데이터베이스란 무엇인가?
파일 시스템
데이터베이스를 위해서는 파일 시스템을 이해해야 한다. 모든 애플리케이션에는 각각의 애플리케이션마다의 파일이 저장되어 있다. 파일 시스템은 파일 중심의 전통적인 데이터 처리 시스템이다. 각 응용프로그램이 개별적으로 자신의 파일을 관리한다
파일 시스템의 문제점
파일 시스템의 문제점이 여러가지 있다. 먼저 파일처리 시스템은 각 파일마다 필요한 데이터를 각각 가지고 있어야 하는데, 이때 데이터의 중복이 생긴다.
또 데이터에 변경 사항이 조금만 있어도, 각 파일에서 해당되는 데이터를 모두 변경해야 한다. 한꺼번에 수정되지 않으면 데이터 값이 서로 틀리게 되는 문제점이 있다. 따라서 비일관성의 문제가 있다.
또 누구나 파일을 수정할 수 있어 보안이 허술하다.
이러한 문제의 해결을 위해 데이터베이스가 등장했다.
데이터베이스
- 여러 사람에 의해 공유되어 사용될 목적으로 통합되어 관리되는 데이터의 집합이다
- 데이터베이스는 단순 표와 같으므로, 이를 관리하는 시스템과 통합되어 제공되며, 따라서 정확한 명칭은 데이터베이스 관리 시스템, DBMS라 한다
- 관계형(RDBMS)과 비관계형(NOSQL) 데이터베이스로 나뉜다.
데이터베이스 특징
- DB의 정확성을 위해 필터링이 가능하고 여러 명이 데이터를 동시 공유하다
- 하나의 데이터베이스에 여러 응용 프로그램이 접근 가능하여 데이터 중복이 최소화된다.
- 삽입 삭제, 갱신을 통해 계속적 변화에 대한 적응이 가능하다
- 응용 프로그램과 데이터베이스를 독립시켜 관리가 가능하다
관계형 데이터베이스
- 데이터를 컬럼과 로우로 이루어진 테이블 형태로 관리한다
- 현실 세상에는 각각의 개체가 존재하고, 개체 간에는 관계를 갖고 있다.
