파악된다.

하마드