- 이를 컴퓨터 세상에서 개체-관계 다이어그램인 ERD로 표현할 수 있다
SQL
- 관계형 데이터베이스를 조회하려면 SQL에 대해 알아야 한다. 데이터를 저장하거나 얻기 위해 사용하는 언어다
테이블 생성하기
- CREATE TABLE 명령어를 통해 테이블을 생성할 수 있다
CREATE TABLE movie (
title,
opening_date,
running_time,
description
);- 각각 데이터 필드의 형식 또한 지정할 수 있다
- varchar는 variable character라고 하여 변할 수 있는 문자를 뜻한다
- not null로 비어 있을 수 없는 값을 지정한다
CREATE TABLE movie (
title varchar(30) not null,
opening_date date,
running_time int,
description varchar(255)
);- 이제 Insert를 통해 만들어진 테이블에 데이터를 삽입해 보자
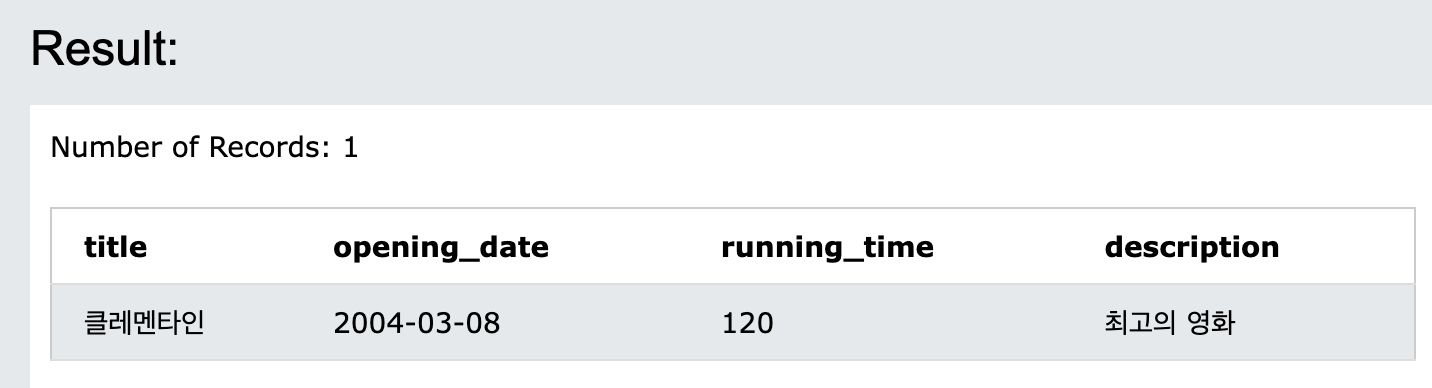
insert into movie (title, opening_date, running_time, description)
values('클레멘타인', '2005-07-08', 120, '최고의 영화');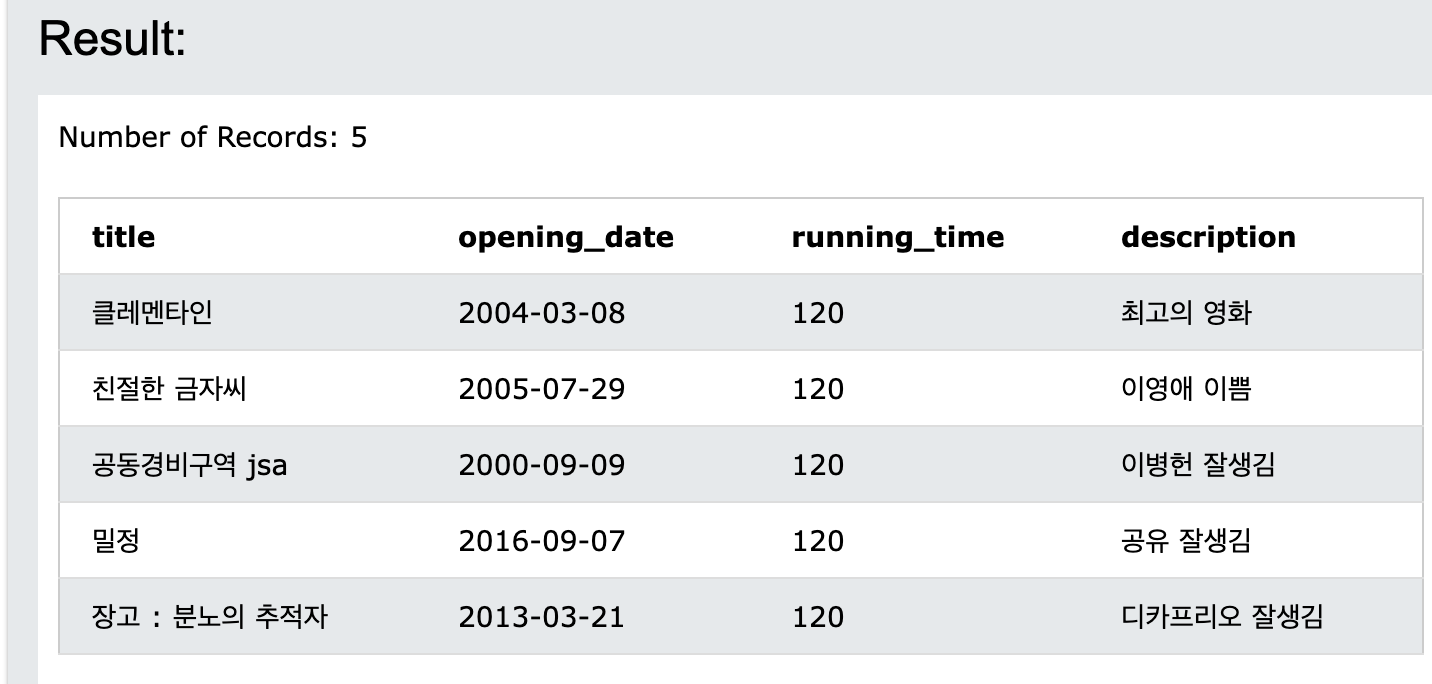
- select를 통해 원하는 데이터를 조회할 수 있다
- where를 통해 특정 조건을 부여할 수 있다
SELECT title
FROM movie
where opening_date >= '2010-01-01'; 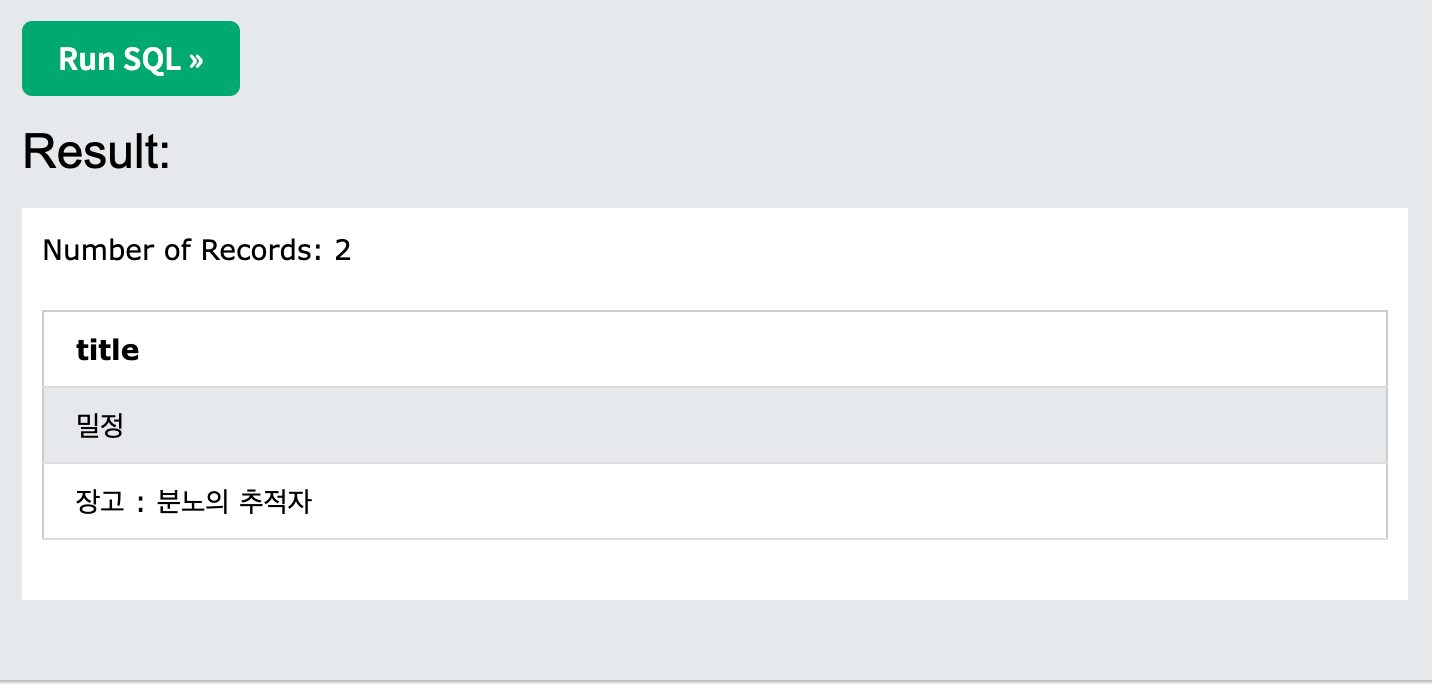
- where에 like를 추가로 부여하면 특정 문자가 포함된 데이터를 조회할 수 있다.
- %를 앞이나 뒤에 추가하는 것은, 어떤 문자(%)가 앞이나 뒤에 와도 상관없다는 뜻이다.
- 이외에도 in , between 등등의 연산자를 사용할 수 있다
SELECT *
FROM movie
where title like "장고%"; 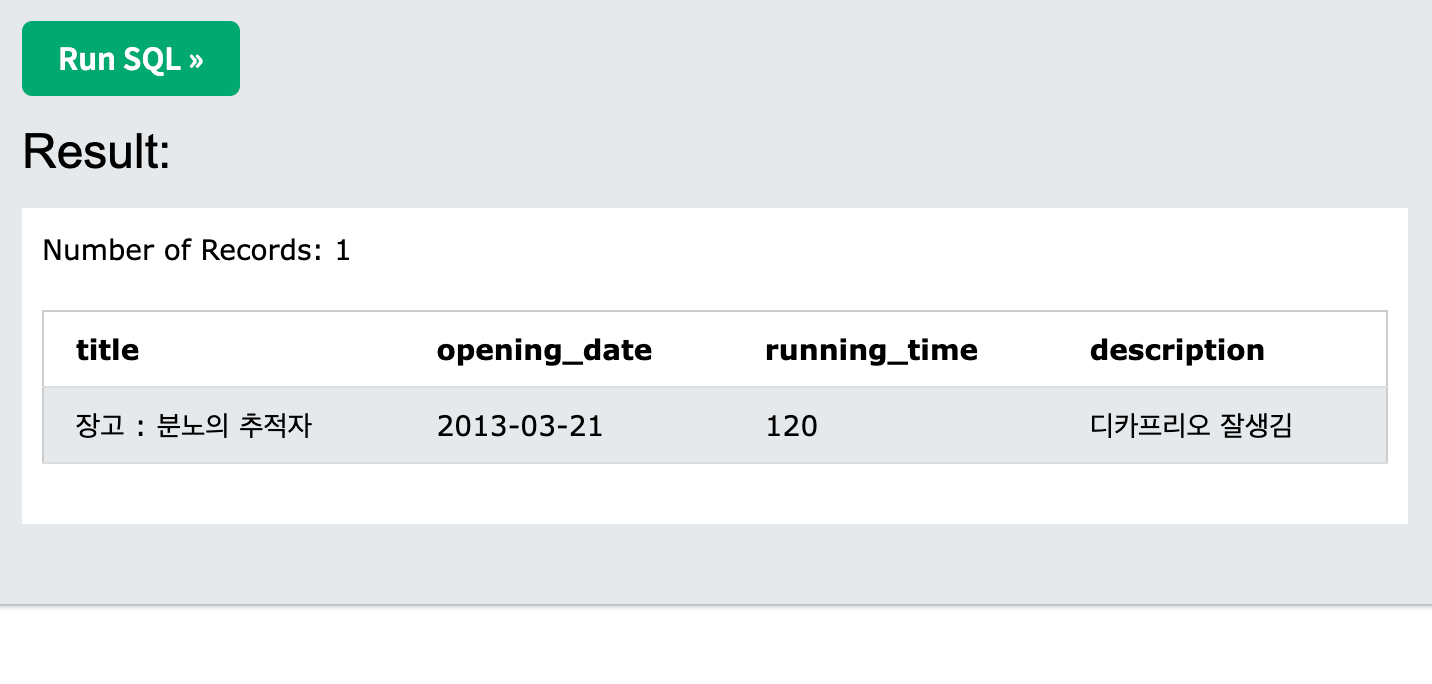
- not을 부여하면 ~빼고 전부 조회라는 명령을 실행하게 된다
SELECT *
FROM movie
where title not like "장고%"; 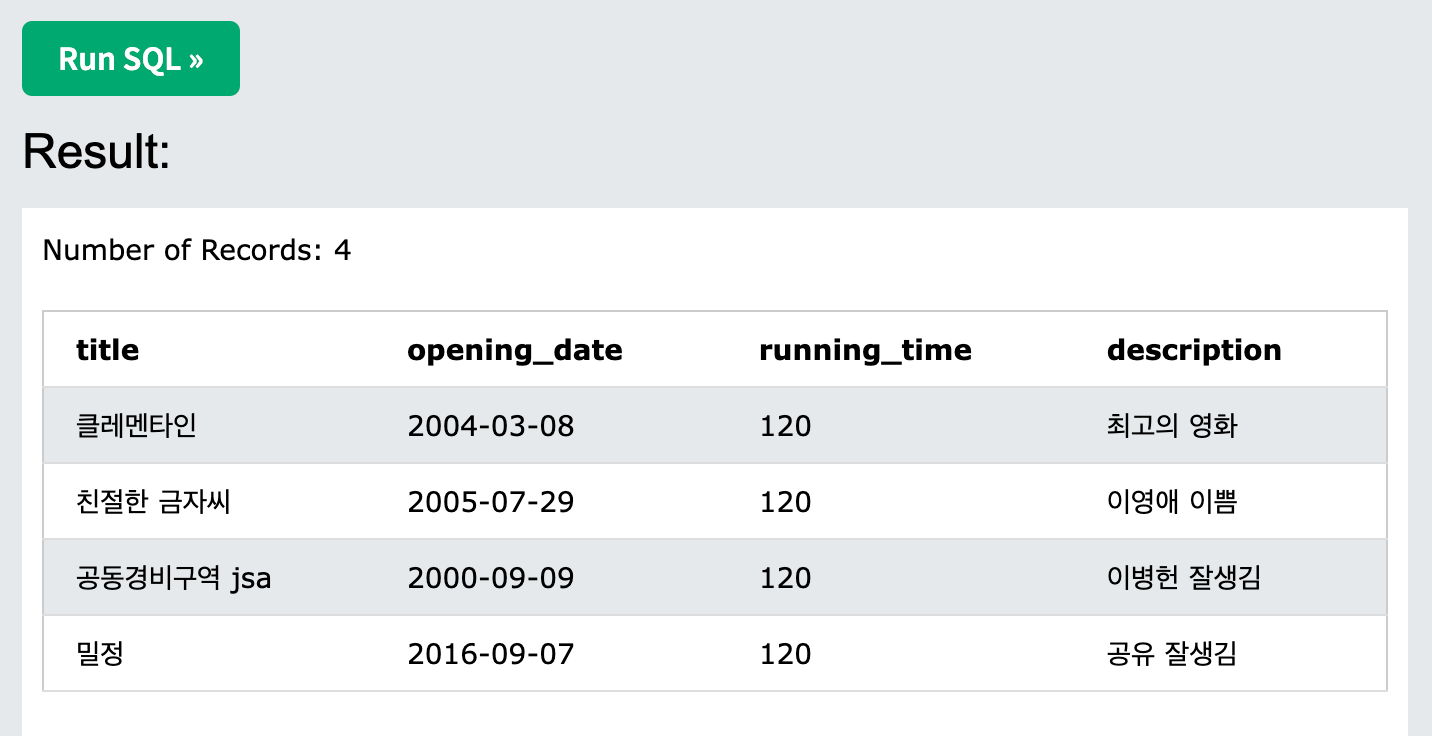
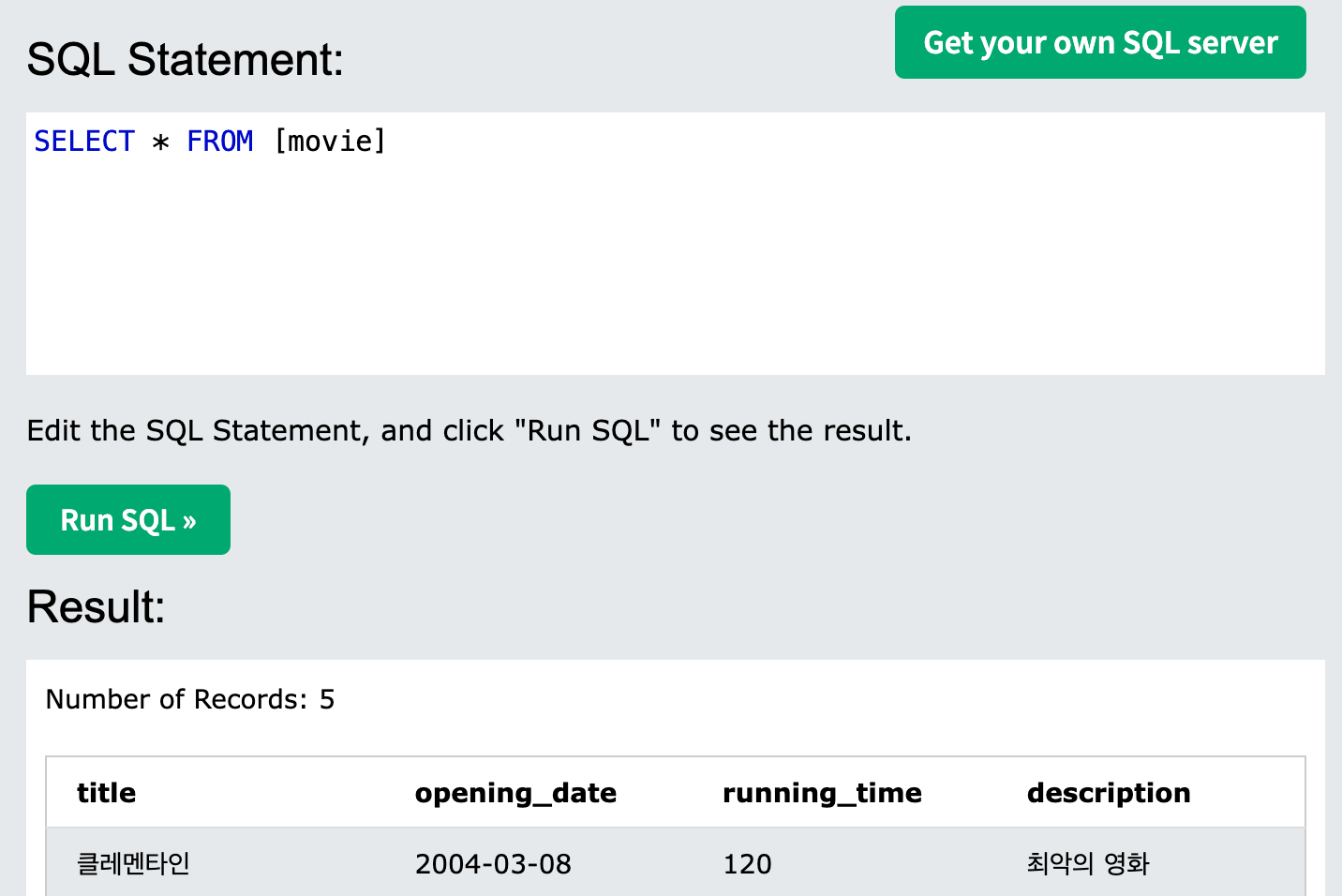
- update를 이용하면 테이블의 데이터를 변경 가능하다.
- 참고로 where가 없으면 명령어가 "모든 데이터를 대상으로 전부 명령어를 실행한다".
-> 따라서 조건을 먼저 명시하고 나머지 쿼리를 작성하자. 아주아주아주 위험하다.
UPDATE movie
set description = '최악의 영화'
where title = '클레멘타인'
;
- Group by를 사용해 그룹핑하여 조회할 수 있다. 어떠한 특정 집계를 수행하기 위해서다.
- 집계 함수의 결과가 조건에 맞는 데이터를 조회할 때는 Having을 사용한다. 그룹핑 할 때 사용하는 where 절이라 생각하면 좋다.
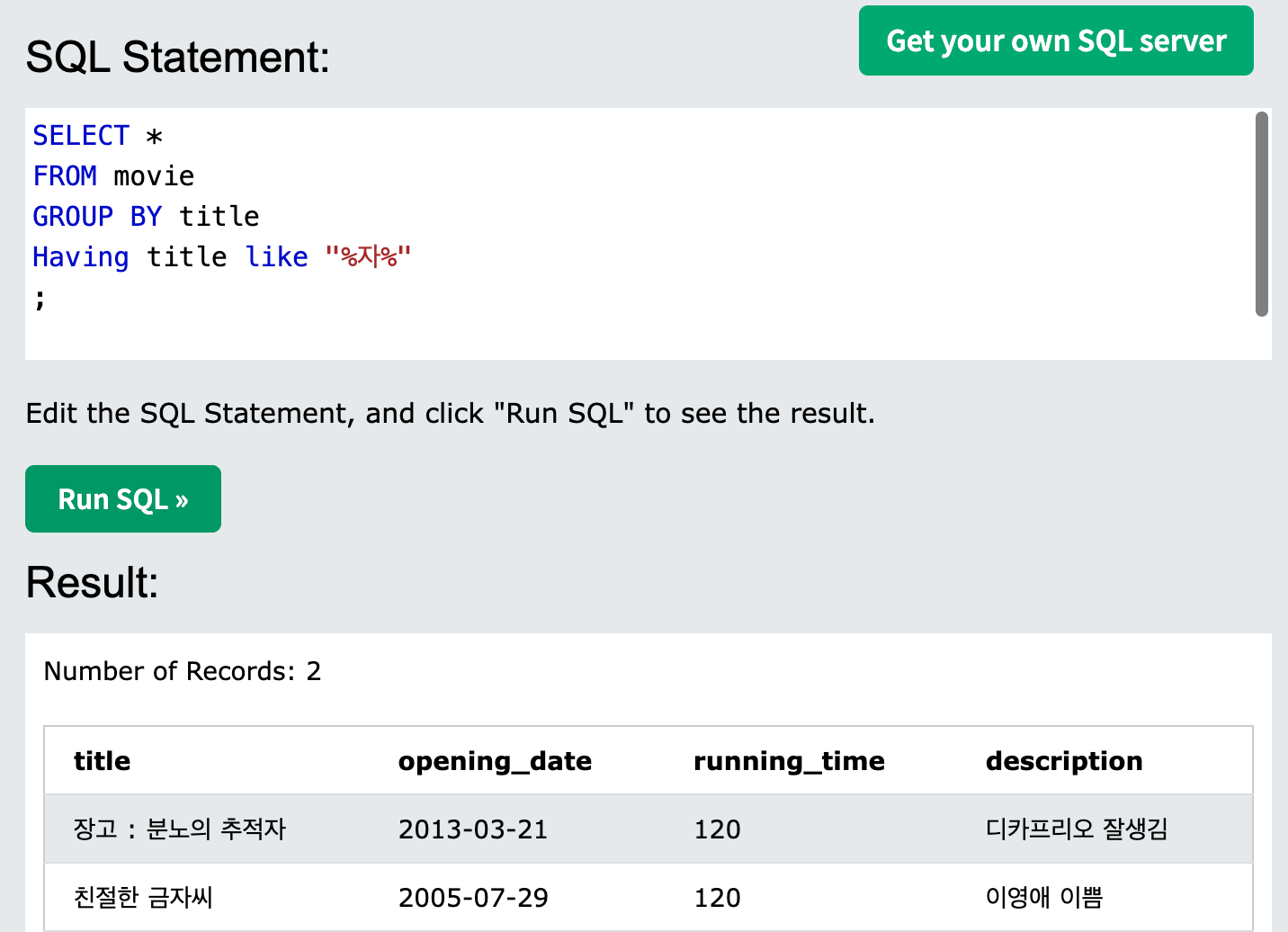
-
Order by를 사용해 정렬하거나, Limit을 사용해 지정한 개수만큼 조회할 수 있다.
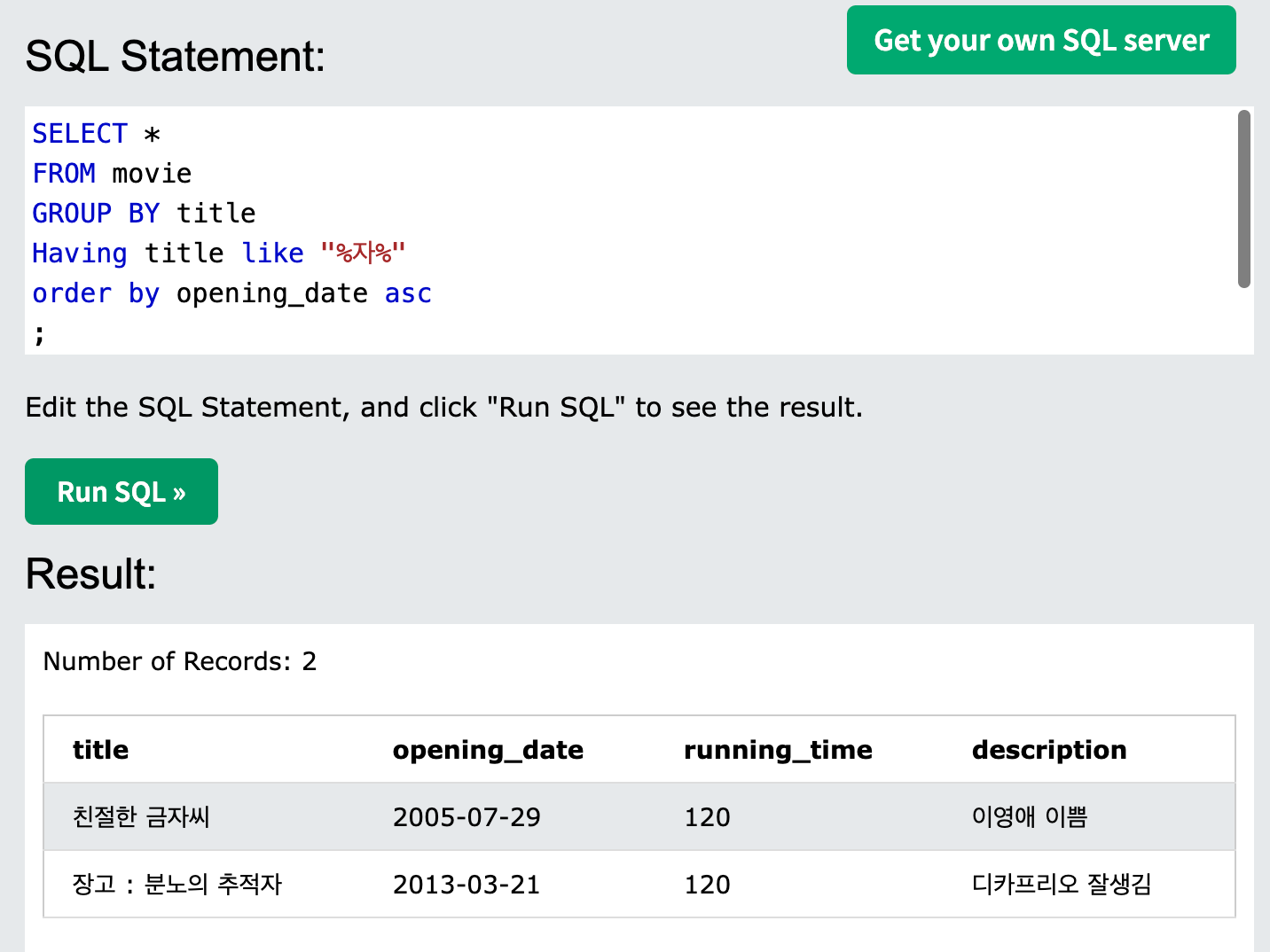
-
이외에도 distinct를 이용해 중복 제거, delete를 통해 삭제 등을 수행할 수 있다. 잘 찾아서 사용해 보자.
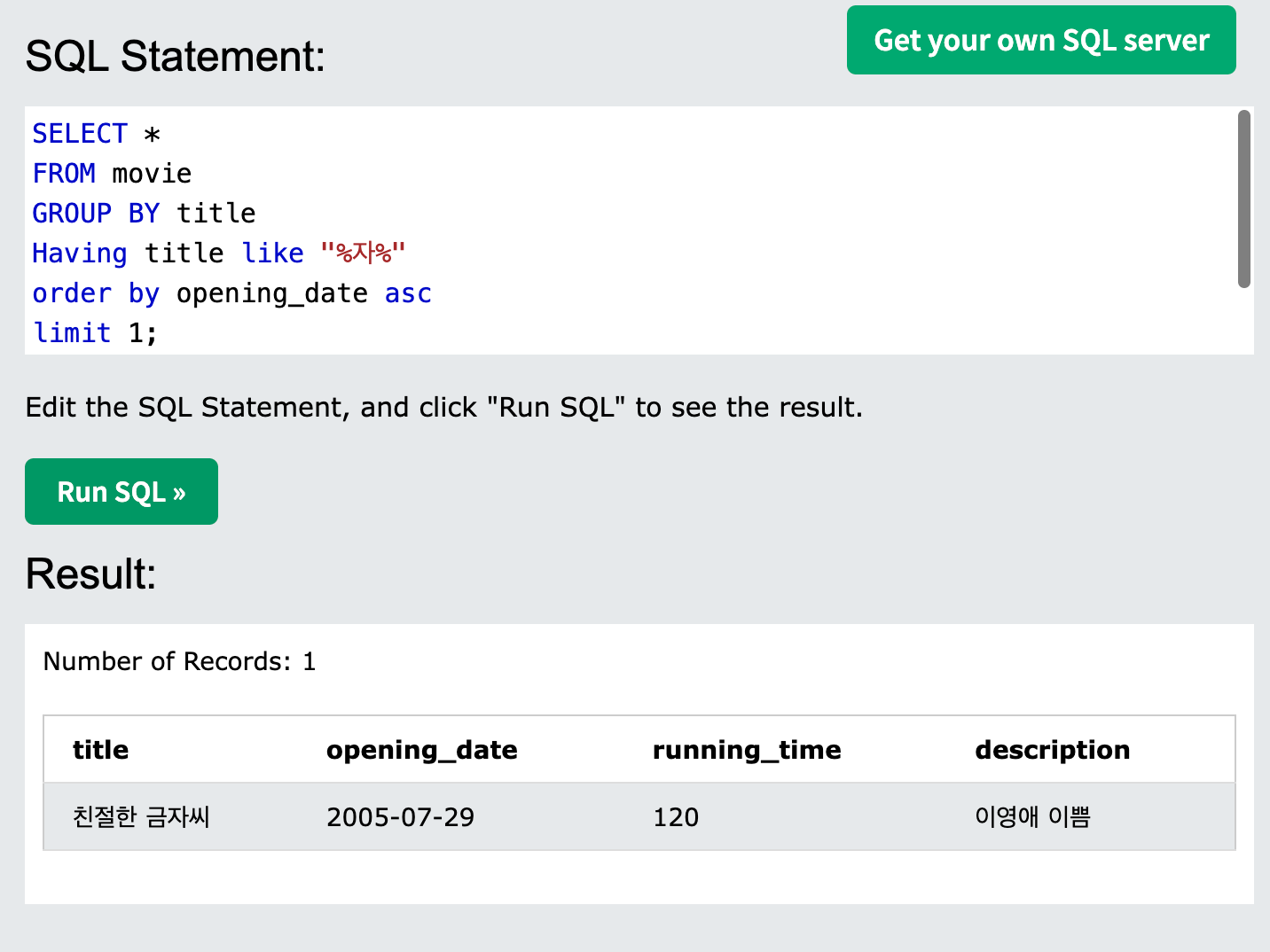
sql 실행 순서
SELECT *
FROM movie
GROUP BY title
Having title like "%자%"
order by opening_date asc
limit 1;
- 다음과 같은 순서대로 위 sql문이 실행된다
FROM(조회 지정)
-> where(필터링)
-> GROUP BY(그룹핑)
-> HAVING(그룹핑 조건)
-> ORDER BY(정렬)
-> LIMIT(제한)위 순서대로 sql이 실행된다
키
PK
- 기본적으로 not null이다. 즉 절대 빌 수 없다.
- 또 절대 중복될 수 없다.
CREATE TABLE movie (
title varchar(30) primary key,
opening_date date,
running_time int,
description varchar(255)
);auto increment
- pk 값이 중복 없이 추가할 때마다 1 증가한다
AS
- 테이블에 별명을 부여할 수 있다
JOIN
- 한 데이터베이스 내의 여러 테이블을 조합하여 결과값을 가져올 때 사용한다
INNER JOIN
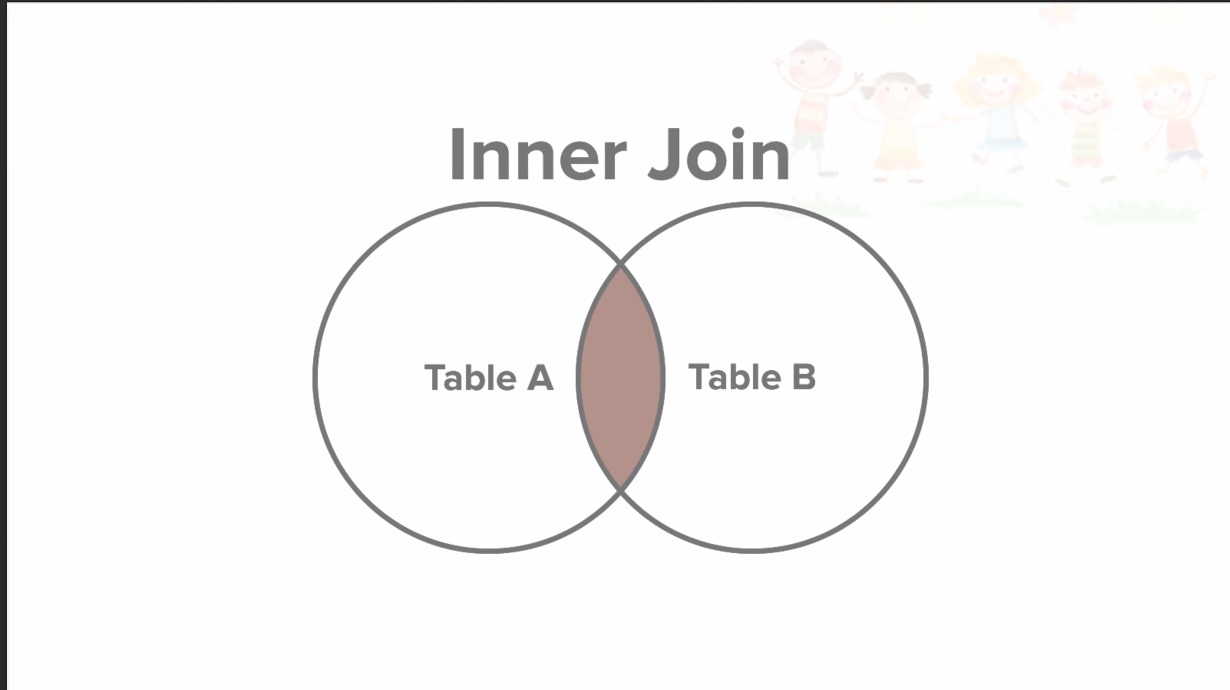
공통 데이터, 즉 교집합을 의미한다.
LEFT JOIN
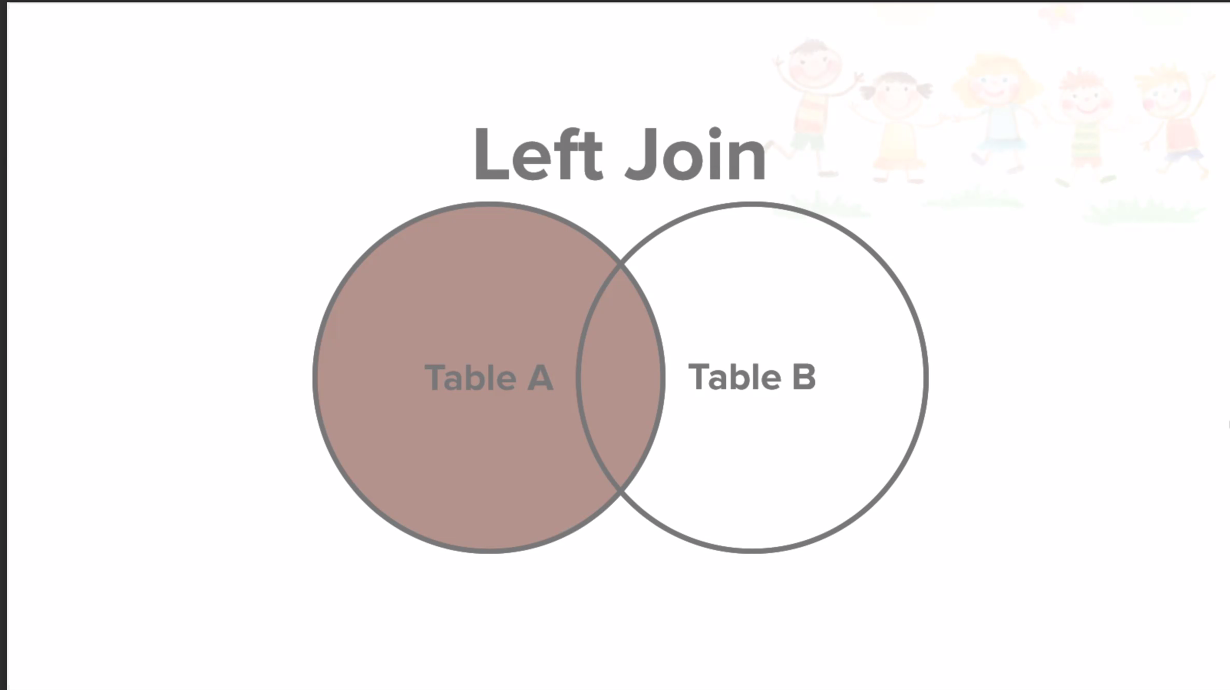
테이블 A의 데이터는 모두 살리고, B에는 교집합을 제외하고 전부 날린다
RIGHT JOIN
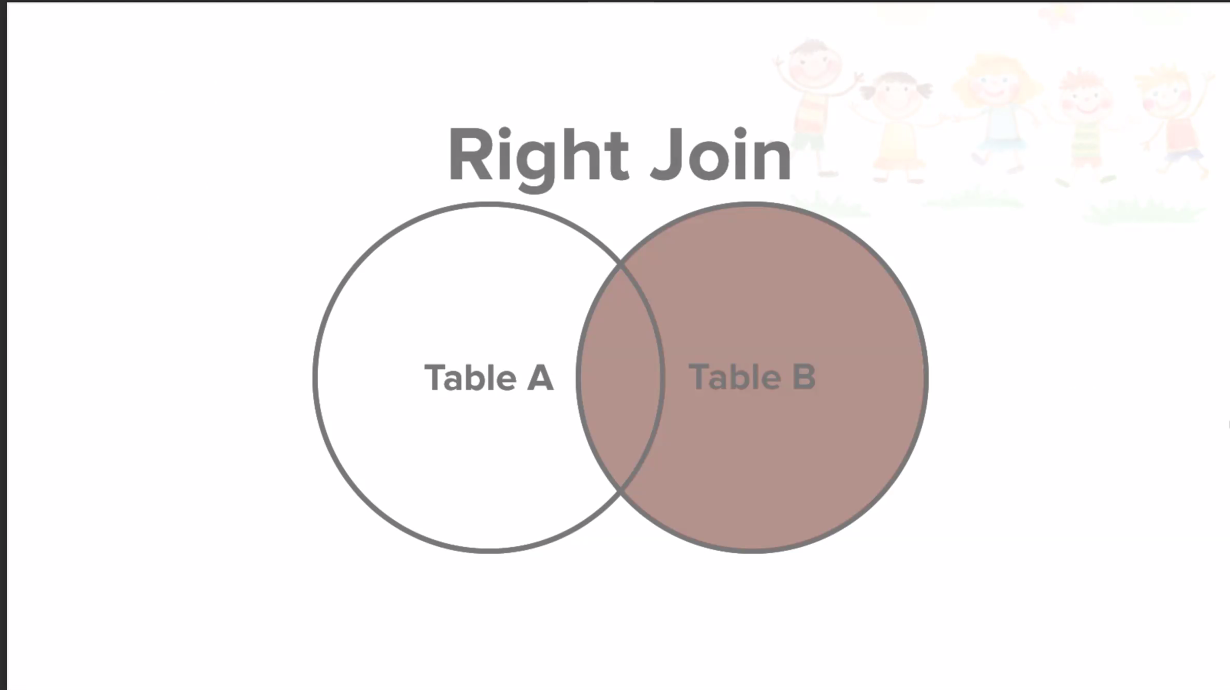
LEFT JOIN과 반대이다
트랜잭션
- 일련의 작업 단위
- 데이터의 무결성을 보장받을 수 있다
- 간단하게 말해 내가 돈을 송금했으면 송금이 모두 성공해 남에게 전액이 가거나, 모두 실패해서 나한테 전액이 돌아오거나 해야 하는 것이다
API
- 뜻을 풀이하면 응용 프로그래밍 인터페이스이다. 여기서 인터페이스는 무엇인가?
- 인터페이스는 두 물체, 공간, 단계 등의 공통 경계면이다.
- 즉 독립되고 관계가 없는 시스템끼리 접촉하거나 통신이 일어나는 부분이다. 따라서 CUI, GUI에서의 I가 인터페이스를 의미한다.
- 쉽게 우리집에 있는 콘센트도 인터페이스다. 발전소의 전기와 우리집 가전제품을 접촉시켜 준다.
- db에 접근하기 위해 유저가 접촉하는 UI도 인터페이스이다("I").

하마드